그랩컷
: Grabcut - Graph cut 기반 영역 분할 알고리즘
- 영상의 픽셀을 그래프 정점으로 갖누하고, 픽셀들을 두 개의 그룹으로 나누는 최적의 컷을 찾는 방식
참고 page
https://grabcut.weebly.com/background--algorithm.html
https://www.cs.ru.ac.za/research/g02m1682/
https://docs.opencv.org/3.4/d8/d83/tutorial_py_grabcut.html
그랩컷 영상 분할 동작 방식
1) 사각형 지정 자동 분할
2) 사용자가 지정한 foreground/background 정보를 활용하여 영상 분할

= 각각의 pixel을 vertex로 인식해서 최적의 위치를 Cut하는 line을 찾는 것이 목표.
그랩컷 함수
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount, mode=None)
-> mask, bgdModel, fgdModel1) img : 입력 영상. 8비트 3채널
2) mask : 입출력 마스크. cv2.GCBGD(0), cv2.GC_FGD(1), cv2.PR_BGD(2), cv2.GC_PR_FGD(3) 네 개의 값으로 구성되어 있으며 cv2.GC_INIT_WITH_RECT 모드로 초기화
3) rect : ROI 영역. cv2.GC_INIT_WITH_RECT 모드에서만 사용됨
4) bgdModel : 임시 배경 모델 행렬. 같은 영상 처리 시에는 변경 금지
→ background
5) fgdModel : 임시 전경 모델 행렬. 같은 영상 처리 시에는 변경 금지
→ foreground
6) iterCount : 결과 생성을 위한 반복 횟수
7) mode : cv2.GC로 시작하는 모드 상수. 보통 cv2.GC_INIT_WITH_RECT 모드로 초기화하고, cv2.GC_INIT_WITH_MASK 모드로 업데이트함
예시 코드
- 니모 분리하기
import sys
import numpy as np
import cv2
# 입력 영상 불러오기
src = cv2.imread('nemo.jpg')
if src is None:
print('Image load failed!')
sys.exit()
# 사각형 지정을 통한 초기 분할
rc = cv2.selectROI(src) # ROI Selector 창이 뜨면 사각형 영역을 지정해주면 됨
mask = np.zeros(src.shape[:2], np.uint8) # 검정색으로 입력 영상과 동일한 크기의 mask 생성
cv2.grabCut(src, mask, rc, None, None, 5, cv2.GC_INIT_WITH_RECT)
# 5번 iteration
# 0: cv2.GC_BGD, 2: cv2.GC_PR_BGD
mask2 = np.where((mask == 0) | (mask == 2), 0, 1).astype('uint8')
# 0과 2가 background이므로 background는 0으로, foreground는 1로 set
dst = src * mask2[:, :, np.newaxis]
# 초기 분할 결과 출력
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()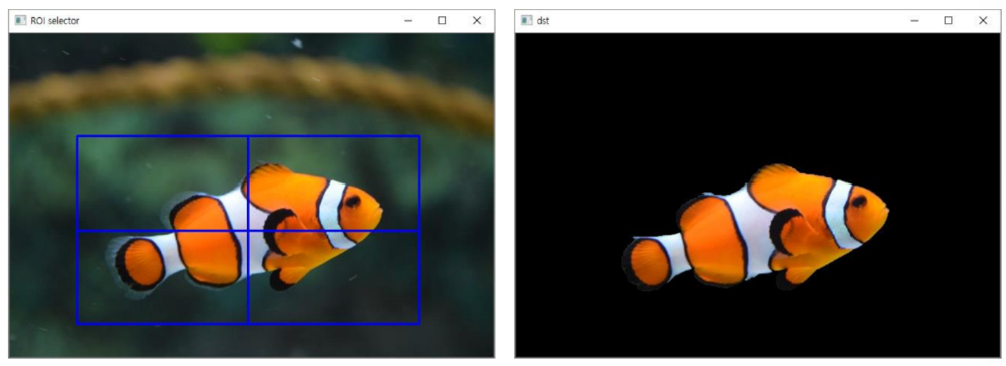
- G.O.A.T 분리하기
import sys
import numpy as np
import cv2
# 입력 영상 불러오기
src = cv2.imread('ironman.webp')
if src is None:
print('Image load failed!')
sys.exit()
# 사각형 지정을 통한 초기 분할
mask = np.zeros(src.shape[:2], np.uint8) # 마스크
bgdModel = np.zeros((1, 65), np.float64) # 배경 모델
fgdModel = np.zeros((1, 65), np.float64) # 전경 모델
# bgd와 fgd는 무조건 1행 65열짜리 이미지로 만들어줘야함
rc = cv2.selectROI(src)
cv2.grabCut(src, mask, rc, bgdModel, fgdModel, 1, cv2.GC_INIT_WITH_RECT)
# 0: cv2.GC_BGD, 2: cv2.GC_PR_BGD
mask2 = np.where((mask == 0) | (mask == 2), 0, 1).astype('uint8')
dst = src * mask2[:, :, np.newaxis]
# 초기 분할 결과 출력
cv2.imshow('dst', dst)
# 마우스 이벤트 처리 함수 등록
def on_mouse(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
cv2.circle(dst, (x, y), 3, (255, 0, 0), -1)
cv2.circle(mask, (x, y), 3, cv2.GC_FGD, -1)
cv2.imshow('dst', dst)
elif event == cv2.EVENT_RBUTTONDOWN:
cv2.circle(dst, (x, y), 3, (0, 0, 255), -1)
cv2.circle(mask, (x, y), 3, cv2.GC_BGD, -1)
cv2.imshow('dst', dst)
elif event == cv2.EVENT_MOUSEMOVE:
if flags & cv2.EVENT_FLAG_LBUTTON:
cv2.circle(dst, (x, y), 3, (255, 0, 0), -1)
cv2.circle(mask, (x, y), 3, cv2.GC_FGD, -1)
cv2.imshow('dst', dst)
elif flags & cv2.EVENT_FLAG_RBUTTON:
cv2.circle(dst, (x, y), 3, (0, 0, 255), -1)
cv2.circle(mask, (x, y), 3, cv2.GC_BGD, -1)
cv2.imshow('dst', dst)
# 마우스 좌클릭 : foreground, 우클릭 : background
cv2.setMouseCallback('dst', on_mouse) # 마우스 이벤트 받아오기
while True:
key = cv2.waitKey()
if key == 13: # ENTER
# 사용자가 지정한 전경/배경 정보를 활용하여 영상 분할
cv2.grabCut(src, mask, rc, bgdModel, fgdModel, 1, cv2.GC_INIT_WITH_MASK)
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
dst = src * mask2[:, :, np.newaxis]
cv2.imshow('dst', dst)
elif key == 27:
break
cv2.destroyAllWindows()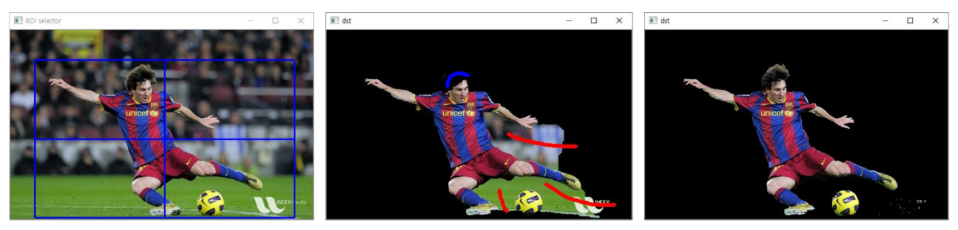
모멘트 기반 객체 검출
모멘트
: 영상의 형태를 표현하는 일련의 실수값
- 특정 함수 집합과의 상관 관계 형태로 계산
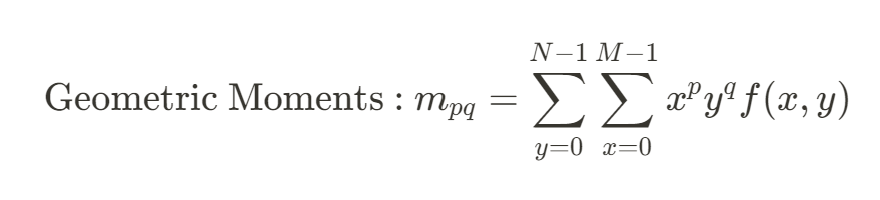
-> Geometric Moments, Central Moments, Normalized central Moments 사용 가능 - HU의 7개 불변 모멘트
1) 3차 이하의 정규화된 중심 모멘트를 조합하여 만든 7개의 모멘트 값
2) 영상의 크기, 회전, 이동, 대칭 변환에 불변
-> 객체에 변형이 있어도 모멘트 값에는 변화가 없음 - 모양 비교 함수
cv2.matchShapes(contour1, contour2, method, parameter)
-> retval1) contour1 : 첫 번째 외곽선 또는 그레이스케일 영상
2) contour2 : 두 번째 외곽선 또는 그레이스케일 영상
3) method : 비교 방법 지장. cv2.CONTOURS_MATCH_I1, cv2.CONTOURS_MATCH_I2, cv2.CONTOURS_MATCH_I3 중 하나 사용.
4) parameter : 사용되지 않음. 0 지정
5) retval : 두 외곽선 또는 그레이스케일 영상 사이의 거리 (distance)
6) 참고 사항
-> HU의 불변 모멘트를 이용하여 두 외곽선 또는 영상의 모양을 비교

... 3번째 방법이 정규화도 포함되어 있기 때문에 가장 좋은 방법이라고 함
import sys
import numpy as np
import cv2
# 영상 불러오기
obj = cv2.imread('spades.png', cv2.IMREAD_GRAYSCALE)
src = cv2.imread('symbols.png', cv2.IMREAD_GRAYSCALE)
if src is None or obj is None:
print('Image load failed!')
sys.exit()
# 객체 영상 외곽선 검출
_, obj_bin = cv2.threshold(obj, 128, 255, cv2.THRESH_BINARY_INV)
# 중간값과 끝값을 이용해서 반전
obj_contours, _ = cv2.findContours(obj_bin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# 외곽선 검출
obj_pts = obj_contours[0]
# 입력 영상 분석
_, src_bin = cv2.threshold(src, 128, 255, cv2.THRESH_BINARY_INV)
contours, _ = cv2.findContours(src_bin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# 결과 영상
dst = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
# 입력 영상의 모든 객체 영역에 대해서
for pts in contours:
if cv2.contourArea(pts) < 1000:
continue
rc = cv2.boundingRect(pts)
cv2.rectangle(dst, rc, (255, 0, 0), 1)
# 모양 비교
dist = cv2.matchShapes(obj_pts, pts, cv2.CONTOURS_MATCH_I3, 0)
# distance 값 return
cv2.putText(dst, str(round(dist, 4)), (rc[0], rc[1] - 3),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0), 1, cv2.LINE_AA)
# distance 값을 화면에 출력
if dist < 0.1:
cv2.rectangle(dst, rc, (0, 0, 255), 2)
#distance 값이 0.1보다 작으면 같은 객체로 인식
cv2.imshow('obj', obj)
cv2.imshow('dst', dst)
cv2.waitKey(0)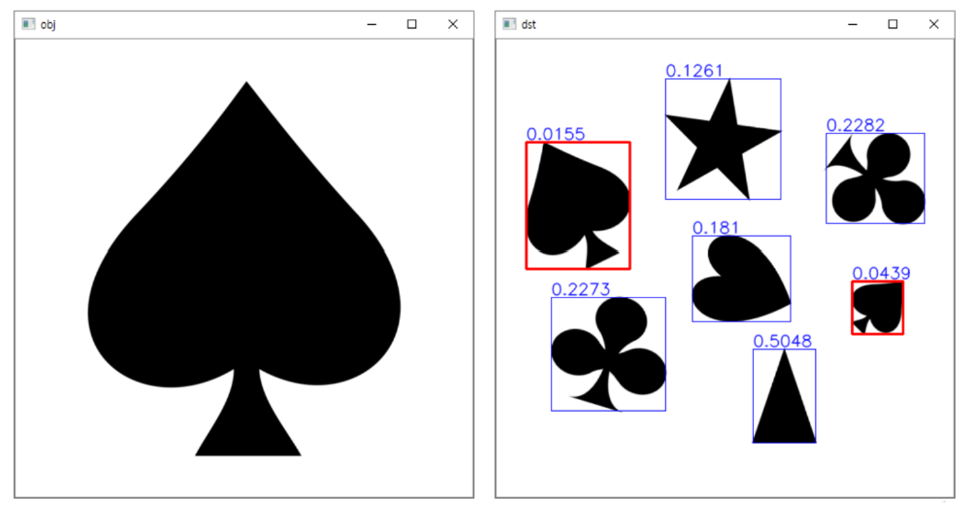
템플릿 매칭 (1) : 이해하기
템플릿 매칭
: 입력 영상에서 (작은 크기의) 템플릿 영상과 일치하는 부분을 찾는 기법
- 템플릿 : 찾을 대상이 되는 작은 영상. patch
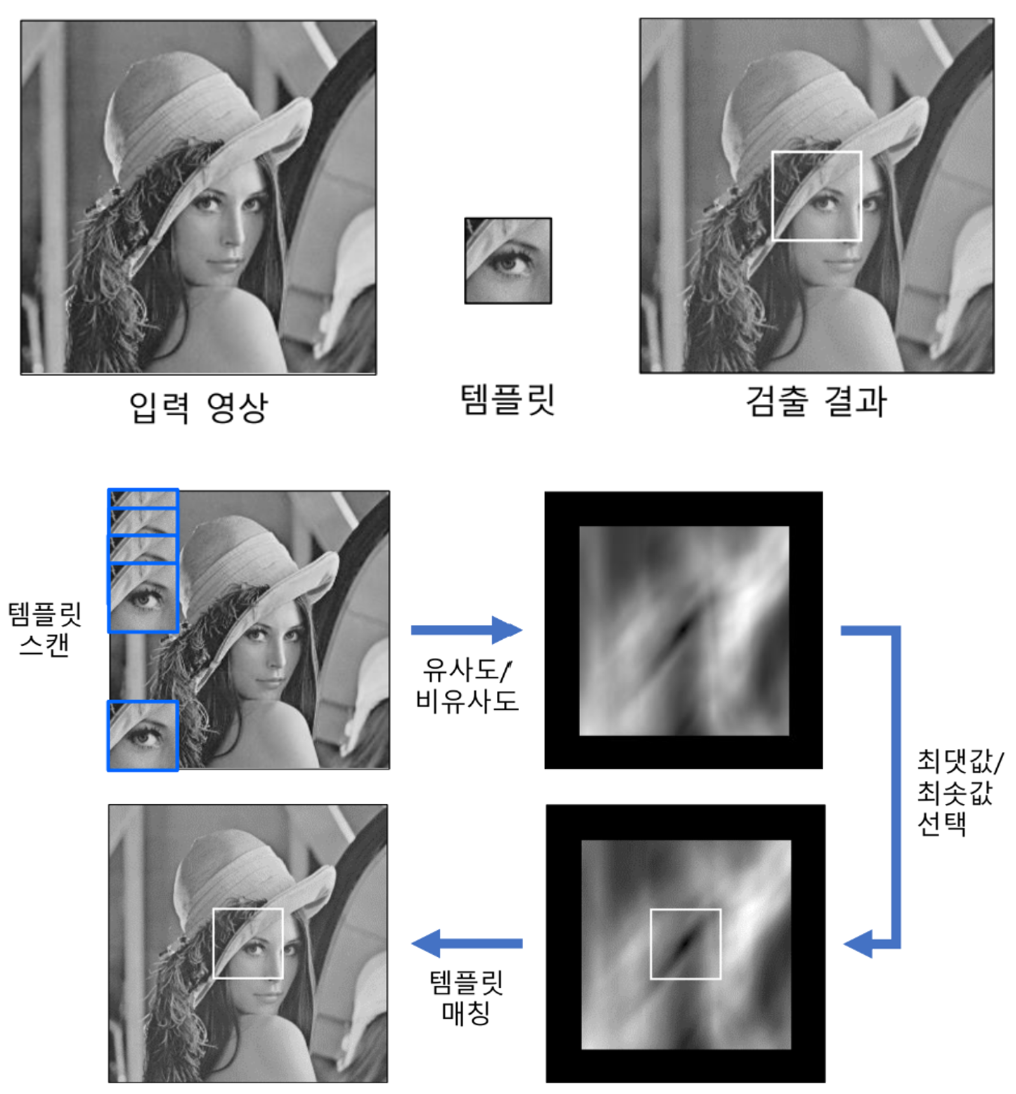
-> 유사도인 경우 최댓값을 matching, 비유사도인 경우 최솟값을 matching - 템플릿 매칭 함수
cv2.matchTemplate(image, templ, method, result=None, mask=None)
-> result1) image : 입력 영상. 8비트 또는 32비트
2) templ : 템플릿 영상. image보다 같거나 작은 크기, 같은 타입
3) method : 비교 방법. cv2.TM_ 으로 시작하는 플래그 지정
| TM_SQDIFF / TM_SQDIFF_NORMED | TM_CCORR / TM_CCORR_NORMED | TM_CCOEFF / TM_CCOEFF_NORMED |
|---|---|---|
| Sum of squared difference | (Cross) Correlation | Correlation Coefficient |
4) result : 비교 결과 행렬. numpy.ndarray.dtype=numpy.float32
image의 크기가 W x H이고, templ의 크기가 w x h이면 result 크기는 (W-w+1) x (H-h+1)

=> 밝기에 대한 보정을 한 뒤 연산을 진행한 결과물이 훨씬 더 좋음
- 두 번째 사진 (TM_CCORR)의 경우 얼굴 인식이 제대로 되지 않았는데, 흰색 부분의 Correlation 값이 크게 나오기 때문에 NORMED를 하거나 Normalize를 한 후 사용하는 것이 좋음

- TM_SQDIFF : distance return
- TM_CCORR : Correlation을 찾아서 위치 return

예시 코드
import sys
import numpy as np
import cv2
# 입력 영상 & 템플릿 영상 불러오기
src = cv2.imread('circuit.bmp', cv2.IMREAD_GRAYSCALE)
templ = cv2.imread('crystal.bmp', cv2.IMREAD_GRAYSCALE)
if src is None or templ is None:
print('Image load failed!')
sys.exit()
# 입력 영상 밝기 50증가, 가우시안 잡음(sigma=10) 추가
noise = np.zeros(src.shape, np.int32)
cv2.randn(noise, 50, 10) # 가우시안 형태의 random number generate
src = cv2.add(src, noise, dtype=cv2.CV_8UC3) # src에 noise를 더해줌
# 템플릿 매칭 & 결과 분석
res = cv2.matchTemplate(src, templ, cv2.TM_CCOEFF_NORMED)
res_norm = cv2.normalize(res, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
_, maxv, _, maxloc = cv2.minMaxLoc(res) # minv,maxv,minloc,maxloc을 return하는데 max만 사용함
print('maxv:', maxv)
print('maxloc:', maxloc)
# 매칭 결과를 빨간색 사각형으로 표시
th, tw = templ.shape[:2]
dst = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
cv2.rectangle(dst, maxloc, (maxloc[0] + tw, maxloc[1] + th), (0, 0, 255), 2)
# 결과 영상 화면 출력
cv2.imshow('res_norm', res_norm)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
maxv: 0.9796600341796875
maxloc: (568, 320)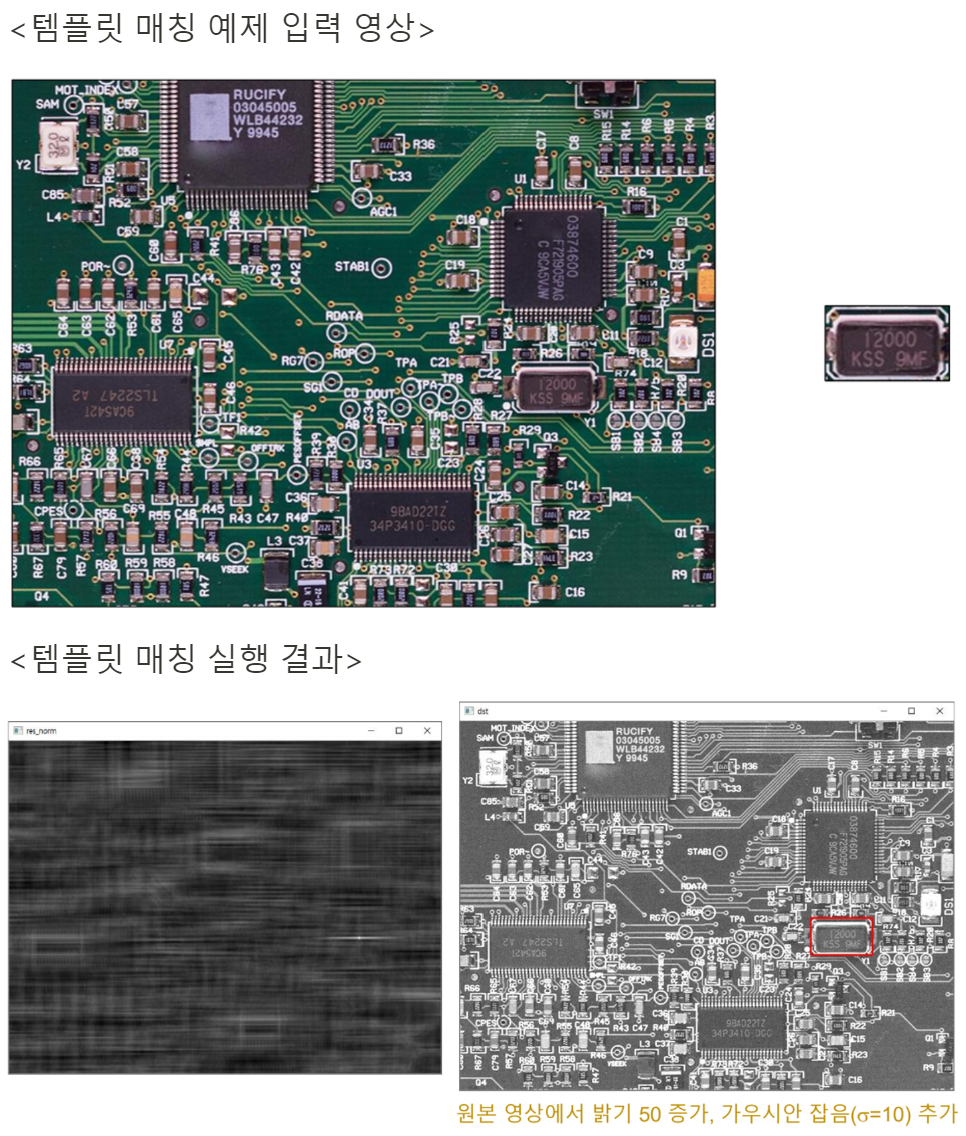
템플릿 매칭 (2) : 인쇄체 숫자 인식
인식
: 여러 개의 클래스 중에서 가장 유사한 클래스를 선택하는 것

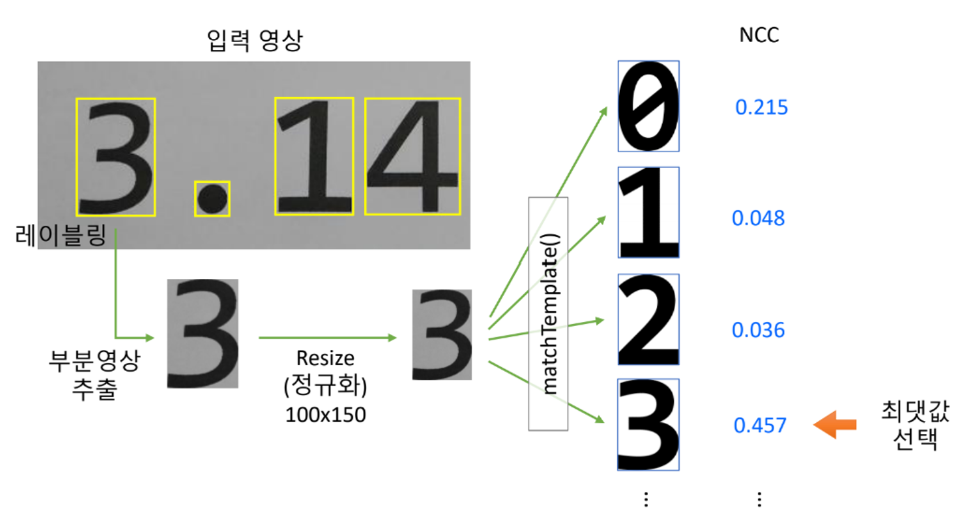
- 숫자 템플릿 영상 생성
1) Consolas 폰트로 쓰여진 숫자 영상을 digit0.bmp ~ digit9.bmp로 저장
2) 각 숫자 영상의 크기는 100x150 크기로 정규화

- 인쇄체 숫자 인식 방법
import sys
import numpy as np
import cv2
def load_digits():
img_digits = []
for i in range(10):
filename = './digits/digit{}.bmp'.format(i)
img_digits.append(cv2.imread(filename, cv2.IMREAD_GRAYSCALE))
if img_digits[i] is None:
return None
return img_digits
def find_digit(img, img_digits):
max_idx = -1
max_ccoeff = -1
# 최대 NCC 찾기
for i in range(10):
img = cv2.resize(img, (100, 150))
res = cv2.matchTemplate(img, img_digits[i], cv2.TM_CCOEFF_NORMED)
if res[0, 0] > max_ccoeff:
max_idx = i
max_ccoeff = res[0, 0]
return max_idx
def main():
# 입력 영상 불러오기
src = cv2.imread('digits_print.bmp')
if src is None:
print('Image load failed!')
return
# 100x150 숫자 영상 불러오기
img_digits = load_digits() # list of ndarray
if img_digits is None:
print('Digit image load failed!')
return
# 입력 영상 이진화 & 레이블링
src_gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
_, src_bin = cv2.threshold(src_gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
cnt, _, stats, _ = cv2.connectedComponentsWithStats(src_bin)
# 숫자 인식 결과 영상 생성
dst = src.copy()
for i in range(1, cnt):
(x, y, w, h, s) = stats[i]
if s < 1000:
continue
# 가장 유사한 숫자 이미지를 선택
digit = find_digit(src_gray[y:y+h, x:x+w], img_digits)
cv2.rectangle(dst, (x, y, w, h), (0, 255, 255))
cv2.putText(dst, str(digit), (x, y - 4), cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
두 숫자의 글꼴이 달라서 consolas 글꼴은 제대로 인식을 하지만, arial 글꼴은 제대로 인식을 하지 못하는 것을 알 수 있음
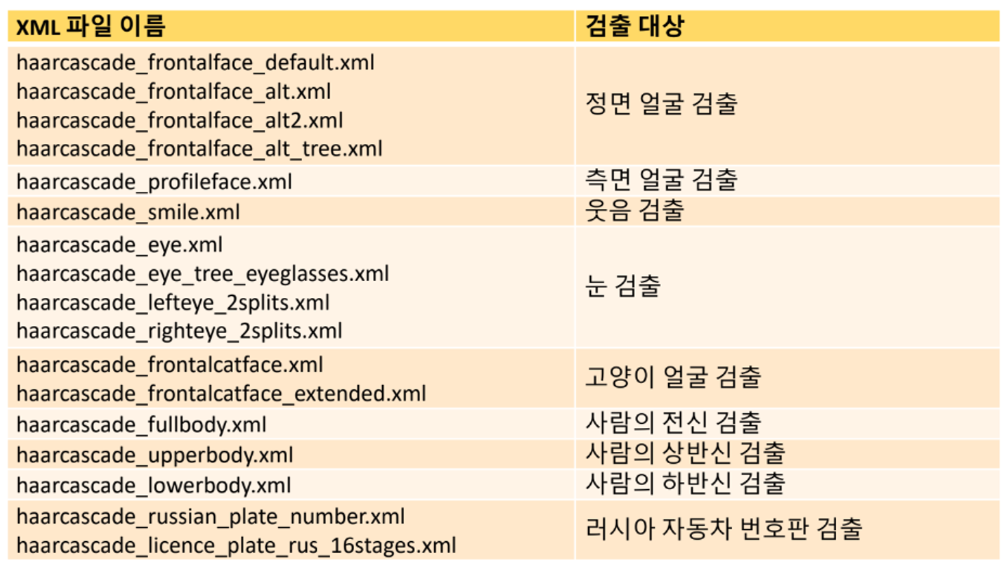
캐스케이드 분류기 : 얼굴 검출
https://docs.opencv.org/4.x/db/d28/tutorial_cascade_classifier.html
Viola-Jones 얼굴 검출기
: Positive 영상 (얼굴 영상)과 Negative 영상 (얼굴 아닌 영상)을 훈련하여 빠르고 정확하게 얼굴 영역을 검출
-
기존 방법과의 차별점
- 유사 하르 특징을 사용
- AdaBoost에 기반한 강한 분류 성능
- Cascade (외관) 방식을 통한 빠른 동작 속도
-
기존 얼굴 검출 방법보다 약 15배 빠르게 동작
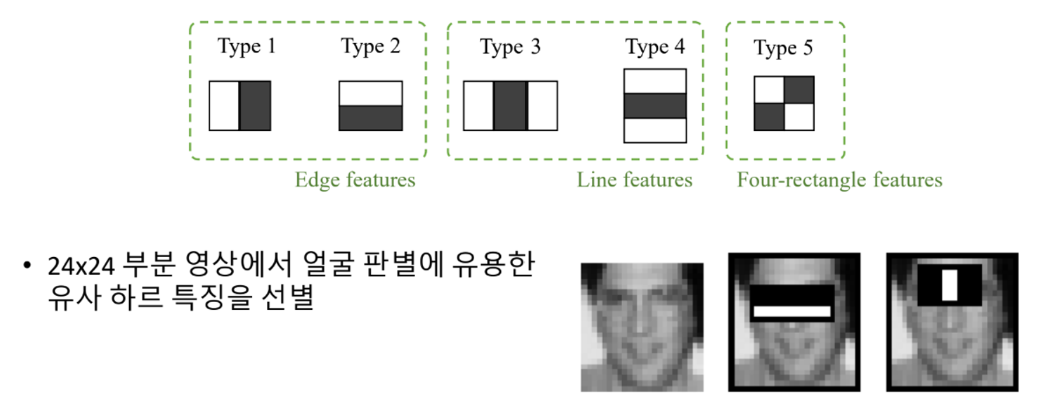
유사 하르 특징 (Harr-like features)
- 사각형 형태의 필터 집합을 사용
- 흰색 사각형 영역 값의 합에서 검정색 사각형 영역 픽셀 값을 뺀 결과 값을 추출
cv2.CascadeClassifier 객체 생성 및 학습 데이터 불러오기
cv2.CascadeClassifier() -> <CascadeClassifier Object>
cv2.CascadeClassifier(filename) -> <CascadeClassifier Object>
cv2.CascadeClassifier.load(filename) -> retval1) filename : XML 파일 이름
2) retval : 성공하면 True, 실패하면 False
- CascadeClassifier 멀티스케일 객체 검출 함수
cv2.CascadeClassifier.detectMultiScale(image, scaleFactor=None,
minNeighbors=None, flags=None, minSize=None, maxSize=None)
-> result1) image : 입력 영상 (cv2.CV_8U)
2) scaleFactor : 영상 축소 비율. 기본값은 1.1
3) minNeighbors : 얼마나 많은 이웃 사각형이 검출되어야 최종 검출 영역으로 설정할지를 지정. 기본값은 3
4) flags : (현재) 사용되지 않음
5) minSize : 최소 객체 크기 (w.h) 튜플
6) maxSize : 최대 객체 크기. (w,h) 튜플
7) result : 검출된 객체의 사각형 정보 (x,y,w,h,)를 담은 numpy.ndarray.shape=(N,4).dtype=unmpy.uint32
예제 코드
import sys
import numpy as np
import cv2
src = cv2.imread('lenna.bmp')
if src is None:
print('Image load failed!')
sys.exit()
classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
if classifier.empty():
print('XML load failed!')
sys.exit()
tm=cv2.TickMeter()
tm.start()
faces = classifier.detectMultiScale(src, scaleFactor=1.2, minSize=(100,100))
tm.stop()
print(tm.getTimeMilli())
# parameter를 조절하면 속도를 빠르게 처리할 수 있음
for (x, y, w, h) in faces:
cv2.rectangle(src, (x, y, w, h), (255, 0, 255), 2)
cv2.imshow('src', src)
cv2.waitKey()
cv2.destroyAllWindows()
HOG 보행자 검출
HOG (Histogram of Oriented Gradients)
- 영상의 지역적 그래디언트 방향 정보를 특징 벡터로 사용

- HOG 기술자 객체 생성 및 보행지 감츨을 위해 학습된 분류기 계수 불러오기
cv2.HOGDescriptor() -> <CascadeClassifier object>
cv2.HOGDescriptor_getDefaultPeopleDetector() -> retval- SVM 분류기 계수 등록하기
cv2.HOGDescriptor.setSVMDetector(svmdetector) -> None1) svmdetector : 선형 SVM 분류기를 위한 계수
- HOG 멀티스케일 객체 검출 함수
cv2.HOGDescriptor.detectMultiScale(img, hitThreshold=None, winStride=None,
padding=None, scale=None, finalThreshold=None,
useMeanshiftGrouping=None) -> fondLocations, foundWeights1) img : 입력 영상. cv2.CV_8UC1 또는 cv2.CV_8UC3
2) hitThreshold : 특징 벡터와 SVM 분류 평면까지의 거리에 대한 임계값
3) winStride : 셀 윈도우 이동 크기. (0,0) 지정 시 셀 크기와 같게 설정
4) padding : 패딩 크기
5) scale : 검색 윈도우 크기 확대 비율. 기본값은 1.05
6) finalThreshold : 검출 결정을 위한 임계값
7) useMeanshiftGrouping : 겹쳐진 검색 윈도우를 합치는 방법 지정 플래그
8) foundLocations : (출력) 검출된 사각형 영역 정보
9) foundWeights : (출력) 검출된 사각형 영역에 대한 신뢰도
예시 코드
import sys
import random
import numpy as np
import cv2
# 동영상 불러오기
cap = cv2.VideoCapture('vtest.avi')
if not cap.isOpened():
print('Video open failed!')
sys.exit()
# 보행자 검출을 위한 HOG 기술자 설정
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
while True:
ret, frame = cap.read()
if not ret:
break
# 매 프레임마다 보행자 검출
detected, _ = hog.detectMultiScale(frame)
# 검출 결과 화면 표시
for (x, y, w, h) in detected:
c = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
cv2.rectangle(frame, (x, y, w, h), c, 3)
cv2.imshow('frame', frame)
if cv2.waitKey(10) == 27:
break
cv2.destroyAllWindows()
