File Concept
: 영구적으로 저장이 되어야 할 자료 (data, program)를 관리하는 'Container'

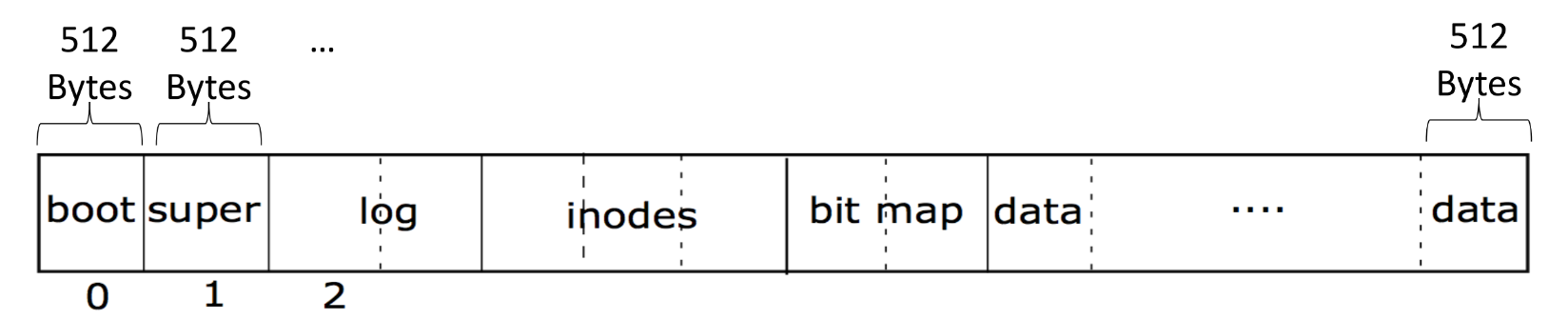
xv6의 file system의 구조는 아래와 같다고 한다.
File Attributes (File Metadata)
: 쉽게 말해 file 관리를 위한 data를 의미하며 일반적으로 directory에 저장된다.
- Name : 사람이 읽을 수 있는 형태로 정보를 저장
- Type : 다양한 type를 지원하기 위해 system에 필요함 (OS는 신경 안씀)
- Location : device에서의 file의 위치를 가리키는 pointer
- Size : 현재 file의 크기
- Protection : 읽고, 쓰고, 실행할 수 있는 권한을 통제하는 역할
- Time, date, user identification : protection, security, usage monitoring을 위한 data
- disk에서 유지되고 있는 directory에 저장되어 있는 file에 대한 정보
File Operations
- Create
- write
- read
- repositioning within file (file seek)
: file 내에서 접근하고자 하는 위치 (offset)를 바꾸는 것- delete
- truncate : file의 data(content)를 전부 지워버리고 metadata만 남겨 놓는 과정
- open() : disk에서부터 memory로 file metadata를 복제하는 것
(이 작업을 하기 위한 directory 구조를 찾는 것)- close()
여기서, open()에 대해 살펴보면, open()을 쓰지 않고 data를 불러오기 위해서는 data의 위치를 directory entry에서 찾은 뒤 hard disk에 접근해야하는데 hard disk와 같은 2차 저장장치로 접근을 하는 과정은 I/O overhead가 매우 크다. 따라서 fopen()과 같은 함수로 hard disk에 있는 metadata 자체를 memory에 복제해서 2차 저장장치로 접근을 하는 과정을 memory에 접근하는 과정으로 변경하여 I/O overhead를 줄일 수 있다.
또한 Memory에 올리게 되면 Cache를 통해 자주 사용하는 file data의 경우 더 빠르게 접근하여 성능을 향상시킬 수 있기 때문에 장점이 많다.
Directories
-
Directory는 2가지 기능을 제공해준다.
- User에게 관련성이 높은 file들을 grouping 하여 체계적인 관리를 할 수 있도록 해준다.
- File system에게 편리한 naming interface를 제공하여 file에 있는 특정한 data item에 대한 detail을 숨길 수 있도록 해준다.
-
대부분의 system의 경우
multi-level directory를 지원하기 때문에 같은 file이고 이름도 같더라도 directory가 다르면 다른 파일로 인식하도록 한다. -
대부분의 system들은
current directory를 갖고 있고 directory tree 구조의 root에서 부터 시작하는 '상대주소'와 '절대주소'를 갖고 있다.
Directory Entry
원래 directory의 경우 file name, size, type 등 file metadata 같은 file에 대한 logical information에 대해 설명해준다. 그런데 이러한 것들이 disk의 자료구조에 존재하기 때문에 한계가 존재하고 이를 해결하기 위해 위에서 언급했듯이 open() 같은 함수를 이용하여 disk에 있는 data를 memory에 복제하여 사용한다.
이 때 directory와 directory entry의 구조를 보면 아래와 같다.
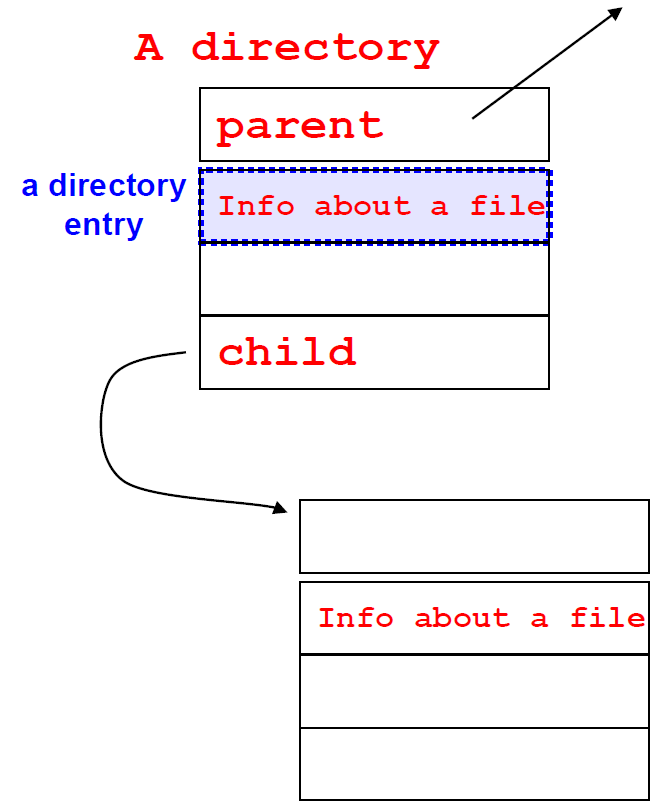
위의 image가 metadata를 저장하는 자료구조인 directory이고, 하나의 directory 당 하나의 directory entry를 갖고 있다. 여기서 잘 보면 하나의 directory에는 2개의 pointer가 존재하는데, 각각 상위 directory와 하위 directory를 가리키고 있는 것을 확인할 수 있다.
이러한 자료구조를 통해 data를 접근할 때 data의 위치를 파악할 수 있게 된다.
Operations
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
Single-Level vs Multi-Level Directory
Single-Level Directory
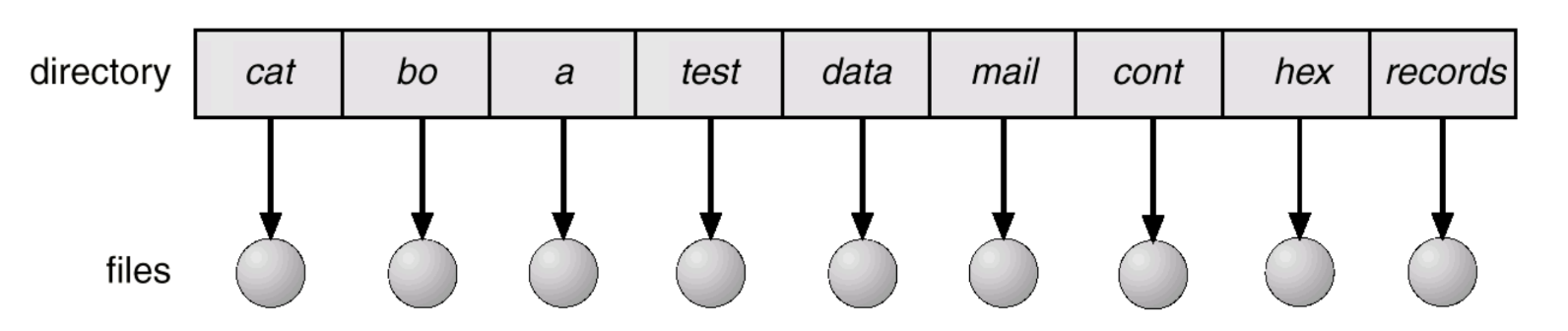
먼저 single-level directory에 대해 먼저 살펴보면, root directory 밑에 모든 파일들이 들어가 있는 모습을 보인다. 이 경우, 동일한 이름의 file을 생성할 수 없고 grouping 과정에서 문제가 발생한다.
Multi-Level Directory
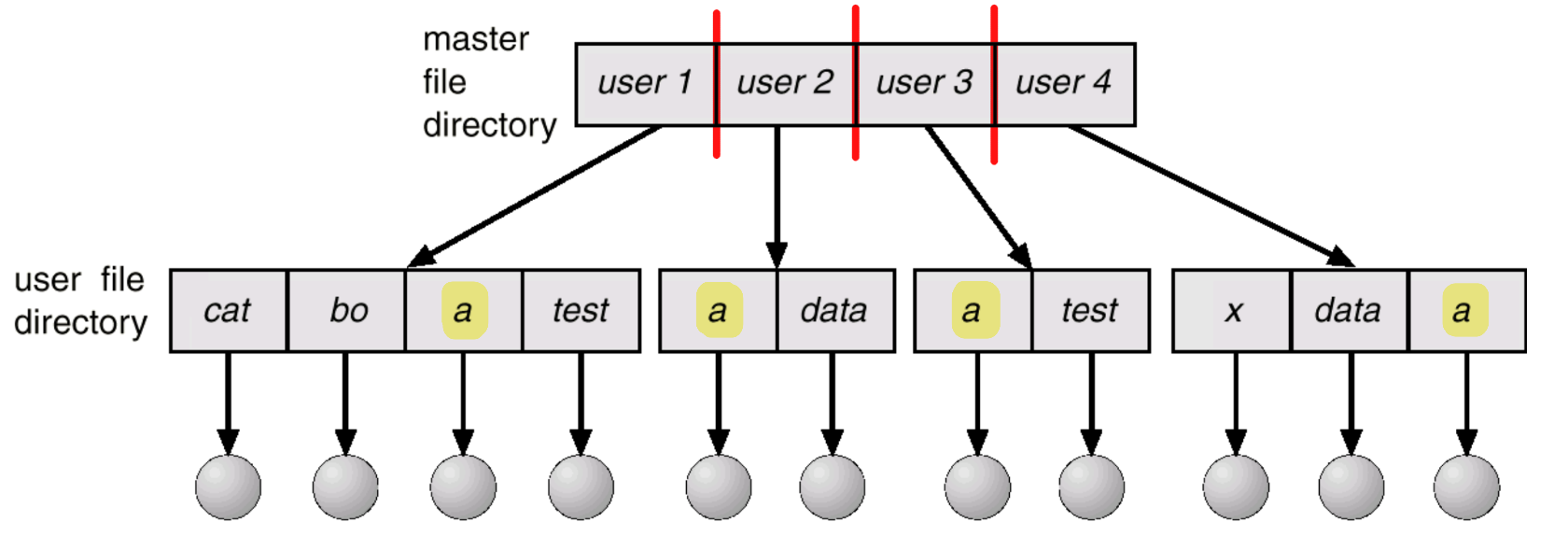
Multi-Level directory는 single-Level과 달리 각각의 user마다 directory를 따로 생성한다. 그렇기 때문에 pathname으로 파일을 관리할 수 있고 사용자간 이름 충돌이 없어지게 된다. (각각의 사용자 개개인의 입장에서는 single-level directory이기 때문)
Tree-Structured Directories

Acyclic-Graph Directories
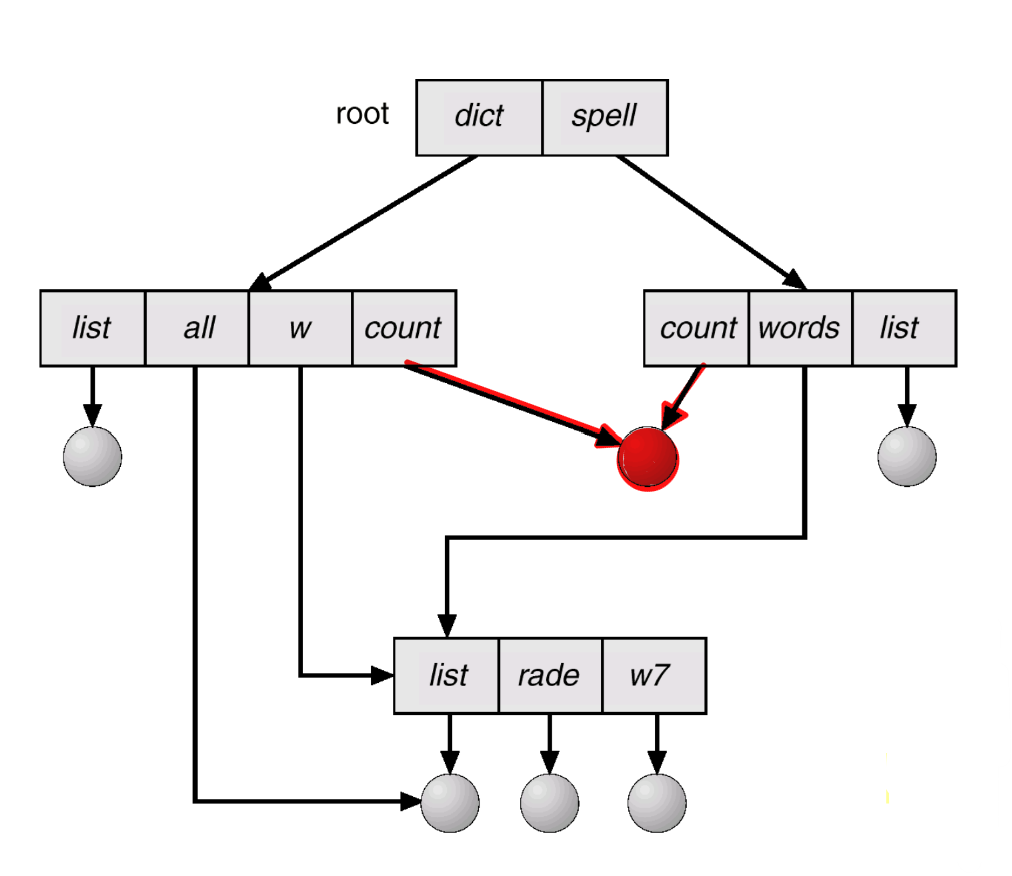
{subdirectory, file}로 관리를 하며, cycle이 허용되지 않고 file/directory를 공유한다.
- 같은
{subdirectory, file}은 2개의 서로 다른 directory일 수도 있다.
- 같은 node를 두 번 방문하게 되기 때문에 traverse problem이 발생한다.
- "Delete" 과정이 복잡하다
[Scenario]
Kang이 subdirectory 'X'를 갖고 있는데 Jung도 X를 자신의 subdirectory로 두고자 하는 경우
Symbolic link
:pathname을 X에 link
- X가 kang에 의해 'delete'될 경우 Jung의 link는
dangling reference(아무 것도 없이 허공을 가리키고 있는 상태) 가 된다.
( Kang이 지웠는데 Jung은 지운 적이 없기 때문에 X에 대한 directory entry(metadata)를 Jung은 갖고 있지 않는다)Hard link
: Kang의 directory에 있는 directory entry를 Jung에게 복사한다.
- X가 update 될 때
consistency problem이 발생한다.- X를 delete 하는 방법 : reference count을 유지하여 reference count가 0이 되었을 때 X를 삭제한다.
( Jung도 directory entry를 갖고 있기 때문에 함부로 delete하면 안되고 아무도 X를 관리하고 있지 않을 때 delete해야 한전하다)
General Graph Directory
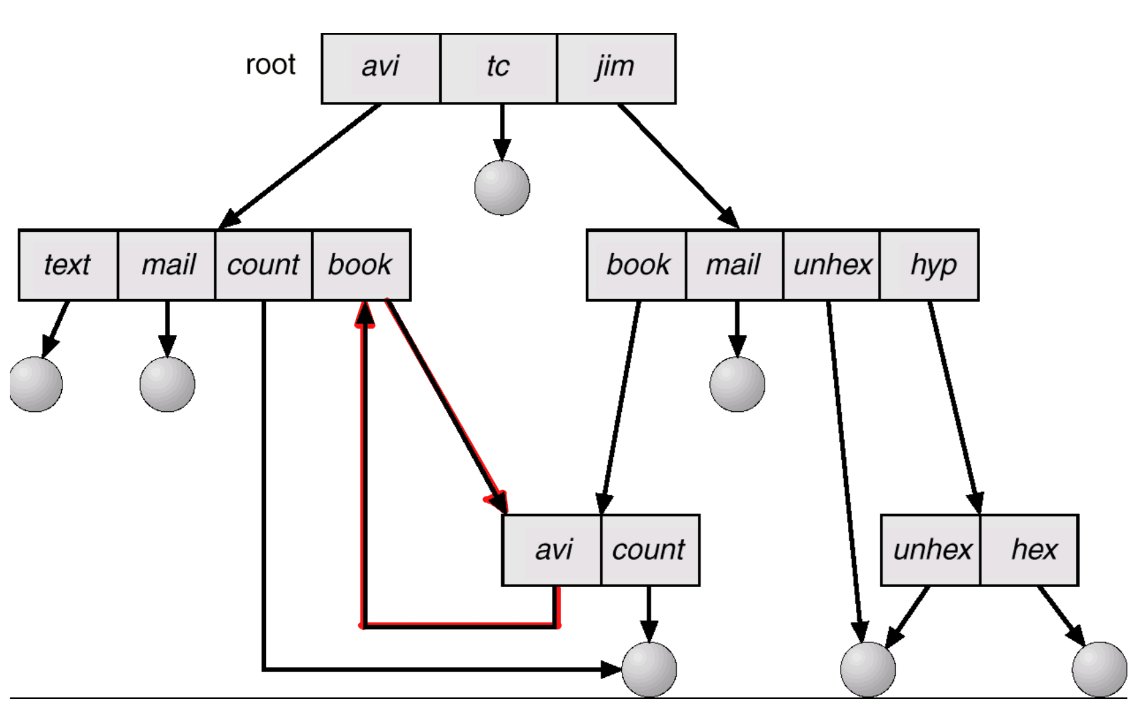
- Cycle 허용
- Traverse와 delete에 대한 algorithm이 복잡함
- Traverse : Cycle에서 무한 루프에 걸리지 않도록 해야 함
- Delete
- Kang이 X를 지운다해도 reference count는 0보다 크다 (self-referencing or cycle 때문에)
- X는 deallocated 된다
- Garbage collection이 필요하다
Cycle이 없도록 보장하는 방법
- file에만 link를 허용한다 (subdirectory에는 허용 X)
- link가 추가될 때마다 link가 올바른지 cycle detection algorithm으로 확인한 뒤 결정한다.
Protection
: File 주인과 생산자는 파일에 어떤 연산이 수행될지 대해 조절할 수 있어야 한다.
Types of access
- Read
- Write
- Execute
- Append
- Delete
- List (name, attribute)
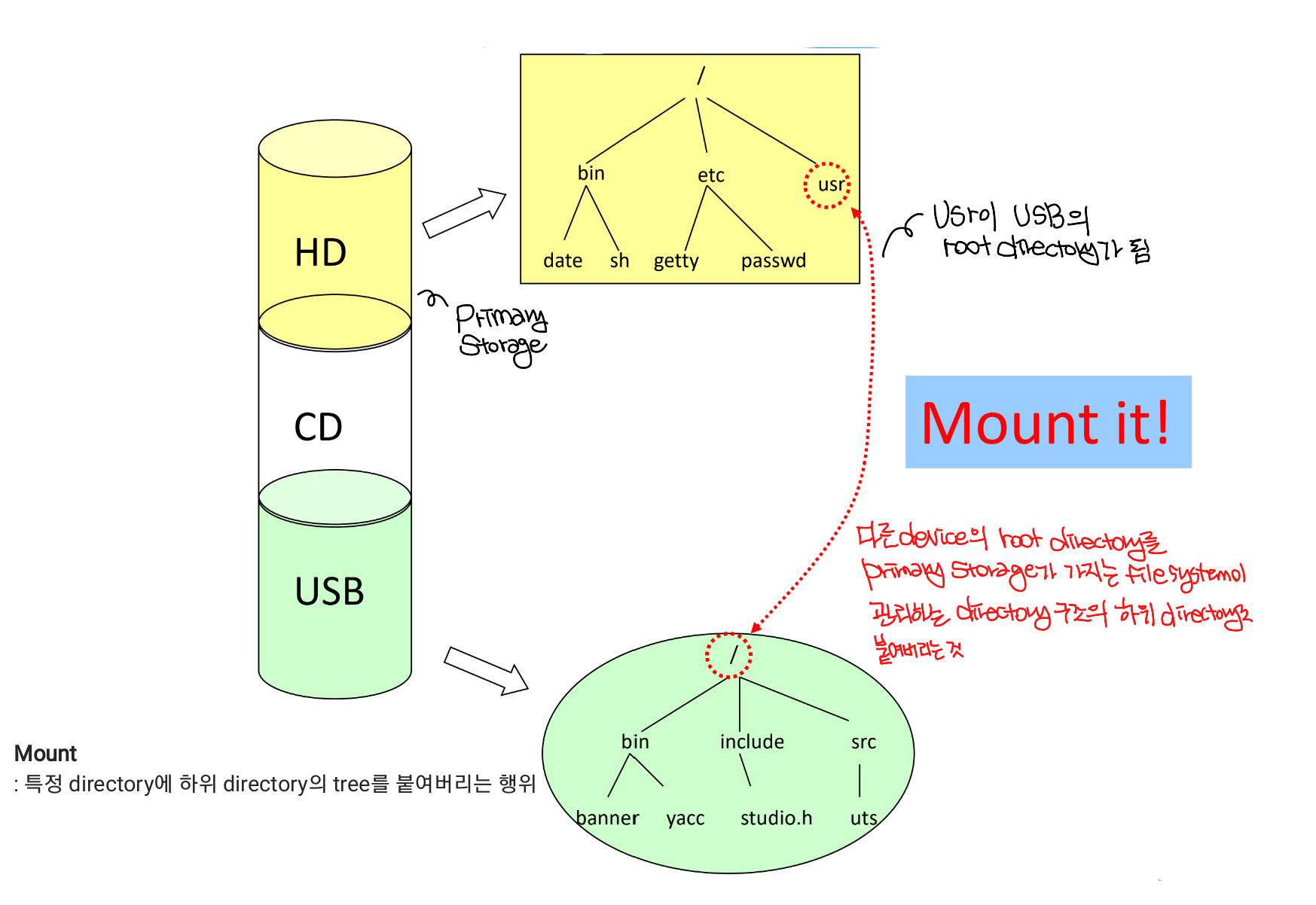
Mounting File System
Allocation of File Data in Dist
Contiguous Allocation
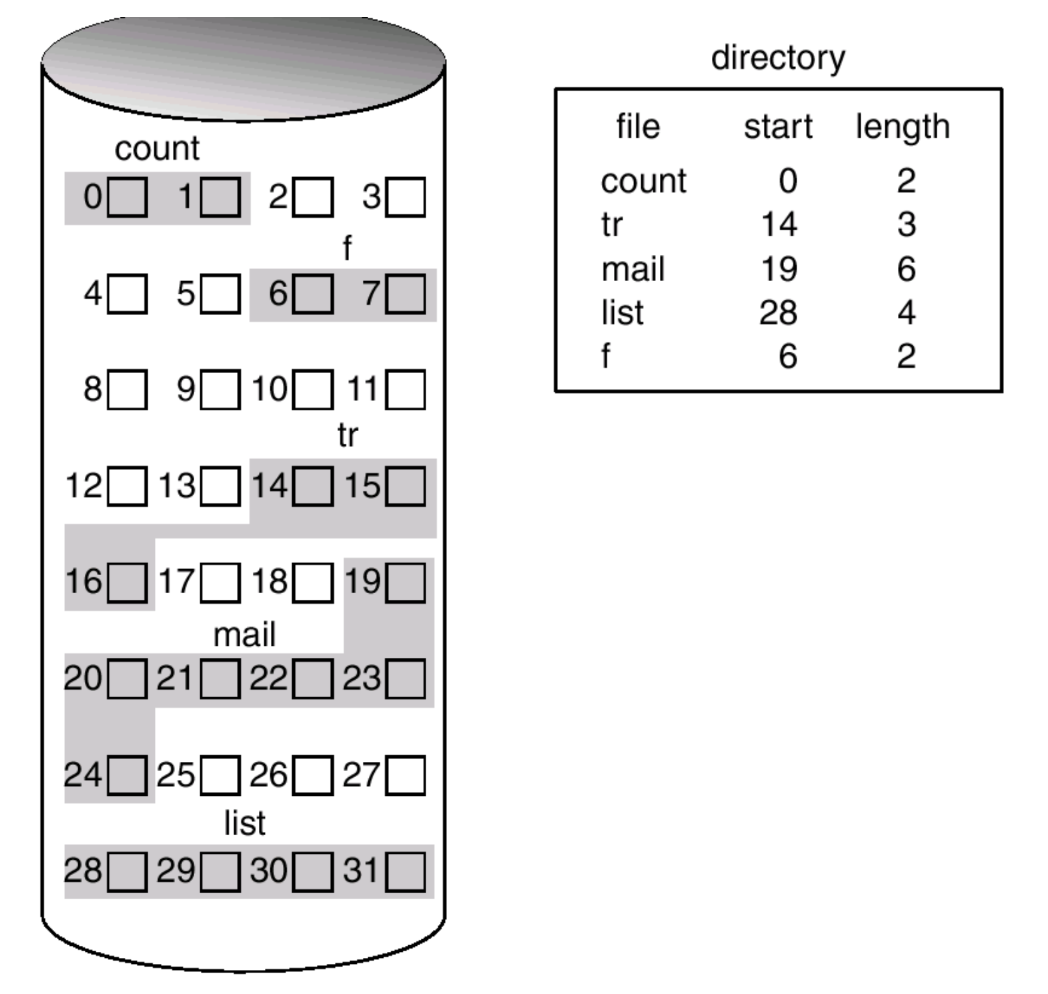
: 각각의 file이 disk의 연속적인 block들을 차지하고 있다. 그렇기 때문에 시작 위치와 길이 (block의 개수)만 알면 되기 때문에 간단하며 한 번의 seek/rotation으로 많은 data를 transfer할 수 있기 때문에 속도가 빠르다는 장점이 있다.
그러나, 단점도 존재하는데 memory management중 paging 기법에서 다뤘던 Dynamic-Storage allocation이 있다. 이 역시 external fragmentation으로 인해 수 많은 크기가 작은 hole들이 생겨나기 때문에 공간의 낭비가 발생하고 file의 크기가 커지게 되면 확장 가능한 공간이 부족할 수도 있게 된다.
Linked Allocation
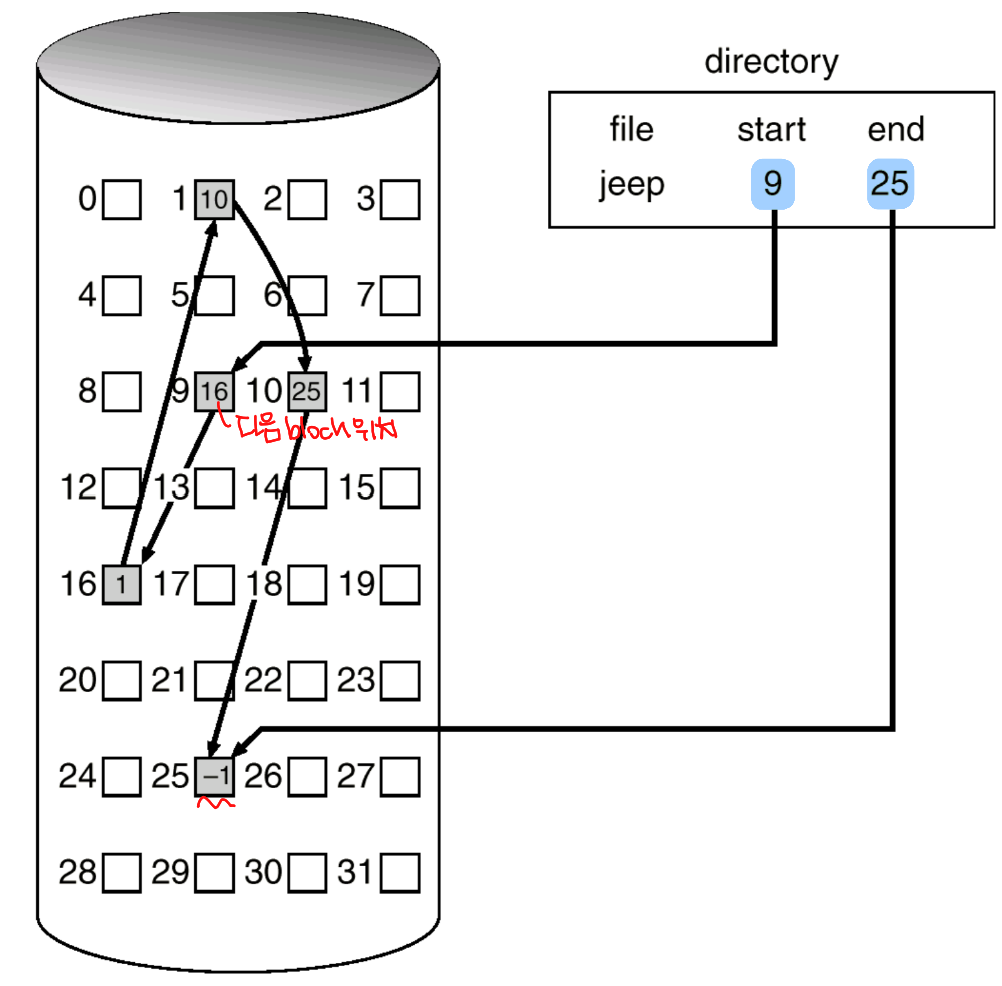
- 각각의 파일이 disk block들의 linked list이다.
- Block들은 disk 내의 여러 군데에 흩어져 있을 수도 있다.
: 단순히 시작 위치만 알면 되기 떄문에 매우 간단하고, 공간의 낭비도 존재하지 않는다. 그러나 만약 3번 block에 접근하려고 한다면 앞의 1,2번 block을 거쳐서 가야 하기 때문에 random access가 안된다는 점과 pointer를 위한 공간이 필요하다는 점, 매 sector I/O마다 seek/rotation을 해야하기 때문에 Disk I/O 효율이 좋지 못하다는 점이 단점이다.
이 모든 것들을 관리하는 자료구조가 FAT (File-Allocation Table)이다.
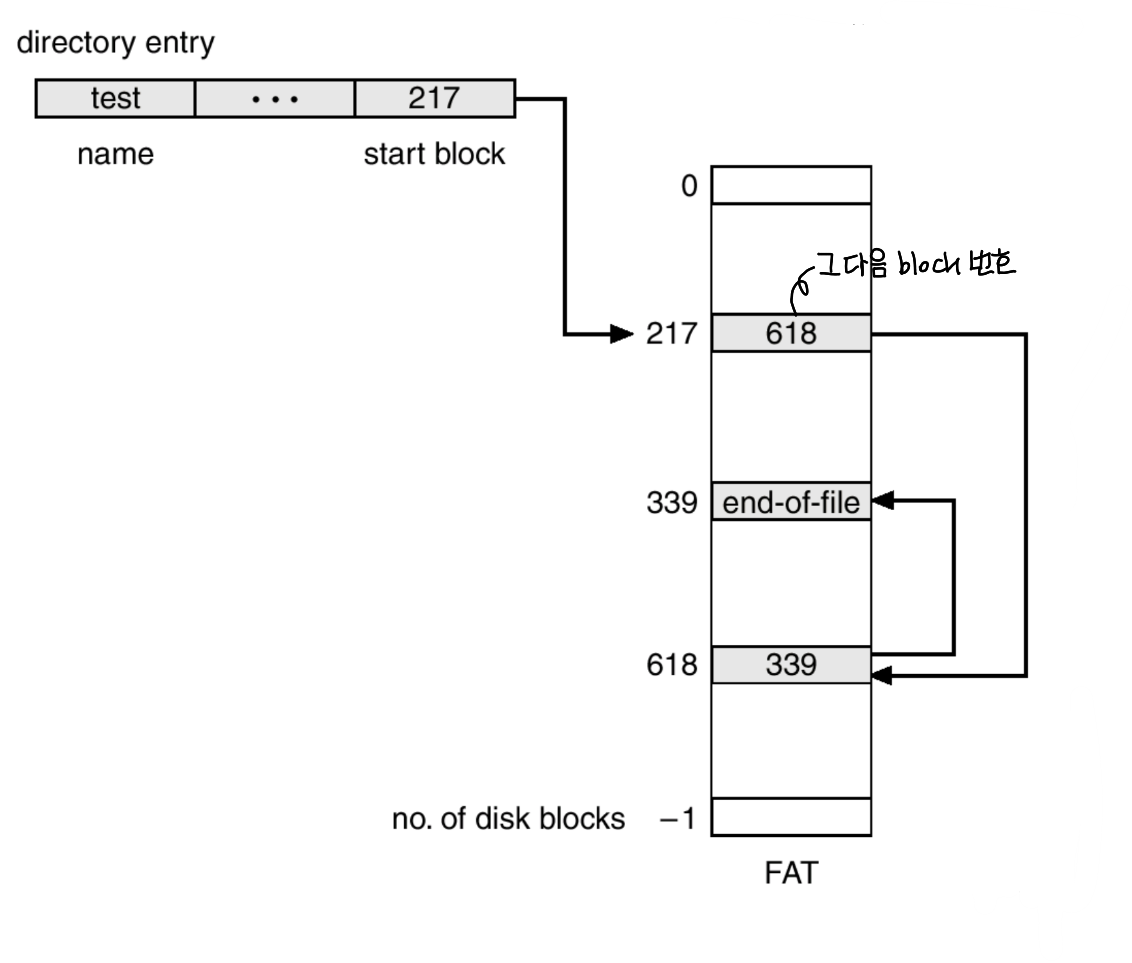
Indexed Allocation
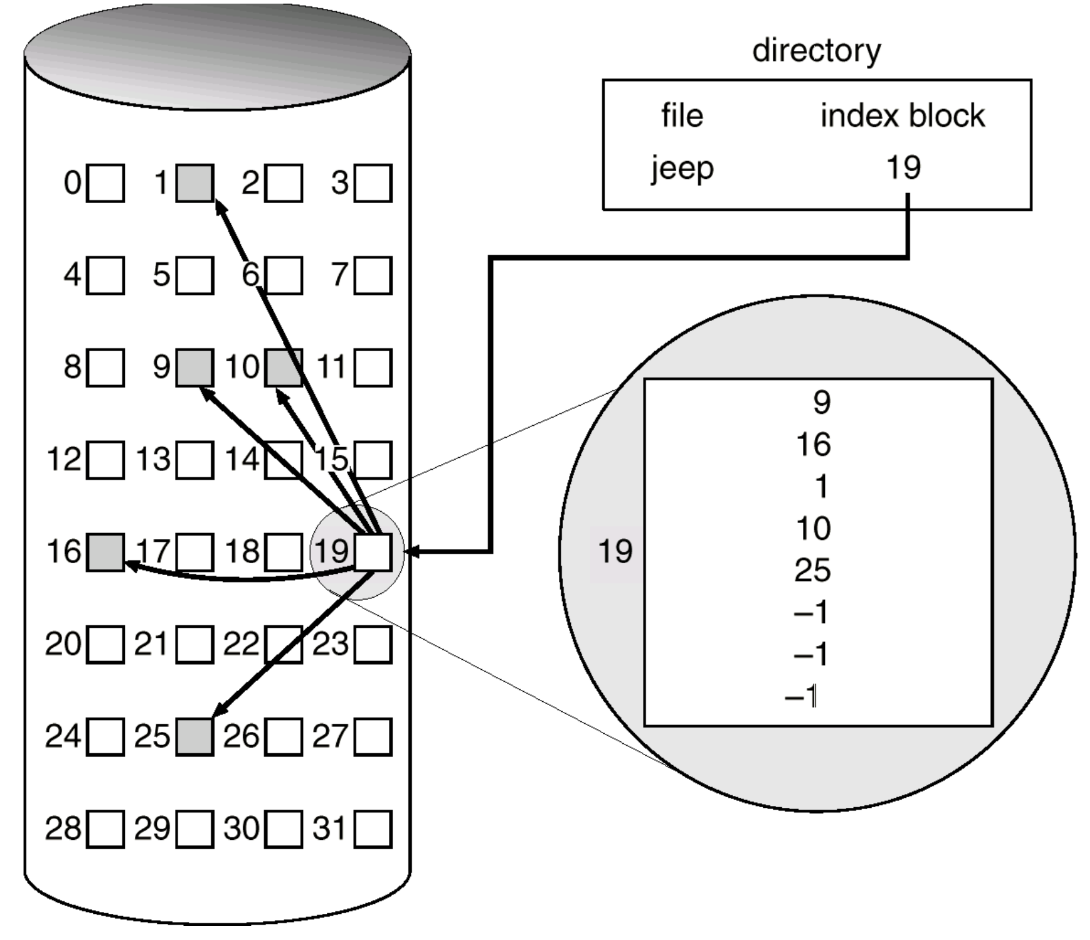
: File data가 저장되는 대신, file data가 저장된 위치 정보를 갱신한다.
- 각각의 file은 각자의 index block을 갖고 있다.
- Index block은 disk block을 가리키는 pointer 배열이다
- Fase direct access와 random access가 가능하다
Free-Space Management
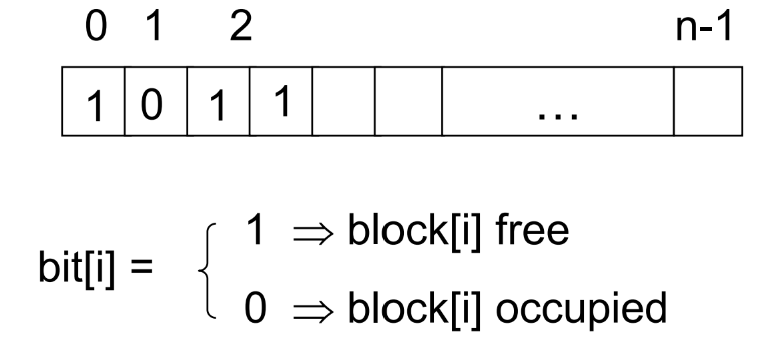
Linked list
- 모든 free block들은 연결
- disk I/O이기 때문에 traversing 과정이 매우 느림
- Contiguous space를 쉽게 얻기 힘듦
- 공간의 낭비가 없음
Grouping
-
Linked list 방식을 수정한 방법
-
첫 번째 free block은 n 개의 pointer들을 갖고 있음
- n-1개의 pointer가 free block들을 가리키고 있음
- 마지막 pointer가 같은 종류의 block을 가리키고 있음
Counting
- 첫번째 free block과 contiguous free block의 개수를 추적
- 일반적으로 여러 contiguous block들은 할당되어 있거나 함께 free된다.
