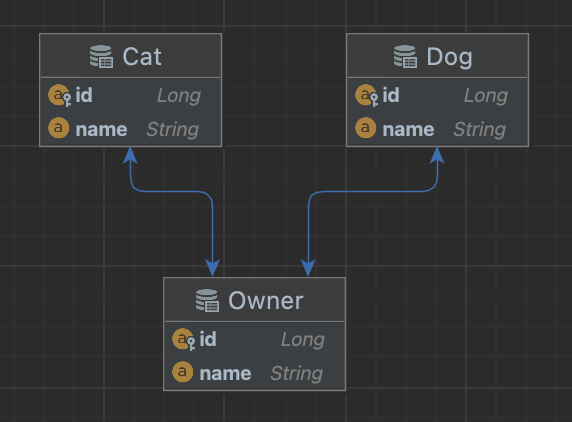
N+1 문제
JPA를 이용한다면 한번씩 마주보게되는 N+1문제를 다뤄볼 예정이다.
N+1 문제란
객체를 데이터베이스에서 불러올 때 1개의 쿼리가 아닌 연관관계 객체를 불러오기 위한 N개의 쿼리가 생성되는 문제이다.
예시로 보일 Entity는 아래와 같다.
@Entity
public class Owner {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
private List<Cat> cats = new ArrayList<>();
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
private List<Dog> dogs = new ArrayList<>();
//...
}@Entity
public class Cat {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
String name;
@ManyToOne(fetch = FetchType.EAGER)
Owner owner;
//...
}@Entity
public class Dog {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
private Owner owner;
public Dog(String name){
this.name = name;
}
//...
}즉시로딩
Owner
@Entity
public class Owner{
//...
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private List<Cat> cats = new ArrayList<>();
//...
}테스트코드
public class OwnerRepositoryTest{
@Autowired
OwnerRepository ownerRepository;
@Autowired
CatRepository ownerRepository;
@BeforeEach
public void setUp(){
List<Owner> owners = new ArrayList<>();
for(int i=0;i<10;i++){
Owner owner = new Owner("집사"+i);
owner.setCat(new Cat("고양이"+i));
owners.add(owner);
}
ownerRepository.saveAll(owners);
em.clear();
}
@Test
@Transactional
public void getCats(){
System.out.println("start============================================");
Owner findOwner = ownerRepository.findById(1L).orElseThrow(RuntimeException::new);
System.out.println("end==============================================");
System.out.println(findOwner.getCats().size());
}
}
결과
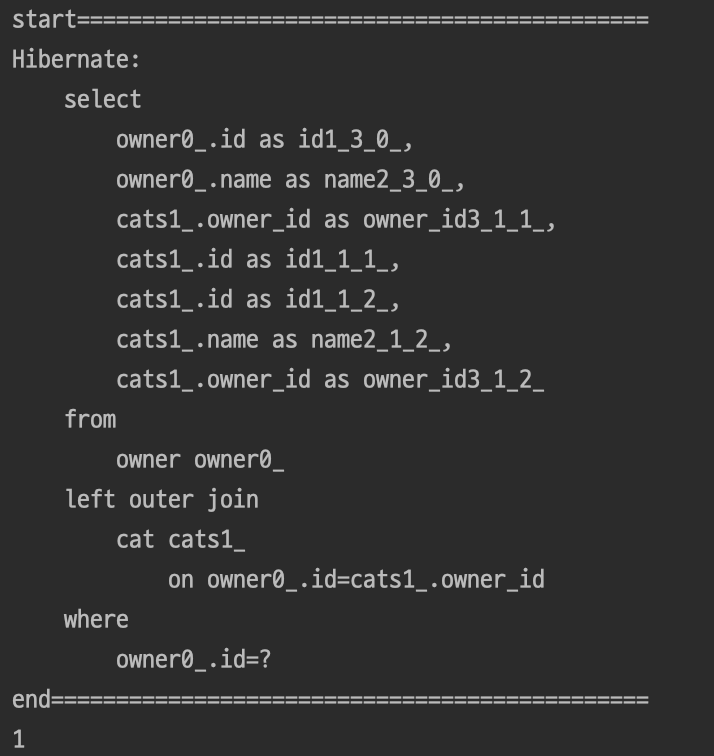
JPA에서 제공하는 findById()와 같은 메소드는 EntityManager에서 id을 가지고 객체를 조회하는 JPQL을 생성한다. 이때 연관관계 객체가 즉시로딩으로 되어 있을 때 Join절을 이용해 1개의 쿼리를 생성하여 연관관계 객체를 가져오게된다.
하지만 문제는 JPQL을 만들때 발생한다. findAll()과 같은 메소드를 사용할 때 JPA는 전체 Owner를 조회하는 SELECT * FROM OWNER 쿼리를 생성하게 될것이고 연관관계를 가져올수 없게 된다. 그렇기 때문에 연관관계를 가져오기 위한 또 다른 SELECT 쿼리를 생성하게 되고 OWNER의 개수만큼 연관관계를 가져와야하기 때문에 OWNER 개수만큼 SELECT 쿼리가 생성된다.
@BeforeEatch
public void setUp(){
List<Owner> owners = new ArrayList<>();
for(int i=0;i<10;i++){
Owner owner = new Owner("집사"+i);
owner.setCat(new Cat("고양이"+i));
owners.add(owner);
System.out.println(owner.getName()+"의 고양이 개수 : "+owner.getCats().size());
}
ownerRepository.saveAll(owners);
em.clear();
}
@Test
@Transactional
public void getCats(){
System.out.println("start============================================");
List<Owner> findOwner = ownerRepository.findAll();
System.out.println("end==============================================");
System.out.println("주인 수 : "+findOwner.size());
} 결과
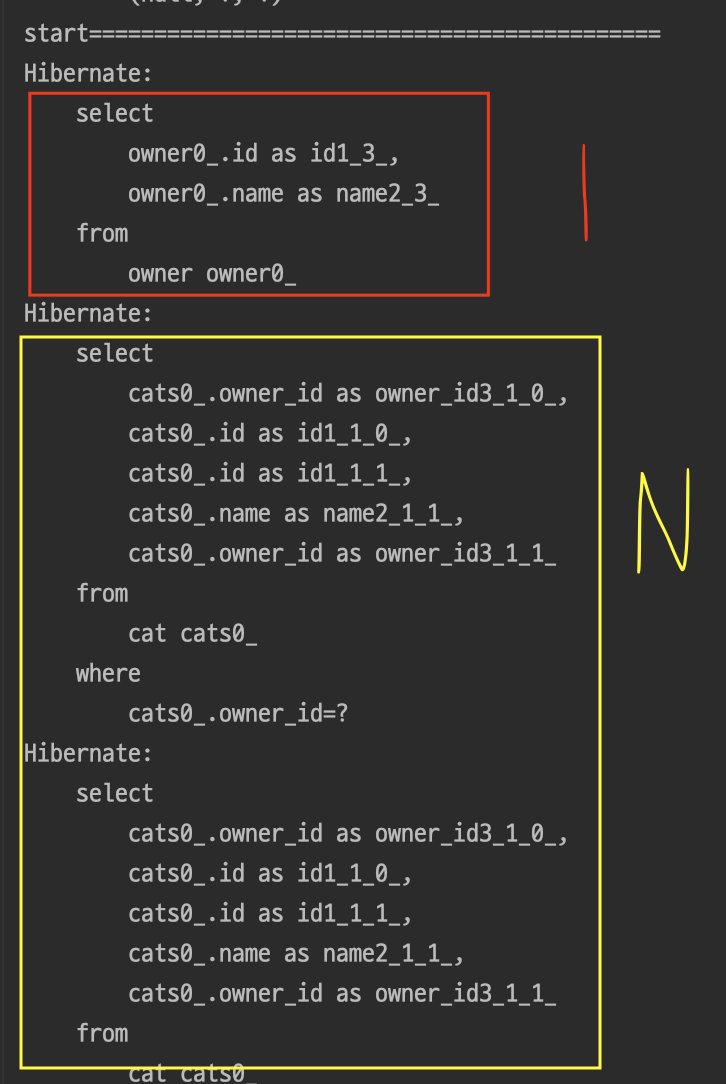
즉, Owner를 가져오기 위한 SELECT쿼리(1)과 Owner만큼의 연관관계를 조회하기 위한 SELECT쿼리(N)이 데이터베이스에 요청되게 된다.
이것이 N+1문제이다.
마찬가지로 findByName()과 같은 쿼리메소드는 Join문을 지원해주지 않는다.
지연로딩
즉시로딩이 아닌 지연로딩에서는 어떻게 동작할까?
Owner
@Entity
public class Owner{
//...
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List<Cat> cats = new ArrayList<>();
//...
}테스트 코드
@Test
@Transactional
public void getCats(){
System.out.println("start============================================");
Owner findOwner = ownerRepository.findById(1L).orElseThrow(RuntimeException::new);
System.out.println("end==============================================");
System.out.println(findOwner.getCats().size());
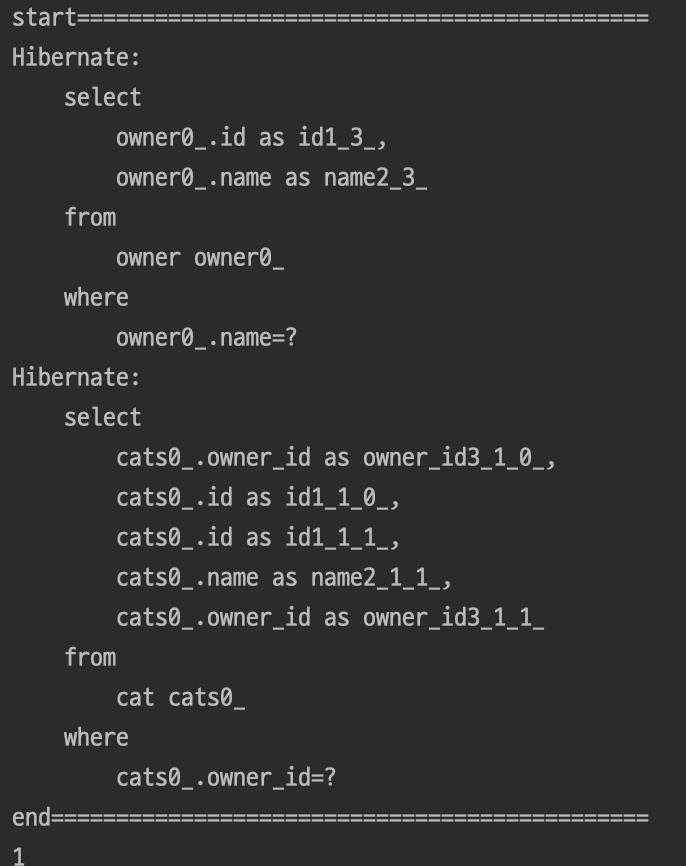
} 결과
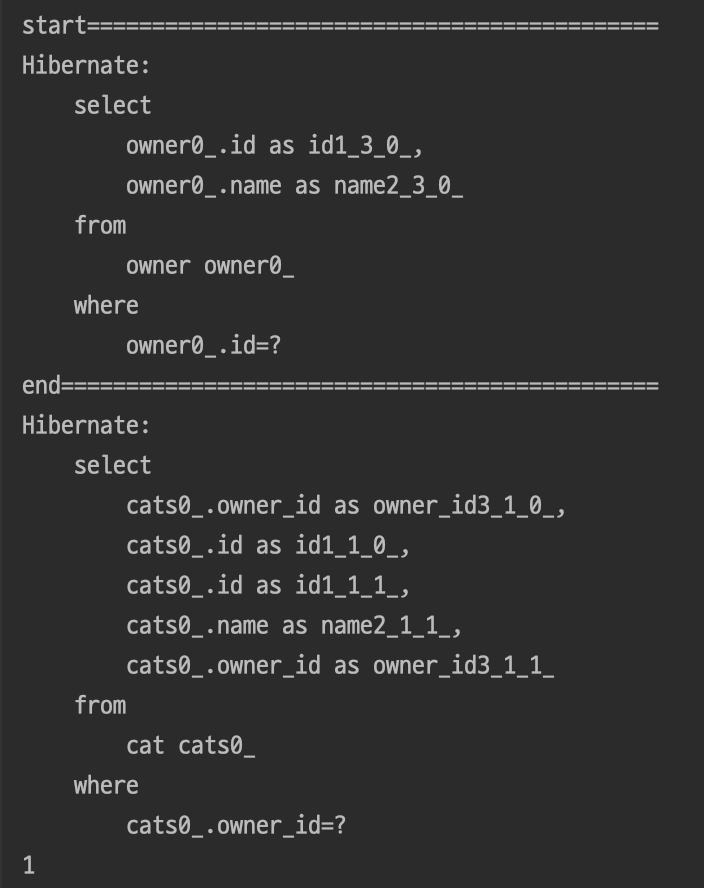
지연로딩시 동일하게 findById()메소드를 사용했음에도 Join문이 적용되지 않고 연관관계 객체를 사용하는 시점에 새로운 쿼리가 발생하게 된다.
지연로딩에는 findById()에 Join문이 적용되지 않을까?
지연로딩을 사용하게 되면 연관관계는프록시 객체이기 때문에 연관관계 객체를 사용할때 JPA가 데이터베이스에서 연관관계를 조회하기 위한 SELECT 쿼리를 생성하기 때문이다.
Owner가 N개라면?
테스트 코드
@BeforeEach
public void setUp(){
List<Owner> owners = new ArrayList<>();
for(int i=0;i<10;i++){
Owner owner = new Owner("집사"+i);
owner.setCat(new Cat("고양이"+i));
owners.add(owner);
System.out.println(owner.getName()+"의 고양이 개수 : "+owner.getCats().size());
}
ownerRepository.saveAll(owners);
em.clear();
}
@Test
@Transactional
public void getCats(){
System.out.println("start============================================");
List<Owner> findOwner = ownerRepository.findAll();
System.out.println("end==============================================");
System.out.println("주인 수 : "+findOwner.size());
for(Owner o : findOwner){
System.out.println("주인 이름 : "+o.getName());
System.out.println("고양이 개수 : "+o.getCats().size());
List<Cat> catList = o.getCats();
System.out.println("고양이 꺼내기");
for(Cat cat : catList){
System.out.println("고양이 이름 : "+cat.getName());
}
}
} 결과
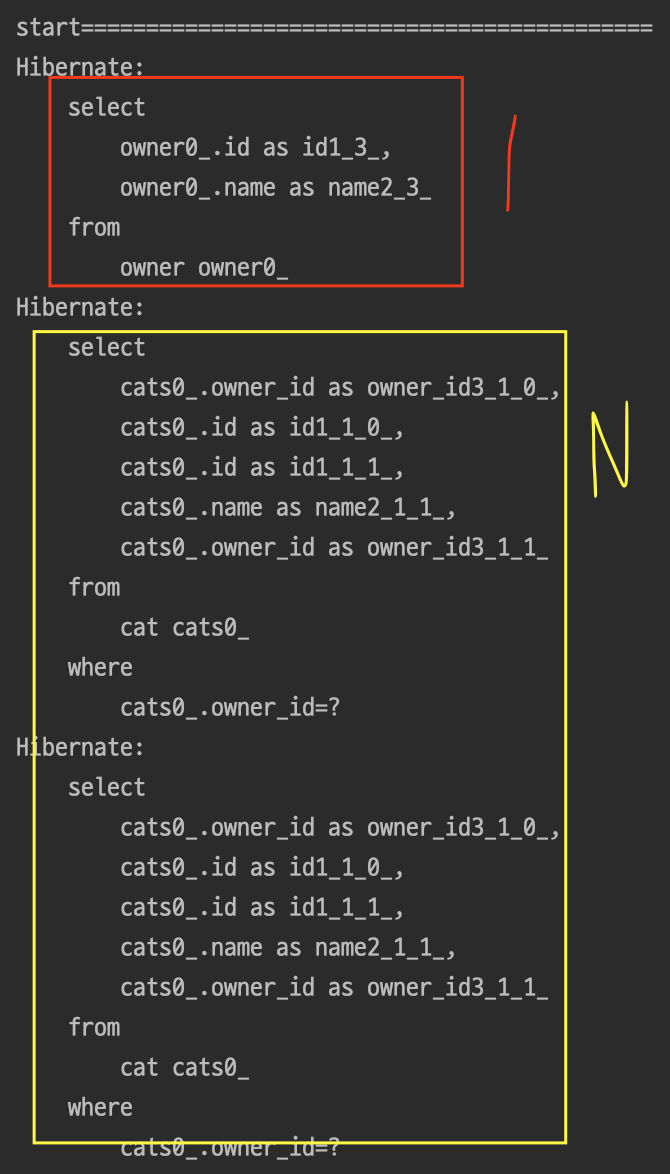
즉시로딩과 마찬가지로 findAll()메소드를 사용했을때 Owner만큼 연관관계를 조회하는 SELECT쿼리가 생성된다.
지연로딩은 N+1 문제 발생 시점만 늦춰줄 뿐이지 즉시로딩과 같은 문제를 가지고 있음을 확인할 수 있다.
N+1 해결방법
JPA는 쿼리메소드를 직접적으로 해석하여 JPQL을 생성하기 때문에 이러한 문제가 발생한다.
JPA를 이용해서 Join문을 사용하는 방법이 없을까?
JPA가 자동생성하는 JPQL이 문제라면 개발자가 직접 JPQL에 Join문을 써서 사용하면 해결되지 않을까?
Query
@Query("select distinct o from Owner o join o.cats")
public List<Owner> findAllJoinFetch();테스트 코드
@Test
public void getCatsJoin(){
System.out.println("start============================================");
List<Owner> findOwner = ownerRepository.findAllJoin();
System.out.println("end============================================");
for(Owner o : findOwner){
System.out.println("주인 이름 : "+o.getName());
System.out.println("고양이 개수 : "+o.getCats().size());
}
} 결과
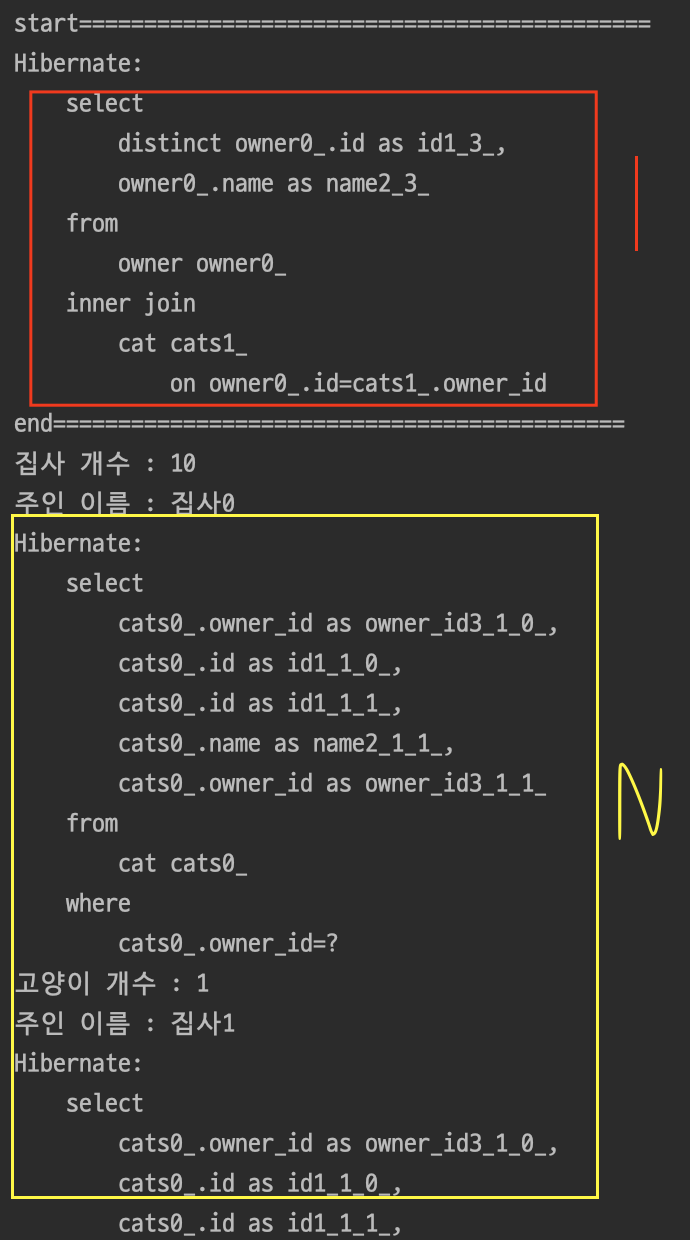
Owner를 조회할 때 Join문은 추가가 되었다. 하지만 여전히 N+1문제는 해결되지 않았다.
Join문은 추가가되었는데 왜 N+1문제는 유지될까?
조회한 엔티티의 연관관계는지연로딩으로 인해프록시 객체이기 때문에 결국 실제 사용할때 연관관계를 조회하는 SELECT쿼리가 생성될 수 밖에 없는것이다.
N+1 해결책(1) Fetch Join
Fetch Join을 사용하면 지연로딩을 사용하는 연관관계도 N+1문제를 해결할 수 있다.
Query
@Query("select distinct o from Owner o join fetch o.cats")
public List<Owner> findAllJoinFetch();결과
Fetch Join은 표면상으로는 SQL의 Join문과 달라보이지 않는다. 하지만 Fetch Join은 JPQL의 성능 처리를 위해 JPQL에만 있는 쿼리이다.
연관관계를 조회할 때 Fetch Join을 사용하게 된다면 지연로딩이 걸려있는 연관관계도 즉시로딩처럼 한번에 조회하기 때문에 연관관계가 프록시 객체가 아닌 실제 엔티티를 참조하고 있다
(테스트 코드 실행 때 @Transactional어노테이션을 작성하지 않으면 지연로딩때 LazyInitializationException 예외가 발생한다. 이걸 이용해서 JPQL로 그냥 join과 fetch join을 각각 테스트해보니 그냥 join은 LazyInitializationException이 발생했고 fetch join은 연관관계를 무사히 가져오는 걸 보니 fetch join은 지연로딩이 걸려있어도 즉시로딩처럼 연관관계를 가져와 N+1문제가 발생하지 않는 이유를 확인할 수 있었다.)
참고로 Fetch Join 시 inner join을 제공한다.
N+1 해결책(2) EntityGraph
Fetch Join대신 사용할 수 있는 방법으로 EntityGraph가 있다.
Query
@EntityGraph(attributePaths="cats", type= EntityGraph.EntityGraphType.FETCH)
@Query("select distinct o from Owner o")
public List<Owner> findAllEntityGraph();결과
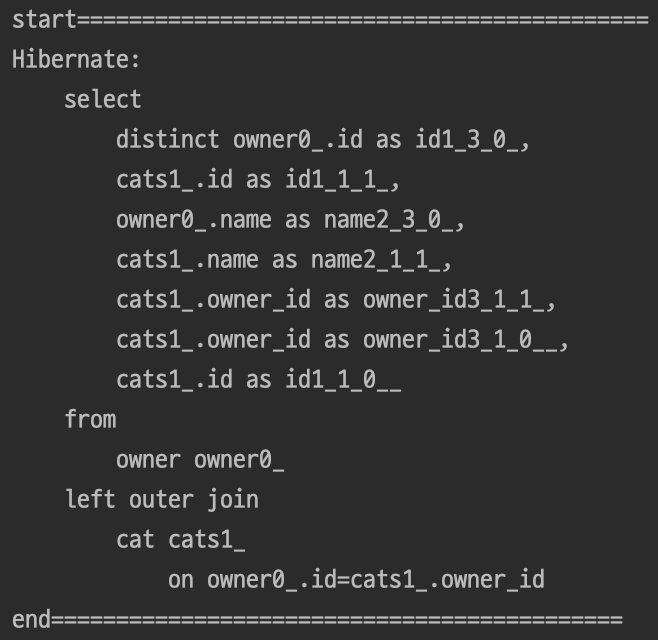
EntityGraph는 @EntityGraph어노테이션을 이용해서 attributePaths에 fetch join을 사용해줄 연관관계 멤버변수롤 설정하고 type을 EntityGraph.EntityGraphType.FETCH를 설정해주면 직접 작성한 Fetch Join과 동일하게 작동되어 N+1을 해결한다.
참고로 EntityGraph시 outer join을 제공한다.
Fetch Join 문제
Fetch Join이 N+1문제를 해결해준다 하지만 만능은 아니다.
JPA에서 Fetch Join을 함께 사용한다면 발생할 수 있는 문제가 있다.
Pagination
Limit을 사용하여 데이터베이스에서 요청한 데이터만 나누어서 가져오게 하는 페이지네이션 기능을 사용할 때 Fetch Join을 사용하게 되면 문제가 발생한다.
Query
@Query(value = "select distinct o from Owner o join fetch o.cats ",
countQuery="select count(distinct o) from Owner o inner join o.cats")
Page<Owner> findAllPage(Pageable pageable);(JPQL로 fetch join을 직접 작성할 때 Paging을 사용하게 되면 Count쿼리를 지원해주지 않기 때문에 countQuery를 분리해서 작성해줘야한다. EntityGraph에서는 정상 작동한다.)
테스트 코드
@Test
@DisplayName("Fetch join으로 paging시 관련 엔티티를 모두 불러와 인메모리에서 paging처리 후 반환")
public void getCatsPagingFetchJoin(){
System.out.println("start============================================");
PageRequest pageRequest = PageRequest.of(0,2);
Page<Owner> findOwner = ownerRepository.findAllPage(pageRequest);
System.out.println("end============================================");
for(Owner o : findOwner){
System.out.println("주인 이름 : "+o.getName());
System.out.println("고양이 개수 : "+o.getCats().size());
}
}결과
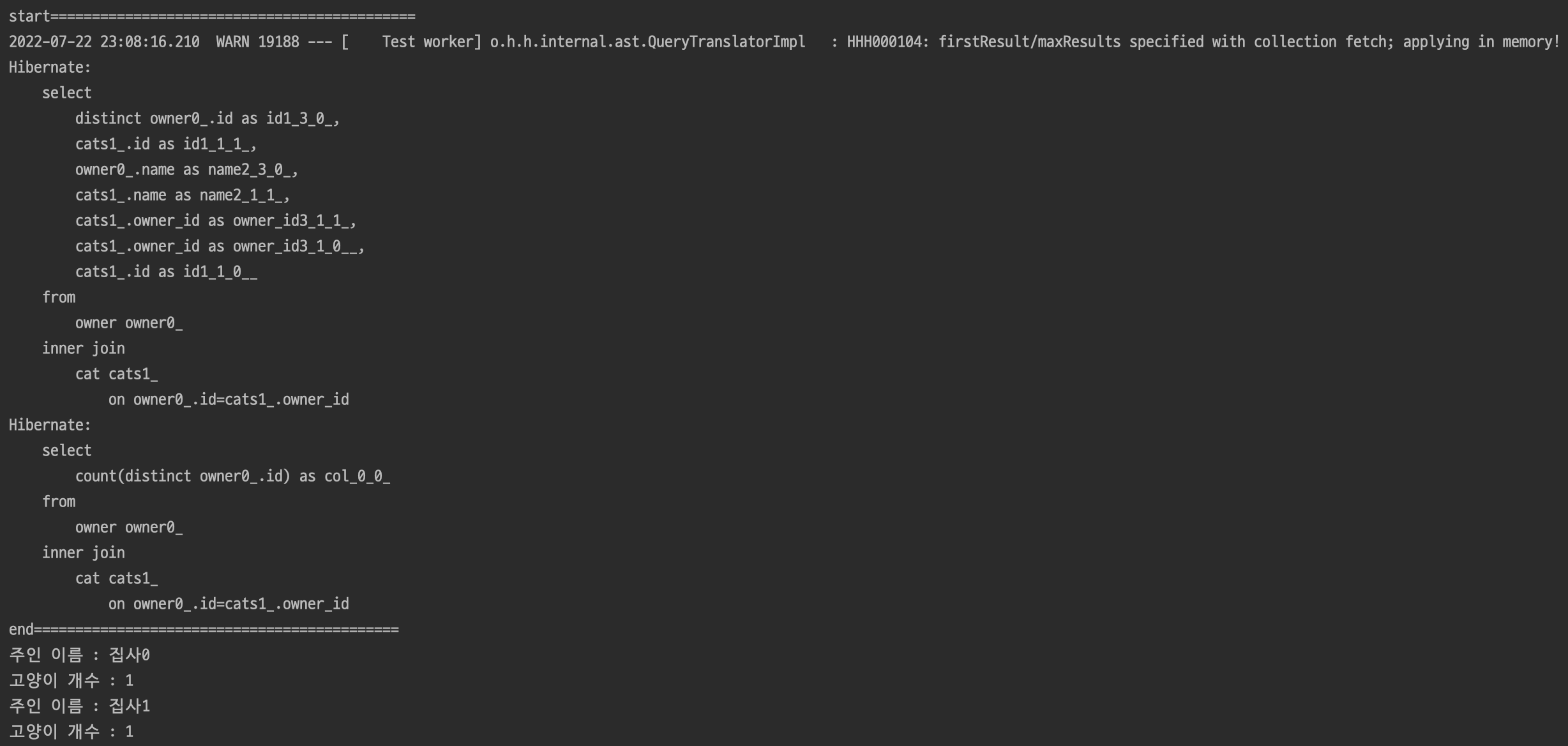
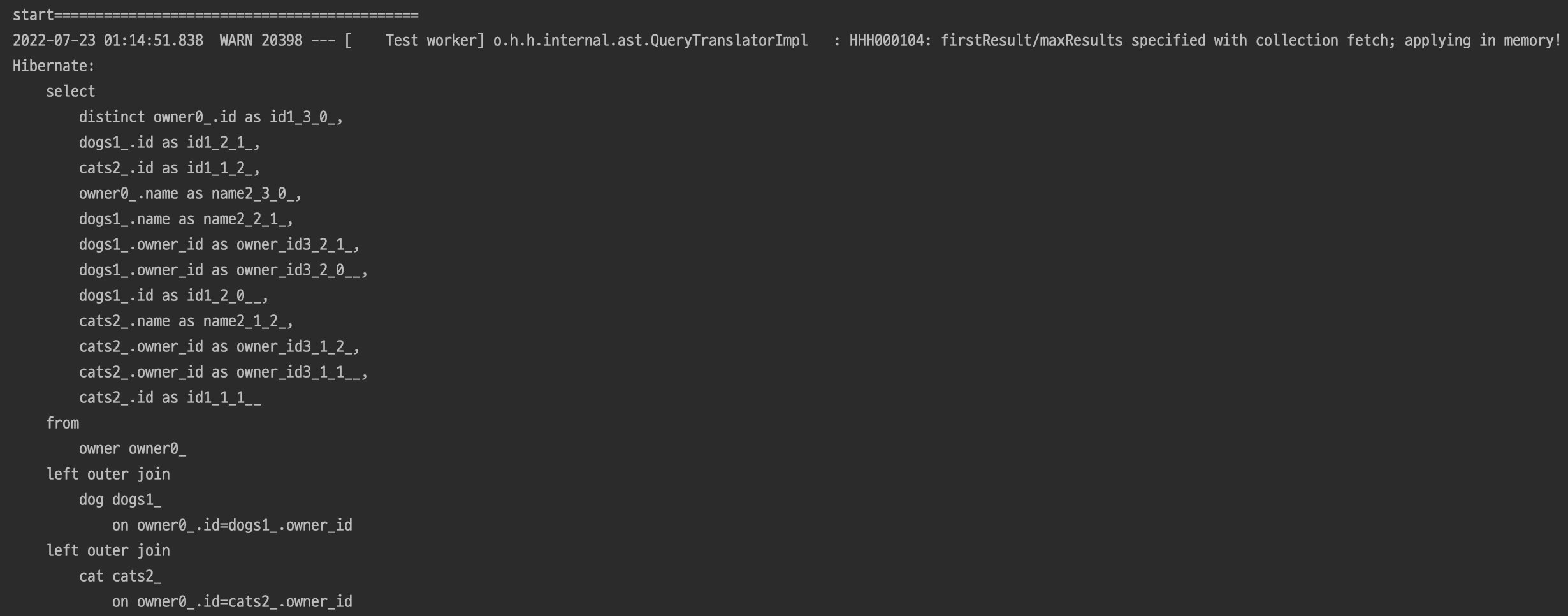
Join문 처리도 되었고 2개의 데이터만 가져오는 것도 잘 동작한것 같지만, SELECT쿼리에서 limit문이 작성되지 않았다.
count쿼리는 필요한 쿼리이니 넘어가고,
하지만 더 큰 문제는 맨 위에있는 WARN에러 이다.

해석하자면 fetch join으로 데이터를 모두 불러오고 페이징을 메모리 내에서 처리한다는 뜻이다.
잘 작동하니까 괜찮겠지라고 생각할수도 있지만, 만약 데이터가 100만개를 모두 불러와 메모리에 저장해놓고 페이징 처리 후 반환한다면..? OOM(Out of Memory)가 발생할 가능성이 높아진다.
메모리에 굳이 데이터를 불러와서 페이징 처리를 하는 이유가 뭘까?
Paging처리를 하게 되면 fetch join시 5개의 Owner와 연관관계로 10개의 Cat이 있다고 가정하고 2개의 Owner와 각 10개의 Cat을 가져오고 싶고 가정하자.
fetch join은 inner join을 사용한댔으니 inner join을 통해 5 * 10 = 50개의 DB row를 가져오게 된다. Owner를 limit해야하는데 현재 각 DB row에는 중복되는 Owner를 포함하고 있기 때문에 SQL 방언 limt를 가지고는 처리하게되면 1개의 Owner와 2개의 Cat만 가져올 수 있기 때문에 JPA가 원하는대로 처리할수 없게된다.
그렇기 때문에 SQL에는 limit없이 모든 Owner를 불러오고 메모리에서 JPA가 페이징 계산을 하여 반환하게 되는 것이다.
그렇기 때문에 In memory문제를 해결해야한다.
In memory해결책(1) @BatchSize
@BatchSize를 이용해서 Owner의 연관관계(Cat)를 size만큼 조회해서 각 Owner에 참조될수 있게한다.
Entity
@BatchSize(size = 5)
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL,fetch = FetchType.LAZY)
private List<Cat> cats = new ArrayList<>();테스트코드
@Test
@Transactional
public void getCatByManyToOnePaging(){
System.out.println("start============================================");
PageRequest pageRequest = PageRequest.of(0,10);
Page<Owner> owners = ownerRepository.findAll(pageRequest);
System.out.println("end============================================");
for(Owner o : owners){
System.out.println("주인 이름 : "+o.getName());
System.out.println("고양이 개수 : "+o.getCats().size());
}
}결과
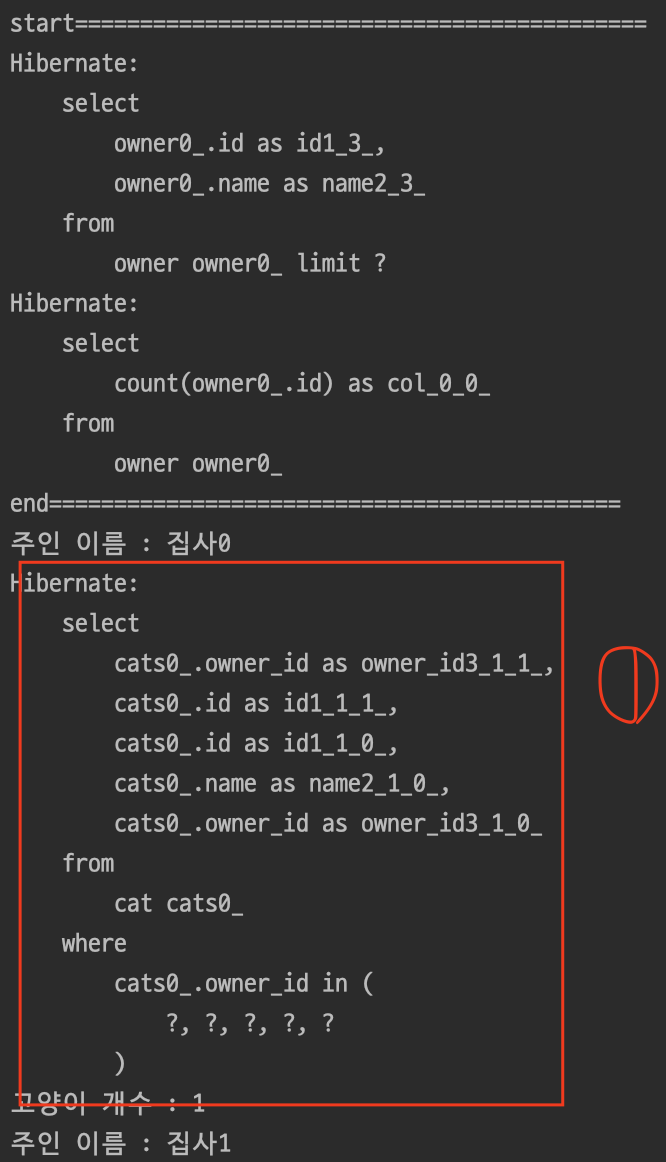
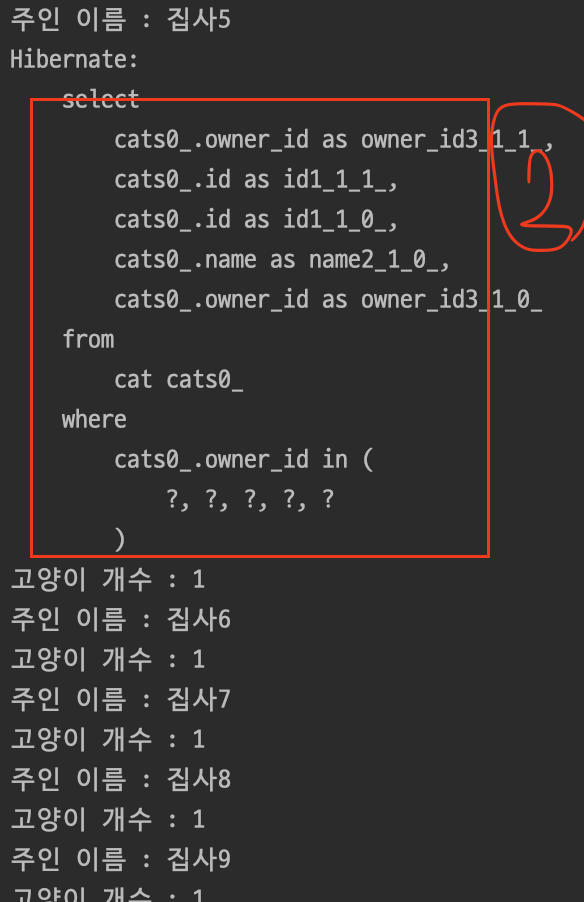
BatchSize는 연관관계를 조회할때 Join은 사용하지 않지만 size만큼의 Owner의 id를 가지고 연관관계 조회를 요청하는 쿼리를 생성하게 된다.
결과를 보게 되면 limit가 적용되고 2개의 쿼리가 따로 생성된 것을 확인할 수 있다.
그리고 추가로 생성된 쿼리를 보게되면 in쿼리가 생성되었는데 이는 Owner의 id를 size만큼 묶어서 연관관계를 따로 조회하는 것이다.
2개의 SELECT쿼리는 무엇인가?
테스트코드에서는 10개의 Owner를 요청했고 BatchSize는 5이다. 그렇기 때문에 첫번째 Select에서0~4까지의 Owner에 대한 Cat을 조회하는 쿼리, 두번째 Select에서5~9까지의 Owner에 대한 Cat을 조회하는 쿼리가 발생. 총 2개의 쿼리가 발생했다.
만약 BatchSize가 3이라면 (1)0~2, (2)3~5, (3)6~8, (4)9의 연관관계를 조회하는 쿼리 4개가 생성될것이다.
BatchSize 연관관계 조회 쿼리가 생성되는 것은 불가피 하지만 총 Owner 개수만큼의 SELECT쿼리를 생성하지 않을 수 있어 성능 개선에 도움이 된다.
단, BatchSize를 이용할때는 fetch join을 사용해서는 안된다.
BatchSize시 fetch join을 사용하지 말아야하는 이유
Fetch Join은 BatchSize보다 우선 적용되기 때문에 BatchSize가 무시되고 ToMany연관관계의 자료형이 List인 경우MultiBagFetchException이 발생하게되고 Set인 경우 In Memory가 발생하게된다.
In memory해결책(2) Fetch(FetchMethod.SUBSELECT)
Fetch(FetchMethod.SUBSELECT)는 BatchSize와 비슷한 동작을 수행한다.
다른점이라고 한다면 BatchSize는 설정한 size만큼의 id를 나누어서 연관관계 쿼리를 생성하는 반면, FetchMethod.SUBSELECT는 모든 Owner에 대한 연관관계를 한번에 가져오게된다.
Multiple Collection Join
엔티티를 모델링하다보면 2개 이상의 OneToMany 연관관계를 가지는 경우가 있다.
OneToMany는 보통 Collection으로 선언하여 참조를 하게 된다.
Fetch Join을 사용했을때 하나의 Collection을 조인했을 경우 문제없이 fetch join이 적용되어 엔티티를 조회한다.
하지만 2개 이상의 Collection 조인을 했을 경우 MultiBagFetchException에러가 발생하게 된다.(ToOne의 연관관계는 상관없이 사용할 수 있다.)

해결방법에는 2가지가 있다.
Set자료형
Set자료형을 사용하게 되면 join시 DB row가 Owner를 중복해서 가져오게 되는데 2개 이상의 Collection시 복잡한 중복관계를 처리(?)할 수 있기 때문에 가능한것으로 생각되어진다.
(정확한 이유는 추후에 찾아서 정리하겠습니다)
Entity
@Entity
public class Owner {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
private Set<Cat> cats = new LinkedHashSet<>();
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
private Set<Dog> dogs = new LinkedHashSet<>();
//...
}Query
@EntityGraph(attributePaths = {"cats", "dogs"}, type = EntityGraph.EntityGraphType.FETCH)
@Query("select distinct o from Owner o")
List<Owner> findAllJoinTwoCollections();테스트코드
@Test
@DisplayName("Fetch join에서 2개 이상의 Collection join 문제")
public void OverTwoCollectionsJoin(){
System.out.println("start============================================");
List<Owner> owners = ownerRepository.findAllJoinTwoCollections();
System.out.println("end============================================");
for(Owner owner : owners){
System.out.println(owner.getName()+"의 고양이 개수 : "+owner.getCats().size());
System.out.println(owner.getName()+"의 강아지 개수 : "+owner.getDogs().size());
}
}결과
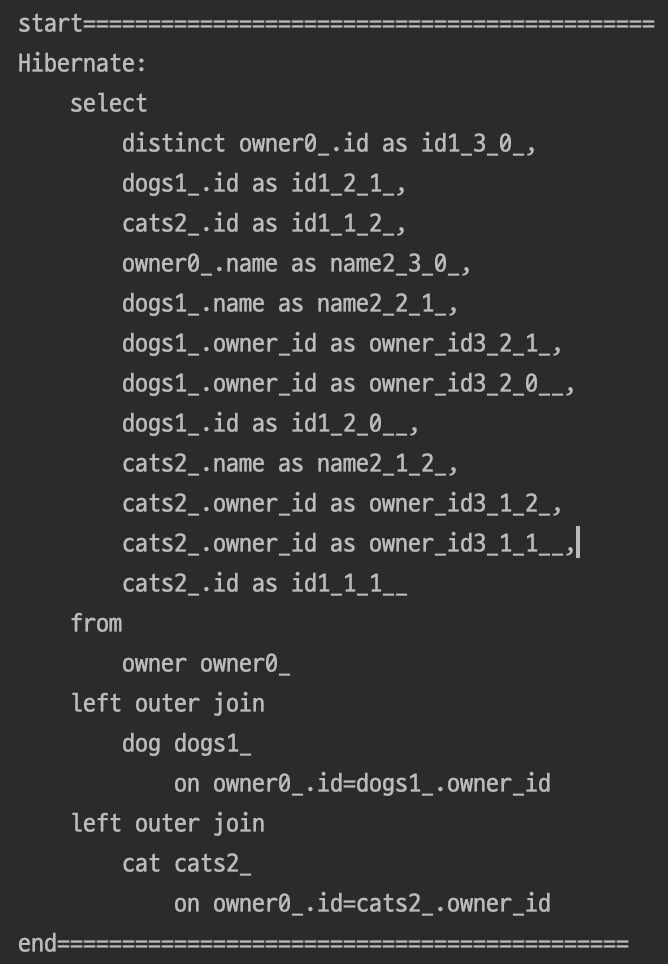
ToMany연관관계의 자료형을 Set으로 변경시 2개의 outer join이 적용되어 Multiple Collection Join이 잘 동작하는 것을 확인할 수 있다.
하지만 List나 Set이나 여전히 Pagination처리 때 In memory가 발생하는것은 동일하다.
@BatchSize
결국은 BatchSize를 사용하게 되면 List나 Set을 사용해도 Multiple Collection Join을 해결할 수 있고, Pagination 문제도 해결할 수 있게 된다.
정리
| 조합 | N+1 | 2 Collection Join | Pagination |
|---|---|---|---|
| List + Fetch Join | O | X (MultiBagFetchExcetpion) | X (In Memory) |
| List + Batch Size | O | O | O |
| Set + Fetch Join | O | O | X (In Memory) |
| Set + Batch Size | O | O | O |
BatchSize로 모든 문제를 해결이 가능하니까 Fetch Join은 사용하지 않아도 되는가?
jojldu님의 블로그의 글을 인용하자면
- BatchSize는 N+1문제를 최대한
in쿼리로 기본적인 성능을 보장해주는 것이다.- 즉, 최소한의 성능을 보장해주는 것이므로 최선이 아닌것이다.
@OneToOne,@ManyToOne과 같은 1관계의 연관관계에 대해서는 모두Fetch Join을 걸어 한방 쿼리를 수행한다.@OneToMany,@ManyToMany와 같이 N관계의 연관관계에 대해서는 데이터가 가장 많은 쪽에Fetch Join을 사용한다.
Fetch Join이 없는 연관관계에 대해서는BachSize적용으로in쿼리로 성능을 보장한다.
Reference
https://jojoldu.tistory.com/165
https://jojoldu.tistory.com/457
https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
https://stackoverflow.com/questions/21549480/spring-data-fetch-join-with-paging-is-not-working

좋은 글 감사합니다. 그런데 잘 이해가 되지 않는 부분이 있습니다.
라고 해주셨는데, 연관된 CAT의 개수만큼 SELECT 쿼리가 발생하는 것 아닌가요?
제가 N+1 문제를 잘못이해한것인지 오타인지 잘 모르겠습니다.