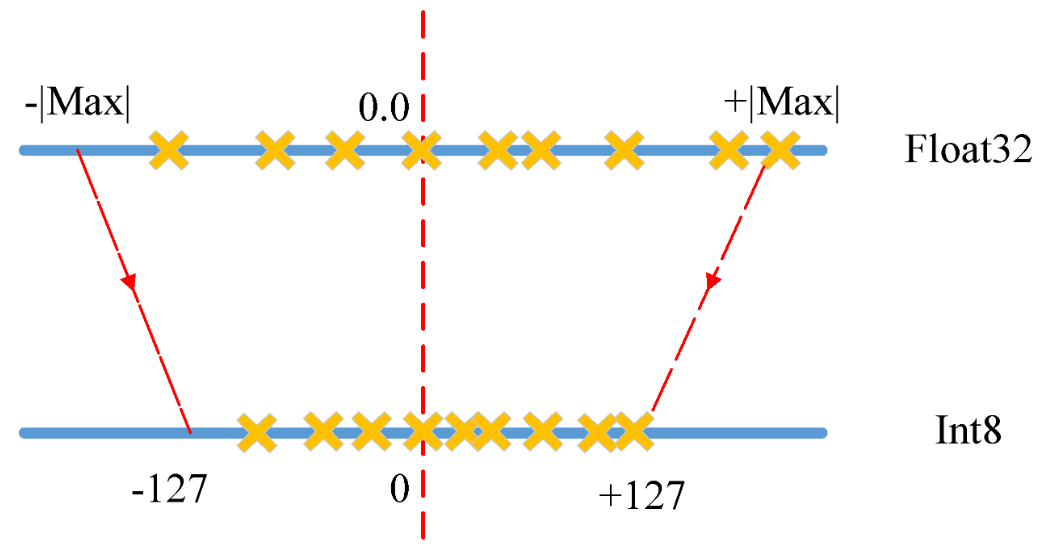
Quantization 개념
- High bit의 Model Weight를 Lower bit로 표현함으로써, 연산과 메모리 access를 높이는 Compression Method.
- 보통 일반적인 모델은 32bit Float Tensor 로 되어있고, 8bit 모델로의 경량화가 목표임
- 대상은 Weight 와 Activation 두가지
Quantization 적용
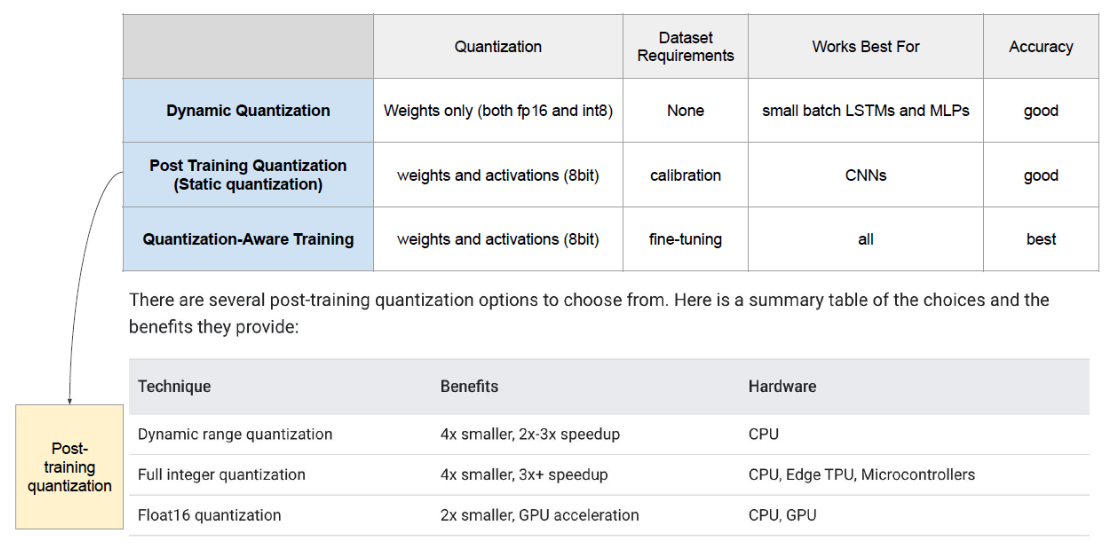
1. Dynamic Quantization
- 학습 이후 양자화
- Weight는 Inference 전에 양자화, Activation은 Inference 수행 도중(동적)에 양자화
- Inference 과정 중 Activation Clipping Range를 동적으로 계산하며 Activation value들을 양자화
- Inference 과정 Image
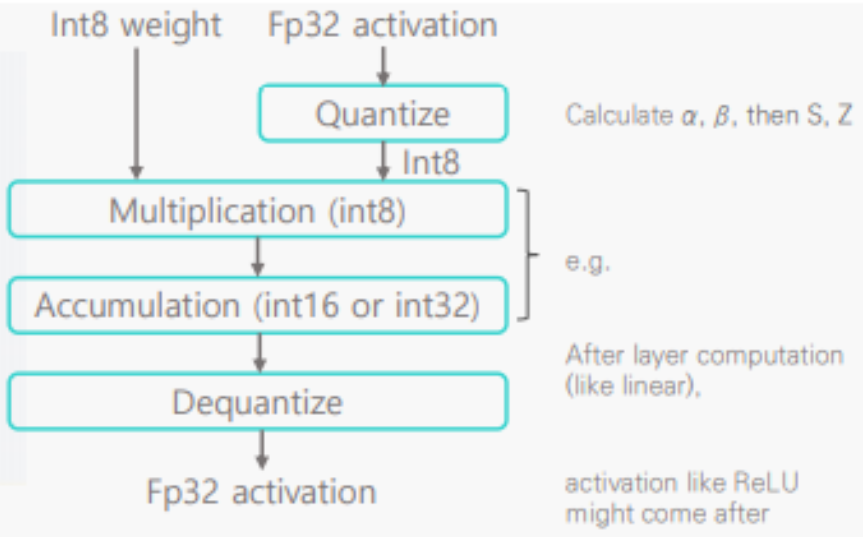
1. Fp32 Activation을 양자화 - 해당 과정에서 S와 Z를 결정하여 Quantize
2. Int8 Weight와 Activation 끼리 곱셈 후 결과를 int16 또는 int32로 누적
3. 최종 결과를 fp32로 비양자화(Dequantaize)
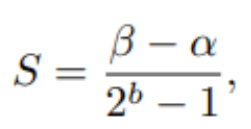
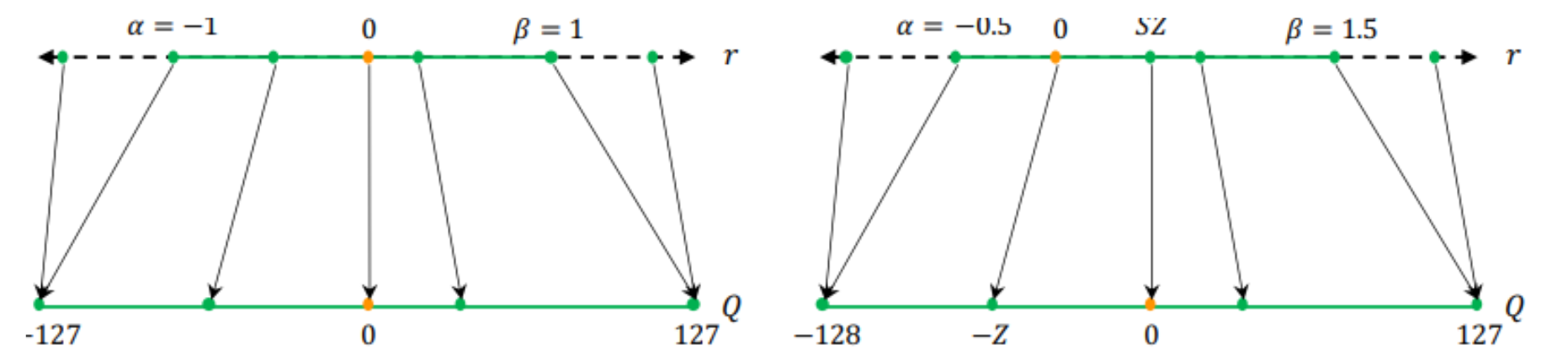
- 알파, 베타는 Clipping Range, S는 Scaling Factor, Z는 Zero Factor
- Quantize 시, S,Z 결정
2. Static Quantization (=PTQ)
- Post-Training Static Quantization (PTQ) 와 동일한 개념
- Weight, Activation 을 모두 훈련 후, 추론 전에 진행
- Static Quantization (=PTQ) 과정 Image
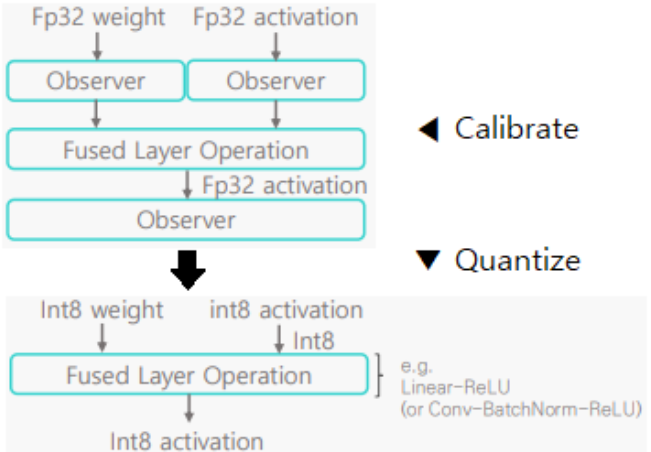
1. Calibration - Weight와 Activation 의 분포에 의거하여 각각의 Clipping 범위 결정
2. Fusion - Weight와 Activation의 Clipping Range를 이용하여 효율적인 연산을 위하여 여러 Layer에 걸친 연산을 합쳐 한번의 연산 수행하도록 Fusion
e.g.) BatchNorm-Activation-Convolution 연산들을 한번에 수행하는 Fusion 연산 생성 후, 이를 수행
3. Quantization - Weight와 Activation이 합쳐진 Fusion Layer를 Clipping Range에 의거하여 양자화
3. Quantization-Aware-Training (QAT)
- Weight, Activation 양자화를 학습 과정 중에 진행
- 양자화/역양자화 모듈을 달아서 Fine-Tuning 하며 Quantization Loss를 학습하여 Clip Value(Scale) 획득
- 학습 이후에 양자화 모듈을 사용하여 fp 모델을 int 모델로 변경 가능
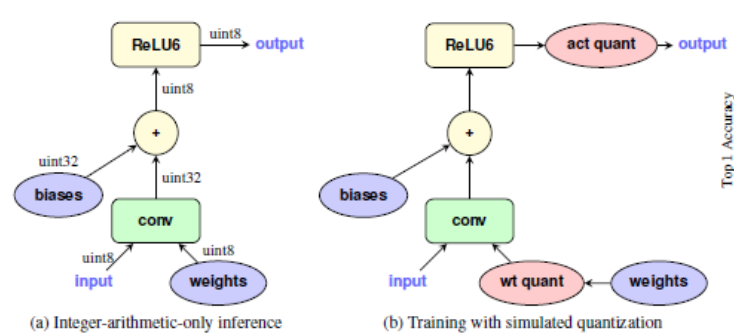
- 양자화에 사용되는 round operation은 미분이 불가능함.
- 따라서 학습을 하면 gradient를 구할수 없고, backward가 불가능함.
- 이런 문제를 해결하기 위해 STE, Non-STE 방법으로 구분
STE
- round function의 미분가능성을 고려하여, 미분 불가능한 부분의 미분값을 Identity Function으로 근사하는 방법
- backward 과정에서 양자화 연산의 미분을 항등 함수로 대체하여, 입력 값의 변화가 그대로 전달(1로 전달됨).
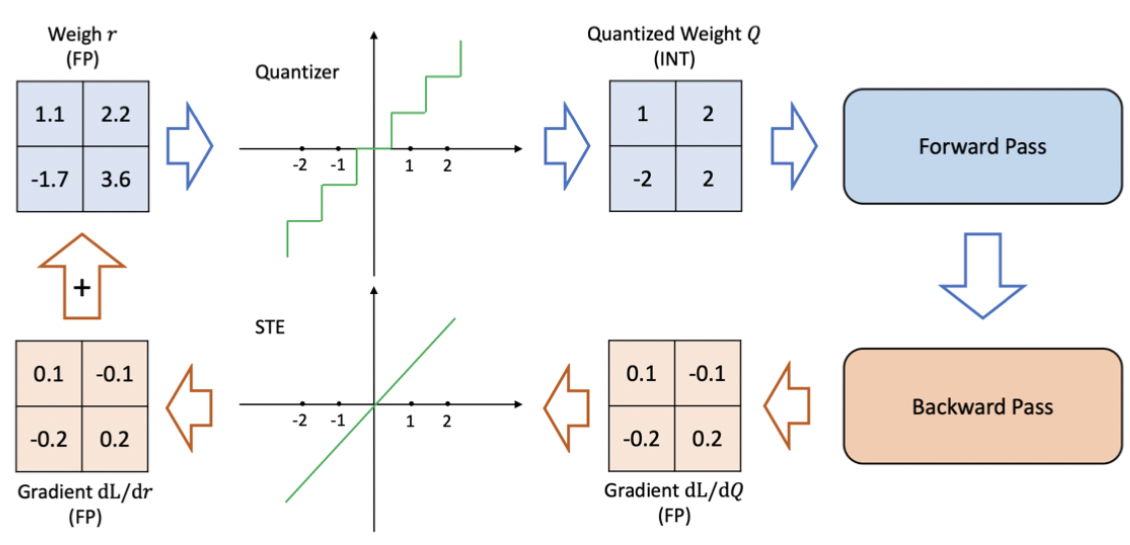
- STE 미분값 1이 됨.
Non-STE
- round function의 미분 가능성을 고려하지 않고, round fuction의 도함수 자체를 어떻게 근사힐지 고려하는 방법
- 양자화 연산의 미분을 근사하거나, 미분불가 상태를 처리하는 다른 방법을 사용하여 gradient를 계산.
- e.g) ProxQuant, AdaRound
- Clipping range, Scaling factor 등을 학습하는 방법론도 제안됨. PACT, QIT 등은 uniform/non-uniform 가정 하에서 Clipping range를 학습하고자 함. LSQ/LSQ+는 activation에 대한 Scaling factor를 학습하고자 함.
- 튜닝하는데 오랜 시간이 걸림
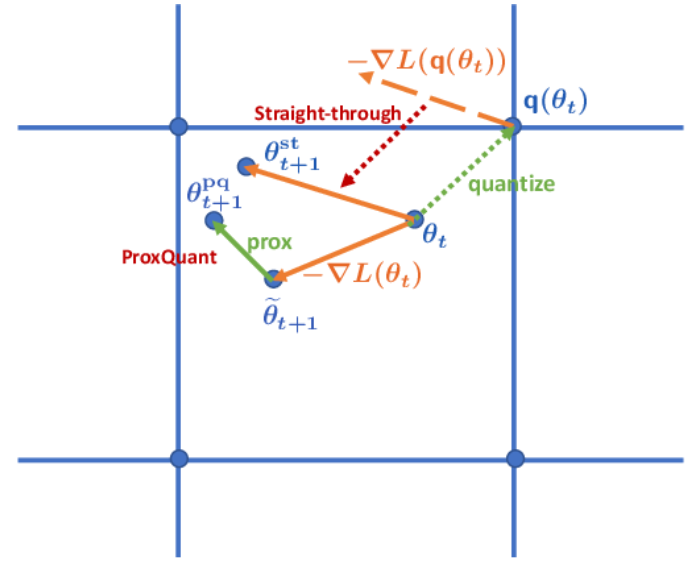
- (주황) STE 방법 - 미분값 1사용 (by Identity Function)
- (초록) Non-STE 방법 - PorxQuant
Quantization 방법
- Calibration Range가 결정된 상태에서, Weight를 Update하는 실질적인 방법론들
1. Uniform vs NonUniform
- Quantization Step size 를 결정하는 방법
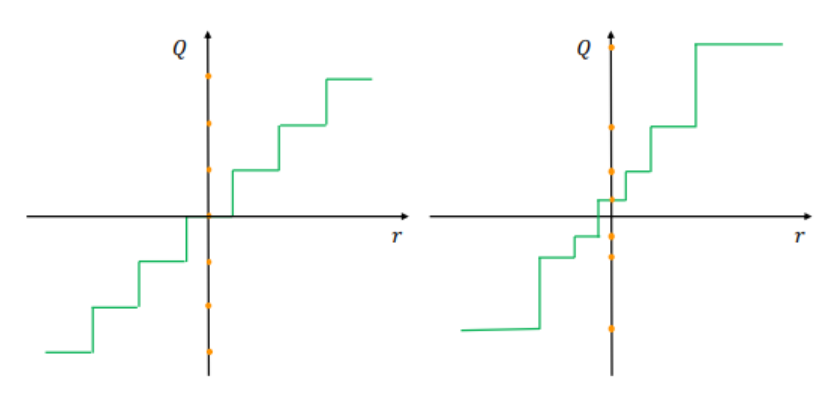
(좌) Uniform
- Quantized Value들이 일정한(Uniform) 간격으로 매핑됨.
- 단순하고 하드웨어에 효율적으로 매핑 가능 -> 표준 양자화 방법
(우)NonUniform
- Quantized Value들이 일정한 간격으로 매핑되지 않음.
- 하드웨어에서 효율적으로 배포하기 어려움
2. Symmetric vs Asymmetric
- Quantize Value들을 Mapping 하는 방법
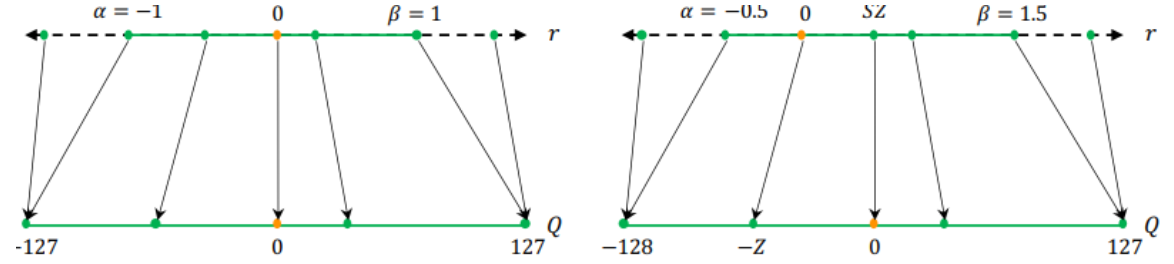
(좌) Symmetric
- output의 range를 정하는 min, max값의 절댓값이 동일한 경우
- 구현이 쉽지만 mapping 결과 범위가 비대칭일 수 있음
(우) Asymmetric
- output의 range를 정하는 min, max값의 절댓값이 동일하지 않은 경우
3. Static vs Dynamic
- Quantize 시킬 시점에 대한 방법
Static
- Weight, Activaiton 모두 Inference 전에 Quantize
Dynamic
- Weight는 Inference 전에 Quantize, Activation은 Inference 도중 Quantize
4. Integrated vs Sequential
- Quantize 단위를 결정하는 방법
Integrated
- 계산된 Calibration Range에 의거하여 Weight를 한꺼번에 Mapping 하여 Quantize
- 대표적인 방법으로 RTN (Round-To-Nearest) 가 있음
- RTN : 각 weight를 가장 가까운 quantization grid로 매핑시켜주는 것
Sequential
- Weight 값을 한개씩(or 묶음) Update 하며 objective function 에 의하여 quantization으로 생기는 loss를 최소화하면서 Quantize
- 대표적인 방법으로 OBQ (Optimal Brain Quantization) 가 있음
- OBQ : 각 weight를 순서대로 한개씩 mapping 하면서 objective function으로 원본 결과와 비교하여 손실을 최소화하는 방법으로 평가하면서 순차적으로 Quantize
Calibration 기준
- Calibration Range 의 기준을 설정하는 방법
- 모델의 어느 부분을 기준으로 Quantize를 수행할 것인가에 대한 방법
- Weight나 Activation 의 분포에 의거하여 Clipping Range를 계산하는 작업
Layer-Wise
- 한 Layer 내 모든 Channel에 대해 동일한 Clipping Range를 생성하여 Quantize
- e.g) Conv Layer의 모든 Filter에 대해 동일한 Clipping Range
- 장점 - 구현이 간단
- 단점 - Layer 내부의 Filter의 값들이 다르다는 것을 상정하지 않음.
Channel-Wise
- 각 Channel에 대해 하나의 Clipping Range를 생성하여 Quantize
- e.g) Conv Layer의 각 Filter에 대해 개별 Clipping Range
- 장점 - 채널 간 변동성 고려 가능 -> 정확도 UP
- 단점 - 구현이 복잡, 계산 비용 UP
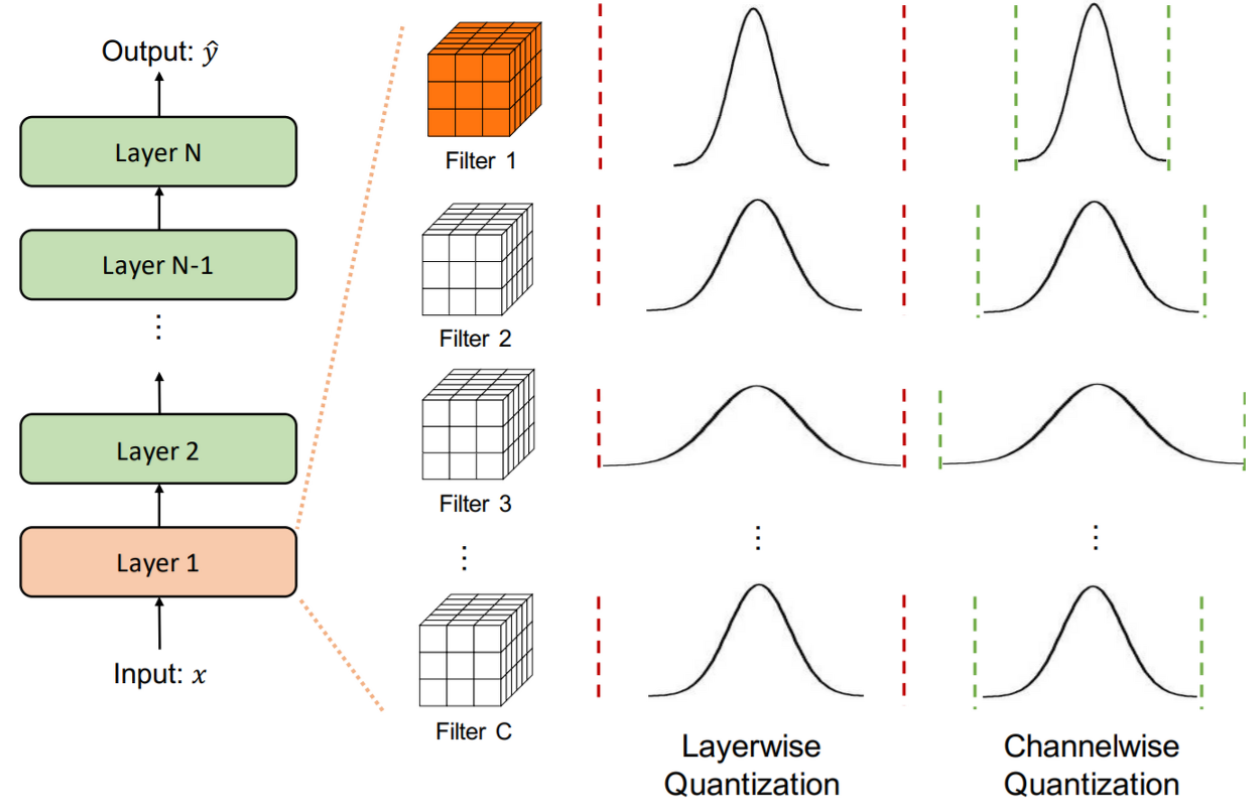
Group-Wise
- 여러 Channel들을 Group으로 묶어 각 Group마다 Clipping Range를 생성하여 Quantize
- e.g) Conv Layer의 채널들을 여러 Group으로 묶어 각 Group에 대해 그룹별 Clipping Range
- 장점 - Channel-Wise 보다 덜 복잡, 어느 정도의 정확도 상승
- 단점 - 그룹 내 채널들의 변동성을 완전히 반영 불가
Tensor-Wise
- 전체 Tensor에 대해 하나의 Clipping Range를 생성하여 Quantize
- e.g) 특정 연산에서 사용되는 모든 Weight, Activation에 대해 단일 Clipping Range
- 장점 - 구현 매우 간단, 효율적
- 단점 - 매우 제한적인 Range로 인한 성능 저하
Token-Wise
- 각 Token 마다 별도의 Clipping Range를 생성하여 Quantize
- e.g) NLP에서 각 단어 Embedding Vector에 대해 개별 Clipping Range
- 장점 - 각 토큰의 변동성 고려로 인해 정확도 상승
- 단점 - 구현 복잡, 계산 비용 증가
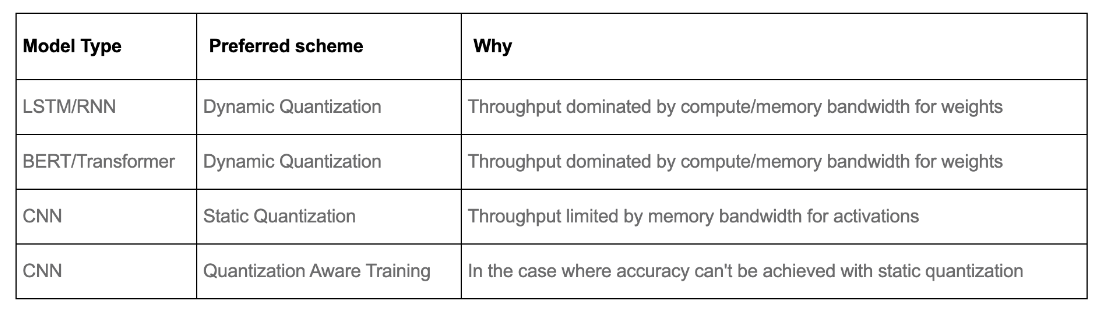
Select Quantization Method
- 어떤 Quantize Method를 사용하면 좋을지에 대한 guideline
Application Example
- 4가지 접근에서의 양자화 방법들을 선택 (상단의 Quantization 방법)
양자화 대상(W or A)을 Uniform, symmetric, static, sequential-column wise 방법들로 양자화 할 것이다. - 양자화 대상의 Calibration Range를 어떻게 정할지 선택 (상단의 Calibration 기준)
Quantaization Clipping Range를 Layer-Wise로 하여 양자화를 수행할 것이다.
Quantization Method Wise
- Quantize 방법 기준
Model Layer Wise
- 모델 아키텍쳐 기준
Quantization Framework
- 실제로 모델을 사용하기 위해서는 양자화, 최적화 두 Flow를 다 거쳐야 실제로 Inference 능력이 떨어지지 않음.
- 최적화는 양자화 모델을 Target으로 하는 Device에 최적화하여 연산을 효율적으로 수행하게끔 하는 과정.
Quantization Library
- torch.Quantizaion
https://pytorch.org/docs/stable/quantization.html - Neural Network Intelligence
https://nni.readthedocs.io/en/v1.6/model_compression.html - IntelLabs Distiller
https://github.com/IntelLabs/distiller - Huggingface Bitsandbytes (hf bnb)
https://huggingface.co/docs/transformers/main_classes/quantization
Optimization Framework (Compiler)
Quantization + Optimaization Framework
- mlc-llm
https://llm.mlc.ai/docs/get_started/introduction.html#deploy-your-own-model- 4bit 까지 지원
- Tensorflow Lite
https://www.tensorflow.org/lite?hl=ko- tensorflow(keras) model만 가능.
- 다양한 하드웨어 inference 가능
- target 하드웨어에 대한 추가 최적화 불가능
- 8bit 까지 지원
- TensorRT
https://developer.nvidia.com/tensorrt- tensorflow(keras), torch 둘 다 가능
- Nvidia GPU 로만 Inference 가능 (전용 최적화)
- Nvidia GPU 종류에 따른 추가 최적화 가능
- 4bit 까지 지원
- TVM
https://github.com/apache/tvm- tensorflow(keras), torch 둘 다 가능
- 다양한 하드웨어 inference 가능
- target 하드웨어에 대한 추가 최적화 가능
- 8bit 까지 지원

고려대학교 인공지능학과 SLP Lab 석사과정생