
사실 처음에는 이 주제로 포스트를 쓰려고 했던건 아니고 Apollo GraphQL 에서 커서 기반 페이지네이션 구현 을 주제로 글을 쓰려고 했습니다. 그런데 막상 찾아보니 백엔드-프론트엔드를 함께 고려하여 커서 기반 페이지네이션을 잘 설명해 놓은 포스트가 없는 것 같아 이 글을 먼저 쓰게 되었습니다.
페이지네이션?
보통 서버에서 데이터를 가져올 때 모든 데이터를 한번에 가져올 수는 없겠지요. 따라서 서버의 입장에서도 클라이언트의 입장에서도 특정한 정렬 기준에 따라 + 지정된 갯수 의 데이터를 가져오는 것이 필요합니다. 이를 흔히 '페이지네이션(Pagination)'이라고 표현하는데, 페이지네이션은 아래와 같은 두가지 방식으로 처리가 가능합니다.
- 오프셋 기반 페이지네이션 (Offset-based Pagination)
- DB의 offset 쿼리를 사용하여 '페이지' 단위로 구분하여 요청/응답하게 구현
- 커서 기반 페이지네이션 (Cursor-based Pagination)
- 클라이언트가 가져간 마지막 row의 순서상 다음 row들을 n개 요청/응답하게 구현
여기서 2. 의 방법을 설명하려고 하는데, 왜 이런 복잡하고 귀찮은 방법을 써야 하는지 궁금해하실 분들을 위하여 1. 의 구현 방법과 문제점에 대해 잠깐 설명하고 넘어갈게요.
1. 오프셋 기반 페이지네이션 (Offset-based Pagination)
이건 아마 모두가 아실, 가장 일반적인 방법입니다. 제가 주로 사용하는 MySQL 에서라면 간단히 LIMIT 쿼리에 콤마를 붙여 '건너 뛸' row 숫자를 지정하면 되니까요.
SELECT id FROM `products` ORDER BY id DESC LIMIT 20, 40LIMIT절 앞에 붙는 숫자가 바로 건너 뛸 갯수(offset) 입니다.
예를 들어, 1부터 시작하여 매기는 page 매개변수, 리스트의 쿼리 단위는 take 매개변수를 통해 전달된다고 할 때 이를 통해 쿼리 스트링을 만든다고 하면-
// page : 1부터 시작하는 페이지
// take : 한번에 불러올 row 수
const query = 'SELECT id FROM products ORDER BY id DESC LIMIT ' + (take * (page-1)) + ', ' + take;이렇게 사용하게 됩니다. 가장 쉽고 편리한 방식인데, 여기에는 두가지 문제가 있습니다.
문제1. 각각의 페이지를 요청하는 사이에 데이터의 변화가 있는 경우 중복 데이터 노출
예를 들어, 1페이지에서 20개의 row를 불러와서 유저에게 1페이지를 띄워줬습니다. 고객이 1페이지의 상품들을 열심히 보고 있는 사이, 항상 열심히 일하고 있는 상품 운영팀에서 5개의 상품을 새로 올렸네요? 유저는 1페이지 상품들을 다 둘러보고 2페이지를 눌렀어요. 그럼 어떻게 될까요?
유저는 이미 1페이지에 보았던 상품 20개중 마지막 5개를 다시 2페이지에서 만나게 됩니다.
가끔 유저들의 활동이 활발한 커뮤니티에서 게시글을 쭉 읽다보면 이런걸 경험한 적이 있으실거에요. 그럼 '아, 이 사이트는 커서 기반 페이지네이션'이 구현되지 않았구나' 라고 생각하시면 됩니다. (ㅋㅋ)
문제2. 대부분의 RDBMS 에서 OFFSET 쿼리의 퍼포먼스 이슈
우리의 DB도 모든 정렬 기준(ORDER BY)에 대해 해당 row가 몇 번째 순서를 갖는지 알지 못합니다. 따라서 offset 값을 지정하여 쿼리를 한다고 했을 때 임시로 해당 쿼리의 모든 값들을 전부 만들어놓은 후 지정된 갯수만 순회하여 자르는 방식을 사용하게 되지요. offset이 작은 수라면 크게 문제가 되지 않지만 row 수가 아주 많은 경우 offset 값이 올라갈 수록 쿼리의 퍼포먼스는 이에 비례하여 떨어지게 되어 있습니다.
Faster Pagination in Mysql – Why Order By With Limit and Offset is Slow?
이 글은 왜 MySQL에서 Limit/Offset 을 사용하면 점점 느려지는지 그 이유와, 이를 개선하는 방법에 대해 설명하고 있습니다. 여기엔 아주 재미있는 부분이 있는데요.
You may ask yourself “who the heck is going to skip to page 50,000 in my application?”.
Let’s list few possible use cases:
- Your favorite search engine (Google / Bing / Yahoo / DuckDuckGo / whatever) is about to index your ecommerce website. You have about 100,000 pages in that website. How will your application react when the search bot will try to fetch those last 50,000 pages to index them? How frequently will that happen?
- In most web applications, we allow the user to skip to the last page, and not only the next page. What will happen when the user will try to skip to page 50,000 after visiting page 2?
- What happens if a user landed in page 20,000 from a Google search result, liked something there and posted it on facebook for another 1000 friends to read?
아마 당신은 이런 의문이 들 수도 있어요. "도대체 어떤 할 일 없는 놈이 우리 앱에서 50,000 페이지나 스킵하겠어?"
가능한 케이스를 나열해볼까요?
- 당신이 즐겨 쓰는 검색엔진 (구글/빙/야후/덕덕고/왓에버) 이 인덱싱을 위해 당신의 이-커머스 웹사이트에 방문하려고 해요. 당신의 서비스는 대충 10만개의 페이지를 갖고 있네요. 이런 상황에서 검색엔진 봇이 뒤에 있는 5만 페이지를 인덱싱하려고 할 때, 당신의 서비스 코드는 어떻게 응답해야 할까요? 이건 또 얼마나 자주 있을까요?
- 대부분의 웹 어플리케이션은 유저에게 '마지막 페이지'로 바로 갈 수 있는 링크를 제공해요. 다음 페이지만 제공하는게 아니구요. 2페이지에 방문했던 유저가 갑자기 50,000번째 페이지로 넘어가려고 한다면 무슨 일이 일어날까요?
- 어떤 유저는 구글 검색결과 페이지에 의해 20,000번째 페이지로 바로 접속했어요. 유저는 이 결과가 마음에 들었고, 페이스북에 이 주소를 1,000명의 친구에게 공유했어요. 그럼 어떤 일이 일어날까요?
그렇습니다. 이런 일은 늘 일어날 수 있는 일이라 대비하는 것이 좋겠습니다.
하지만 다시 말하면,
- 데이터의 변화가 거의 없다시피하여 중복 데이터가 노출될 염려가 없는 경우
- 일반 유저에게 노출되는 리스트가 아니라 중복 데이터가 노출되어도 크게 문제 되지 않는 경우
- 검색엔진이 인덱싱 할 이유도, 유저가 마지막 페이지를 갈 이유도, 오래 된 데이터의 링크가 공유 될 이유도 없는 경우
- 애초에 row 수가 그렇게 많지 않아 특별히 퍼포먼스 걱정이 필요 없는 경우
이런 경우라면 오프셋 기반 페이지네이션을 사용해도 아무 문제가 없다는 얘기입니다. 이런 경우에까지 커서 기반을 고려할 필요는 없는거죠. 저희가 만드는 서비스들도 유저가 접속하는 서비스 페이지에는 철저하게 커서 기반을 사용하고 있지만, 백오피스는 편한 오프셋 기반을 사용하고 있습니다.
2. 커서 기반 페이지네이션 (Cursor-based Pagination)
드디어 본론을 이야기 할 차례가 되었습니다.
이 글의 첫 부분에서 제가 커서 기반 페이지네이션에 대해 간단히 이렇게 정의내렸죠?
클라이언트가 가져간 마지막 row의 순서상 다음 row들을 n개 요청/응답하게 구현
오프셋 기반 페이지네이션은 우리가 원하는 데이터가 '몇 번째'에 있다는 데에 집중하고 있다면, 커서 기반 페이지네이션은 우리가 원하는 데이터가 '어떤 데이터의 다음'에 있다는 데에 집중합니다. n개의 row를 skip 한 다음 10개 주세요 가 아니라, 이 row 다음꺼부터 10개 주세요 를 요청하는 식이지요.
그럼 DB에서 '뭐뭐 다음꺼 10개'는 어떻게 가져올까요? 이건 아무래도 예를 들어 설명드리는게 좋겠네요.
케이스:: id DESC 정렬시
우선, 위의 오프셋 기반 페이지네이션에서 예를 들었던 ID 역순 정렬의 'products' 테이블에서 첫번째 리스트를 가져오는 방법은 이렇습니다. (우리의 'products' 테이블은 총 1,000개의 상품이 빈자리 없이 꽉 채워 ID 1부터 1000까지 입력되어 있다고 가정할게요. 표 그리기 귀찮아서 5개만 가져옵니다ㅋ)
SELECT id FROM `products` ORDER BY id DESC LIMIT 5그럼 우리는 이런 결과를 얻게 됩니다.
| id | title |
|---|---|
| 1000 | 상품#1000 |
| 999 | 상품#999 |
| 998 | 상품#998 |
| 997 | 상품#997 |
| 996 | 상품#996 |
이제 다음 리스트를 가져와야겠죠? 상품#996 아래에 '있어야 할' 상품#995~상품#991 을 가져오면 되겠네요. 이걸 쿼리로 쓰면 이렇게 됩니다.
SELECT id, title
FROM `products`
WHERE id < 996
ORDER BY id DESC
LIMIT 5너무 쉬워서 실망하셨나요? 여기서 cursor 가 바로 products 테이블의 id 이고, 그 값은 996 입니다.
참 쉽죠? 하지만 이번엔 정렬 기준이 바뀌어서 유저는 가장 가격이 싼 상품들부터 보고싶다고 합니다.
케이스:: price ASC 정렬시
첫번째 리스트는, 여전히 쉽습니다.
# 첫번째 리스트
SELECT id, title, price
FROM `products`
ORDER BY price ASC
LIMIT 5그래서 이런 결과를 얻었습니다.
| id | title | price |
|---|---|---|
| 242 | 상품#242 | 5800 |
| 335 | 상품#335 | 5900 |
| 798 | 상품#798 | 9500 |
| 957 | 상품#957 | 13200 |
| 446 | 상품#446 | 14100 |
여기서 cursor 는 446일까요? 아닙니다. 정렬 기준이 price 니까 14100 이 cursor 가 됩니다.
자, 이제 다음 리스트를 가져와볼까요? 정렬 방향이 바뀌었으니 부등호도 방향이 반대가 되겠네요.
# 두번째 리스트
SELECT id, title, price
FROM `products`
WHERE price > 14100
ORDER BY price ASC
LIMIT 5결과는 잘 나왔는데, 여기에는 한가지 바로 문제가 있네요. id 는 고유값이라서 절대 겹칠 일이 없었지만 가격은 고유값이 아니잖아요? 14,100원짜리 상품이 상품#446 하나면 정말 다행인데, 그 뒤로 5개나 있으면 어쩌죠? 저 쿼리대로라면 그 상품들은 모두 skip 되고 한참 밑에 있었어야 할 상품들 5개가 나올거거든요.
따라서 커서 기반 페이지네이션을 위해서는 반드시 정렬 기준이 되는 필드 중 (적어도 하나는) 고유값이어야 합니다.
여기서는 ORDER BY절에 id 필드를 두번째 정렬 기준으로 추가해봅니다.
케이스:: price ASC, id ASC 정렬시
# 첫번째 리스트
SELECT id FROM `products` ORDER BY price ASC, id ASC LIMIT 5첫번째 리스트 쿼리를 이렇게 고치고,
# 두번째 리스트 : WRONG
SELECT id, title, price
FROM `products`
WHERE price > 14100
AND id > 446
ORDER BY price ASC, id ASC
LIMIT 5
# 두번째 리스트 : VALID
SELECT id, title, price
FROM `products`
WHERE
(price > 14100
OR
(price = 14100 AND id > 446))
ORDER BY price ASC, id ASC
LIMIT 5위 코드에서 첫번째 코드처럼 쓰면 절대 안 됩니다. 엄하게 id 가 446보다 작은 상품들은 가격과 상관없이 전부 결과에서 사라지게 되니까요. 그래서 OR절을 넣어 지정한 price 보다 작은 경우와 같은 경우를 구분하고, price가 같은 경우에만 id 비교를 하도록 쿼리를 변경했습니다.
결과는? Success!
위의 방법으로도 사실 대부분의 케이스는 핸들링이 가능합니다. 혹시 ORDER BY가 위 예제처럼 2개가 아니라 훨씬 더 많은 케이스라면 이 글을 참조해주세요.
OR절 사용의 문제점
이렇게 구현하는 경우 두가지 문제가 있습니다.
1. 대부분의 RDBMS는 WHERE에 OR-clause 를 사용하면 인덱싱을 제대로 못 태움.
2. 클라이언트가 ORDER BY에 걸려있는 모든 필드를 알아야하고, 매 페이지 요청시마다 이 값들을 전부 보내야 함.
이 중 1번은 사용하는 DB가 어떤 것이냐에 따라 처리하는 방식이 달라, 고려해야 할 사항 역시 달라지게 됩니다. 이걸 다 언급하는건 이 글의 범위를 벗어나게 되는데(개인적으로 저희 팀에서는 아예 OR절 사용 금지 에 가까운 준칙을 세워서 지키고 있습니다ㅋ) 이걸 어찌저찌 해결하더라도 여전히 2번의 문제는 남습니다.
그럼 몇 개의 필드를 ORDER BY 조건절로 사용하든, 항상 같은 방향으로 특정 값을 부여하고, 이를 cursor로 사용할 순 없을까요? 나름의 계산식을 만들어 그런 값을 만들어 보겠습니다.
케이스:: price DESC, id DESC (커스텀 cursor 생성)
좀 더 쉬운 이해를 위해 price DESC, id DESC 일 때를 먼저 해볼게요.
# 첫번째 리스트
SELECT id, title, price,
CONCAT(LPAD(price, 10, '0'), LPAD(id, 10, '0')) as `cursor`
FROM `products`
ORDER BY price DESC, id DESC
LIMIT 5;이 쿼리로는 이런 결과를 얻었습니다.
| id | title | price | cursor |
|---|---|---|---|
| 446 | 상품#446 | 14100 | 00000141000000000446 |
| 957 | 상품#957 | 13200 | 00000132000000000957 |
| 798 | 상품#798 | 9500 | 00000095000000000798 |
| 335 | 상품#335 | 5900 | 00000059000000000335 |
| 242 | 상품#242 | 5800 | 00000058000000000242 |
CONCAT : MySQL 내장함수, 문자열 합침 (숫자인 경우 문자열 자동변환)
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat
LPAD : MySQL 내장함수, 문자열 / 숫자를 지정된 길이의 문자열로 채움 (왼쪽)
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_lpad
cursor 필드를 보면 바로 이해가 되시죠? 숫자값인 데이터를 LPAD를 이용해 10자 길이의 고정 문자열로 만들고 이를 CONCAT으로 붙인 모양입니다. 10자인 이유는, price, id 필드가 10자를 넘어가지 않을 거라는 확신 때문인데, 어차피 문자열이므로 늘려도 무방합니다. (이 길이는 퍼포먼스와 trade-off 이니 안정적이면서 적절한 값을 선택하면 됩니다)
이제 일관된 cursor 값을 얻었으니, 두번째 리스트 쿼리는 아주 간단하게 할 수 있습니다.
# 두번째 리스트
SELECT id, title, price,
CONCAT(LPAD(price, 10, '0'), LPAD(id, 10, '0')) as `cursor`
FROM `products`
HAVING `cursor` < '00000058000000000242'
ORDER BY price DESC, id DESC
LIMIT 5;
HAVING절을 사용하면 인덱싱에 문제가 있는데, 이 부분은 아래에서 다시 설명합니다.
케이스:: price ASC, id ASC (커스텀 cursor 생성)
위와 같은 방식으로 ASC 가 섞여있을 경우는 그냥 두번째 리스트 쿼리에서 부등호 방향만 바꾸면 되는데, 그것보단 생성하는 cursor 값을 일관되게 만드는게 더 좋을 것 같습니다. 그래야 ASC/DESC가 섞여 있을 때 대응도 쉽고 쿼리 생성하는 코드를 자동화 할 수 있을테니까요.
# 첫번째 리스트
SELECT id, title, price,
CONCAT(LPAD(POW(10, 10) - price, 10, '0'), LPAD(POW(10, 10) - id, 10, '0')) as `cursor`
FROM `products`
ORDER BY price ASC, id ASC
LIMIT 5;이 쿼리로는 이런 결과를 얻었습니다.
| id | title | price | cursor |
|---|---|---|---|
| 242 | 상품#242 | 5800 | 99999942009999999758 |
| 335 | 상품#335 | 5900 | 99999941009999999665 |
| 798 | 상품#798 | 9500 | 99999905009999999202 |
| 957 | 상품#957 | 13200 | 99999868009999999043 |
| 446 | 상품#446 | 14100 | 99999859009999999554 |
POW : MySQL 내장함수, 제곱 연산
https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_pow
뭔가 굉장히 복잡해진 것 같지만 그냥 각각 아래와 같이 변경한 식입니다.
price대신에POW(10, 10) - priceid대신에POW(10, 10) - id
POW(10, 10)는 10,000,000,000 인데, 이러면 가장 낮은 price 값을 가진 상품이 가장 높은 cursor 값을 갖게 되겠지요? id 도 마찬가지입니다.
두번째 리스트를 부르는 로직은 ASC/DESC 와 무관하게 동일합니다. cursor 생성식과 HAVING 절의 비교값만 바뀌었죠.
# 두번째 리스트
SELECT id, title, price,
CONCAT(LPAD(POW(10, 10) - price, 10, '0'), LPAD(POW(10, 10) - id, 10, '0')) as `cursor`
FROM `products`
HAVING `cursor` < '99999859009999999554'
ORDER BY price ASC, id ASC
LIMIT 5;HAVING 대신 WHERE 쓰기
그럼 위에서 쓴 쿼리의 퍼포먼스는 어떨까요?
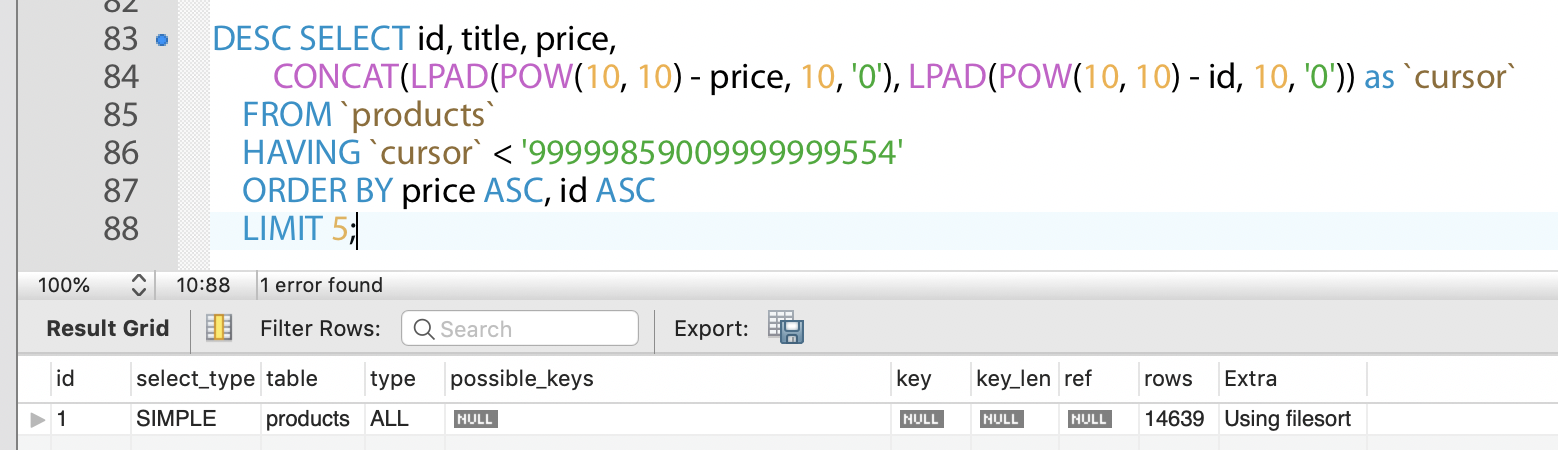
아, 안타깝게도 Using filesort 를 타고 있어요. 인덱스를 전혀 이용하고 있지 않네요.
원인은 HAVING 절 때문입니다. 이걸 WHERE 절로 바꾸면 아래와 같은 결과가 나옵니다.
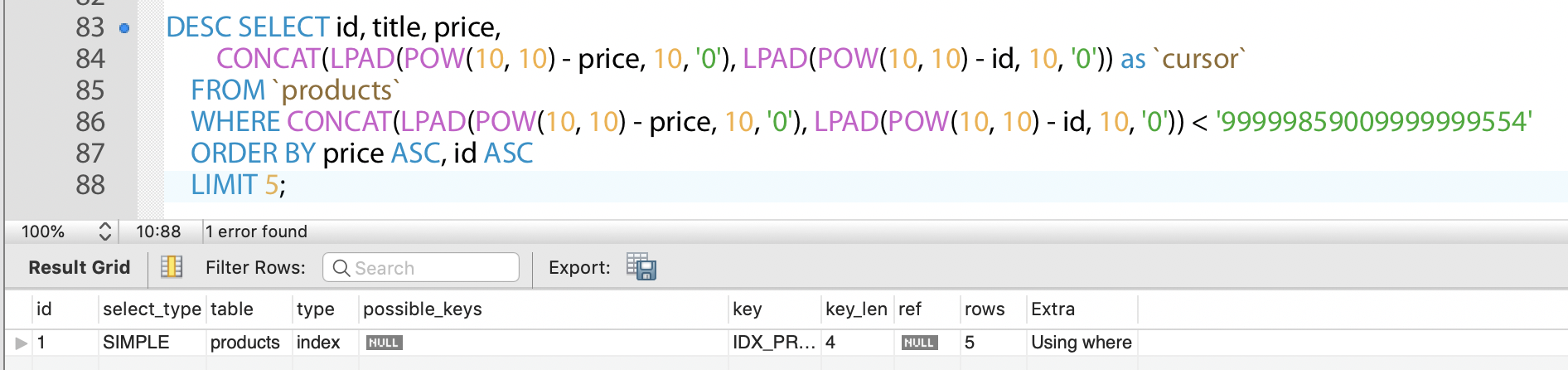
쿼리는 좀 지저분해졌지만, Using where 에 인덱스도 잘 타고 있네요. 사실 HAVING절을 사용한 것은 쿼리를 통해 즉시 결과를 확인하기 편하다는 그 이유, 딱 하나 때문이었습니다. SQL로 보기는 좀 지저분하지만 어차피 우리는 쿼리를 코드로 생성할테니 상관 없습니다.
서버 코드에 적용
위에 설명드린 내용을 Plain Javascript 나 Knex.js 기반으로 짧게 코딩하여 쓸까 했는데, 설명하자니 너무 많은 내용이고 또한 이 '커서 기반 페이지네이션' 자체는 특정 플랫폼에 종속되는 내용이 아니기에 간단히 제가 사용하고 있는 모양만 보여드리는게 나을 것 같습니다.
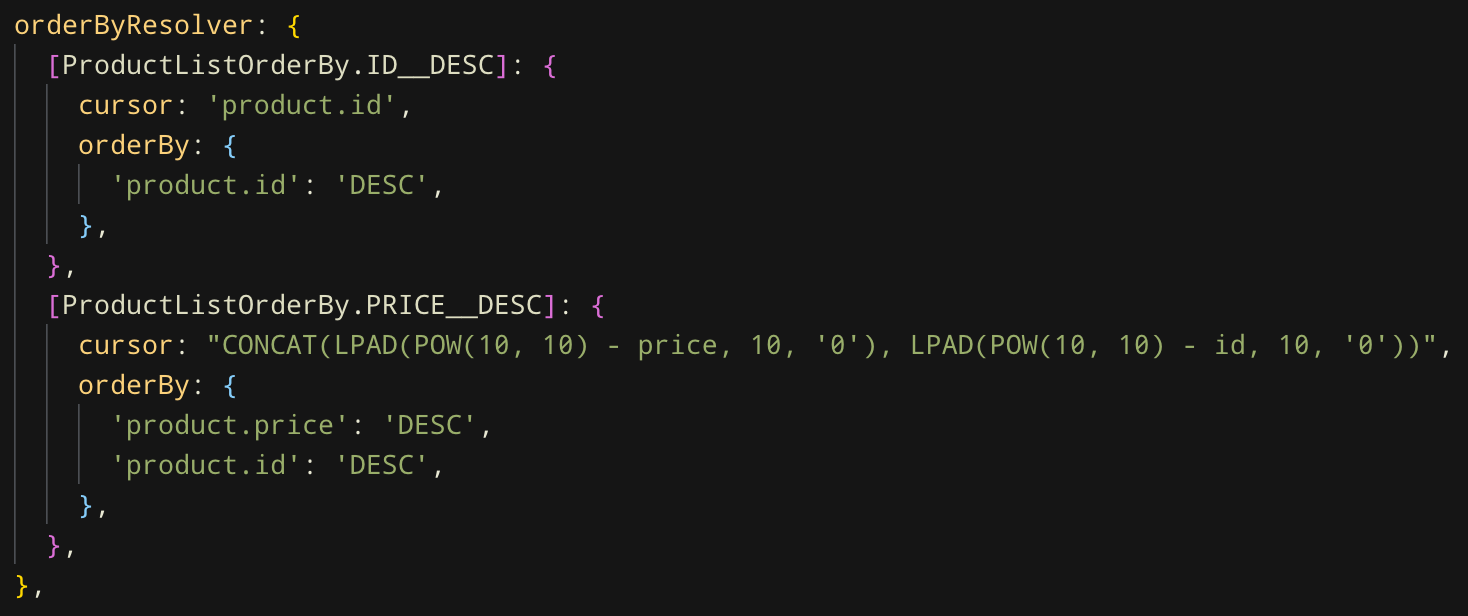
위 내용은 제가 구현한 GraphQL Resolver 에서 전달받은 orderBy 매개변수를 처리하는 설정 부분입니다. 이걸 TypeORM의 QueryBuilder 를 통해 각각 SELECT 절과 ORDER BY 절로 생성하게 됩니다.
사실 위에 설명한 내용대로만 보면 각 필드가 cursor 에서 차지하는 '자릿수' 말고는 딱히 cursor 생성 쿼리를 이렇게 전부 inline 할 필요는 없는데, 몇가지 예외 케이스가 있어 일단 현재까지는 이렇게 사용하고 있습니다. 이 글을 쓰기 전까진 저 역시도 확실히 내용 정리가 안되었는데 써놓고보니 확실히 정리할 수 있을 것 같네요ㅋ
정리
- 동일 레코드 중복 노출, 데이터의 빈번한 C/U/D 가 없는 리스트의 페이지네이션은 오프셋 기반으로 구현해도 좋습니다.
- 그외 거의 모든 리스트는 커서 기반 페이지네이션을 사용하는 것이 무조건적으로 좋습니다.
- 서버의 쿼리 퍼포먼스 / 클라이언트의 사용 편의를 위해서 커서로 사용할 값을 별도로 정의하고, 이 값을 활용한
WHERE/LIMIT으로 커서 기반 페이지네이션을 구현할 수 있습니다. - 이렇게 구현하는 경우 각 정렬 방식마다
cursor값과 정렬할 필드, ASC/DESC를 지정함으로써 쿼리 생성을 깔끔하게 할 수 있습니다.
사실 이렇게 길게 쓸 줄은 몰랐는데 너무 길어졌네요;
아무쪼록 많은 분들께 도움이 되었으면 합니다.

10개의 댓글

잘봤습니다.
그런데 100만건 돌려서 테스트 해봤는데 OR절을 사용한게 가장 빠르고
커스텀 cursor사용한건 일반 offset보다 느린 결과가 나왔는데요....





좋은 글 감사합니다. 많이 배워갑니다!