How to use DL Model On-Device?
- 학습된 모델을 온디바이스에서 사용하는 방법
1. Compressing
- 학습된 모델을 올리려는 디바이스의 램을 고려하여 경량화
- 모델의 크기와 램의 관계에 대한 자세한 정보는 하단에 기술해놓았음
https://velog.io/@hyunku/AI-Deep-Dive-%EB%AA%A8%EB%8D%B8%EC%9D%98-%ED%81%AC%EA%B8%B0%EA%B3%BC-RAM%EC%9D%98-%EA%B4%80%EA%B3%84
예시
- 디바이스 가용RAM이 6GB이라고 가정하면, 올리려는 모델은 6GB 미만이여야 함
- 현재 모델이 TinyLLaMA 1B 32bit 모델이라고 가정
- 현재 모델의 총 크기는 10억 * 4byte = 40억 byte = 4000MB = 4GB
- 8bit Quantization 을 수행한다고 가정
- 8bit 양자화된 모델의 총 크기는 10억 * 1byte = 10억 byte = 1000MB = 1GB
- 50% Pruning을 수행한다고 가정
- 최종 경량화된 모델의 크기는 5억 * 1byte = 5억 byte = 500MB = 0.5GB
2. Optimization
- 파이토치 모델(.pt)을 serialize시켜 특정 언어나 프레임워크에 대한 의존성을 없앰
- torch.onnx.export() : 최적화. .pt 모델을 .onnx 모델로 변환시켜줌
torch.onnx.export()
- torch.onnx.export() 실행시 수행하는 작업들
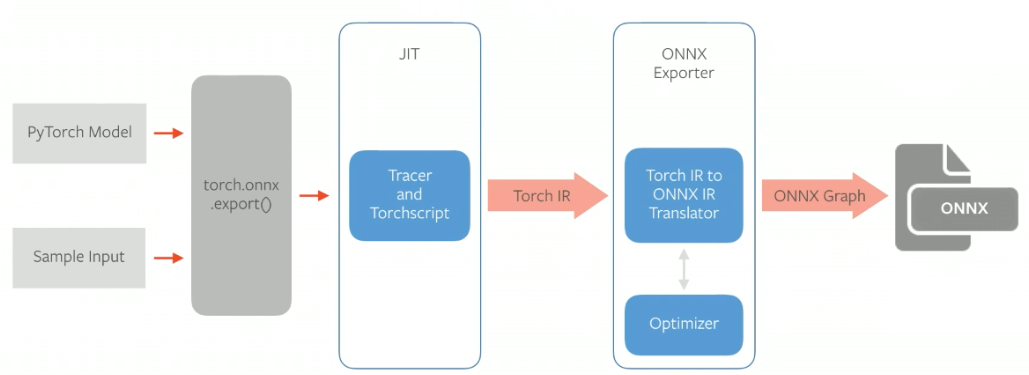
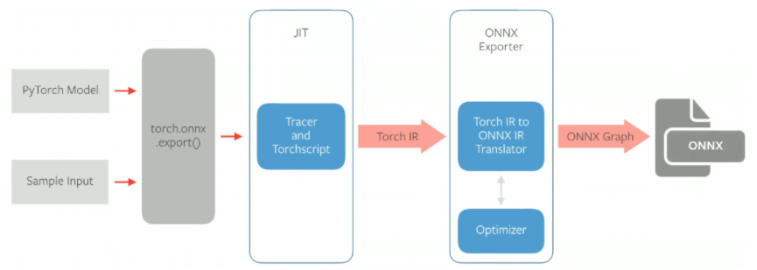
- 실행하면 PyTorch의 JIT 컴파일러인 TorchScript를 통해 script 또는 trace 가 생성됨. 이렇게 생성된 script/trace는 Torch IR라고 함.
- IR은 forward() 시 수행되는 연산을 최적화한 그래프.
- Torch IR은 ONNX Exporter를 통해 ONNX IR 로 변환되면서 연산을 추가적으로 최적화
- 최종 생성된 ONNX IR은 .onnx 모델로 저장됨
Trace vs Script
Trace
- Trace의 경우, IR 생성시 if문과 같은 분기(Dynamic Control Flow)가 있는 경우, 한가지 과정에 대해서만 수행. 즉, static graph를 생성함
- torch.onnx.export() 의 default 인자는 trace임.
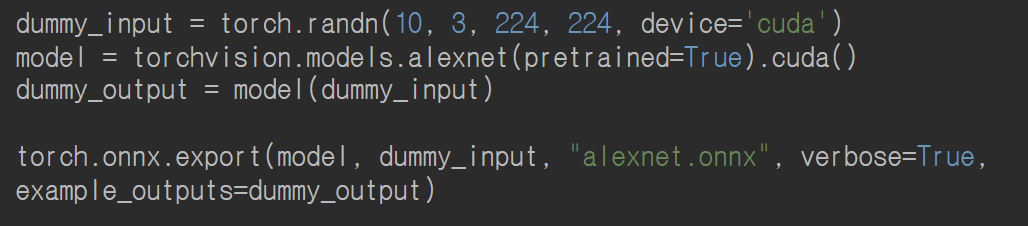
Script
- Script의 경우, IR 생성시 if문과 같은 분기(Dynamic Control Flow)가 있는 경우, 모든 과정에 대해서 수행. 즉, 전체 코드를 보고 컴파일 진행하므로 dynamic graph를 생성하며, example data도 필요 없음
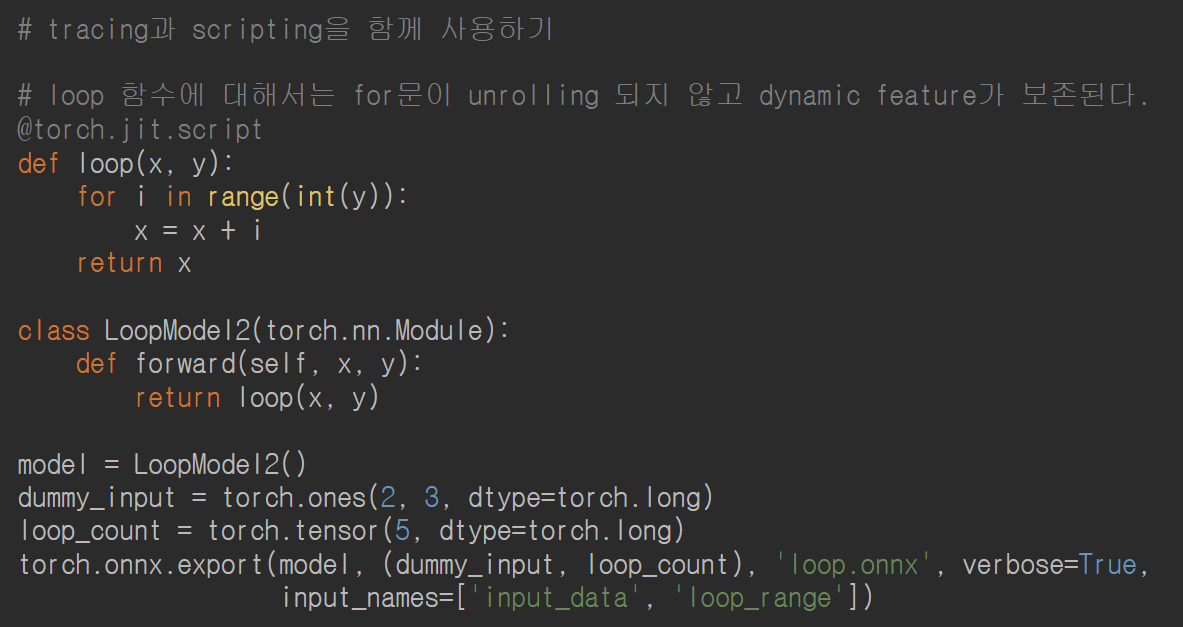
- Script 사용하고 싶은 경우, @torch.git.scirpt 데코레이터를 추적하려는 함수 위에 얹혀주면 됨.
onnx graph (IR)

Summary
- Optimizitaion 은 torch.onnx.export() 로 한번에 끝남.
- 파이토치 모델(.pt)을 .onnx 모델로 변경해줌
3. Load & Inference
- .onnx 파일 load후, 추론 엔진을 통해 Inference 수행
- Android Application 으로 사용한다고 가정 (예시)
Inference Engine
- ONNX Runtime
https://onnxruntime.ai/docs/tutorials/mobile/
App 개발
- ONNX Runtime 을 포함하여 애플리케이션 개발해야함.
- ONNX Runtime C++ 로 모델 로드하고 추론 수행
- JNI(Java Native Interface) 로 Java(개발언어) 에서 C++ 함수 호출
- Android 프로젝트에서 NDK와 CMake를 사용하여 C++ 코드를 컴파일하고 Java 코드와 연동하도록 설정
- Applacation 배포

고려대학교 인공지능학과 SLP Lab 석사과정생