
3줄요약
- Diarization = Recognition(화자분류) + Segmentation(화자 변경 구간 탐지)
- 과거에는 segment(화자 변경 구간 탐지) -> clustering(화자label) & ASR(segment마다 stt수행)으로 cascade하게 수행
- 근래에는 여러 모듈들을 융합하며, ASR과 Diarizaiton을 병합하여 동시에 수행

1. Introduction
Speaker Diarization
- "누가"(Speaker Recognition) "언제"(Segmentation) 말했는지 구분하여 기록하는 것
- 포스팅에서는 "화자 구분" 이라고 언급
Traditional Method
- 전통적인 Speaker Diarization 기법 - 독립적인 여러 하위 모듈들로 구성됨

- Front-End Processing - 음성 신호 전처리 : e.g) 음성 증강, 음성 잔향 제거, 음성 분리 등
- Speech Activity Detection (SAD) - 음성 활동 감지 : 음성/비음성 부분으로 구분
- Segmentation - 음성 신호 세분화 : SAD로 음성/비음성 구분된 부분 중, 음성 부분만 사용
- Speaker Embedding - 음성 특징 추출 : 음성 부분을 음향(Acoustic) 특징이나 Embedding vector로 변환하여 각 화자의 특징을 추출
- Clustering - 화자별 그루핑 : 화자 특징 임베딩을 화자 정보로 그루핑
- Post Processing - 그루핑 결과 정제 : 그루핑된 부분을 정제
History
- 1990s : 화자 구분을 목적으로 초기 연구가 진행되었음
- Generalized Likelyhodd Ratio (GLR), Bayesian information criterion (BIC)
- 2000s : 화자 구분을 다양한 도메인에서 수행하는 목적으로 발전하였음
- information bottleneck clustering (IBC), variational Bayesian (VB) approaches, joint factor analysis (JFA)
- JFA를 사용한 대표적인 예시가 i-vector이며, 통계 모델링(PCA, VB-GMM, PLDA)을 활용하여 기존 강세였던 Mel에서 주파수를 분석하는 기법인 MFCC를 대체하였음
- 2010s : 신경망의 발전으로 화자 구분을 기존 통계 based에서 신경망(DL) 기반으로 진행
- d-vector, x-vector 등
- 기존의 하위 모듈들을 신경망으로 대체하는 end-to-end neural diarization (EEND)
Category
- Speaker Diarization 을 화자 구분을 목적으로 학습되었는지 아닌지, 단일 모듈/다중 모듈 결합에 대한 연구인지에 따라, 총 4가지 카테고리로 분류

1. 화자 구분 목적 X & 단일 모듈 최적화
- 화자 구분과 관련 없는 목표를 가진 시스템에서 단일 모듈에 대한 연구
- e.g) 음성 전처리 기술, 특정 모듈을 최적화하는 기술
2. 화자 구분 목적 O & 단일 모듈 최적화
- 개별 모듈을 최적화하여 전체 시스템 성능을 향상
- e.g) Affinity matrix refinement, IDEC, TS-VAD
3. 화자 구분 목적 X & 다중 모듈 결합 최적화
- 화자 구분과 관련 없는 목표를 가진 시스템에서 여러 모듈들을 결합하며 최적화된 경우
- 주로 다른 음성 처리 기술과 결합하여 성능을 향상시키는 방식
- e.g) VB-HMM, VBx
4. 화자 구분 목적 O & 다중 모듈 결합 최적화
- 화자 구분을 목적으로 여러 모듈을 결합하여 최적화
- 주로 신경망을 활용한 종단 간(end-to-end) 시스템에서 많이 사용됨
- e.g) UIS-RNN, RPN, online RSAN, EEND
Evaluation Metric
DER (Diarization Error Rate)
- 화자 구분 모델의 정확도를 측정하는 데 사용되는 지표
- 세 가지 오류 term의 합으로 구성됨

- 음성의 잘못된 경보(False Alarm, FA): 음성으로 예측되었지만 실제로는 비음성인 경우
- 음성의 놓친 탐지(Missed Detection, Miss): 실제로는 음성이지만 예측에서는 비음성인 경우
- 화자 레이블 간 혼동(Speaker Confusion, SC): 잘못된 화자로 예측된 경우
DER 예시
실제값 (Ref): 화자 A가 1분부터 2분까지 발언, 화자 B가 2분부터 3분까지 발언
예측값 (Hypothesis): 화자 A가 1분부터 1분 30초까지 발언으로 예측, 화자 B가 1분 30초부터 3분까지 발언으로 예측
False Alarm (FA): 예측에서 1분 30초부터 2분까지 화자 B의 발언이 잘못된 경보
- 잘못된 경보 시간: 30초
Missed Detection (Miss): 실제 화자 A의 발언 중 1분 30초부터 2분까지의 발언이 놓쳤음
- 놓친 발언 시간: 30초
Speaker Confusion (SC): 화자 A의 1분 30초부터 2분까지의 발언이 화자 B로 잘못 예측했음
- 잘못된 화자 예측 시간: 30초
Total Duration of Time: 전체 오디오 시간은 2분(1분부터 3분까지)
DER : 30(FA) + 30(MISS) + 30(SC) / 120(Total Duration of Time) = 0.75
JER (Jaccard Error Rate)
- 각 화자를 동등하게 평가하는 것을 목표로 하는 지표
- DER과 달리 발화 전체가 아닌 각 화자별 오류율을 먼저 계산하고, 이를 평균내서 구함
- 각 화자의 발화 시간(Pred)을 참조 기록(Label)과 비교하여 계산
- 각 화자별 오류율을 합산하여 평균
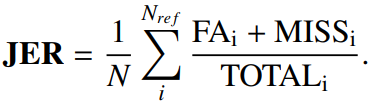
- JER은 예측과 실제의 교집합을 사용하여 계산되므로, JER은 100%를 초과할 수 없음
FAi : i번째 화자에 대한 잘못된 경보(False Alarm) 시간
MISSi : i번째 화자에 대한 놓친 탐지(Missed Detection) 시간
TOTALi : 실제값과 예측값에서 i번째 화자의 발화 시간의 합집합
Nref : 실제값에서의 화자 수
JER 예시
실제 기록 (Ref): 실제로는 화자 A가 1분부터 2분까지, 화자 B가 2분부터 3분까지 말함
예측 기록 (Hypothesis): 모델은 화자 A가 1분부터 1분 30초까지, 화자 B가 1분 30초부터 3분까지 말한 것으로 예측함
화자 A에 대한 FA: 0초 (잘못된 경보 없음)
화자 A에 대한 MISS: 30초 (1분 30초부터 2분까지의 발화가 놓쳤음)
화자 A의 TOTAL: 1분 30초 (실제와 예측에서 화자 A의 총 발화 시간)
화자 B에 대한 FA: 30초 (1분 30초부터 2분까지의 발화가 잘못 예측됨)
화자 B에 대한 MISS: 0초 (놓친 발화 없음)
화자 B의 TOTAL: 1분 30초 (실제와 예측에서 화자 B의 총 발화 시간)
WDER (Word-level Diarization Error Rate)
- 각 화자의 발화 시간을 기준으로 하는 DER과 달리, 최종 transcription 결과의 정확도를 측정하기 위해 설계된 지표
- 올바르게 라벨링된 단어와 잘못 라벨링된 단어를 세어 계산
Outline
1. Introdution
- 간단한 개요
2. Traditional Speaker Diarization System
- 화자 구분 목적 X & 단일 모듈 최적화 카테고리에서의 전통적인 모듈화된 Speaker Diarization System에 대한 설명
- Pre-Processing, 음성 활동 감지(SAD), Segmentation, Speaker Embedding, Clustering, Post-Processing
3. DL based Speaker Diarization System
- 화자 구분 목적 O 인 경우에서, 단일 모듈과 다중 모듈 결합으로 구분하여 설명
- DL 기반의 화자 임베딩, 모듈 결합 기법, End-to-End 화자 구분 시스템
4. Integration with ASR(=STT)
- ASR과 화자 구분의 역사적 상호작용, 현재 기술 동향, 미래 전망
5. Evaluation Metric & Dataset
- 화자 구분 기술을 평가하는 데 사용되는 다양한 지표와 연구에 사용되는 데이터셋을 소개
- DER, JER, 단어 수준 DER(WDER) 등
2. Traditional Modular System
- 전통적인 화자 구분 시스템은 여러 개의 독립적인 모듈로 구성되어 있음.
- 이 모듈들은 각각 특정한 역할을 수행하며, 전체 시스템의 성능을 최적화하기 위해 개별적으로 최적화됨.
1. Pre-Processing
- 음성 신호의 품질 향상을 목적으로 다양한 기술을 사용
- 신호에 STFT 변환을 수행하여 주파수 영역대로 변환한 결과를 사용함
- Spectrogram 또는 Spectrum을 feature로써 사용함
Spectrum vs Spectrogram
- (좌) Power Spectrum, (우) Spectrogram
Spectrogram
- raw signal을 STFT 변환시킨 결과
- 2D array로, (T,F)의 형태를 가지며 (시간, 주파수)의 차원에서 복소수(실수부+허수부)값을 가짐
- 복소수 값은 실수부 + 허수부로 이루어져 있으며, 실수부는 진폭(주파수 성분), 허수부는 위상(주파수 각도, time domain에서 파형이 어떻게 변하는지)을 의미함
Spectrum
- Spectrogram의 복소수값에서 절대값을 취하고 제곱한 값
- 2D array로, (T,F) 의 형태를 가지며, (시간, 주파수)의 차원에서 실수값(주파수 강도)을 가짐
- 절댓값을 취하는 이유는 위상 정보를 날리기 위함
- 제곱하는 이유는 주파수의 에너지(Power)는 신호의 크기(Amplitude)에 제곱해서 비례하기 때문
Example
- raw dim : 1D array - (,N) - N: Sample Num
- STFT Spectrogram dim : 2D array - (T,F) - T: 시간, F: 주파수
- Power Spectrum dim : 2D array - (T,F)
#STFT 수행
f, t, Zxx = stft(x, fs, nperseg=400, noverlap=200)
#진폭 계산
magnitude = np.abs(Zxx)
#파워 스펙트럼 계산
power_spectrum = magnitude ** 2- nperseg는 window 내 sample 수(segement 크기)
- noverlap은 window 내 sample 겹칠 sample 수(겹칠 크기)
- hop size = nperseg - noverlap
Speech Enhancement (음성 증강)
- 잡음을 줄이고 신호 대비 잡음 비율(SNR)을 개선하여 음성 신호의 품질을 향상
- LSTM : LSTM을 사용하여 음성 신호에서 잡음을 제거
- input: raw signal(noisy) -> STFT(spectrogram) -> Log Power Spectrum
- target: cleaned signal -> STFT(spectrogram) -> Log Power Spectrum
- input이 target을 예측하도록 MSE를 이용하여 LSTM 모델 구축
- LSTM : LSTM을 사용하여 음성 신호에서 잡음을 제거
Dereverberation (음성 잔향 제거)
- 실내 환경에서 발생하는 잔향을 제거하여 음성 신호의 명료도를 높임
- WPE (Weighted Prediction Error) : 음성 신호에서 늦게 도착하는 잔향을 제거
- STFT에서 WPE 필터를 적용하여 늦게 따라오는 잔향 제거
- raw signal -> STFT -> WPE -> inverse STFT -> Denoised Signal
- WPE (Weighted Prediction Error) : 음성 신호에서 늦게 도착하는 잔향을 제거
Speech Separation (음성 분리)
- 여러 화자가 동시에 발화하는 상황에서 각 화자의 음성 신호를 분리
- Bimforming : 여러 마이크를 사용하여 특정 방향에서 오는 음성 신호를 강화하고 다른 방향에서 오는 신호를 억제
- 멀티채널 음성 분리를 위한 대표적인 기술
- 빔포밍은 각 마이크의 신호를 STFT로 변환한 후, 특정 방향에서 오는 신호를 강화하는 필터를 적용함
- 각 채널(여러 화자)의 raw signal -> 각 채널의 STFT -> 각 채널의 Bimformer Weight 계산 -> 각 채널의 STFT에 각 채널의 Bimformer Weight 적용 -> inverse STFT -> 강화된 Signal
- Bimforming : 여러 마이크를 사용하여 특정 방향에서 오는 음성 신호를 강화하고 다른 방향에서 오는 신호를 억제
2. Speech Activity Detection (SAD)
- 음성 활동 감지(SAD)는 speech waveform에서 음성 구간과 비음성 구간을 구분하는 기술
Energy-based Method
- 음성 신호는 비음성 신호보다 에너지가 높다는 가정에 기반
- 신호의 에너지를 계산하고, 임계값을 설정해서 음성과 비음성을 구분
Static-based Method
- 음성과 비음성 구간의 통계적 특성을 모델링하여 구분
- 히든 마르코프 모델(HMM), 가우시안 혼합 모델(GMM) 등을 사용하여 음성과 비음성을 분류
Machine Learning-based Method
- 간단한 신경망, 서포트 벡터 머신(SVM) 등의 머신러닝 모델을 사용하여 음성과 비음성 구간을 분류
- 대규모 음성 데이터를 사용해 모델을 학습시키고, 이를 바탕으로 음성과 비음성을 구분
Deep Learning-based Method
- 심층 신경망을 사용하여 음성과 비음성 구간을 구분
- CNN, RNN, LSTM 등 사용
3. Segmentation
- 음성 신호를 연속된 부분(segment)으로 나누는 과정
- 화자 분할(Speaker Diarization)과 음성 인식(ASR) 시스템에서 중요한 전처리 단계
Segment Category
Fixed-Length Segment (고정 길이 Segment)
- 일정한 길이의 Segment로 신호를 나눔
Variable-Length Segment (가변 길이 Segment)
- 신호의 변화에 따라 Segment의 길이를 동적으로 조절
Segmentation Techniques
1. BIC (Bayesian Information Criterion)
- BIC 값을 사용하여 신호의 변화를 탐지
- 각 Segment의 BIC 값을 계산하고, BIC 값이 최대인 지점에서 신호를 분할
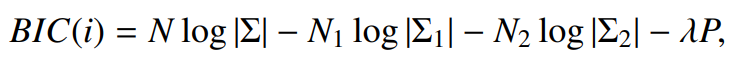
-
N: 샘플수
-
sigma: 공분산행렬
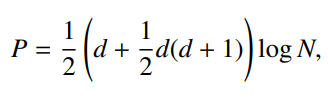
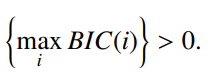
-
BIC점수 = 전체구간의 결정값 - 1번구간의 결정값 - 2번구간의 결정값 - 규제항
-
BIC점수가 최대가 되는 지점에서 신호를 분할
# BIC 계산 함수
def compute_bic(X, i):
N, d = X.shape
X1, X2 = X[:i], X[i:]
N1, N2 = len(X1), len(X2)
# 공분산 행렬 계산
Sigma = np.cov(X, rowvar=False)
Sigma1 = np.cov(X1, rowvar=False)
Sigma2 = np.cov(X2, rowvar=False)
# 로그 결정 행렬 값 계산
log_det_Sigma = np.log(det(Sigma))
log_det_Sigma1 = np.log(det(Sigma1)) if N1 > d else 0
log_det_Sigma2 = np.log(det(Sigma2)) if N2 > d else 0
# 페널티 항 계산
P = (d + 0.5 * d * (d + 1)) * np.log(N) / 2
# BIC 값 계산
bic_value = N * log_det_Sigma - N1 * log_det_Sigma1 - N2 * log_det_Sigma2 - P
return bic_value
# 음성 신호 생성
fs = 16000 # 샘플링 주파수
t = np.linspace(0, 1.0, fs)
x = np.concatenate([ # 분할 시점 정해놓이 이전에는 1번신호, 이후에 2번신호 만듬
np.sin(2 * np.pi * 440 * t[:fs//2]), # 1번신호
np.sin(2 * np.pi * 880 * t[fs//2:]) # 2번신호
])
# 스펙트로그램 생성
nperseg = 400
noverlap = 200
f, t, Zxx = stft(x, fs, nperseg=nperseg, noverlap=noverlap)
magnitude_spectrogram = np.abs(Zxx)
# BIC 기반 분할
bic_values = []
for i in range(1, magnitude_spectrogram.shape[1]):
bic = compute_bic(magnitude_spectrogram.T, i) # 전치하여 프레임별로 분할
bic_values.append(bic)
bic_values = np.array(bic_values)
change_point = np.argmax(bic_values) + 1 if np.max(bic_values) > 0 else -1
# 결과 출력
print(f"최적의 분할 지점: {change_point}, BIC 값: {np.max(bic_values)}")2. AIC (Akaike Information Criterion)
- AIC 값을 사용하여 신호의 변화를 탐지
- 각 Segment의 AIC 값을 계산하고, AIC 값이 최대인 지점에서 신호를 분할
3. GLR (Generalized Likelihood Ratio)
- GLR 값을 사용하여 신호의 변화를 탐지 (통계적 방법)
- 각 Segment의 GLR 값을 계산하고, GLR 값이 최대인 지점에서 신호를 분할
4. DNN (Deep Neural Network)
- 심층 신경망을 사용하여 신호의 변화를 학습하고 탐지
- 학습된 DNN 모델을 사용하여 신호의 변화 지점을 예측하고 분할
4. Speaker Representation
- Speaker Representation을 뽑는 방법에 대하여 설명하고, Representation에 대한 평가 과정까지의 전체 시스템을 이야기할 것
1. Similarity Metirc
- 과거에는 따로 Speaker Representation을 뽑지 않고, Segment들의 유사도에 의거하여 화자 분리를 하였음
- 유사도 지표로는 KL-Distance, GLR, BIC 등이 있으며, Segmentation에서도 사용됨
2. GMM-UBM based Representation
- 초기 speaker representation 추출 시스템
- (한계) MAP 적응 과정에서 채널 잡음과 같은 원치 않는 변이도 함께 학습됨
- (한계) 추출되는 Representation은 고차원임
- Speaker Verification System으로부터 Representation 추출
- UBM훈련 -> GMM훈련 -> representation 추출 -> representation 평가
1. UBM
- 다양한 화자의 음성 데이터를 사용하여 각 화자에 독립적인 UBM을 훈련
- UBM은 많은 수의 가우시안 모델이 혼합된 형태 (512~2048 사이라고 함)
- 모델은 일반적인 음향 특성을 학습하게 됨
- 많은 수의 가우시안 혼합 모델을 포함하고 있으며, 각 혼합 모델은 평균 벡터, 공분산 행렬, 혼합 가중치를 가지고 있음
2. GMM
- 특정 화자의 음성 데이터를 사용하여 UBM을 해당 화자에 맞게 적응시킴
- 화자의 특성을 반영하는 새로운 GMM이 생성됨
- 적응과정(재훈련)에서 MAP (maximum a posteriori)가 사용됨
3. Speaker Representation
- GMM의 평균 벡터가 Speaker Representaion
4. Evaluate Representation
- Speaker Verification Task에서 정확도 평가
- GMM과 UBM 간의 Log Likelyhood Ratio를 계산하여 화자를 검증
- 특정 음성 Segment가 주어진 화자의 GMM에 얼마나 적합한지를 평가
2. Joint Factor Analysis (JFA) Representation
- GMM-UBM의 결과로 나온 Representation (M) 에서 스피커와 채널 변이를 분리하여 모델링
- (GMM-UBM의 한계 개선) Speaker Representation을 추출하는 과정에서 채널 잡음(환경 잡음)을 분리하였음
- (한계) 여전히 고차원임
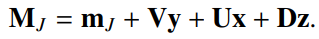
- M: GMM-UBM의 결과로 나온 SuperVector
- m: Supervector의 평균
- 여러 화자의 SuperVector를 평균내어 화자에 독립적인 평균 벡터 m을 추정
- y: 화자 변이 벡터
- 화자 변이를 나타내는 행렬 V를 학습
- SuperVector에서 m을 뺀 후, 화자 변이 벡터를 투영(V)시켜 변이를 학습
- z: 채널 변이 벡터
- 녹음 환경과 장비에 의해 발생하는 음성 신호의 변화를 의미
- 채널 변이를 나타내는 행렬 U를 학습
- SuperVector에서 m과 Vy를 뺀 후, 채널 변이를 학습
- x: 잔여 변이 벡터
- SuperVector에서 m, Vy, Ux를 제거한 후 남은 부분으로 추정
simple code example
import numpy as np
from sklearn.mixture import GaussianMixture
# 가상의 데이터 생성
np.random.seed(0)
num_speakers = 5
num_utterances = 10
feature_dim = 13
supervector_dim = feature_dim * 10 # 가우시안 혼합 모델(GMM)의 혼합 수를 10으로 가정
# 각 스피커에 대해 초벡터(supervector) 생성
supervectors = []
for speaker in range(num_speakers):
for utterance in range(num_utterances):
# 각 화자의 발화에 대해 초벡터 생성 (랜덤 데이터로 시뮬레이션)
supervector = np.random.randn(supervector_dim)
supervectors.append(supervector)
supervectors = np.array(supervectors)
# 평균 벡터(m) 추정
m = np.mean(supervectors, axis=0)
# 스피커 변이 행렬(V) 및 변이 벡터(y) 추정
def estimate_speaker_variability(supervectors, m, num_speakers, supervector_dim):
V = np.random.randn(supervector_dim, num_speakers)
y = []
for i in range(num_speakers):
speaker_vectors = supervectors[i * num_utterances: (i + 1) * num_utterances]
speaker_mean = np.mean(speaker_vectors, axis=0)
y_i = np.linalg.pinv(V).dot(speaker_mean - m) # pseudo-inverse를 사용하여 y_i 추정
y.append(y_i)
return V, np.array(y)
V, y = estimate_speaker_variability(supervectors, m, num_speakers, supervector_dim)
# 채널 변이 행렬(U) 및 변이 벡터(z) 추정
def estimate_channel_variability(supervectors, m, V, y, num_speakers, num_utterances, supervector_dim):
U = np.random.randn(supervector_dim, num_utterances)
z = []
for i in range(num_speakers):
for j in range(num_utterances):
idx = i * num_utterances + j
residual = supervectors[idx] - m - V.dot(y[i])
z_i = np.linalg.pinv(U).dot(residual) # pseudo-inverse를 사용하여 z_i 추정
z.append(z_i)
return U, np.array(z)
U, z = estimate_channel_variability(supervectors, m, V, y, num_speakers, num_utterances, supervector_dim)
# 결과 출력
print("평균 벡터 (m):", m)
print("스피커 변이 행렬 (V):", V)
print("스피커 변이 벡터 (y):", y)
print("채널 변이 행렬 (U):", U)
print("채널 변이 벡터 (z):", z)3. i-vector Representation
- 대중적인 speaker representation 추출 시스템
- Speaker Identification System으로부터 Representation 추출
- 훈련된 UBM-GMM -> 각 화자의 Speaker Representation -> 저차원에 투영(i-vector) -> PLDA (Speaker간 유사도 평가)
i-vector Representation
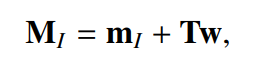
- 해당 수식은 w = T^-1(M-m) 으로 다시 표현할 수 있음
- M은 Supervector, m은 Supervector의 평균, T는 학습가능한 Projection Matrix
- T를 학습시켜 i-vector(w)를 얻음
- (특징) 채널잡음을 분리하지 않고, 통으로 Representation을 추출하였음
- (GMM-UBM, JFA의 한계 개선) 저차원의 벡터로 추출하여, 다양한 하류 작업에서 작업 가능
very simple code
np.random.seed(42)
n_samples = 1000 # 샘플 수
n_features = 13 # MFCC 차원 (예: 13)
n_components = 16 # GMM 구성 요소 수 (예: 16)
# 임의의 MFCC 특징 벡터 생성
X = np.random.rand(n_samples, n_features)
# 1. GMM-UBM 학습
gmm_ubm = GaussianMixture(n_components=n_components, covariance_type='diag', max_iter=100)
gmm_ubm.fit(X)
# 2. MAP 적응: 화자 발화 데이터를 사용하여 GMM을 적응시킵니다.
def map_adapt(gmm, X):
"""MAP 적응을 통해 GMM을 적응시킴"""
n_components, n_features = gmm.means_.shape
n_samples = X.shape[0]
# 계산된 책임도 (responsibility)
responsibilities = gmm.predict_proba(X)
# 새로운 평균 계산 (MAP 적응)
adapted_means = np.zeros_like(gmm.means_)
for i in range(n_components):
N_i = responsibilities[:, i].sum()
adapted_means[i] = (responsibilities[:, i][:, np.newaxis] * X).sum(axis=0) / N_i
return adapted_means
# 발화에 대한 MAP 적응을 적용하여 새로운 GMM 평균 (적응된 평균 벡터) 얻기
adapted_means = map_adapt(gmm_ubm, X)
# 3. 초벡터 생성: 적응된 평균 벡터를 결합하여 초벡터(supervector)를 생성
supervector = adapted_means.flatten()
# 4. Total Variability Matrix 학습 (PCA를 사용하여 단순화)
# 실제 시스템에서는 더 복잡한 방법으로 학습하지만, 여기서는 PCA를 사용하여 T를 근사화합니다.
pca = PCA(n_components=100) # 100차원으로 투영
pca.fit(np.array([supervector])) # 초벡터로 PCA 학습
# 5. i-vector 추출
i_vector = pca.transform(np.array([supervector]))[0]
print("i-vector shape:", i_vector.shape)PLDA Analysis
- i-vector가 speaker representation을 잘 뽑았는지 평가
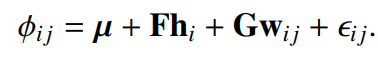
- 파이: i-vector, 뮤: i-vector의 평균 벡터, F: 화자 변이 행렬, G: 채널 변이 행렬,
h: speaker latent factor, w: session latent factor, e: residual term - EM알고리즘을 이용하여 PLDA의 파라미터를 학습
- E(Expectation Step)에서 latent factor(h,w)의 기대값 계산
- M(Maximization Step)에서 파라미터(F,G) 최대화
- E, M과정을 수렴할 때까지 반복 (파라미터의 변화가 없어질 때까지)
- (한계) EM알고리즘이 너무 복잡하고 오래걸림 -> G-PLDA 사용
G-PLDA Anaysis
- i-vector가 speaker representation을 잘 뽑았는지 평가
- latent factor(h,w) 가 gaussian distribution을 따른다고 가정
-> PLDA 계산이 간단해짐
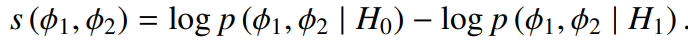
- 로그 가능도 비율을 사용하여 두 샘플이 동일한 화자로부터 왔는지 평가
- 파이1, 파이2는 각각 다른 두 샘플을 의미하고, 같은 화자인지, 다른 화자인지 판별
- 로그 가능도 비율이 양수이면 같은 화자일 확률이 높고, 음수이면 다른 화자일 확률이 높음
- 이 비율은 화자 검증 및 분리 작업에서 클러스터 간의 유사성을 평가하는데 사용됨
Summary
- i-vector system: Supervector를 저차원 벡터로 투영하여 화자를 표현
- PLDA: i-vector를 사용하여 화자와 채널 변이를 모델링하고, 화자간 유사성을 평가
- G-PLDA: PLDA 모델을 가우시안 분포를 따르는 잠재 변수로 단순화하여 계산을 간단하게 만듬
4. Neural Network Based Representations
- 신경망을 이용한 Speaker Representation 추출 방법
- 최근 접근법으로, 가장 많이 사용되는 방법
- 주요 방법: d-vector, x-vector
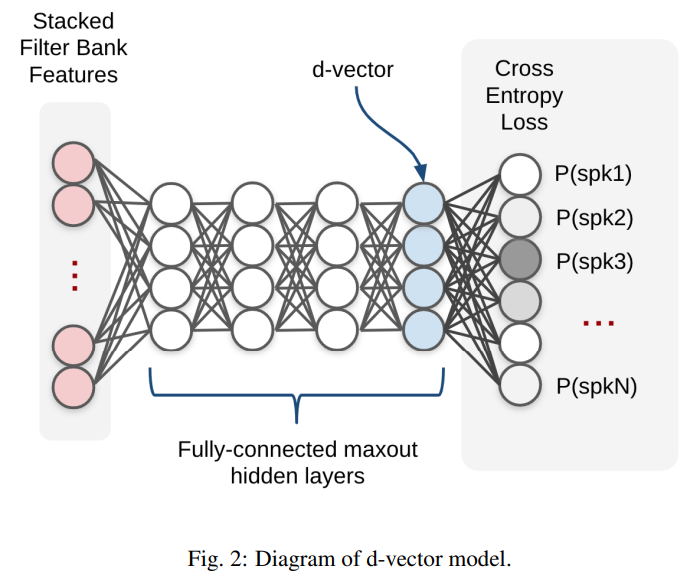
d-vector
- 신경망을 통해 고정된 길이의 벡터를 추출하는 방법
- 음성 신호의 frame별 특징을 추출한 후, 이들을 평균 내서 하나의 벡터로 만듬
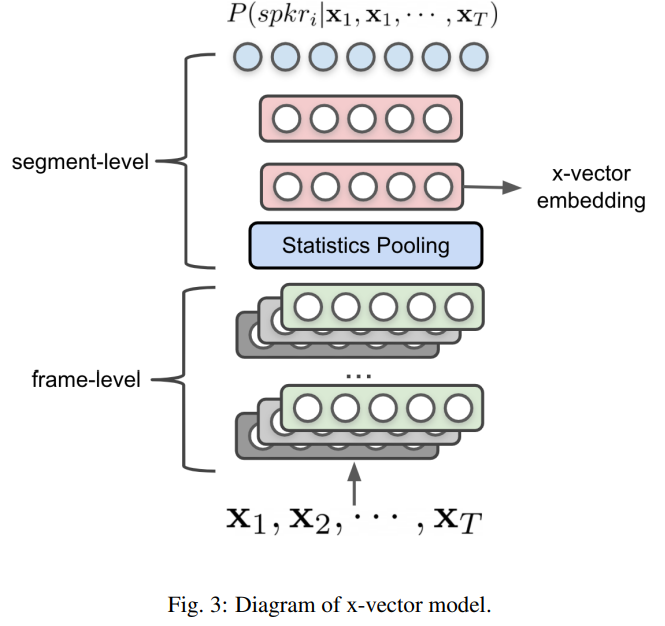
x-vector
- d-vector의 개선된 버전으로, 더 깊은 신경망 구조를 사용하여 더 강력한 Speaker Representation을 생성함
- x-vector는 음성 신호의 frame별 특징을 추출한 후, 이를 더 복잡한 네트워크를 통해 처리하여 segment level feature를 뽑고, 이를 이용하여 최종 Speaker Representation을 생성함
5. Clustering
- 추출한 Speaker Representation을 이용하여 Segment의 Cluster를 생성함
- Speaker Diarization 목적의 Clustering 방법을 설명할 예정
Agglomerative Hierarchical Clustering (AHC)
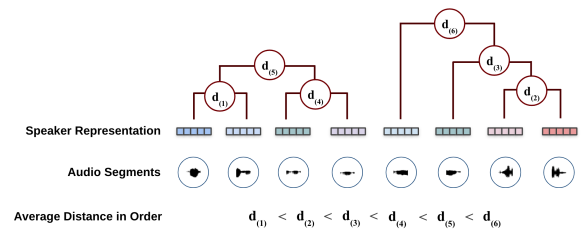
- 초기에는 각각의 음성 Segment를 개별 Cluster로 간주한 다음, 가장 유사도가 높은 두 클러스터를 합치는 과정을 반복하여 수행
- 유사도는 앞서 언급한 BIC, KL, PLDA 등을 사용할 수 있음
- 모든 Segment가 특정 기준의 Cluster로 합쳐질 때까지 반복 수행
- 특정 기준으로 유사도 임계값, Cluster(화자) 수 지정 가능
Spectral Clustering
- Graph Theory에 기반한 Clustering 방법
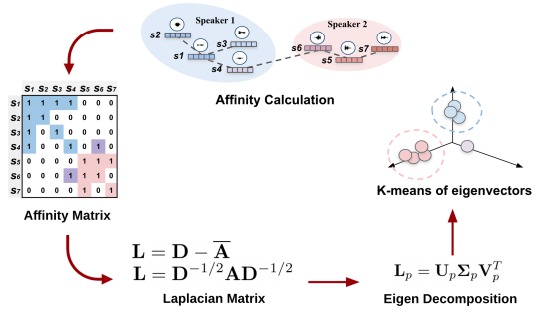
- Segment의 Similarity을 Graph로 표현하고, Graph의 Laplacian Matrix의 eigen value값 및 eigen vector를 사용하여 cluster를 찾는 방법
- Graph로 표현할 때, Node값으로 Segment, Edge값으로 Affinity Matrix(유사도) 사용
Spectral Clustering 단계
1. Affinity Matrix (유사도 행렬 생성)
- 가우시안 커널을 사용하여 segment들 간의 유사도 행렬 A를 만듬
2. Graph Laplacian (그래프 값 계산)
- 유사도 행렬 A을 사용하여 Graph Laplacian L을 계산
3. Eigen decomposition (고유값, 고유벡터 계산)
- Graph Laplacian L의 가장 작은 k개의 고유값, 고유벡터를 계산하고, (n,k) dimension을 갖는 행렬 U를 생성
- U의 (n,k)에서 n는 segment num, k는 선택한 고유벡터 수를 의미
4. Spectral Embedding
- U의 각 행은 원래 Segment를 k차원 공간으로 Mapping한 Spectral Embedding을 의미함
- 즉, U의 각 행은 각 Segment의 k차원 벡터를 의미
5. Clustering
- 행렬 U의 각 행(Segment)에 대해 k-means 클러스터링을 수행함
Other Clustering Algorithm
K-Means
- 장점: 알고리즘이 단순하고, 빠름
- 단점: 앞서 설명한 AHC, Spectral Clustering 보다 성능이 떨어짐
Mean-shift
- 장점: 사전에 Cluster 수 지정할 필요 없음 (비모수 방법)
- e.g) KL Distance, i-vector & cosine sim, i-vector & PLDA
6. Post-Processing
Resegmentation
- Clustering 결과를 통해 추정된 Speaker Boundary를 정교하게 조정하는 과정
Viterbi Resegmentation
- 최적의 Sequence를 찾기 위한 Dynamic Programing 방법
- GMM 추정 : 각 화자에 대응하는 GMM을 추정. Baum-Welch 알고리즘을 사용하여 각 화자의 음성 데이터에 맞는 GMM 파라미터 학습
- Resegmentation : 추정된 GMM으로 Viterbi Resegmentation 수행
VB-HMM based Diarization
- Variational Beysian Hidden Marcop Model (VB-HMM)
- Segmentation, Clustering을 함께 최적화
- Viterbi Resegmentation 보다 우수한 성능
System Fusion
- 여러 Speaker Diarization system의 output을 결합(앙상블)하여 최종 결과를 개선
- 앙상블시 주의할 점
- 서로 다른 system 간 화자 label이 다를 수 있음
- 서로 다른 system 간 추정된 화자의 수가 다를 수 있음
- 여러 system 간 추정된 시간의 경계가 다를 수 있음
연구 사례
- 최적의 system 선택
- 각 system을 하나의 cluster로 보고, AHC 방법을 사용하여 2개 cluster가 남을 때까지 반복하고, 큰 cluster에서 다른 모든 diarization output과의 거리가 짧은 output을 최종 결과로 선택
- 두 system의 결합
- 두 화자 cluster간의 matching을 찾고, matching 결과에 기반하여 resegmentation 수행
- 여러 system 결합
- Diarization Output Voting Error Reduction (DOVER)
- Voting 기반으로 output을 결합
- DER값 기반을 서로 다른 system 간의 화자 label을 정렬
- 모든 화자를 정렬한 후, 각 시스템은 각 세그먼트 영역에 화자 label을 투표
- 각 Segment 영역에서 가장 높은 투표 가중치를 얻은 화자 label이 선택됨
- 여러 화자 label이 동일한 투표 가중치를 얻은 경우, 첫 번째 system의 결과를 선택하는 등의 huristic 방법 사용
- (단점) 중첩된 음성이 없는 상황을 가정
- 중첩된 음성도 처리 가능하게 여러 화자 system 결합
- 수정된 DOVER: DOVER와 동일하지만, 각 Segment에 대해 각 화자의 음성 활동을 가중치 투표 점수 기반으로 추정한다는 차이가 있음
- Dover-LAP : 중첩된 화자를 처리하기 위해 가중치가 부여된 k-part graph matching 사용해서 화자를 정렬하고, 각 segment에서 voting 수행한 뒤, 상위 K개의 화자 label 선택함. K는 해당 segment에서 발화하고 있는 화자의 수를 나타냄
7. Joint Segmentation & Clustering
- 1~6까지의 과정은 화자의 경계 먼저 구분하고, 경계를 기준으로 나뉜 segment들에 기반하여 clustering 하여 화자를 구분하였음 (화자 경계 나누기 + 화자 구분)
- 해당 시스템은 경계 나누기와 화자 구분을 cascade하게 수행하지 않고, 동시에 수행함
VB-HMM
- HMM : sequential한 data에서 특정 화자(hidden state)를 모델링하는 확률 모델
- VB : 복잡한 모델의 추론을 간단하게 근사하여서 해결하는 Beyesian method
VB-HMM Process
- GMM : 각 화자에 대해 GMM을 정의
- HMM : 화자 간 전이 확률을 정의
- E-Step : 각 샘플이 특정 화자에 속할 확률 계산
- M-Step : 계산된 확률에 기반해서 각 화자에 대한 GMM Update
- EM과정 반복
- 최종 예측 : 각 Segment가 어느 화자에 속하는지 예측
=> Segment 단위로 Clustering되어 화자 변이를 예측하면서 구분을 동시에 하게 됨
VB-HMM Code example
# GMM
gmm_speakers = []
for i in range(n_speakers):
gmm = GaussianMixture(n_components=1, covariance_type='full')
X = np.random.rand(n_samples, n_features) + i # speaker bias
gmm.fit(X)
gmm_speakers.append(gmm)
# HMM
transition_matrix = np.array([
[0.7, 0.2, 0.1], # 화자 1에서 다른 화자로 전이될 확률
[0.2, 0.6, 0.2], # 화자 2에서 다른 화자로 전이될 확률
[0.1, 0.3, 0.6] # 화자 3에서 다른 화자로 전이될 확률
])
initial_state_prob = np.array([0.5, 0.3, 0.2]) # initalize state prob
# EM
def e_step(X, gmm_speakers, transition_matrix, initial_state_prob):
# 가우시안 혼합 모델을 사용하여 각 화자에 대한 확률 계산
n_samples = X.shape[0]
n_speakers = len(gmm_speakers)
gamma = np.zeros((n_samples, n_speakers)) # 책임도 행렬
for t in range(n_samples):
for k in range(n_speakers):
gamma[t, k] = gmm_speakers[k].score_samples(X[t].reshape(1, -1))
# 확률 정규화
gamma = np.exp(gamma)
gamma /= gamma.sum(axis=1, keepdims=True)
return gamma
def m_step(gamma, X):
# 각 화자 GMM을 업데이트 (책임도를 기반으로)
for k in range(len(gmm_speakers)):
weights = gamma[:, k]
gmm_speakers[k].fit(X, sample_weight=weights)
# E-step 및 M-step 반복
for iteration in range(10):
gamma = e_step(X, gmm_speakers, transition_matrix, initial_state_prob)
m_step(gamma, X)
# 예측
predicted_speakers = np.argmax(gamma, axis=1)Variational Bayesian x-vector (VBx)
- VB-HMM과 동일한 방법으로 모델링하지만, VB-HMM에서는 학습할 때 segmentation의 spectrogram, MFCC를 feature로 사용하는 반면, VBx에서는 학습 feature로 x-vector를 사용함으로써, 학습 시간을 매우 단축시키고 좋은 성능을 끌어냄
3. Recent Speaker Diarization
- DL을 이용한 최근의 Speaker Diarization 방법론들
- feature size (feature dim) 은 보통 (segement_num, feature)가 됨
- feature로는 MFCC 또는 log mel spectrogram이 이용됨
Single-Module Optimization
- 이전 단원에서 다루었던 고전 방법의 단일 모듈에 대해서 DL로 바꾼 경우를 설명
Clustering Enhance
GNN
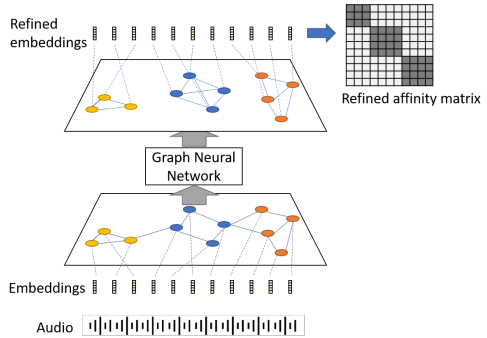
- 노드값에 segment별 화자 representation을 넣어줌
- 엣지값에 화자 representation 간의 유사도 행렬 (Affinity Matrix)을 넣어줌
- 유사도 행렬로 self-attention 기반으로 계산된 matrix를 사용하기도 함
DEC (deep embedded clustering)
- Latent Space 에서 Clustering 성능을 향상시키는 방법
- AutoEncoder를 사용하여 화자벡터를 latent space에 mapping하고, latent space에서 clustering 수행
DEC Process
- AutoEncoder : feature_dim -> Embedding_dim -> feature dim의 형태를 갖는 AE 학습 (Reconstruction Loss)
- KMeans Clustering : 학습된 Encoder를 이용하여 latent space로 mappnig 후, K-Means로 초기 Cluster 생성
- DEC : 학습된 Encoder 뒤에 Clustering Layer를 추가한 구조. Clustering layer는 그냥 nn.linear(emb_dim, n_cluster) 를 의미
- KL-Divergence : DEC 모델은 목표 분포와 Soft aligned cluster prob의 KL-Divergence를 최소화하는 방식으로 최적화함
Distance Estimator
- 기존 방법들은 동일한 size로 segmentation을 수행하여서 time domain이 무시되었음
- Segment들 간의 관계를 모델링(거리 측정)하기 위하여 제안
RRNNs (Relational RNN)
- 최종 화자 분류는 Segment와 cluster 중심간의 거리에 관련이 있음
- 기존에는 거리를 계산하는 데 PLDA, cosine 등을 사용하였지만, RNN based로 화자 cluster 중심과 segment embedding 간의 관계를 학습하는 방식을 선택하였음
Post Processing
- DL로 upgrade한 post processing 방법 설명 (Clustering성능 향상)
TS-VAD
- Target-Speaker Voice Activity Detection
- 화자 중첩, noisy 한 environment에서도 동작
TS-VAD 동작원리
- input1: i-vector들 (K, f) = (화자수, ivector_dim)
- input2: MFCC (T,d) = (frame, MFCC_dim)
- output: 화자의 발화 확률 벡터 (T,K) = (frame,화자수)
- 각 frame에서 모든 화자들에 대한 활동
- process
- 전통적인 clustering method로 initial diarization 결과 획득
- 각 화자의 clustering 결과 기반으로 i-vector 추출
- i-vector를 TS-VAD에 적용하고, 그 결과를 기반으로 i-vector를 정제하면서 해당 과정 반복
EEND
- 전통적인 clustering은 다수의 화자 처리가능하지만, 중복처리는 불가능
- 해당 방법은 중복 발화는 처리가능하지만, 화자 수가 많으면 한계
- 따라서 EEND와 전통적인 clustering 방법을 함께 사용
Joint Optimization
- 이전 단원에서 다루었던 고전 방법의 여러 모듈에 대해서 DL로 바꿔서 통합한 경우를 설명
Segmentation + Clustering
UIS-RNN
- GRU를 이용하여 frame(=sequence)를 모델링하고, Distance-dependent CRP로 화자를 할당한 뒤, 베르누이 분포를 통해 화자 변경을 모델링
UIS-RNN Process
- input: sequence embedding (T,d) = (frame, feature_dim)
- ouput: speaker label sequence (T,) = (frame,) => frame마다 화자 label이 들어있음

- X: input (sequence embedding)
- Y: output (speaker sequence)
- Z: latent vector (sequence 에서의 화자 변경 여부)
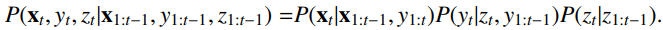
- 첫번째 Term : 이전까지 embedding sequence와 현재 화자 index를 기반으로 현재 embedding vector xt
- GRU,RNN으로 모델링함
- 현재 sequence 생성 확률
- 두번째 Term : 화자 변경 여부에 따라 현재 시간 t에서 화자 인덱스를 어떻게 할당할 것인지 모델링
- CRP (Distance-dependent Chinese Resturant Process) 를 사용하여 모델링
- 화자 수가 제한되지 않은 상황에서 화자 관계를 모델링하기 좋음
- 화자 할당 확률
- 세번쨰 Term : 이전 시간 (t-1)까지의 화자 변경 여부 (z:t-1) 에 따라 현재 시간 t에서 화자가 변경될 확률을 모델링
- 베르누이 분포 사용
- 화자 변경 확률
Segmentation + Embedding Extraction + ReSegmentation
- RPN을 도입하여 수행
RPN 개념
- 이미지에서 객체탐지 목적으로 제안된 방법
- 객체 탐지하기 위해 anchor 박스를 사용하여 여러 위치에서 객체가 존재하는지 확률를 모델링
RPN 작동 방식
- input: frame당 feature (T,F) = (frame_num, feature=spectorgram)
- latent feature: (T,F) -> (T,F,C) (C:CNN으로 나온 Channel)
- latent feature에 window를 시간축을 기준으로 다양하게 씌워 Anchor 생성
- Anchor는 음성 신호의 특정 시간 구간을 의미하게 됨
- output1(SAD, Speaker Activity Detection) : (N,1)
- N은 생성된 앵커(anchor)의 수
- 각 anchor 구간에 음성 활동이 있는지 판단 (0,1값)
- output2(Speaker Embedding) : (N,d)
- d는 speaker embedding의 차원
- output3(Region Refinement) : (N,2)
- 각 앵커의 위치와 크기를 보정하기 위하여 앵커의 중심위치, 앵커길이 두 정보를 저장
- 해당 output들을 이용하여 이후 과정(clustering, post processing)을 통해 Speaker Diarizaiton 결과 획득 가능
Seperation + Diarization
- Speech Separation : 여러 화자의 중복된 음성을 각각의 개별 음성으로 분리
- Speech Diarization : 누가 언제 말했는지 식별하는 작업
- 누가(Speech Recognition) + 언제 식별 (주의. STT는 별개의 작업임)
기존 연구 : Koundaes-Bastian
- 행렬 분해, 공간 공분산 모델을 사용(통계적 모델링)하여 수행
RSAN
- 하나의 모델로 음성 분리, 화자 수 계산, 화자 Diarization 동시에 수행
RSAN 작동 방식
- input : (T,F) (F:Spectrogram)
- Residual Mask : (T,F) 이전 단계 (t-1)에서 남은 음성 신호를 나타내는 mask
- Speaker Embedding : (d,) 이전 단계에서 얻은 화자 임베딩 벡터
- output1 : Residual Mask : (T,F)
- output2 : speaker embedding (d,)
- feature에 대해서 화자1에 대한 임베딩을 뽑고, 나머지 신호 영역을 뽑음. 다음 단계에서 화자2에 대한 임베딩을 뽑고, 또 그 나머지 신호 영역을 뽑음. 해당 과정을 반복하여 나머지 영역의 평균 값이 특정 임계값 이하로 떨어지면 반복 과정을 중단하고 각 화자 임베딩과 잔여 mask를 얻을 수 있음
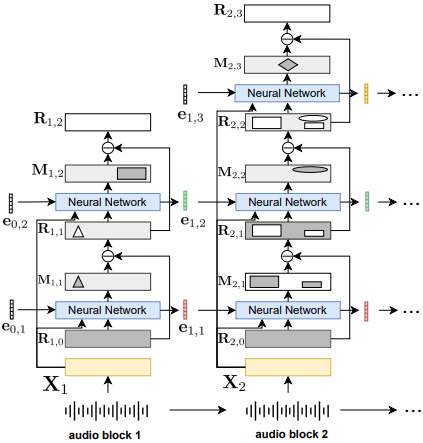
End-to-End Diarization (EEND)
- 하나의 신경망으로 Speaker Diarization의 모든 과정을 수행
- 과거에는 cascade한 module로 구성하던 것을 하나의 모델로 모든 과정 수행
- input : (T,F)
- output : (T,K) K : 화자수, 각 frame에서 어떤 화자가 말했는지
- self-attention, bilstm으로 모델링
4. Speaker Diarization & ASR
- 기존에는 Diarization은 ASR의 preprocessing의 과정이였고, ASR성능(WER) 는 고려하지 않고 Segment를 처리하는 방식으로 진행되었음
- 하지만, 이런 방식은 Truncation 등의 오류가 발생할 수 있음
- 최근에 ASR과 Diarization의 융합이 이루어지고 있음
초기 연구
- ASR 결과로 나온 lexical(어휘) 정보를 Speaker Diarization system 에 활용
- 초기 연구로 큰 발전은 없었음
RT03 eval
- ASR의 결과로 나온 단어 경계 정보를 segmentation에 활용
- 성능인 미비했지만, ASR을 이용하여 Diarization 성능을 올리려는 첫 시도
RT07 eval
- 화자 Dependent한 ASR로부터 얻는 word alignments를 활용하여 SAD를 개선함으로써, Clustering 성능 향상
segmentation system
- ASR의 word alignments를 이용하여 segmentation 개선
- segmentation의 결과와 해당 ASR 출력의 단어가 일치하지 않는 문제 개선(word-breakage)
Diarization based on ASR lexical informantion
- ASR 결과로 나온 lexical(어휘) 정보를 Speaker Diarization system 에 활용
- 큰 발전은 이룬 연구들
Diarization based on Linguistic feature
- input으로 ASR의 output(linguistic feature)과 speech frame 별로 추출한 feature (acoustic feature, mel spectrogram)를 함께 사용하여 output으로 화자 label sequnece를 추출함 (T,K)
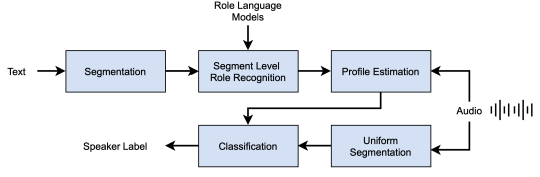
- speaker change detector, text based recognizer 두 가지 모델링 수행
Integrating lexical & acoustic for Diarization
- ASR의 output(linguistic feature)을 clustering에 통합
- 유사도 Matrix를 사용하여 통합
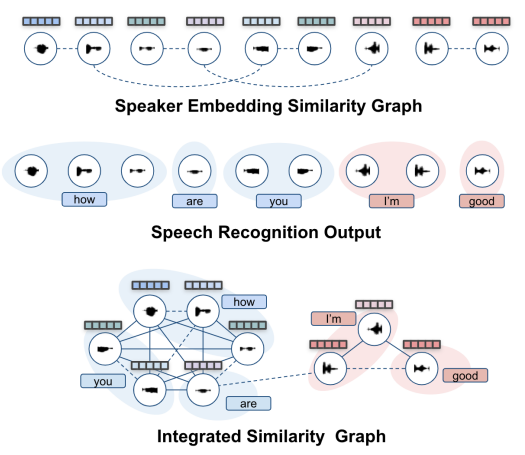
Process
- Speech -> Acoustic Feature (N,F) -> 유사도행렬 (N,N)
- ASR output linguistic feature (N,T,F) -> 유사도행렬 (N,N)
- 최대값 기반 유사도행렬 통합 : U[i, j] = max(S_acoustic[i, j], S_lexical[i, j])
- Clustering : (N,N) -> (N,)
Integrated system: ASR + Diarization
- ASR과 Diarization 을 동시에 공동으로 수행하는 내용 (End-to-End)
1. ASR system with Speaker Tag
RNN-T(2019)
- 화자 태그를 삽입하여 음성인식 수행
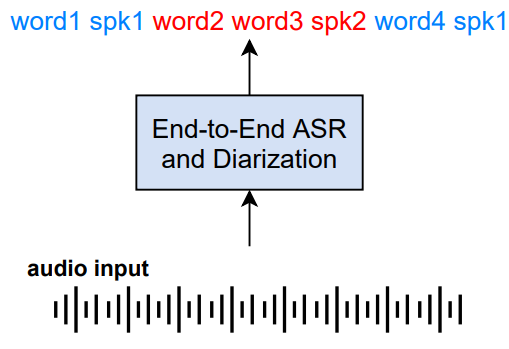
한계
- 화자 label을 학습 시 고정시켜야 함 -> 중첩 화자 처리 힘듬
2. MAP based Integration
- Maximum A Posteriori 방법으로 ASR과 Diarization 통합
(2020)
- 각 segment에서 ASR과 Speaker Embedding을 반복적으로 수행하여 최적화하여 최종 결과 도출
3. End-to-End ASR (SA-ASR)
- 화자수 계산, 다화자ASR, 화자 식별 공동 수행
- 다수의 화자가 동시에 발화하면 각 화자가 말한 내용을 인식하고, 이를 각각의 화자에게 할당하는 방향성
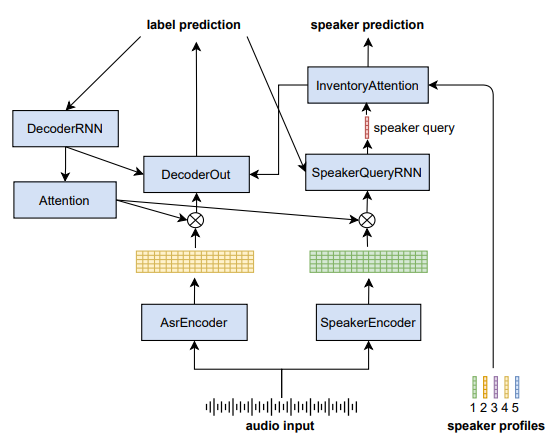
process
- input: acoustic feature (T,F), speaker embedding (K,D)
- 각 frame별 acoustic feature, 각 화자 벡터(x-vector)
- output: 음성인식 결과 - (N,), speaker recognition output (N,)
- 출력 Sequence를 의미하며, 음성인식 결과에는 Sequence 내부 Text token들이 들어있고, Recognition output은 Sequence 내부 화자 label 값 token들이 들어있음
- e.g) ASR Output: [H,E,L,L,O], Recognition Output: [1,2,2,1,1]
example code
class TransformerASR(nn.Module):
def __init__(self, input_dim, hidden_dim, num_heads, num_layers, vocab_size, num_speakers):
super(TransformerASR, self).__init__()
# Embedding layers
self.audio_embedding = nn.Linear(input_dim, hidden_dim)
self.speaker_embedding = nn.Linear(num_speakers, hidden_dim)
# Positional Encoding
self.positional_encoding = nn.Parameter(torch.zeros(1, 1000, hidden_dim)) # Assume max length 1000
# Transformer Encoder
self.encoder_layer = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=num_heads)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
# Transformer Decoder for ASR
self.decoder_layer = nn.TransformerDecoderLayer(d_model=hidden_dim, nhead=num_heads)
self.transformer_decoder = nn.TransformerDecoder(self.decoder_layer, num_layers=num_layers)
# Output layers
self.fc_text = nn.Linear(hidden_dim, vocab_size)
self.fc_speaker = nn.Linear(hidden_dim, num_speakers)
def forward(self, audio_input, speaker_profiles, tgt_mask=None):
# audio_input: (batch_size, time_steps, input_dim)
# speaker_profiles: (batch_size, num_speakers, speaker_dim)
# Embedding the input
audio_embedded = self.audio_embedding(audio_input) + self.positional_encoding[:, :audio_input.size(1), :]
speaker_embedded = self.speaker_embedding(speaker_profiles).mean(dim=1, keepdim=True) # Mean across speakers
# Encode the audio
memory = self.transformer_encoder(audio_embedded.transpose(0, 1)) # (time_steps, batch_size, hidden_dim)
# Decode using the memory from encoder
tgt = audio_embedded.transpose(0, 1) # Using the same embedded audio as initial target input
output = self.transformer_decoder(tgt, memory, tgt_mask=tgt_mask) # (time_steps, batch_size, hidden_dim)
# Predict the text
text_output = self.fc_text(output) # (time_steps, batch_size, vocab_size)
# Predict the speaker for each token
speaker_output = self.fc_speaker(output) # (time_steps, batch_size, num_speakers)
return text_output.transpose(0, 1), speaker_output.transpose(0, 1)
# Hyperparameters
input_dim = 128 # Dimension of input features (e.g., mel-spectrogram)
hidden_dim = 256 # Hidden dimension size
num_heads = 8 # Number of attention heads
num_layers = 4 # Number of Transformer layers
vocab_size = 30 # Vocabulary size (number of possible output tokens)
num_speakers = 10 # Number of speakers in the system
# Example inputs
batch_size = 2
time_steps = 100
speaker_dim = 128
audio_input = torch.randn(batch_size, time_steps, input_dim) # Example audio features
speaker_profiles = torch.randn(batch_size, num_speakers, speaker_dim) # Example speaker embeddings
# Initialize the model
model = TransformerASR(input_dim, hidden_dim, num_heads, num_layers, vocab_size, num_speakers)
# Forward pass
text_output, speaker_output = model(audio_input, speaker_profiles)5. Evaluation Dataset
- Speaker Diarization 평가에 사용되는 방법과 일반적으로 사용되는 데이터셋을 설명
- 영어 데이터를 이용한 General하게 사용되는 데이터셋
CALLHOME: NIST SRE 2000
- 최신 논문에서 Speaker Diarization Taks에 가장 많이 사용되는 데이터셋
- 500개의 다국어 전화 통화 세션이 포함되며, 각 세션은 2~7명의 화자가 존재
AMI Corpus
- 여러 장소에서 171개의 회의 세션에서 기록된 100시간 분량의 회의 녹음
- 음성 인식 모듈(Traditional System)과 Integrated System 평가에 적합하며, 각 회의 세션은 3~5명의 화자 존재
ICSI Meeting Corpus
- 75개의 회의 기록을 포함하며, 4가지 유형의 회의 존재
- 대화마다 단어 수준의 time, transcript, speaker label을 제공
- 총 6개의 마이크로 기록되어 화자별 채널 및 다중 채널 녹음 제공
- 각 회의에는 3~10명 존재
CHiME-5/6 Challenge Dataset
- 일상 가정 환경의 대화, 50시간 오디오
- label, segmentation, transcript 가 포함되며 화자는 4명
- 총 6개의 4채널 마이크로폰 사용됨
VoxConverse Dataset
- DER이 주요 지표, JER이 보조 지표로 사용됨
- 74시간 분량의 대화 데이터이며, YouTube에서 추출됨
- Train Set: 20.3h, 216개 녹음
- Test Set: 53.5h, 310개 녹음
- 화자 수는 1~21명
- 오디오에는 배경음악, 웃음소리 등 다양한 유형의 noise가 포함되어있음
- 0%~30.1%까지의 중첩된 음성이 존재
LibriCSS
- 10시간 분량의 다채널 녹음
- LibriSpeech의 오디오를 실제 회의실에서 재생하고, 7채널 마이크로폰으로 녹음됨
- 10개 세션으로 구성되며, 각 세션은 6개의 10분짜리 미니 세션으로 나뉨
- 각 미니 세션은 8명의 화자가 참여하며, 0%~40%까지의 중첩 비율 가짐
ETC
- Corpus of Spontaneous Japanese - 12시간 분량의 2명의 화자 간 대화
- AISHELL-4 - 118시간 분량의 중국어 회의 시나리오
