TCAT 서비스 기술 개발
1. 프로젝트 소개
우리가 하는 프로젝트의 주제는 공연 후기 기록/공유 웹사이트 TCAT이다. 이 프로젝트의 백엔드 개발자로 기능 개발을 담당하였다. 사용한 기술 스택은 Springboot Framework를 이용했고, OCR로 티켓의 이미지를 읽고 데이터를 전처리하기 위해 Flask를 사용했다.
전체 개발 Github 링크는 다음과 같다.
github
시스템 아키텍쳐는 다음과 같다.
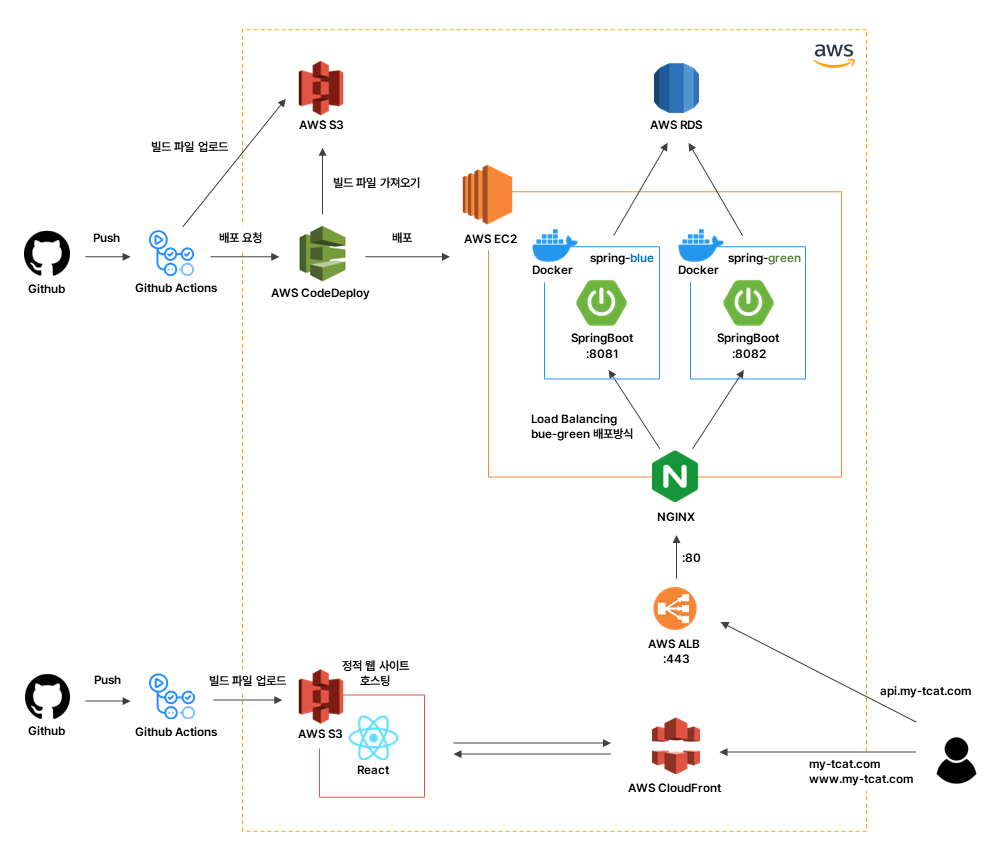
크게 백엔드, 프론트엔드 개발, OCR, 배포로 나눌 수 있다.
이번 블로그에서는 백엔드 개발을 필수적으로 거쳐야하는 기본 세팅과 개발과정에서 어려움을 느꼈던 무한스크롤 및 페이지네이션에 대해서 다룰 것이다.
2. 데이터베이스 구축
ERD CLOUD 플랫폼을 이용하여 데이터베이스 구축에 이용했다.
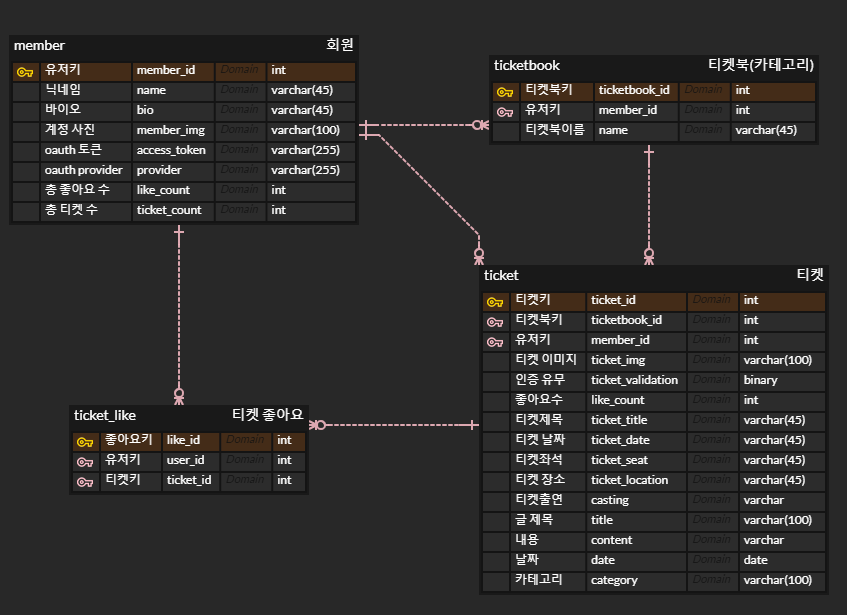
차후 초기 데이터베이스를 기준으로 구독 기능을 추가하면서 follows 테이블도 추가하였다.
데이터베이스는 AWS RDS를 이용하였고, springboot의 JPA 데이터베이스를 이용했다.
2-1. AWS RDS, Springboot 연결하기
1. 데이터베이스 생성
우선 RDS설정하는 방법에 대해서 알아보자.
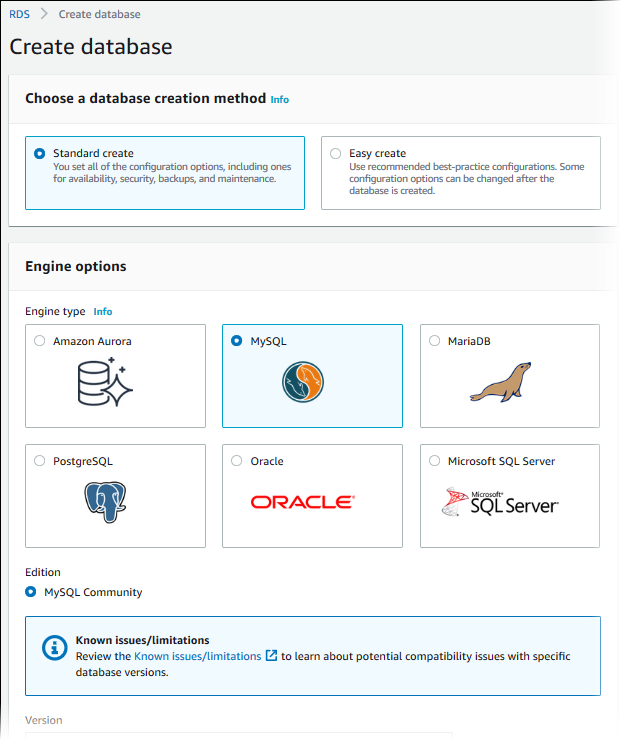
AWS 사이트에서 RDS생성하기 버튼을 눌러 사용하고자 하는 엔진 타입을 선택한다. TCAT프로젝트 같은 경우 MySQL을 사용했기 때문에 MySQL을 선정하였다.
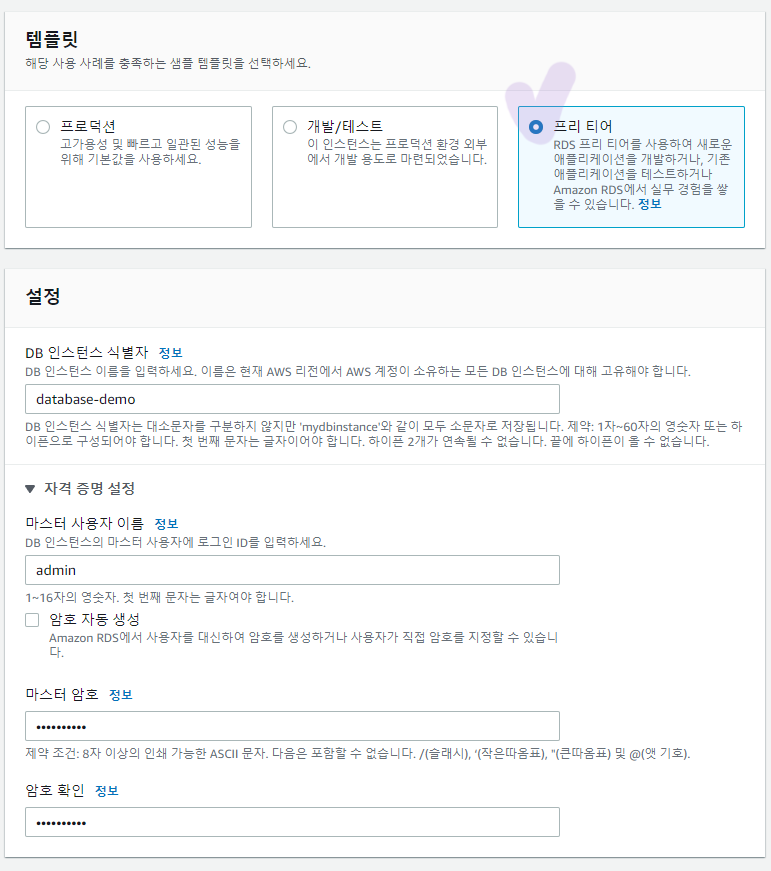
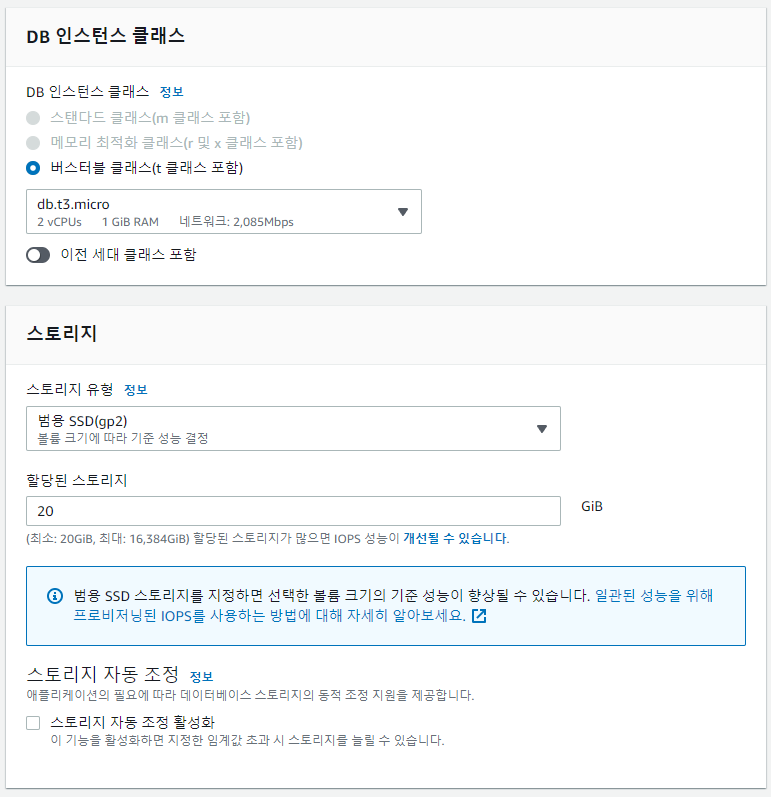
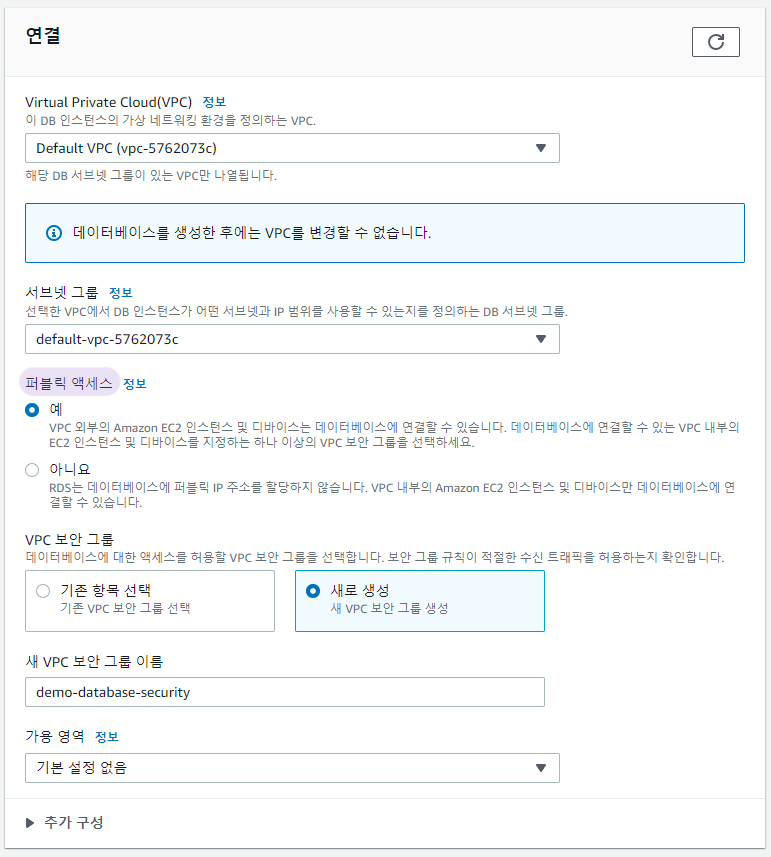
이후 나머지 설정은 프리티어를 사용할 것이기 때문에 기본값으로 설정하고 비밀번호를 정한뒤 데이터베이스 생성하기를 눌러 생성을 완료했다. 초기데이터이름은 mytcatdb로 했다.

엔드포인트와 포트번호는 스프링부트에서 연결할때 사용할 정보이니 잘 기억해두기로 하자
2. 보안그룹 설정
생성한 데이터베이스의 상세화면으로 넘어가 보안그룹을 추가한다.
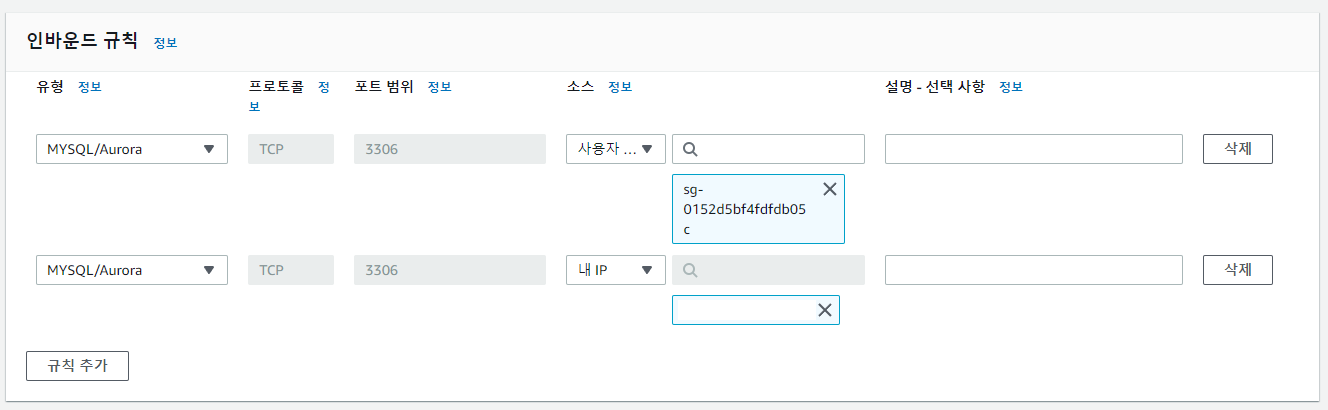
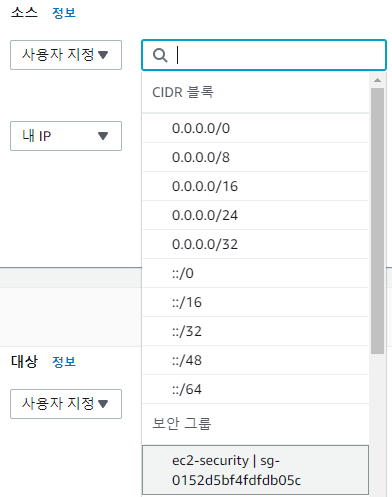
인바운드 규칙은 MySQL로 하고 DB에 접근할 수 있도록 'ec2-security'의 보안 그룹을 선택하고, 내 로컬 PC에서도 접근할 수 있도록 '내 IP'를 추가하면 끝이다.

3. MySQL Workbench에 연결
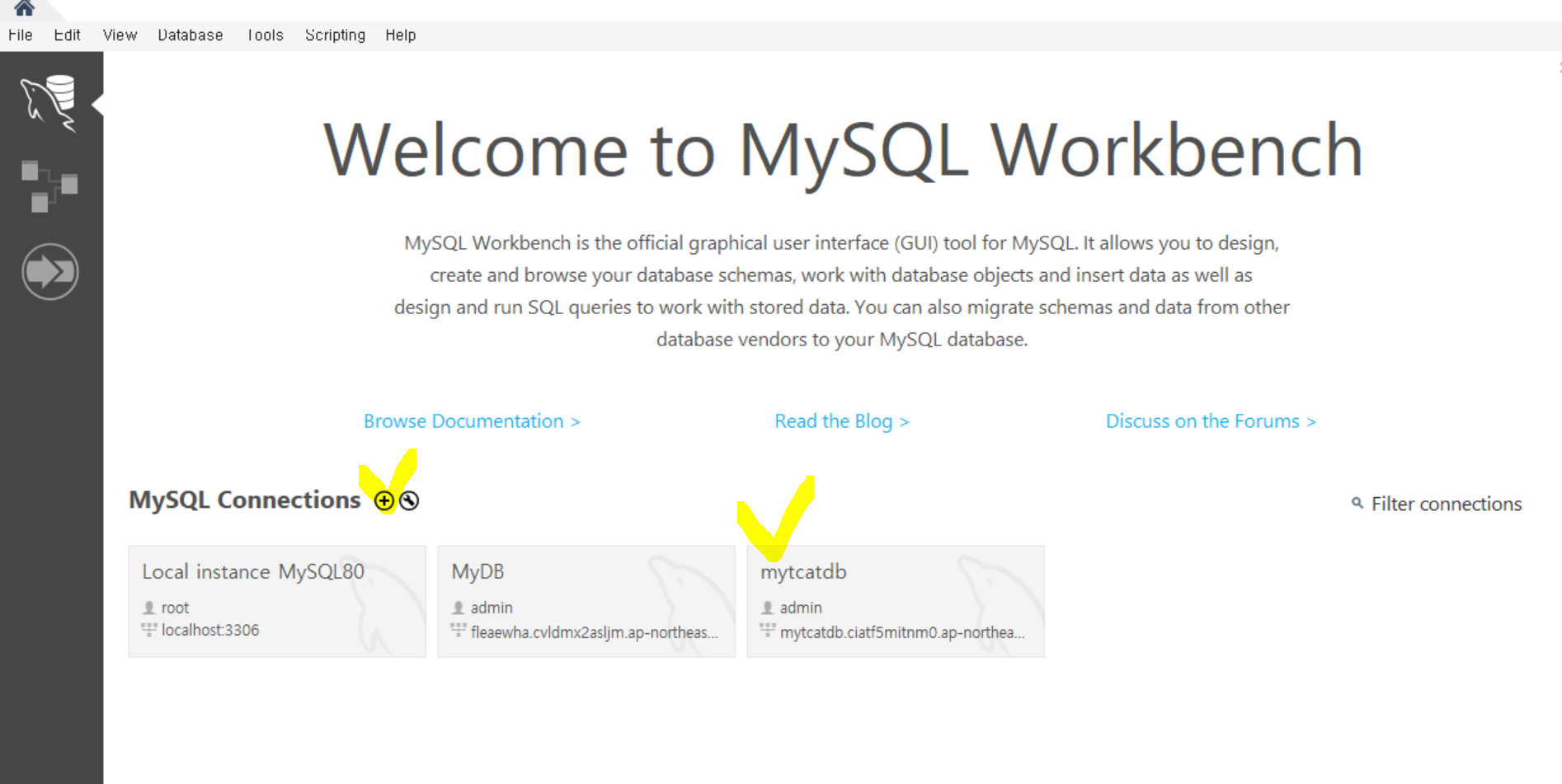
새로운 Connection을 만들고 기억해둔 엔드포인트와 포트번호 그리고 설정한 아이디/비번으로 RDS를 연결해준다.
4. Springboot build.gradle/applicaiton.yml설정
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'mysql:mysql-connector-java'application.yml
url: jdbc:mysql://(엔드포인트):(포트번호)/(데이터베이스 이름)?serverTimezone=Asia/Seoul&characterEncoding=UTF-8
username:
password:
driver-class-name: com.mysql.cj.jdbc.Driver을 설정하게 되면 이제 Springboot와 연결하여 JPA 데이터베이스를 이용해 테이블을 생성/수정할 수 있는 기본 설정을 마친셈이다.
2-2. JPA데이터 베이스 설정
JPA를 사용하기 위해서 application.yml에 JPA관련 설정을 해줘야한다.
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
# show_sql: true
format_sql: trueddl-auto가 none이면 프로젝트를 빌드할때마다 데이터베이스 테이블을 새로 만들지 않겠다라는 의미고(기존의 것 리셋안함), 최초 생성시 혹은 JPA 도메인을 수정했다면 create로 바꿔줘야한다.
JPA에서 primary key와 foreign key 설정하는 ticketbook예시는 다음과 같다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Ticketbook {
@Id //primary key 선정
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ticketbook_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY) //다대일 관계
@JoinColumn(name = "member_id") //member_id로 조인(외부키)
private Member member;
private String name;
private String ticketbookImg;
private String description;
@OneToMany(mappedBy = "ticketbook", cascade = CascadeType.ALL) //일대다 관계 ->참조 받는 대상
private List<Ticket> tickets = new ArrayList<>();
3. Builder 사용하기
프로젝트 보안 및 성능을 위해 Setter를 사용하지 않고 Builder를 이용하는 것이 지향된다. 여기에는 여러 이유가 있는데 Builder의 장점이 강력하기 때문이다.
[ 빌더 패턴(Builder Pattern)의 장점 ]
-필요한 데이터만 설정할 수 있음
-유연성을 확보할 수 있음
-가독성을 높일 수 있음
-변경 가능성을 최소화할 수 있음
1. 필요한 데이터만 설정할 수 있음
필요한 데이터만 설정할 수 있는 빌더의 장점은 생성자 또는 정적 메소드와 비교하여 테스트용 객체를 생성할 때 용이하게 해주고, 불필요한 코드의 양을 줄이는 등의 이점을 안겨준다.
2. 유연성을 확보할 수 있음
빌더 패턴을 이용하면 새로운 변수가 추가되는 등의 상황이 생겨도 기존의 코드에 영향을 주지 않을 수 있다.
3. 가독성을 높일 수 있음
빌더 패턴을 사용하면 매개변수가 많아져도 가독성을 높일 수 있다. 생성자로 객체를 생성하는 경우에는 매개변수가 많아질수록 코드 리딩이 급격하게 떨어진다. 하지만 빌더 패턴을 사용하면 다음 코드처럼 가독성이 좋아진다.
@Builder
public Ticketbook(String name, String ticketbookImg, String description) {
this.name = name;
this.ticketbookImg = ticketbookImg;
this.description = description;
}4. 변경 가능성을 최소화할 수 있음
많은 개발자들이 수정자 패턴(Setter)를 흔히 사용한다. 하지만 Setter를 구현한다는 것은 불필요하게 변경 가능성을 열어두는 것이다. 이는 유지보수 시에 값이 할당된 지점을 찾기 힘들게 만들며 불필요한 코드 리딩 등을 유발한다. 만약 값을 할당하는 시점이 객체의 생성뿐이라면 객체에 잘못된 값이 들어왔을 때 그 지점을 찾기 쉬우므로 유지보수성이 훨씬 높아질 것이다. 그렇기 때문에 클래스 변수는 변경 가능성을 최소화하는 것이 좋다.
실제 빌더 패턴을 하기 위해서 해야할단계는 크게 두 단계이다.
Domain에 @Builder 어노테이션을 사용하여 객체를 수정할 생성자를 만든 후,
@Transactional
public Ticketbook save(TicketbookDto ticketbookDto, Long memberId) {
Member member = memberRepository.findOne(memberId);
Long tempId = ticketbookDto.getId();
Ticketbook ticketbook = Ticketbook.builder()
.name(ticketbookDto.getName())
.ticketbookImg(ticketbookDto.getTicketbookImg())
.description(ticketbookDto.getDescription())
.build();
ticketbook.setMember(member);
ticketbookRepository.save(ticketbook);
member.replaceTicketbookSequence(tempId, ticketbook.getId());
return ticketbook;
}
.builder()를 이용해 데이터데이스를 수정 혹은 생성한다.
@Builder
public Ticketbook(String name, String ticketbookImg, String description) {
this.name = name;
this.ticketbookImg = ticketbookImg;
this.description = description;
}Setter를 열어두지 않음으로써 (실무와 조금 더 가깝게) 안정성있는 개발을 할 수 있다.
4. 오프셋 페이지네이션/ 커서 기반 페이지네이션
블로그 기능을 가진 웹사이트를 개발할 때, 무한 스크롤을 위해 페이징을 해야한다. 서버의 입장에서도 클라이언트의 입장에서도 특정한 정렬 기준에 따라 + 지정된 갯수 의 데이터를 가져오는 것을 페이지네이션이라고 하는데 이 페이지네이션에는 두가지 방법이 있다.
-
오프셋 기반 페이지네이션 (Offset-based Pagination)
:DB의 offset 쿼리를 사용하여 '페이지' 단위로 구분하여 요청/응답하게 구현 -
커서 기반 페이지네이션 (Cursor-based Pagination)
:클라이언트가 가져간 마지막 row의 순서상 다음 row들을 n개 요청/응답하게 구현
4-1. 오프셋 기반 페이지네이션
가장 일반적인 방법으로 제가 MySQL 에서를 예로 들면 간단히 LIMIT 쿼리에 콤마를 붙여 '건너 뛸' row 숫자를 지정하면 된다.
SELECT id FROM `products` ORDER BY id DESC LIMIT 20, 40
LIMIT절 앞에 붙는 숫자가 바로 건너 뛸 갯수(offset)이다.
하지만 오프셋 기반 페이지네이션은 문제가 있다.
1. 각각의 페이지를 요청하는 사이에 데이터의 변화가 있는 경우 중복 데이터 노출
만약 1페이지에서 20개의 row를 불러와서 유저A에게 1페이지를 띄워준 뒤, 타 유저B가 5개의 글을 더 올렸다면 1페이지를 보고있던 유저A가 2페이지를 누를시 20개중 마지막 5개를 다시 2페이지에서 중복으로 확인하게 된다는 문제가 있다.
2. 대부분의 RDBMS 에서 OFFSET 쿼리의 퍼포먼스 이슈
우리의 DB도 모든 정렬 기준(ORDER BY)에 대해 해당 row가 몇 번째 순서를 갖는지 알지 못하기 때문에 offset 값을 지정하여 쿼리를 한다고 했을 때 임시로 해당 쿼리의 모든 값들을 전부 만들어놓은 후 지정된 갯수만 순회하여 자르는 방식을 사용하게 된다. offset이 작은 수라면 크게 문제가 되지 않지만 row 수가 아주 많은 경우 offset 값이 올라갈 수록 쿼리의 퍼포먼스는 이에 비례하여 떨어지게 된다는 문제가 있다.
위와 같은 문제때문에 TCAT프로젝트에서는 커서 기반 페이지네이션을 사용하기로 결정했다.
4-2. 커서 기반 페이지네이션
커서 기반 페이지네이션의 작동 방식은 다음과 같다.
클라이언트가 가져간 마지막 row의 순서상 다음 row들을 n개 요청/응답하게 구현
오프셋 기반 페이지네이션은 우리가 원하는 데이터가 '몇 번째'에 있다는 데에 집중하고 있다면, 커서 기반 페이지네이션은 우리가 원하는 데이터가 '어떤 데이터의 다음'에 있다는 데에 집중하여 작동한다. n개의 row를 skip 한 다음 10개 주세요 가 아니라, 이 row 다음꺼부터 10개 주세요 를 요청하는 식이다. 따라서 현재 내가 어느 데이터를 보고 있는지 확인하기 위해 cursorID가 필요하다.
트렌딩 티켓을 가져올 때 무한스크롤을 위해 커서 기반 페이지네이션을 사용했다.
+)JPAQuerydsl 생성
편리한 개발을 위해 JPAQuerydsl를 사용했다.
buildscript {
ext {
queryDslVersion = "5.0.0"
}
}
plugins {
id 'org.springframework.boot' version '2.7.0'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id "com.ewerk.gradle.plugins.querydsl" version "1.0.10"
id 'java'
}
dependencies {
implementation 'com.querydsl:querydsl-jpa:5.0.0'
implementation 'com.querydsl:querydsl-apt:5.0.0'
}
def querydslDir = "$buildDir/generated/querydsl"
querydsl {
jpa = true
querydslSourcesDir = querydslDir
}
sourceSets {
main.java.srcDir querydslDir
}
compileQuerydsl {
options.annotationProcessorPath = configurations.querydsl
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
querydsl.extendsFrom compileClasspath
}
build.gradle에 다음 설정을 추가한 뒤, 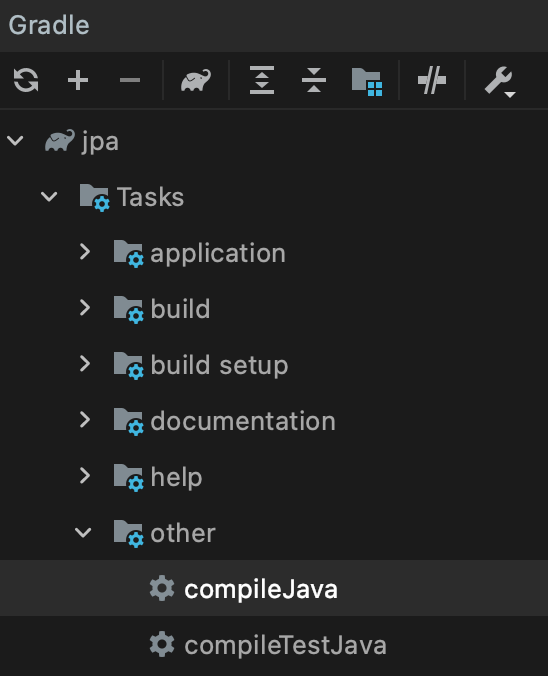
compileJava를 눌러 Q클래스를 생성한다.
이후 JPAQueryFactory를 이용하여 쉽게 데이터베이스에 접근하는 코드를 짰다.
티켓 트렌딩을 가져오는 예시는 다음과 같다.
public Page<Ticket> findAll(Integer cursorLikeCount, Long cursorId, Pageable pageable) {
queryFactory = new JPAQueryFactory(em);
List<Ticket> findAllTickets = queryFactory.selectFrom(ticket)
.where(currentdate(LocalDateTime.now()), cursorLikeCountAndCursorId(cursorLikeCount, cursorId))
.orderBy(ticket.likeCount.desc(), ticket.id.asc())
.limit(pageable.getPageSize())
.fetch();
return PageableExecutionUtils.getPage(findAllTickets, pageable, findAllTickets::size);
}
private BooleanExpression currentdate(LocalDateTime currentdate) {
return ticket.date.between(currentdate.minusDays(7), currentdate);
}
private BooleanExpression cursorLikeCountAndCursorId(Integer cursorLikeCount, Long cursorId) {
if (cursorLikeCount == null || cursorId == null) {
return null;
}
return ticket.likeCount.eq(cursorLikeCount)
.and(ticket.id.gt(cursorId))
.or(ticket.likeCount.lt(cursorLikeCount));
}
커서 기준이 되는 attribute를 ticket_id와 ticketLikeCount로 설정하여 likeCount가 많은 순대로 데이터를 불러올 수 있게 설정했다.
ticket_id와 ticketLikeCount를 cursorId와 cursorLikeCount에 넘겨주면 그 다음 id를 가진 티켓(글)을 찾아주고 likeCount를 기준으로 정렬했으므로 cursorLikeCount보다 좋아요 수가 작은 티켓을 동시에 찾아주므로 좋아요 수로 정렬된 티켓들을 커서 기반으로 가져오게 된다.
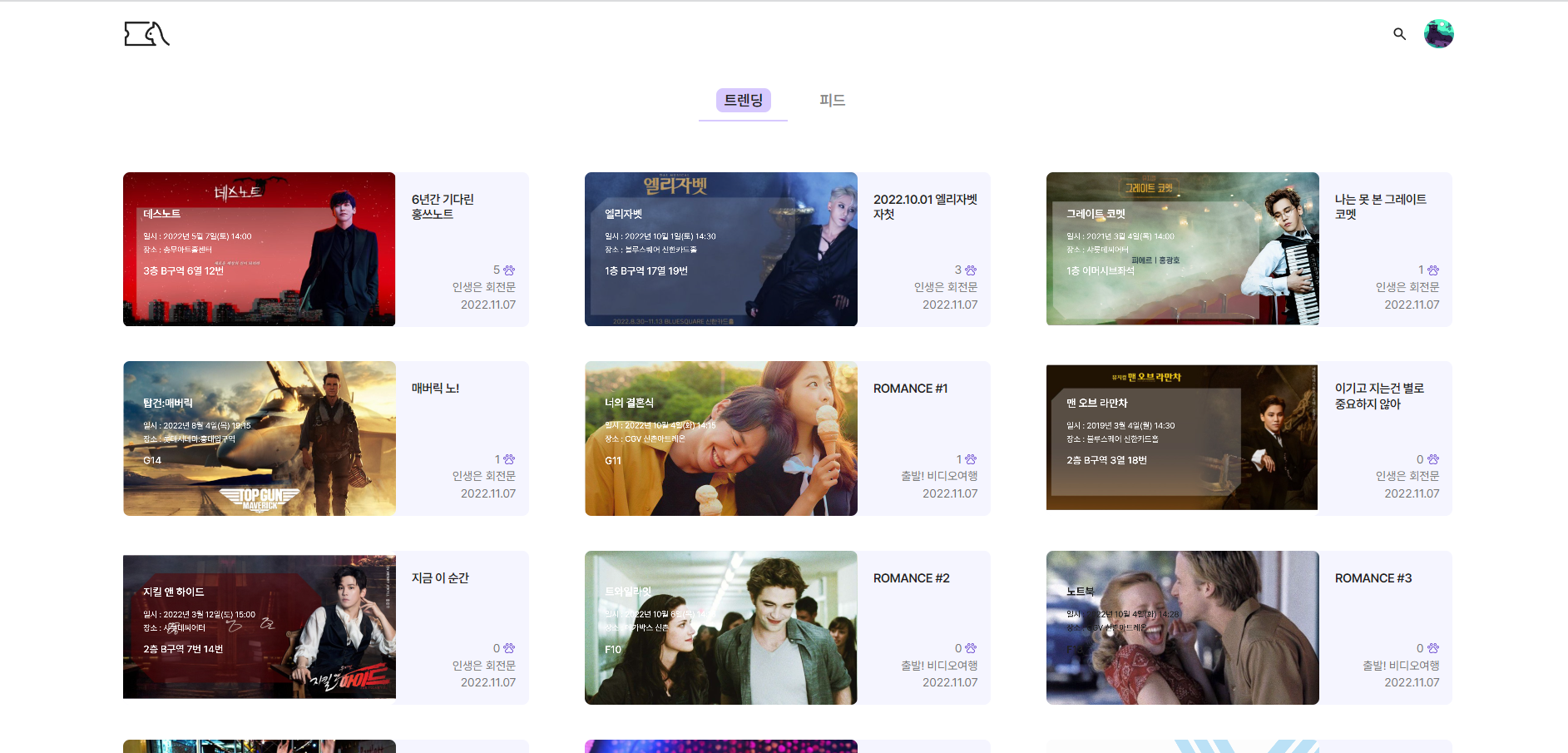
최종적으로 다음과 같이 좋아요 수가 많은 티켓(글)로 정렬하여 페이징을 하게 됨을 확인할 수 있다.
참고:
커서기반페이지네이션
