GraphQL


Intro
소프트웨어 마에스트로 컨퍼런스 발표(8.31) 내용을 요약한 글 입니다.
안녕하세요. 소프트웨어 마에스트로 연수생 이현진입니다.
이번 발표에서는 GraphQL의 컨셉, REST API와의 차이, 실제 활용 실습과 더 나아가 React에서 GraphQL이 해결할 수 있는 문제에 대해서 이야기해보도록 하겠습니다.
발명은 필요에의해서 시작됩니다.
페이스북이 그래프QL을 만들기로한 이유는 다음과 같습니다.

- 모바일 사용량의 증가로 효율적인 데이터 로딩이 필요(저전력 장치 및 느린 네트워크 문제)
- 다양한 플랫폼(플랫폼의 다양화로 인해 모든 요구 사항에 맞는 하나의 API를 구축하고 유지관리하기 어려움)
- 빠른 기능 개발에 대한 기대(지속적 배포는 업계의 표준이 되었고 빠른 반복과 빈번한 제품 배포는 필수적이고 이에따라,
프론트엔드와 백엔드의 의사소통 비용은 증가)
이런 문제들을 해결하기위한 방법은 뭘까요? 각각 대응시켜보겠습니다.
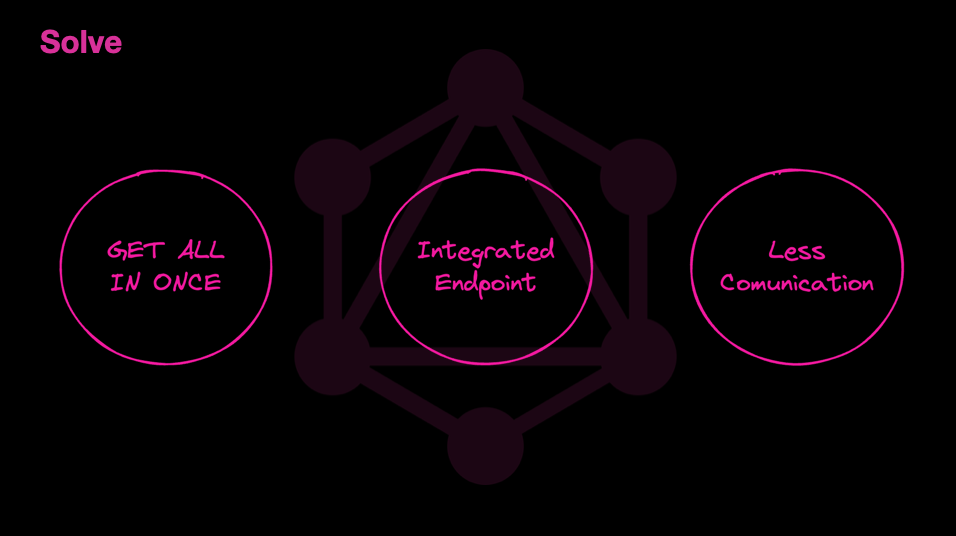
필요한 데이터만한번에,정확하게요청한다.- 엔드포인트를
통합한다. - 프론트엔드와 백엔드의
커뮤니케이션을 줄이고개발에 집중한다.
이 해결 방법이 곧 GraphQL입니다.
이제 GraphQL이 어떻게 이 문제들을 해결했는지 알아보겠습니다.

GraphQL은 Facebook에서 개발한 오픈소스 언어로 현실 세계의 데이터를 표현하는 가장 적합한 방법이 Graph라는 사실에 착안합니다.
사람들은 다른 사람들과 관계를 맺으며 살아갑니다. 가족, 친구, 동료와 사회적 관계를 맺고 있습니다. 이러한 관계중 일부는 겹치지만 겹치지 않는 관계도 존재합니다. 우리 모두는 각자의 삶 내에서 연결된 관계 그래프를 지닙니다.
GraphQL이 API 개발에서 해결하려고 하는 문제가 이렇게 서로 연결된 데이터입니다. GraphQL API는 데이터를 효율적으로 연결할 수 있으며, 요청의 수와 복잡성을 줄이고 클라이언트가 정확히 필요로하는 데이터를 제공할 수 있습니다.
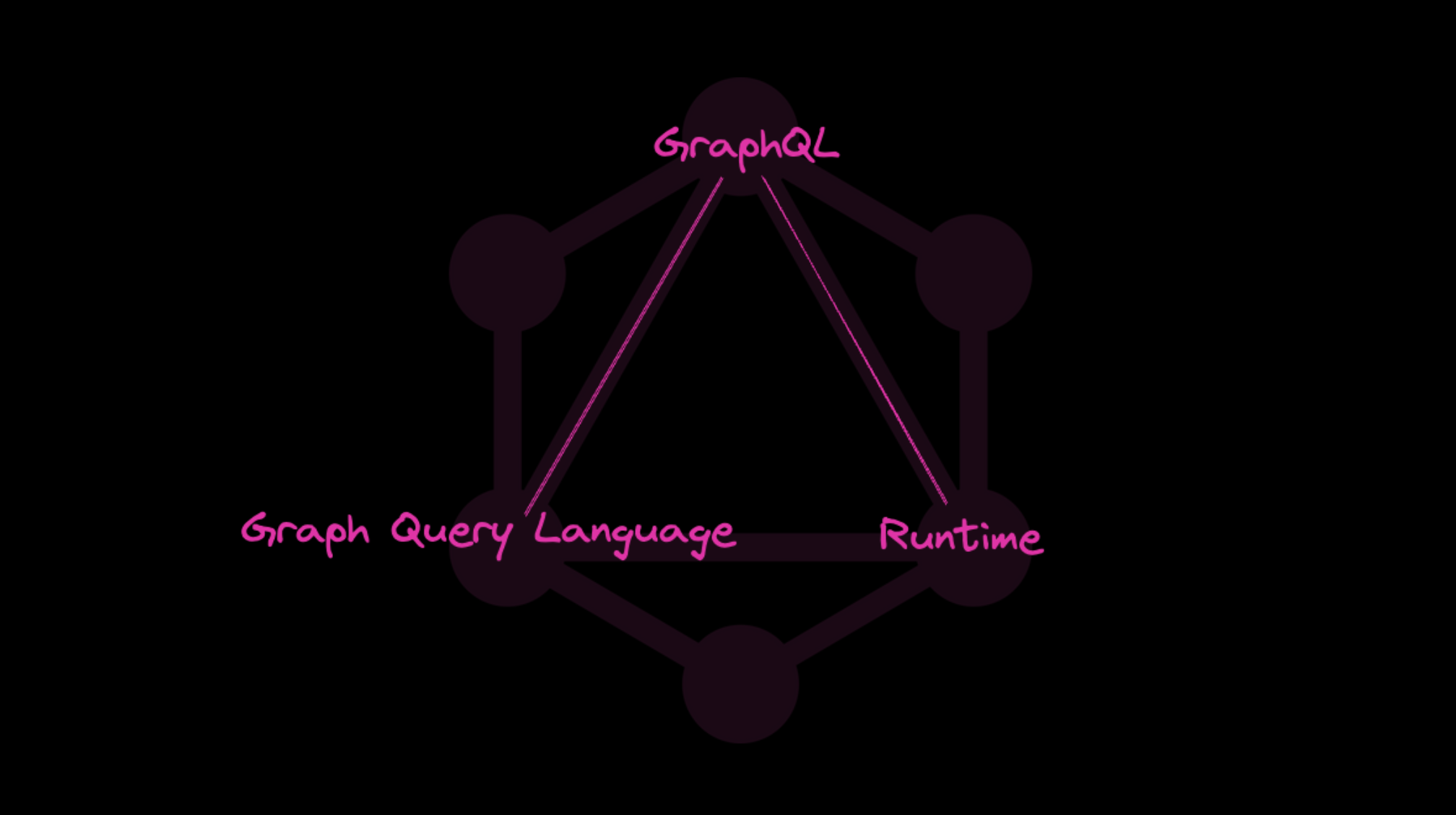
GraphQL은 두가지 의미로 해석될 수 있습니다.
- GraphQL은 API를 위한
Query Language이다. - GraphQL은 서버사이드에서 실행되는 쿼리를 해석하는
Runtime이다.

Query Language는 데이터베이스 또는 데이터 관리 시스템에 접근하기 위한 언어로 대표적으로 SQL을 들 수 있습니다.
SQL이 데이터베이스에 질의를 하는 언어인 반면에, GQL은 클라이언트에서 API에게 질의를 하는 언어입니다.
따라서 GraphQL은 데이터베이스의 종류에 구애받지 않고 API가 사용되는 모든 컨텍스트에서 효과적으로 사용할 수 있습니다.
GraphQL은 백엔드 입장에서 구현돼야할 Runtime이기도 합니다.
API 사용자는 GraphQL 언어를 사용해서 필요한 데이터를 정확하게 요구하기 위한 텍스트를 구성하고 클라이언트는 이 텍스트 요청을 전송채널(예:HTTPS)를 통해 API 서비스에 전달합니다. 그러면 GraphQL Runtime 계층이 이 텍스트 요청을 받아서 백엔드에 있는 다른 서비스들과 커뮤니케이션하고 그 결과들을 모아서 적합한 데이터를 만듭니다. 그렇게 만들어진 데이터를 JSON과 같은 형식으로 API 사용자에게 반환하는 것 입니다.
GraphQL vs REST
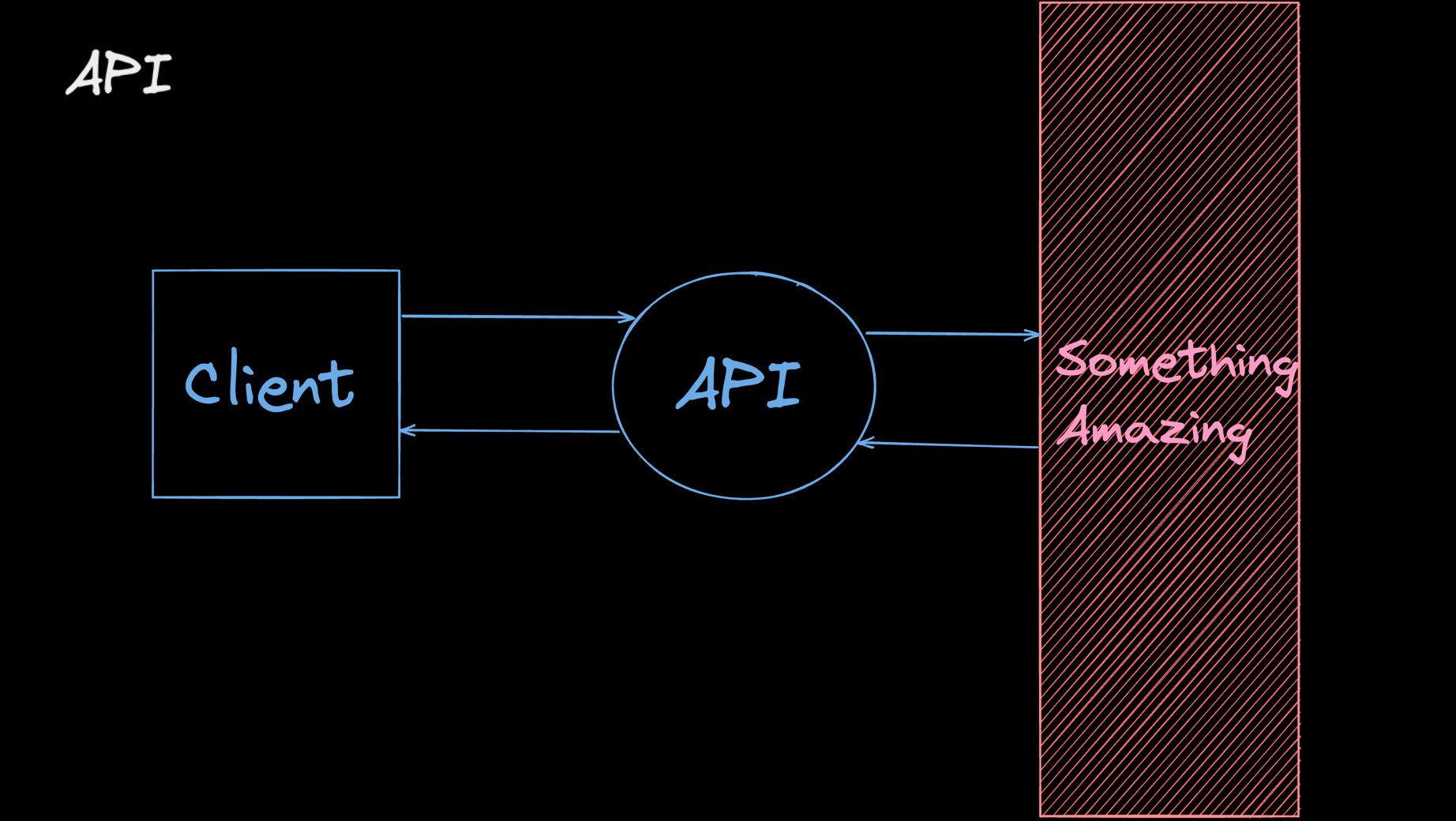
API는 데이터가 데이터베이스에서 애플리케이션으로 흐르는 인터페이스를 제공합니다.
즉, API의 사용자는 서버가 어떤 언어로 만들어져있는지, 데이터베이스는 어떤 것을 쓰는지 신경쓸 필요가 없고 우리가 중요하다고 생각하는 것에 집중할 수 있도록 도와줍니다.

현대의 많은 애플리케이션은 REST API로 구성되어있습니다. REST 형식의 API는 URL 구조와 쿼리 매개변수를 사용하여 서버에 요청합니다.
REST API는 URL과 요청 METHOD를 조합하기 때문에 다양한 Endpoint가 존재합니다.
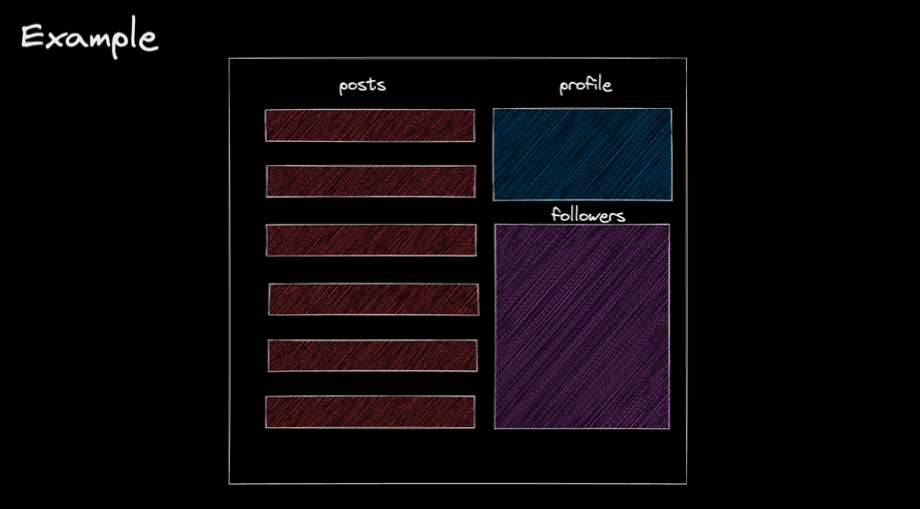
블로그 애플리케이션을 렌더링하는 것을 예로 들어보겠습니다.
블로그 애플리케이션은 크게 Posts, Profile, Followers 컴포넌트로 이루어져 있고 각각은 하나의 REST API Endpoint에 매핑됩니다.
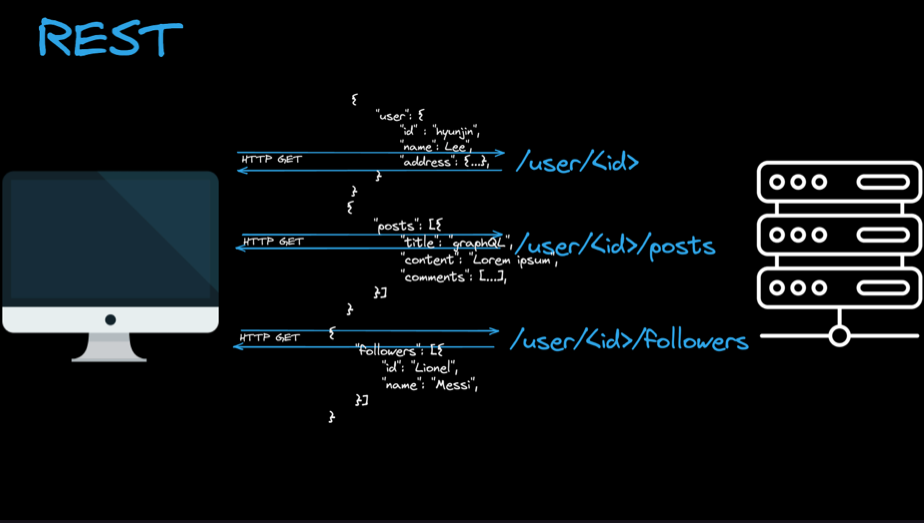
REST API에서는 URL이 자원을 나타내기 때문에 세가지 각기 다른 네트워크 요청을 보내야만 자원을 가져올 수 있습니다.
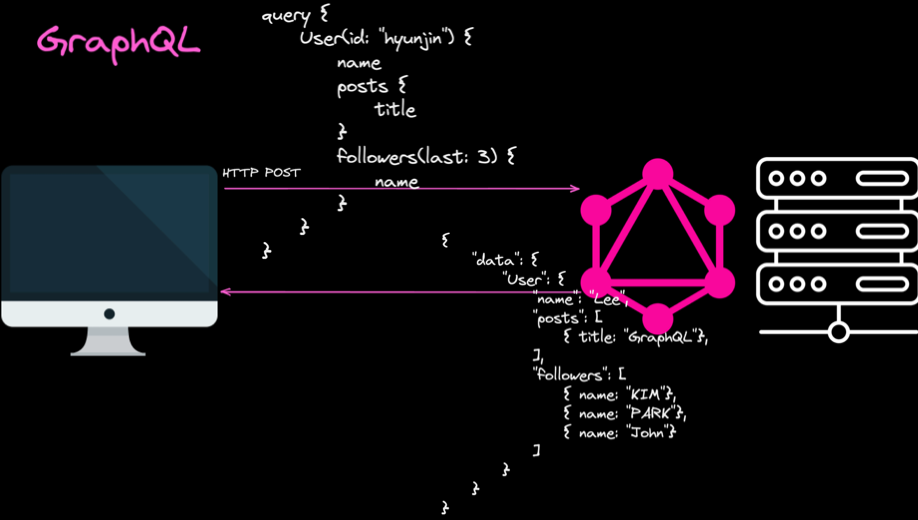
반면 GraphQL은 이 3개의 네트워크 요청을 단 하나의 요청으로 통합할 수 있습니다.
왼쪽 위가 GraphQL로 작성한 쿼리문이고 오른쪽 아래가 응답 데이터입니다.

GraphQL 쿼리와 응답 내용의 구조는 상당히 직관적입니다. 요청하는 쿼리문의 구조와 응답의 구조는 거의 일치합니다.
또한 user와 연결되어있는 posts와 followers 같은 리소스들을 하나의 요청으로 처리할 수 있습니다.
이런 GraphQL의 특징을 선언적 data fetching이라고 합니다.
자신이 선언한 쿼리 내용대로 데이터를 받아올 수 있습니다.
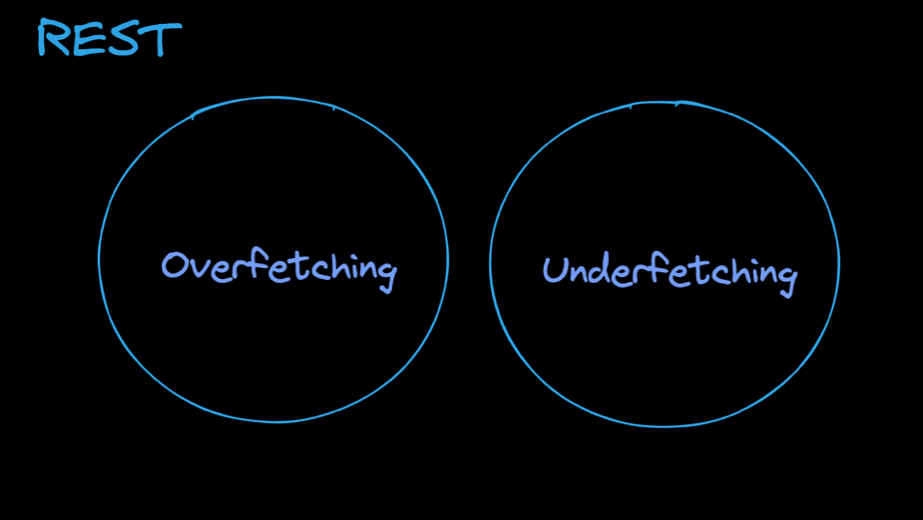
예제를 통해 알 수 있는 REST API의 문제는 두가지입니다.
첫째, Overfetching. REST API의 특성상 데이터를 주고받을 때 클라이언트에서 활용하지 않는 필요없는 데이터까지 주고받을 확률이 높습니다. 따라서 이는 불필요한 리소스 낭비를 초래합니다.
둘째, Underfetching. 필요한 데이터를 만들기 위해 여러번의 API 호출이 필요합니다.
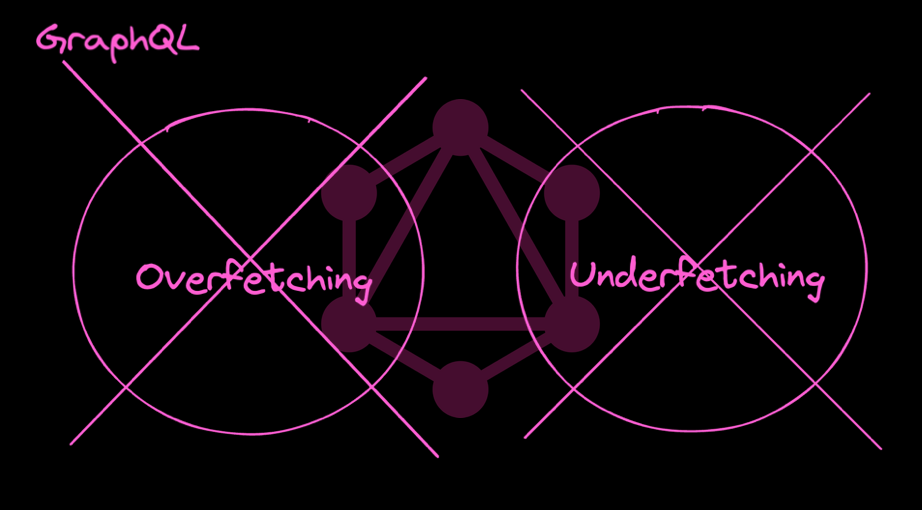
이를 통해 GraphQL이 가지는 이점은 명확합니다.
여러개의 엔드포인트가 아닌 하나의 엔드포인트를 만들고 한번의 요청으로 원하는 정보만를 얻는다. 즉 Overfetching과 Underfetching 문제를 해결한다.

예시를 통해 GraphQL과 REST를 비교해보면 글의 초반부에 소개드렸던 REST API의 문제점 두가지를 해결해준다는 것을 알 수 있습니다.
- 효율적인 데이터 로딩이 필요 -> 한번의 요청으로 원하는 데이터만 받아옴.
- 다양한 플랫폼 지원 -> 원하는 데이터의 형식을 클라이언트 측에서 결정할 수 있음.

마지막 문제인 Communication 문제는 어떻게 해결할까요?
REST API의 문제였던 프론트엔드와 백엔드의 커뮤니케이션 비용 문제를 GraphQL이 어떻게 해결하는지 알아보겠습니다.

보통 REST API는 서버에서 데이터를 내려준대로 활용합니다.(Fixed Data Structures)
신기한 점은 GraphQL은 클라이언트에서 가져올 데이터를 선언할 수 있다는 점입니다.
어떻게 선언적으로 데이터를 가져올 수 있을까요?
데이터의 구조가 정해져 있다면 가능합니다.
Schema, Resolver
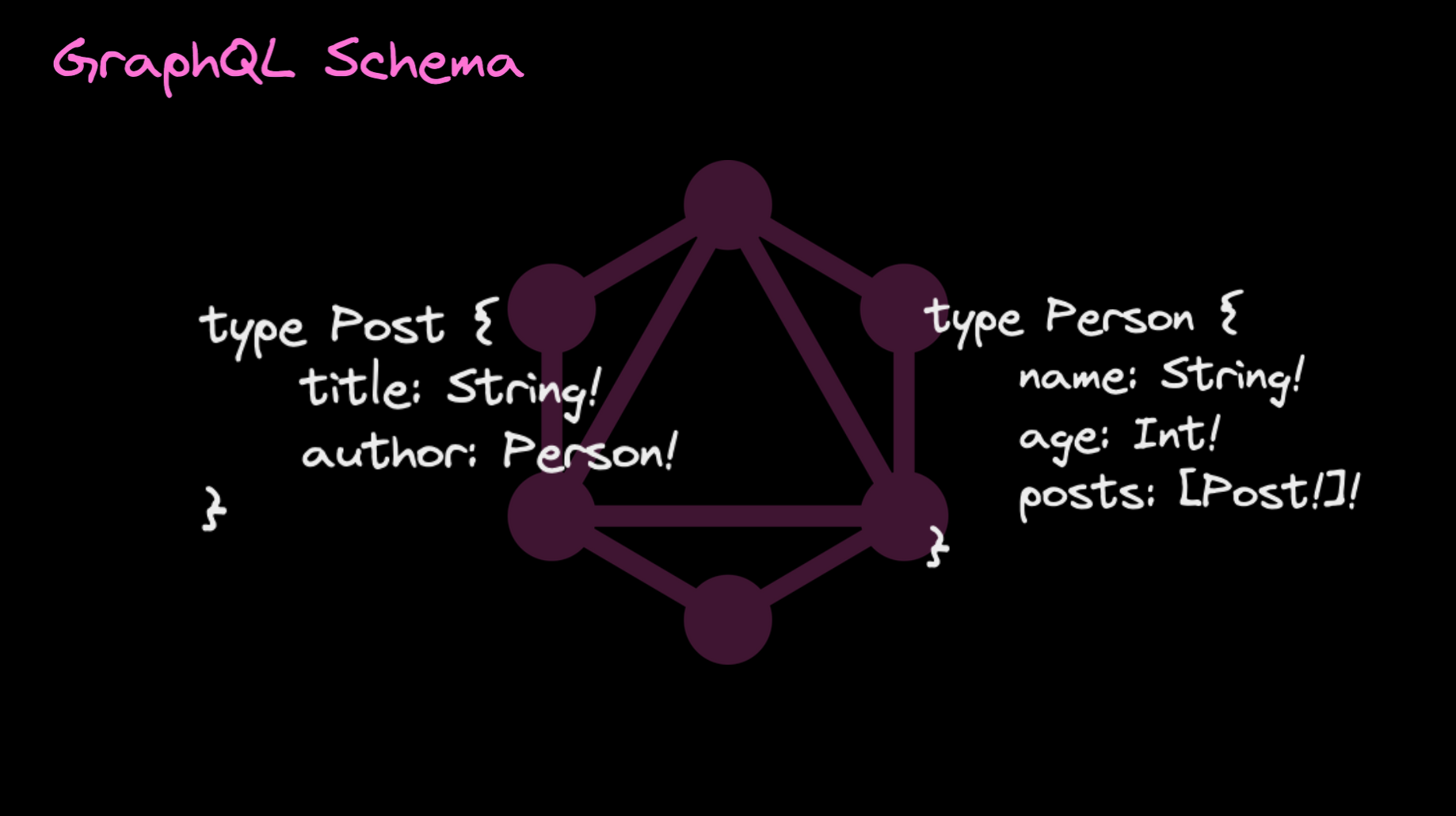
이 구조를 GraphQL에서는 스키마(schema)라고 합니다.
스키마는 API가 무엇을 할 수 있는지 기술한 것이기 때문에 GraphQL 클라이언트는 이 스키마를 통해 서비스에 어떻게 요청할지 알 수 있습니다.
스키마는 타입을 가진 필드를 그래프로 나타낸 것이며 이 그래프는 데이터 서비스를 통해 읽고 수정할 수 있는 모든 객체를 보여줍니다.

GraphQL은 프론트엔드 팀과 백엔드 팀이 스키마를 같이 정의하는 것으로 커뮤니케이션 비용을 줄입니다.
프론트엔드 팀과 백엔드 팀이 회의실에 앉아서 스키마에 대해 토의하고 무엇이 필요한지 정의합니다. 서로 스키마를 공유한다면 더이상의 커뮤니케이션은 필요하지 않습니다.

회의가 끝나면 백엔드 팀은 resolver(이하 리졸버)를 정의하는 것을 통해 같이 정의한 스키마를 충족시킵니다.
리졸버 함수는 GraphQL의 뒤에서 움직이는 대부분의 처리 로직으로 스키마의 각 필드는 리졸버 함수와 연동되며, 리졸버 함수에는 각 필드가 어떤 값을 가져와야하는지 정의합니다.

정리를 해보면, 프론트엔드팀과 백엔드팀이 먼저 스키마를 정의한 후 백엔드 팀은 그 데이터를 가져오기 위한 리졸버 함수를 정의합니다.
이후 클라이언트에서 GraphQL 언어로 텍스트 형태로 필요한 데이터를 요청하면 백엔드에서 구현된 GraphQL Runtime이 요청을 해석하여 클라이언트가 원하는 데이터를 내려줍니다.
Github API를 이용한 실습

Github는 2017년까지 REST API를 사용하다가 GraphQL로 변경했습니다.
이 실습에서는 GraphQL을 사용해서 제가 만든 이슈에 댓글을 달아보는 것을 해보도록 하겠습니다.
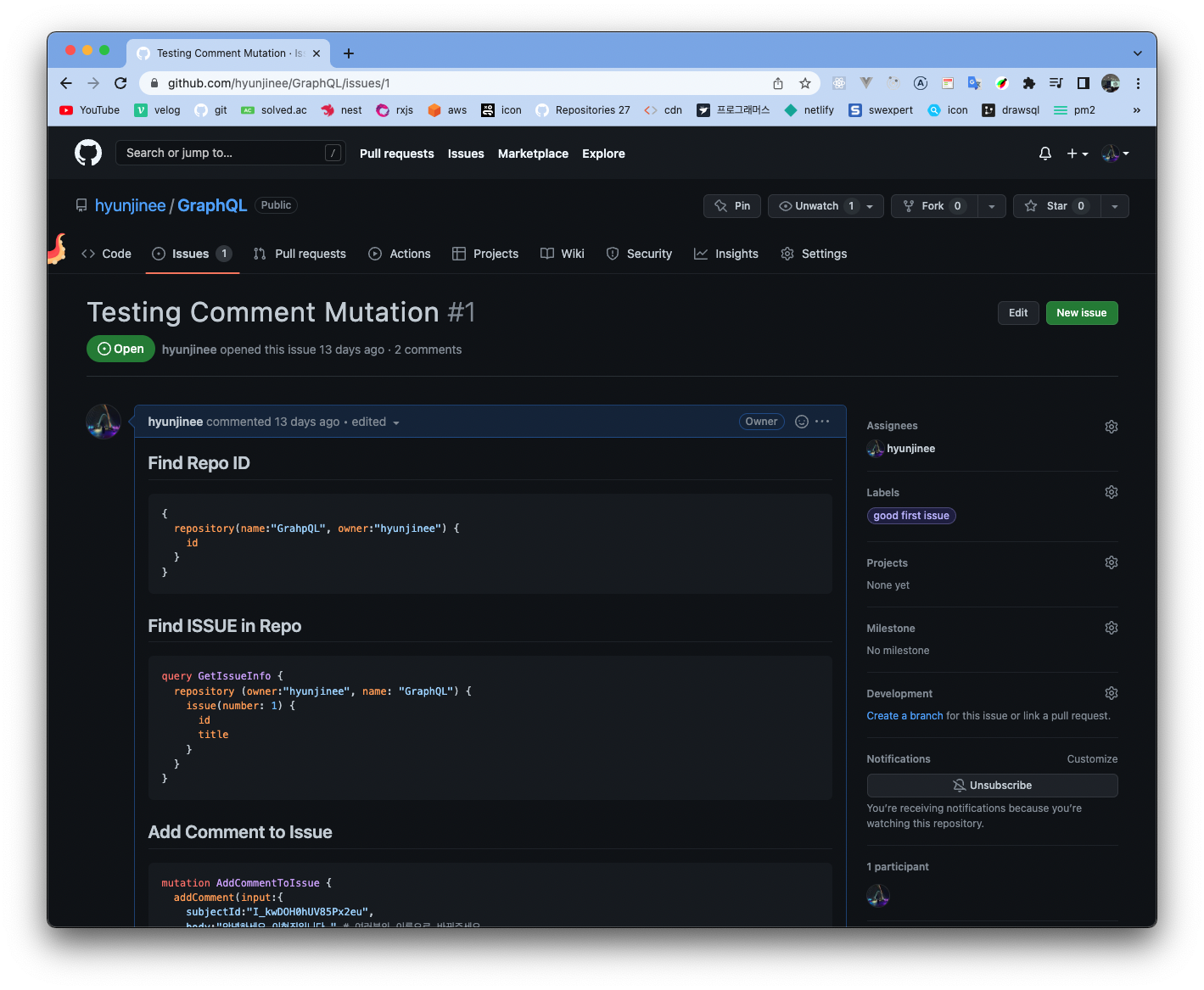
제가 미리 테스트 이슈를 한개 만들어 놓았고, 이 이슈에 GraphQL을 사용하여 댓글을 달아보겠습니다.
아래 링크에 접속한 후 Github 계정으로 로그인 해주세요.
https://docs.github.com/en/graphql/overview/explorer
mutation AddCommentToIssue {
addComment(input:{
subjectId:"I_kwDOH0hUV85Px2eu",
body:"안녕하세요 이현진입니다." # 여러분의 이름으로 바꿔주세요
}) {
commentEdge {
node {
createdAt
}
}
}
}위 코드를 복사해서 붙여넣은 후 이름을 바꿔주고 실행해주세요.
이제 실제로 댓글이 잘 작성되었는지 확인하기 위해 아래 링크에 접속해서 확인해보세요.
https://github.com/hyunjinee/GraphQL/issues/1
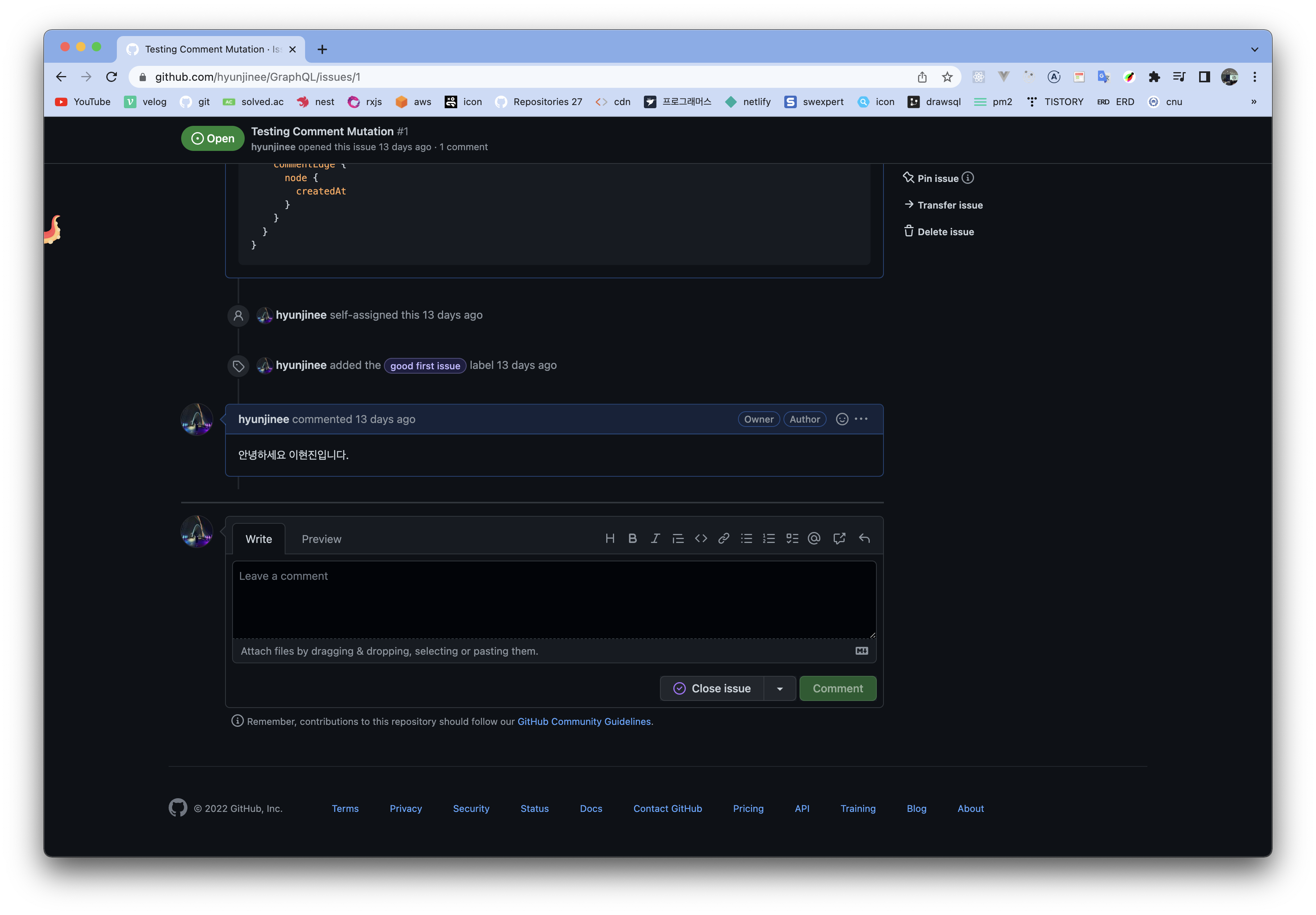
위와 같이 댓글이 잘 작성된 것을 볼 수 있습니다.
GraphQL in React
마지막으로 GraphQL이 React에서 어떤 문제를 해결했는지 알아보겠습니다.
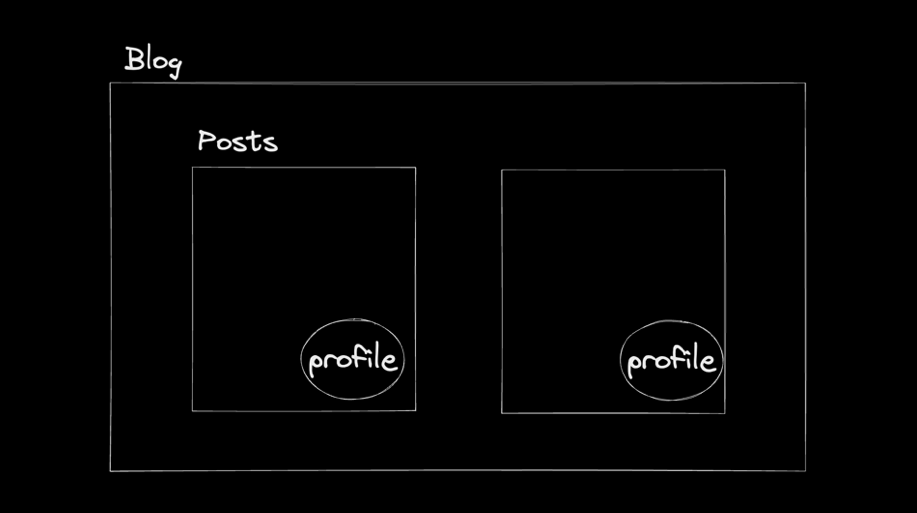
위와같은 블로그 애플리케이션의 구조에서 Posts 컴포넌트와 Profile 컴포넌트 모두 데이터를 불러오는 코드를 갖는 컴포넌트라고 가정해보겠습니다.
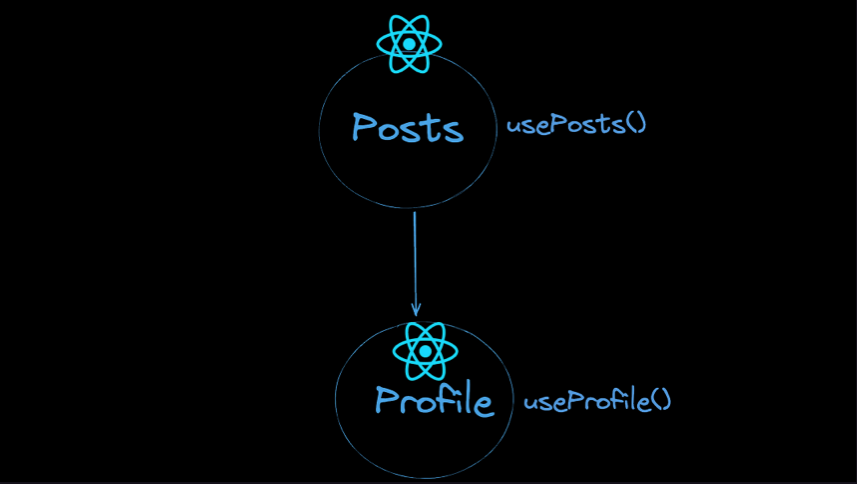
추상화 해서 나타내보면 Posts가 상위 컴포넌트이고 Profile이 하위 컴포넌트이며 각각 데이터를 불러오는 코드를 가지고 있습니다.

Posts와 Profile은 계층 구조를 가지므로 Profile 컴포넌트는 Posts 컴포넌트가 렌더링이 된 이후에야 데이터 fetching을 시작할 수 있습니다. 위 그림을 보면 Posts는 렌더링이 되었지만 Profile은 데이터 fetching을 시작조차 하지 않은 모습을 볼 수 있습니다.
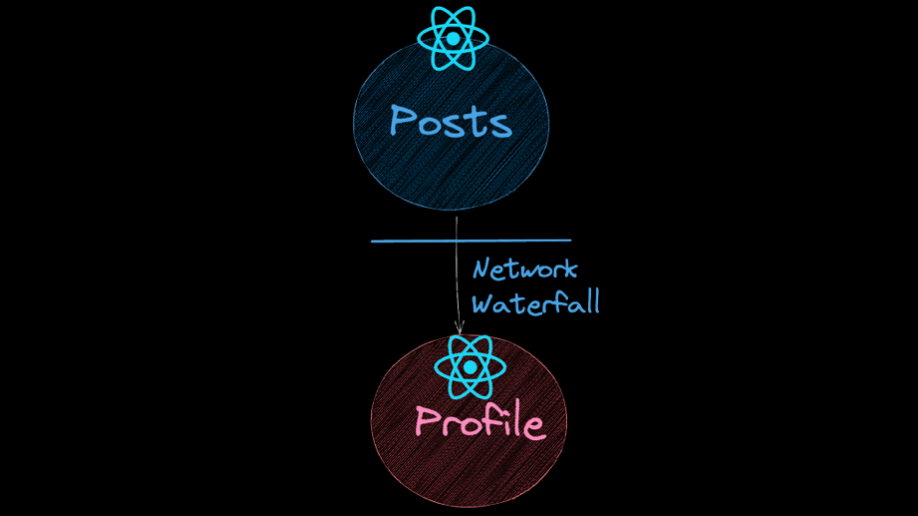
이런 현상을 Network Waterfall이라고 합니다.
물론 동시에 요청을 보낼 수 있겠지만 데이터를 가져오는 코드가 컴포넌트와 의존성을 가지므로 동시에 요청을 보내는 것 자체가 불가능합니다.
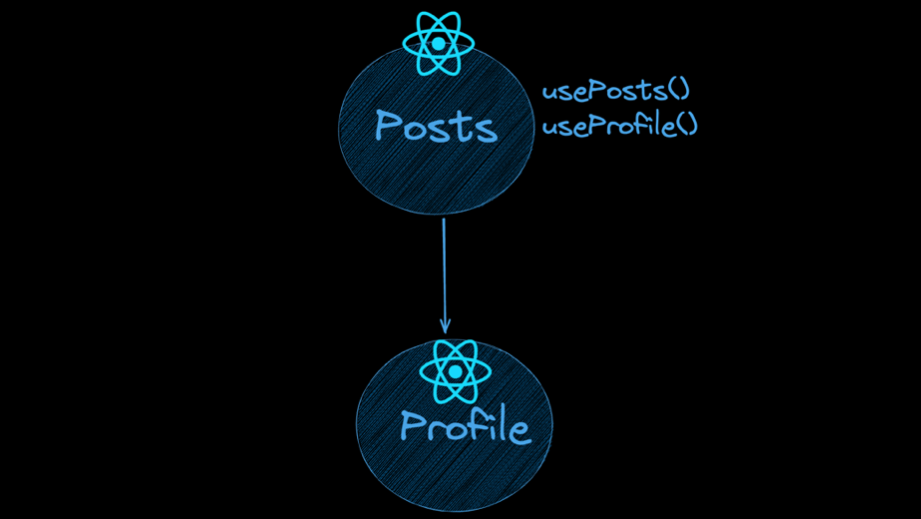
물론 위와 같이 데이터를 가져오는 로직을 상위 컴포넌트로 옮기고 props drilling을 하면 해결할 수 있습니다. 하지만 하위 컴포넌트가 여러개라면 상위 컴포넌트가 점점 복잡해질 것입니다.
무엇이든 복잡한 것을 만들 때는 작은 부분(컴포넌트)으로 나누어 한번에 한 부분만 집중하는 것은 좋은 접근법 입니다. 작은 부분들은 가능하면 서로 의존하지 않게 독립적으로 설계해야 바람직하며, 각 부분별로 테스트 및 재사용이 가능해야합니다.
GraphQL에서는 각 컴포넌트에 대응하는 데이터를 fragment로 정의할 수 있습니다.
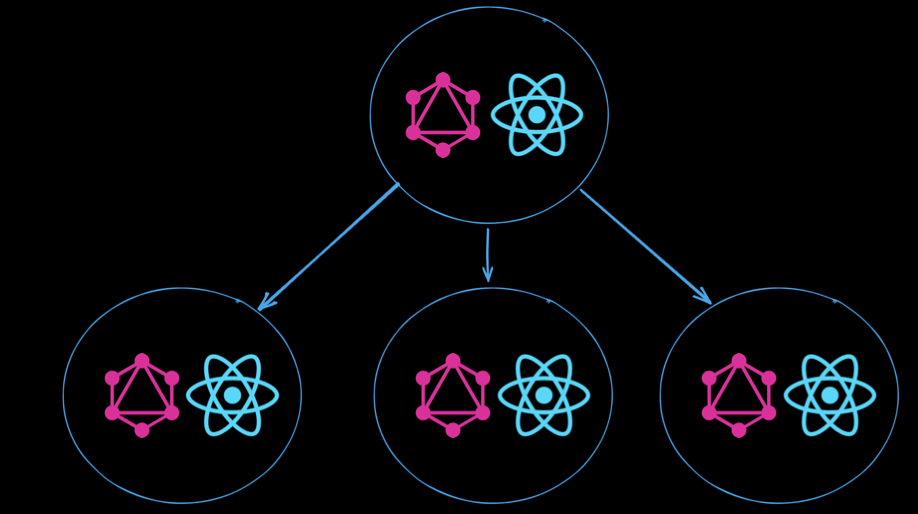
컴포넌트의 구조를 위와 같이 표현하고 각 컴포넌트가 필요로 하는 데이터 구조를 fragment로 표현합니다.
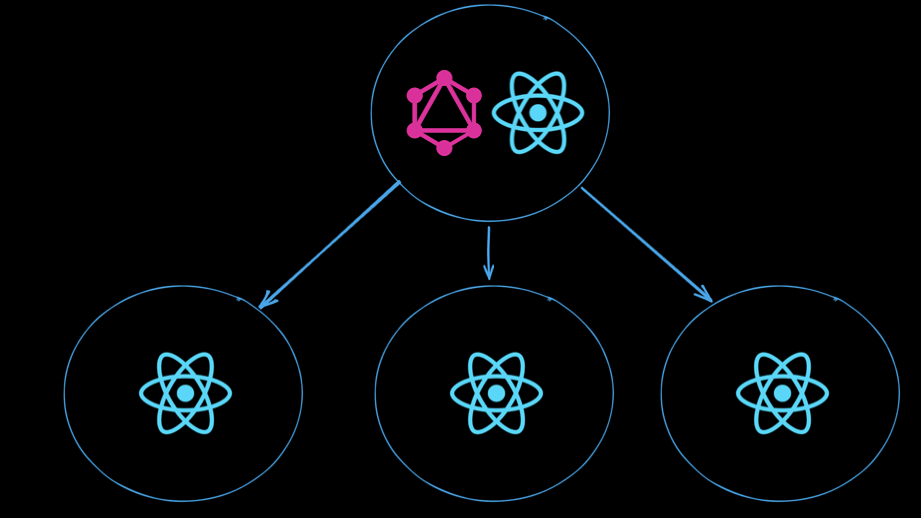
이제 각 fragment들을 최상위 컴포넌트의 쿼리에 모두 배치시키고 GraphQL의 이점을 살려 단 한번의 쿼리로 모든 데이터를 받아옵니다.
이렇게 함으로써 애플리케이션 내에서 데이터흐름을 추적하기 쉬워지며 Network Waterfall 현상도 해결할 수 있습니다.
마치며
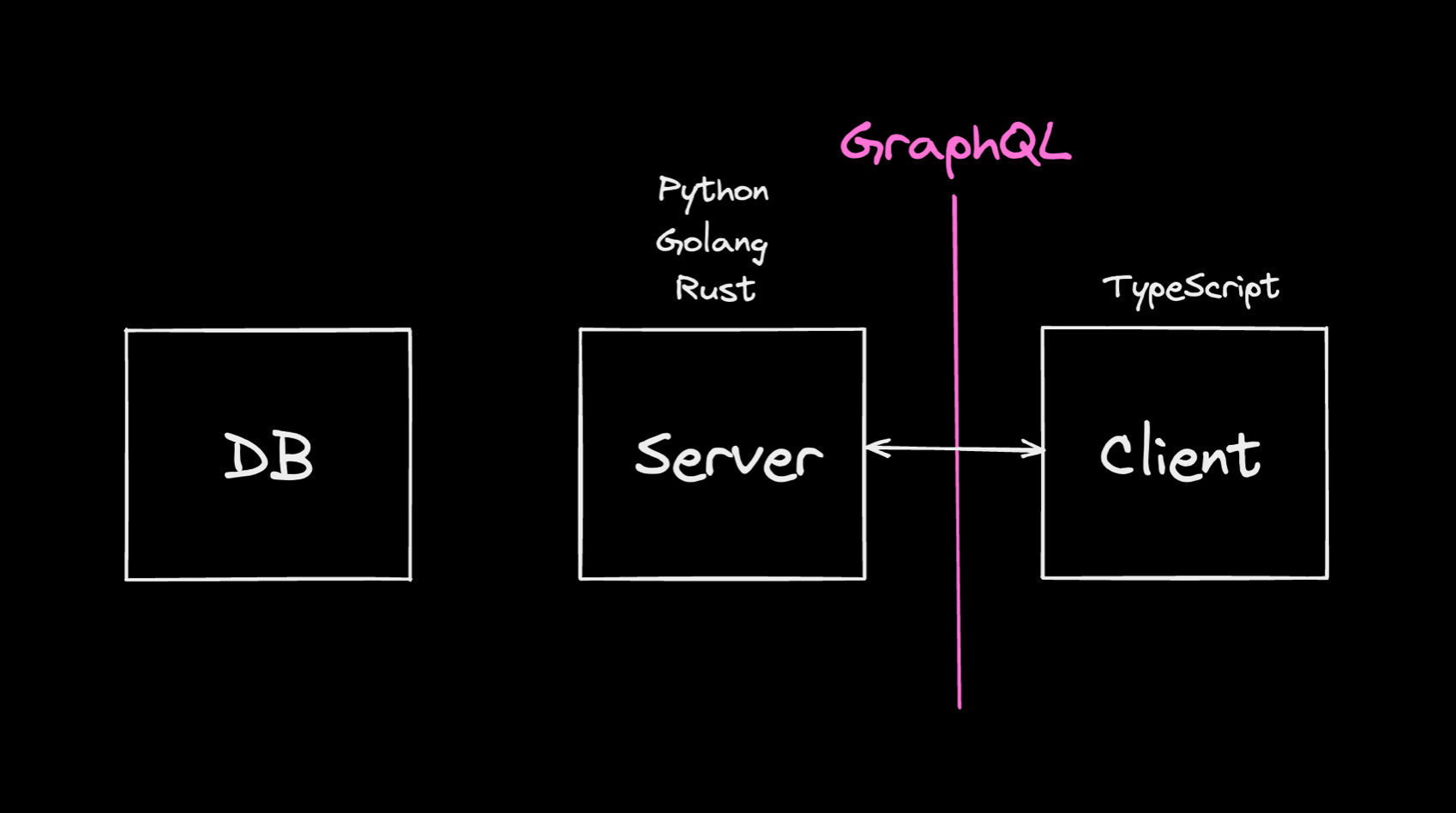
GraphQL은 클라이언트에서 서버에 질의를 하기 위한 언어입니다.
GraphQL은 SQL의 경쟁 상대가 아니며, SQL 처럼 데이터베이스에 쿼리를 하기 위해 사용해서는 안됩니다.
GraphQL는 스키마를 정의하여 클라이언트와 서버가 대화할 수 있게 해줍니다.
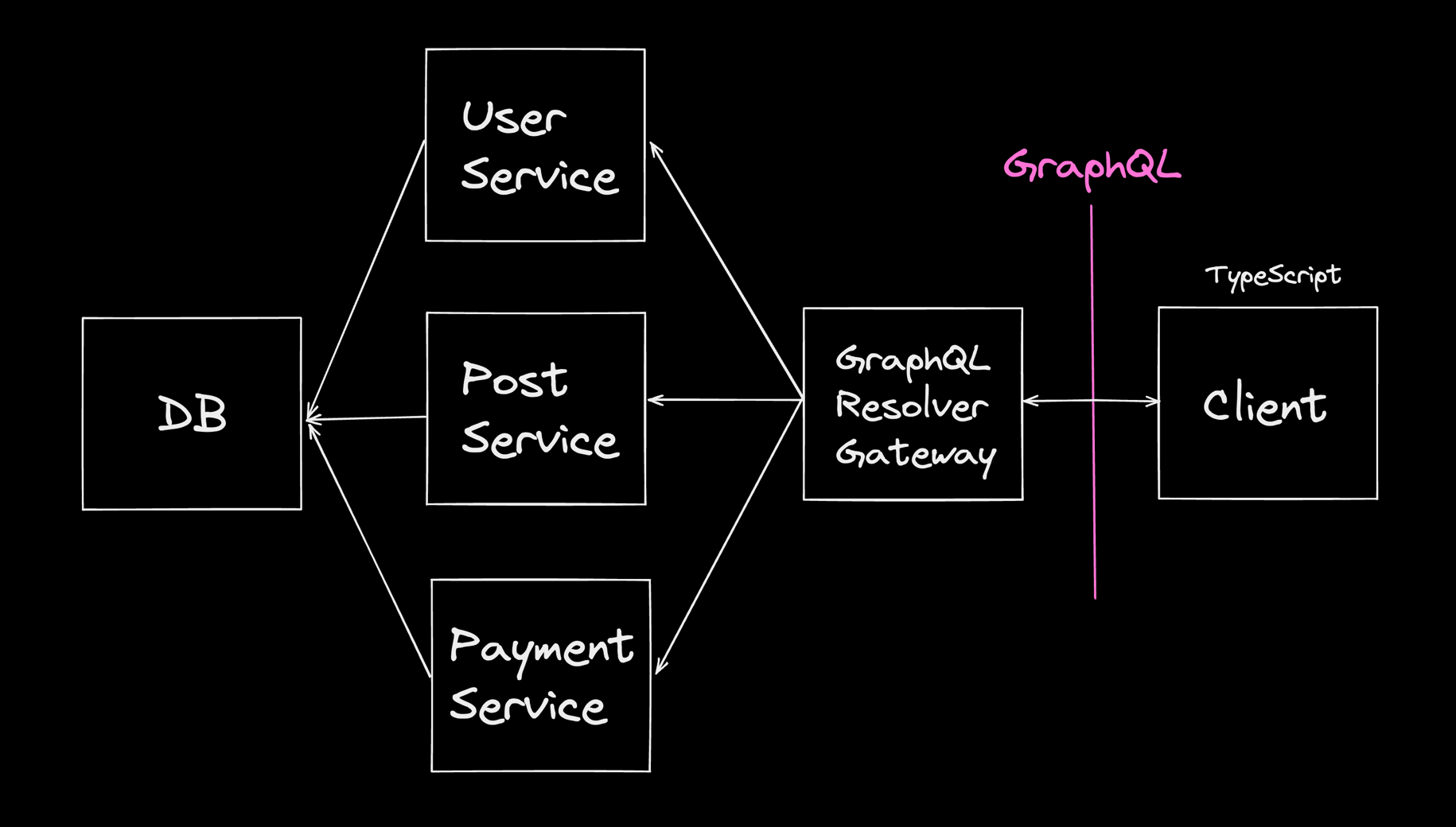
만약 백엔드가 다양한 언어로 구성된 여러 서비스로 되어있다면, 리졸버가 여러 서비스와 대화하여 데이터를 가져올 수 있습니다.
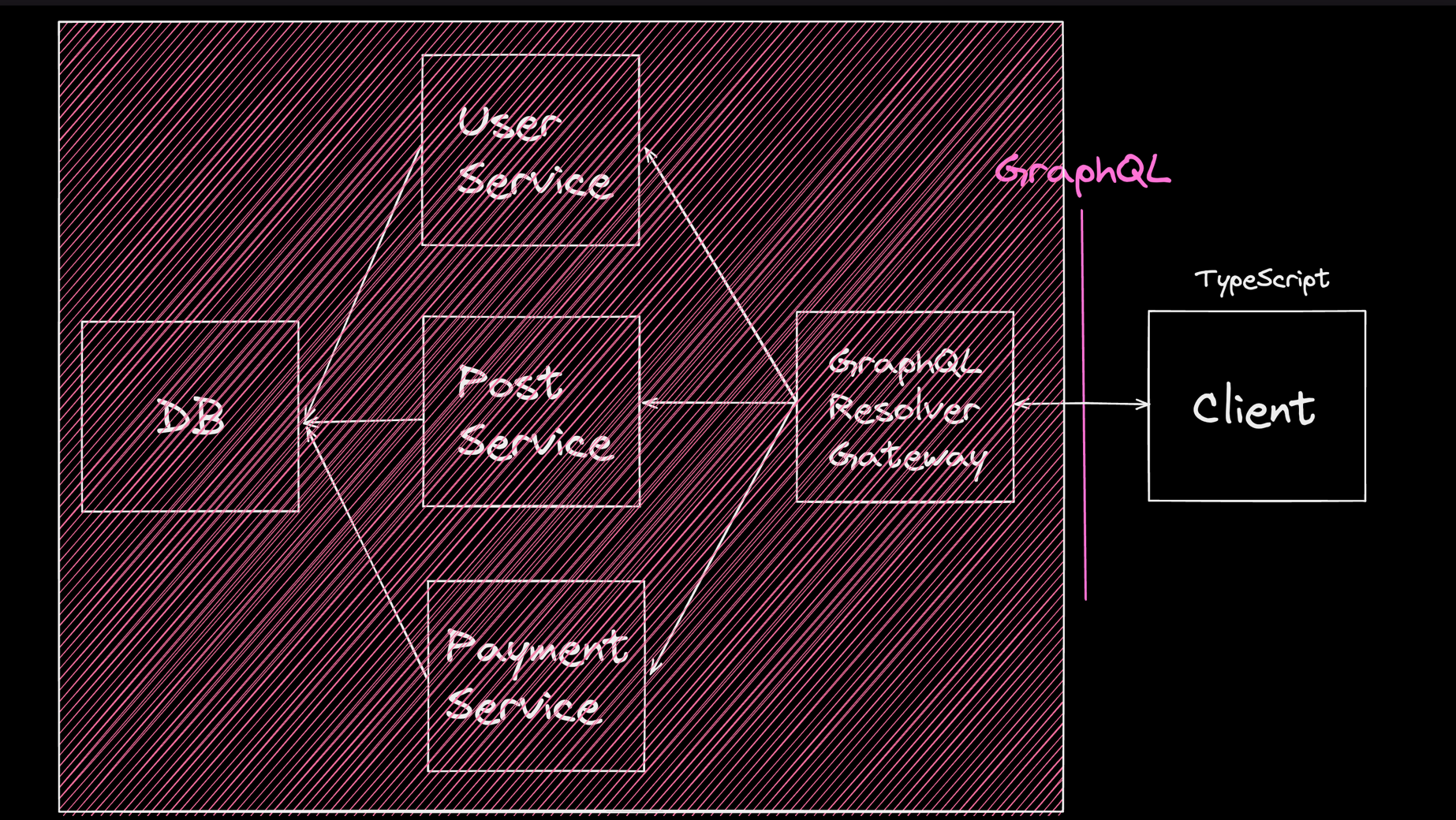
GraphQL의 아름다움은 프론트엔드 개발자가 백엔드를 보지 않아도 된다는 것 입니다. 프론트엔드 개발자는 스키마가 정의되면 백엔드 개발자가 어떻게 개발하든 신경쓰지 않아도 됩니다.
이것이 GraphQL의 의도입니다.

GraphQL은 API를 위한 쿼리언어이며, 동시에 런타임이기도 합니다. GraphQL은 스키마를 통해 API에 있는 데이터에 대한 완벽하고 이해하기 쉬운 설명을 제공하고 리졸버를 통해 원하는 필드에 원하는 데이터를 충족시킬 수 있습니다. 또한, 시간이 지남에 따라 API를 쉽게 진화시킬 수 있고 강력한 개발자 도구를 지원합니다.
데이터들을 엔드포인트에 대응되는 것이 아닌 서로 그래프처럼 연결되어있다고 생각해보면 어떨까요?
Think in graphs, not endpoints.
Reference
- How to GraphQL
- GraphQL in Action. Samer Buna
- Data Flows in React
- 컴포넌트, 다시 생각하기
- GraphQL Docs
- Apollo Docs
- GraphQL 기초 톺아보기
- GraphQL 개념잡기
- 발표 Repo


정말 유익한 글이네요 감사합니다!