이번 posting에서는 Hard disk 같은 2차 저장장치에 대해 다뤄보고자 한다.

Hard disk의 경우 위의 그림과 같이 생겼다.
Physical Disk Structure
Disk를 옆, 위에서 바라보면 아래의 그림과 같다.
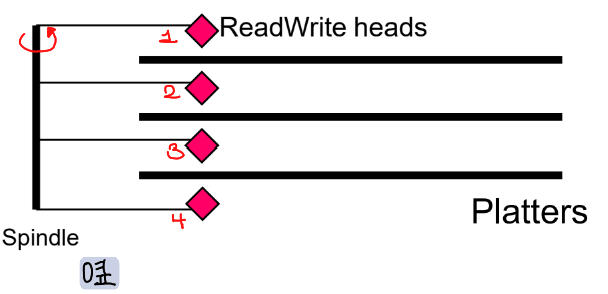
먼저 옆을 보면, 여러 개의 platter들이 있고, spindle을 축으로 하는 head들이 사이사이에 존재한다. Platter에는 magnetic이 존재해서 head들이 이동하면서 platter의 양면에 data를 기록하고, 기록한 data를 읽는다.
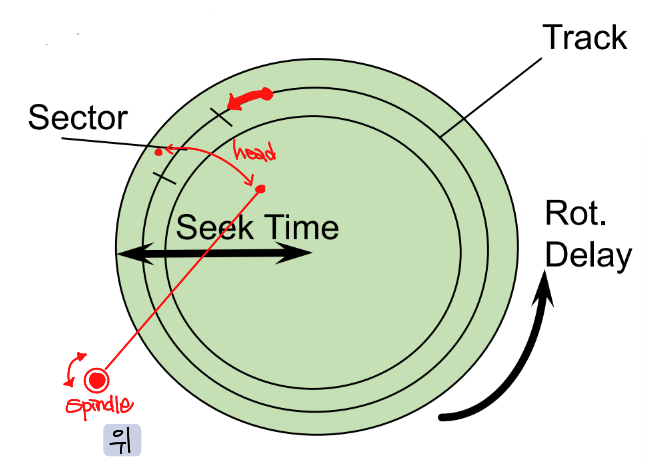
이번엔 위에서 보면, 하나의 platter를 볼 수 있고 platter에는 track과 sector가 존재한다. 원래 그림에는 없었지만, 그림으로 그려보면 platter 바깥에 spindle이 존재하고 head가 platter 위를 움직이면서 해당 data를 갖고 있는 sector를 찾는다. 이 때 track 위를 움직이는데 걸리는 시간을 Seek Time이라고 하고, head가 track 위의 특정 sector에 도착한 뒤 원하는 data가 head 바로 아래에 오기 까지 걸리는 시간을 Rotational delay, data를 찾은 위 head가 data를 읽는 속도 (쓰는 속도)를 Transfer time이라고 한다.
CHS (Cylinder-HEad-Sector)
: data가 들어 있는 sector를 지정하는 system
LBA (Logical Block Address)
: Disk drive가 다뤄지는 단위로, hard disk controller가 LBA를 받아서 CHS 주소 체제로 변환한 뒤, 해당 sector에 존재하는 data를 Read/Write 하게 된다.
Disk Scheduling
CPU Scheduling에서는 어떤 process에게 CPU를 할당해주고 어떻게 하면 더 효율적으로 자원을 사용할 수 있는지를 다뤘다면, Disk Scheduling에서는 Access time을 최소화하는 것에 초점이 맞춰져 있다.
먼저 Access time에 대해 알아보면, Access time은 두 가지로 구성되어 있다.
- Seek time : Disk의 head가 원하는 sector를 갖고 있는 cylinder로 움지이는데 걸리는 시간
- Rotational latency : Disk head에 원하는 sector가 올 때까지 기다리는 시간
일반적으로 seek time은 seek distance와 비례하다고 한다. 그 이유는 seek time의 경우 위의 그림에서 언급했듯이 sector를 찾기 위해 넓은 영역을 이동하기 때문에 찾기 위해 이동하는 거리가 길어질 수록 시간도 비례하여 오래 걸릴 수 밖에 없다. 따라서 rotational delay 보다 seek time을 최소화 하는 것이 효율이 더 좋아질 확률이 높아지게 된다.
Seek Time Benchmark
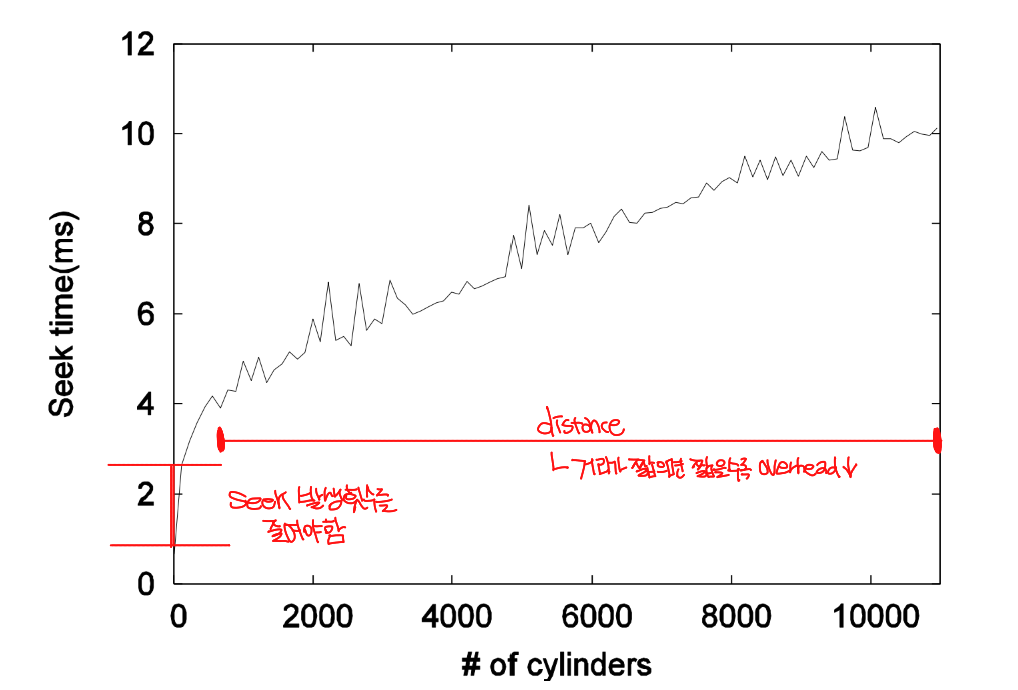
Seek time을 modeling하면 위의 그림과 같이 어떤 함수로 표현을 할 수 있다. 가로 축은 cylinder의 개수 즉, distance를 의미하고 세로 축은 seek time을 의미한다. 언뜻 보면 약간 함수와 비슷하게 생겼지만, 이 함수를 modeling하면 다음과 같은 함수가 된다고 한다.
지금부터 여러 알고리즘에 대해 살펴볼 것이다.
그 전에 scehduling을 살펴보기 위한 setting 값을 설정하면,
- Queue에 있는 Cylinder 번호 (LBA 번호가 Cylinder에 mapping이 되어 있다고 가정)
98, 183, 37, 122, 14, 124, 65, 67
- Cuuren head position
53
FCFS
Scheduling을 다루는 모든 영역에는 반드시 FIFO가 있을 수 밖에 없다. Disk scheduling 역시 예외는 아닌데, 여기서도 queue에 들어간 순서대로 head가 읽기 시작을 한다.
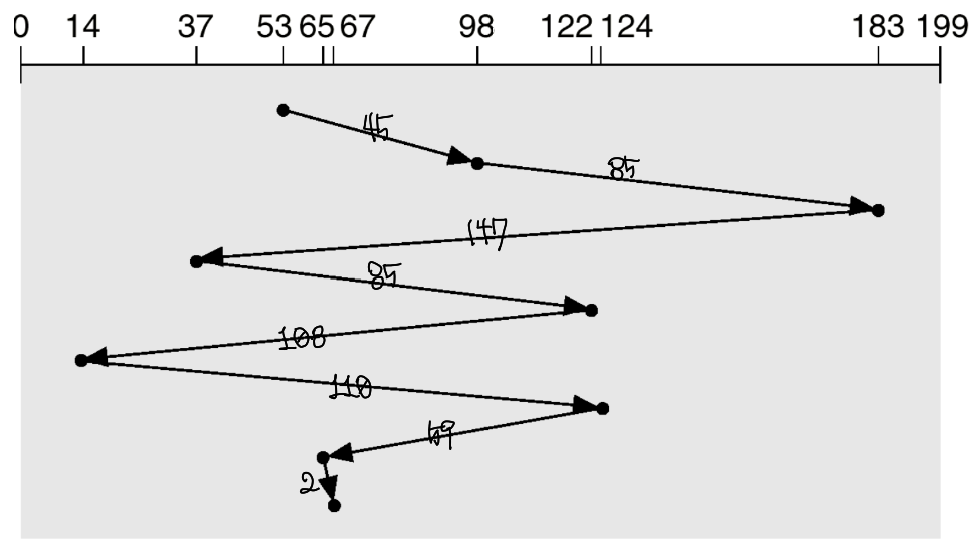
위에서의 setting 값을 FCFS로 읽게 되면 위의 그림과 같이 되는데, FCFS이다보니 한 눈에 봐도 좌우로 매우 긴 거리를 이동하고 있다는 것을 알 수 있다. 실제로 이동거리를 계산해보면 640 cylinder를 이동하게 된다.
SSTF
SSTF는 Shortest Seek Time First의 약자로, CPU Scheduling에서의 SJF(Shortest Job First)와 일맥상통하는 알고리즘이다. 즉, 현재의 head 위치에서 seek time이 가장 짧은 (가장 가까운 거리에 있는) 요청부터 먼저 처리를 하는 알고리즘이다.
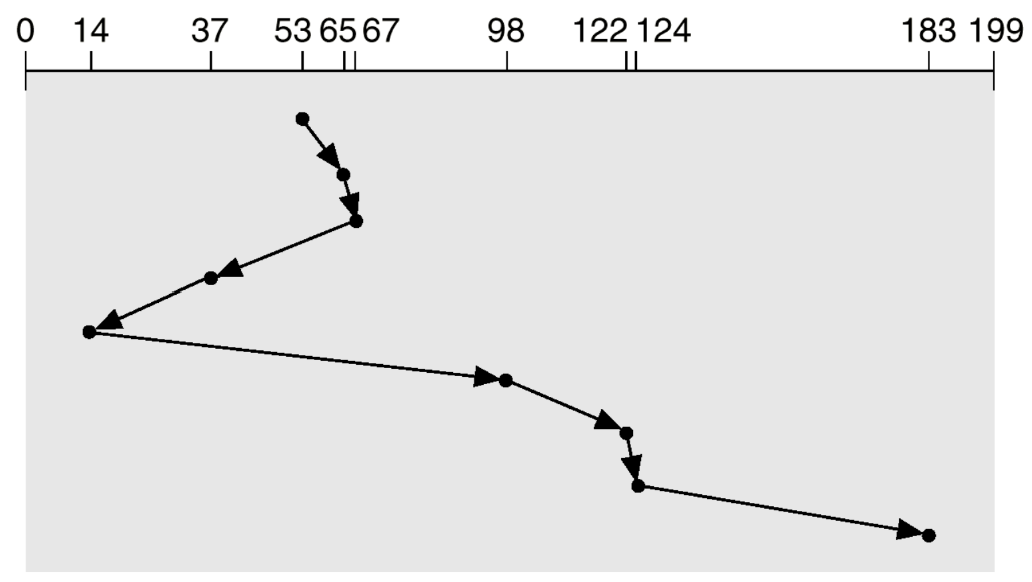
언뜻 보았을 때는 확실히 FCFS보다는 더 적게 이동하는 것을 알 수 있고 실제로 236 cylinder만큼을 이동한다.
그러나 이 알고리즘의 경우 문제점이 존재하는데, SJF 처럼 Starvation 문제가 발생한다는 점이다. 여기서는 위에서 설정한 setting 값만 했지만 실시간으로 계속 queue에 서비스를 받을 대상이 들어오는 상황일 때 만약 그 대상이 기존에 있던 대상보다 현재 head의 위치와 가깝다면 기존에 존재하던 요청들이 계속 뒤로 밀려나게 된다. 그런데 이렇게 밀려나는 과정이 언제 끝날지도 모르기 때문에 성능을 예측하기 힘들다는 문제점도 존재한다.
이를 개선하기 위한 알고리즘이 다음에 나올 SCAN알고리즘이다.
SCAN
: FCFS보다는 seek distance를 줄이면서 SSTF의 문제점을 완화시키는 방법
이전의 알고리즘과 다른 점은 SCAN의 경우 disk arm (head)가 disk의 끝에서 시작해서 반대쪽 끝까지 이동을 하면서 그 이동 과정에 존재하는 요청들을 순차적으로 처리를 한다는 점이다. 그 후 반대쪽 끝 지점에 도달을 했다면 다시 반대쪽 방향으로 돌아서 처음 시작한 위치로 돌아가면서 마찬가지로 경로 상의 모든 요청들을 처리한다.
이러한 scheduling 방식이 마치 엘리베이터의 원리와 비슷하다고 해서 Elevator algorithm이라고도 불린다.

이 경우 1번 swing 내에 반드시 service를 받는다는 보장이 생기기 때문에 SSTF의 문제점인 Starvation, Unpredictability을 동시에 해결할 수 있다. 이를 통해 계산을 하면 208 cylinder를 이동하게 된다.
그러나 이 알고리즘 역시 문제점이 존재하는데, Unfair wait time에 대한 문제가 발생한다. 쉽게 말하면 중간에 존재하는 요청들은 1번 swing 하는 동안 2번의 service 기회를 얻지만, 만약 요청이 위의 그림에서 0번이나 199번에 존재하게 되면 1번 swing 할 때 1번의 기회만 주어지게 된다. Worst case이 경우 평균 대기 시간이 늘어나게 된다는 문제점이 존재하게 된다.
C-SCAN
: Service를 받는 기회의 불균등을 해결하기 위한 방법으로 한 쪽 방향으로 이동할 때만 service를 하는 방법
C-SCAN의 경우 SCAN 알고리즘의 Circular 버전이다. 사실 Circular queue 처럼 원형의 형태를 갖는 것은 아니지만, SCAN에서 swing을 하는 과정을 한 방향으로만 하는 알고리즘이다. 즉, 한 방향으로 이동할 때 존재하는 요청들에 대해서는 무조건 service를 하고 반대쪽 끝에 도달했을 때 재빠르게 처음 지점으로 돌아가서 다시 반대 방향으로 이동하는 방식이다. 이렇게 하면 양쪽 끝에 있는 요청들도 중간과 동일하게 2번의 service 기회를 얻기 때문에 unfair wait time 문제가 존재하지 않게 된다.
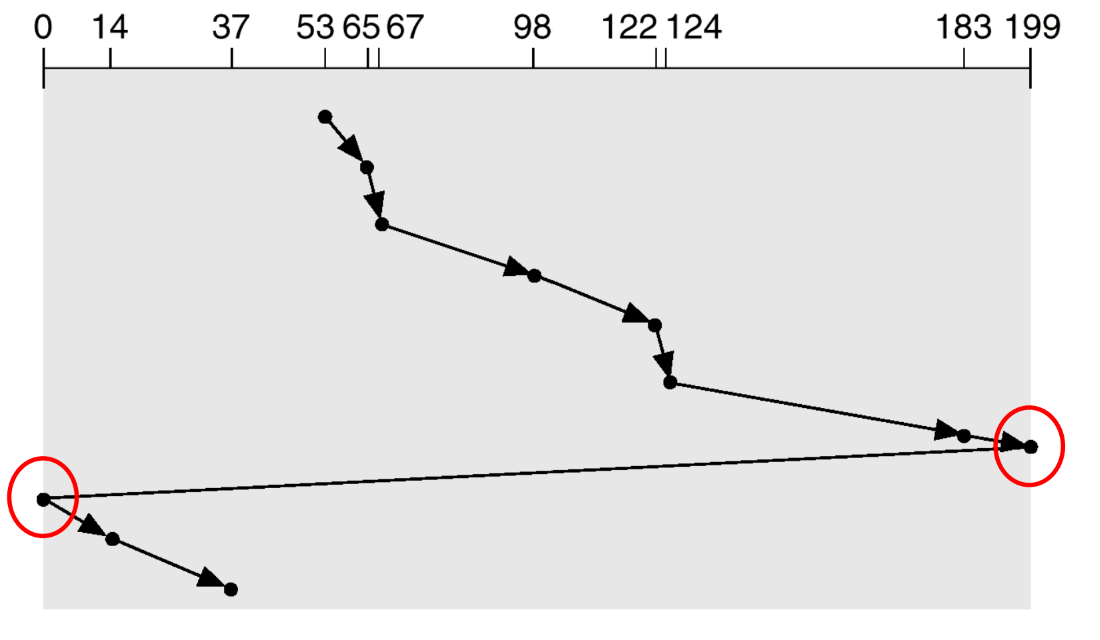
그러나, 이 경우 의미 없는 seek이 발생하기 때문에 #throughput 측면에서 SCAN이 더 짧아질 수 있다는 점이 존재한다. SCAN은 반대 방향으로도 service를 해주지만, C-SCAN은 반대 방향으로는 service를 하지 않기 때문에 처음 위치로 돌아오는 과정에서 의미 없는 seek time이 발생하게 되고, 무조건 제일 끝지점 (위의 그림에서는 199)을 찍고 돌아와야 하기 때문에 효율성 측면에서 좋다고 볼 수 없다.
이를 보완한 알고리즘이 C-LOOK이다.
C-LOOK
: 진행 방향에 더 이상 request가 없는데도 끝까지 전진하는 C-SCAN의 단점을 보완한 알고리즘
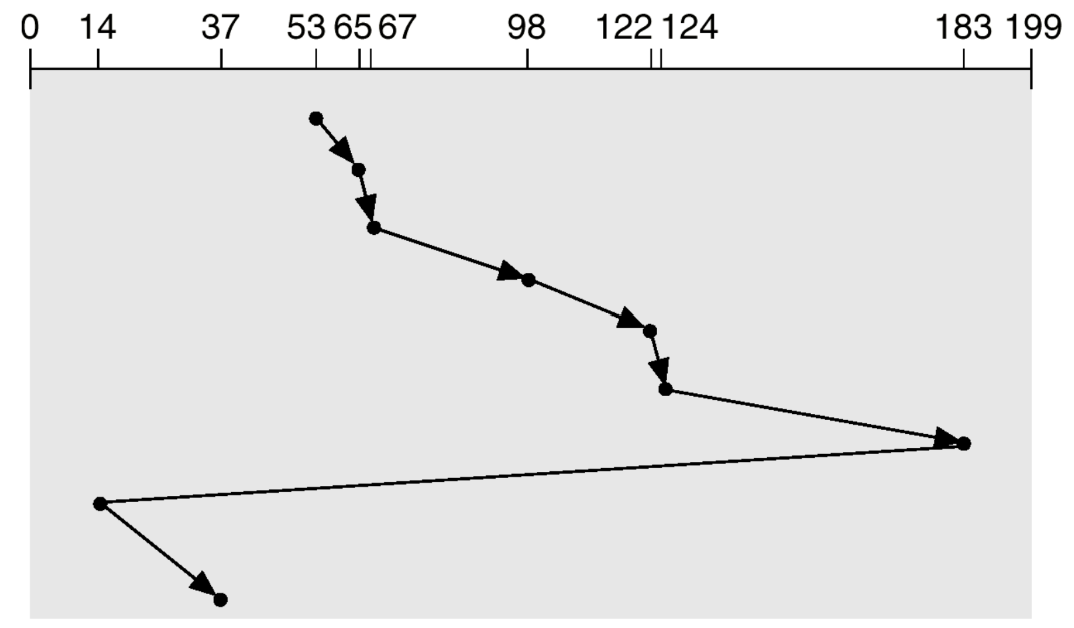
위의 그림을 보면 C-SCAN에서는 199를 무조건 찍고 돌아가는 과정이 queue에 있는 요청들 중 제일 큰 값인 183을 service한 뒤 다시 돌아가게 되고, 돌아갈 때도 queue의 제일 작은 값인 14로 돌아가고 있는 모습을 볼 수 있다.
Arm Stickiness Problem
: SCAN, C-SCAN, SSTF에서 매우 희박한 확률로 발생할 수 있는 문제이다. 하나 이상의 process들이 하나의 track에 대해 높은 access rate를 갖고 있을 때, 즉 queue에 동일한 요청들이 여러 개 존재할 때 이 process들이 전체 device를 독점할 수도 있다는 문제이다. 이러한 문제가 발생하면 starvation 문제가 발생할 확률이 매우 높다.

Disk Management
Physical formatting (Low-level formatting)
- Disk를 disk controller가 읽고 쓸 수 있도록 sector 단위로 나눈다.
- 각각의 sector는
[head + data(512 bytes) + trailer]로 구성된다. 이 때 head와 trailer에는 metadata가 존재한다. - header와 trailer는
sector의 번호와ECC (Error Correction Code)가 존재한다.- Error 발생 O bad sector
- Error 발생 X data 전달
- LBA와 mapping을 시키지 않은 여유 공간 (spare sectors/cylinder)들은 bad sector를 위해 남겨둔다.
Disk가 file들을 갖고 있을 수 있도록 하기 위해 OS는 disk에 OS의 자료구조를 기록할 필요가 있다.
- Disk를 하나 이상의 cylinder 그룹으로 partition 시켜서 각각을 독립적인 disk로 다룬다.
- Logical formatting : file system을 초기화하기 위한 자료구조
RAID (Redundant Array of Inexpensive (Independent) Disks)
: 여러 개의 하드 디스크에 일부 중복된 데이터를 나눠서 저장하는 기술로 작은 용량의 저장장치를 여러 대로 묶어서 대용량 저장장치를 만들어서 사용하는 기술을 의미한다.
RAID의 목적
- 여러 개의 디스크 모듈을 하나의 대용량 디스크처럼 사용할 수 있도록 한다.
- 여러 개의 디스크 모듈에 데이터를 나눠서 한번에 쓰고 한 번에 읽는 방식으로 입출력 속도를 높인다.
- 여러 개의 디스크를 모아서 하나의 디스크로 만들고 그 중 하나 혹은 그 이상의 디스크에 장애가 나더라도 최소한 데이터가 사라지는 것을 방지한다.
RAID Level
Level 0 : Block striping, non-redundancy
: data 손실이 치명적이지 않은 고성능의 application에 적용된다.
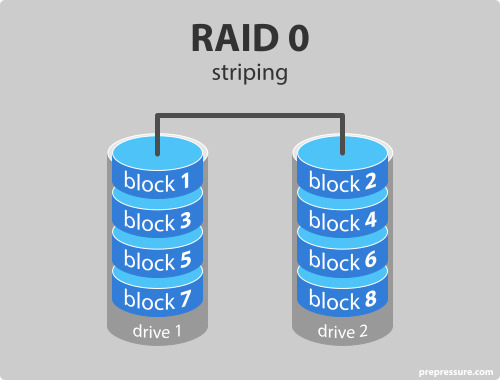
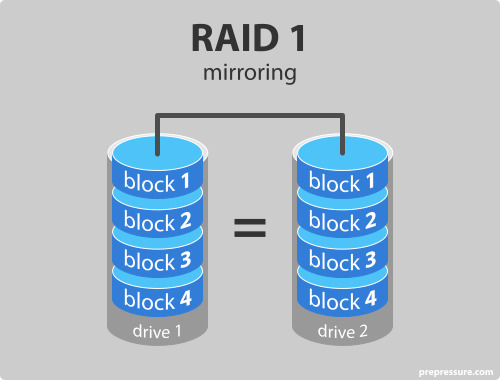
Level 1 : Mirrored disks with block striping
: disk를 복제하는 방법으로 디스크 장애를 대비하여 백업 용으로 다른 디스크를 동일하게 구성하는 방법 이다. 디스크에 기록되는 모든 데이터를 다른 디스크에 복사하는 방법으로 복구 능력을 제공한다. 그렇기 때문에 database system에서 log를 저장하는 것과 같은 application에 주로 사용된다. 그러나, 똑같은 양의 disk에 복제를 하기 때문에 다른 level보다 사용하는 disk 양이 반으로 줄어들게 된다는 단점이 존재한다.
Level 2 : Bit-level striping with ECC disks
Level 3 : Byte-level striping with a dedicated parity disk
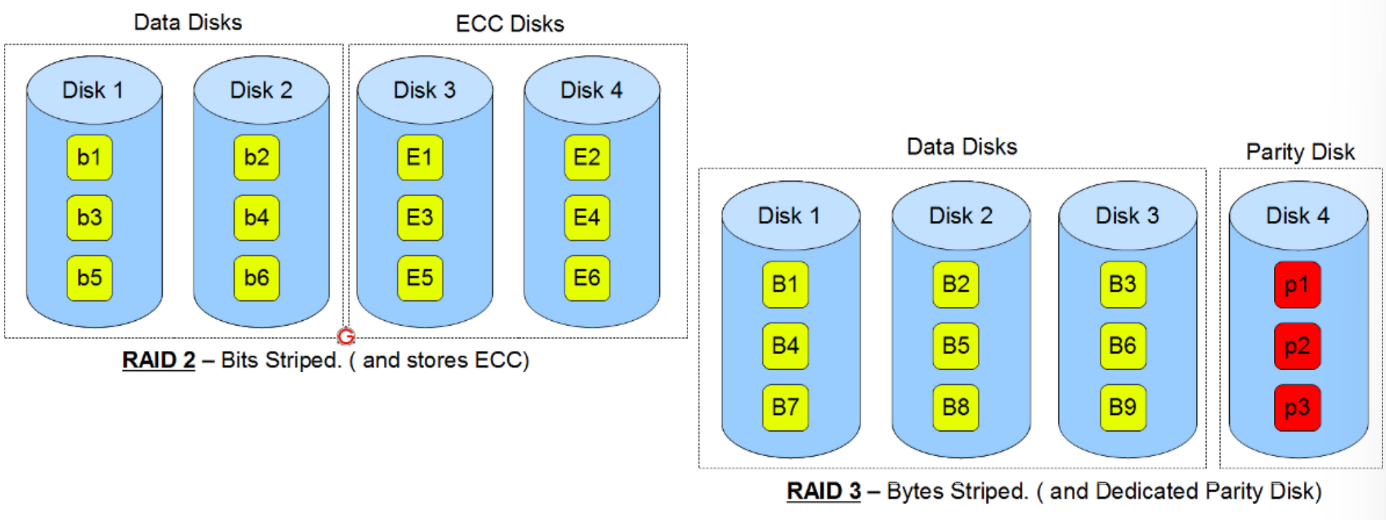
Bit, Byte 단위로 striping을 하게 되면 seek overhead가 굉장히 커지기 때문에 level 2, 3은 잘 사용되지 않는다고 한다.
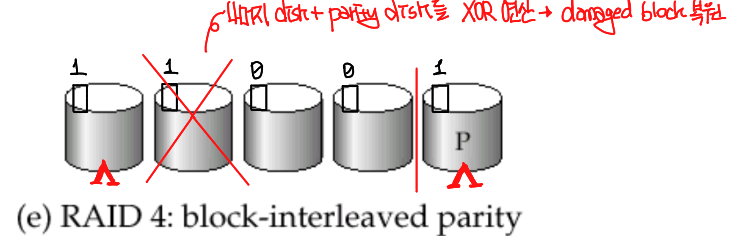
Level 4 : Block-interleaved parity, block-level striping
: N개의 서로 다른 disk 각각에 parity block을 setting 해서 data block에 쓰기 작업을 할 때 대응하는 parity block의 bit도 연산된 뒤 parity disk에 작성이 되게 된다.
이 방법의 경우 disk 손상이 발생했을 때 block들의 bit들을 XOR 연산으로 복구할 수 있다는 장점이 있지만, bottleneck 현상이 발생하게 되면 write의 성능이 disk가 아닌 1개의 parity disk의 성능에 수렴하게 된다는 단점이 존재한다.
Level 5 : Block-interleaved distributed parity, block-level striping
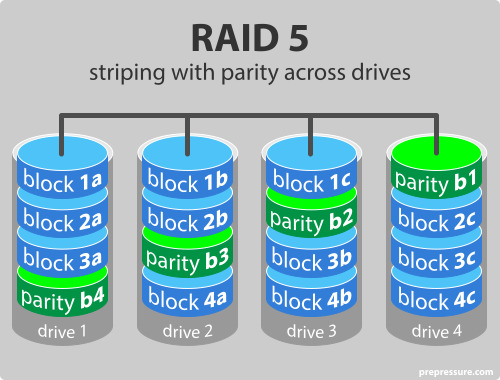
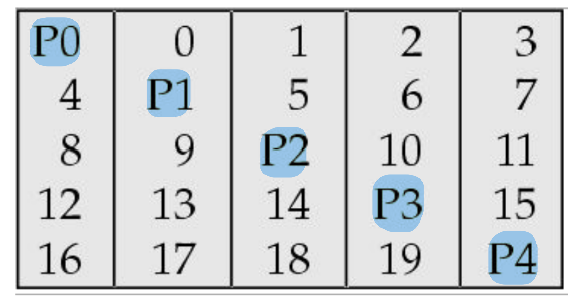
Level 4에서 달라진 점은 parity block이 1개만 존재했던 것이 각각의 block에 존재한다는 점이다. 그렇기 때문에 bottleneck 현상이 발생할 가능성이 줄어들게 된다.
Choice of RAID Level
위에서 언급했듯이 Level 2, 3은 bit, byte 단위이기 때문에 잘 사용하지 않고 남은 1, 4, 5 중에서 Level 4의 경우 Level5가 존재하는 이상 더 좋은 Level5를 사용할 것이 자명하기 때문에 Level1과 Level5가 가장 자주 쓰이게 된다.
여기까지 Mass Storage Management에 대해 알아보았다.
다음 posting에서는 I/O system에 대해 다루고 길었던 OS posting을 마무리하고자 한다.
