Speech Processing Tasks
음성 처리 분야에는 다양한 분야가 있음.
ASR
- STT라고도 불리며, 이는 Speech to Text 과정임
- Waveform(Raw signal) -> Acoustic Feature(mel-spectrogram) -> Linguistic Feature(P2G Modeling) -> text 의 process를 거친다.
TTS
- ASR 과정의 역순이며, 이는 Text to Speech 과정임
- Text -> Linguistic Feature(G2P Modeling) -> Acoustic Feature(mel-spectrogram) -> Vocoder -> Waveform 의 process를 거친다.
용어 정리
Waveform
- 말하면 나오는 Raw Signal
- Waveform은 Linguistic Feature, Acoustic Feature로 구분할 수 있음. (하지만 어려움)
Acoustic Feature
- 음향 특징을 의미.
- Mel-Spectrogram이 Acoustic Feature임.
- 음향 특징에는 화자 정보도 포함되어 있음.
- 신호를 주파수 영역대에서 분석(푸리에 변환)하여 각 시간대별, 각 주파수 대역별 세기 분석 가능
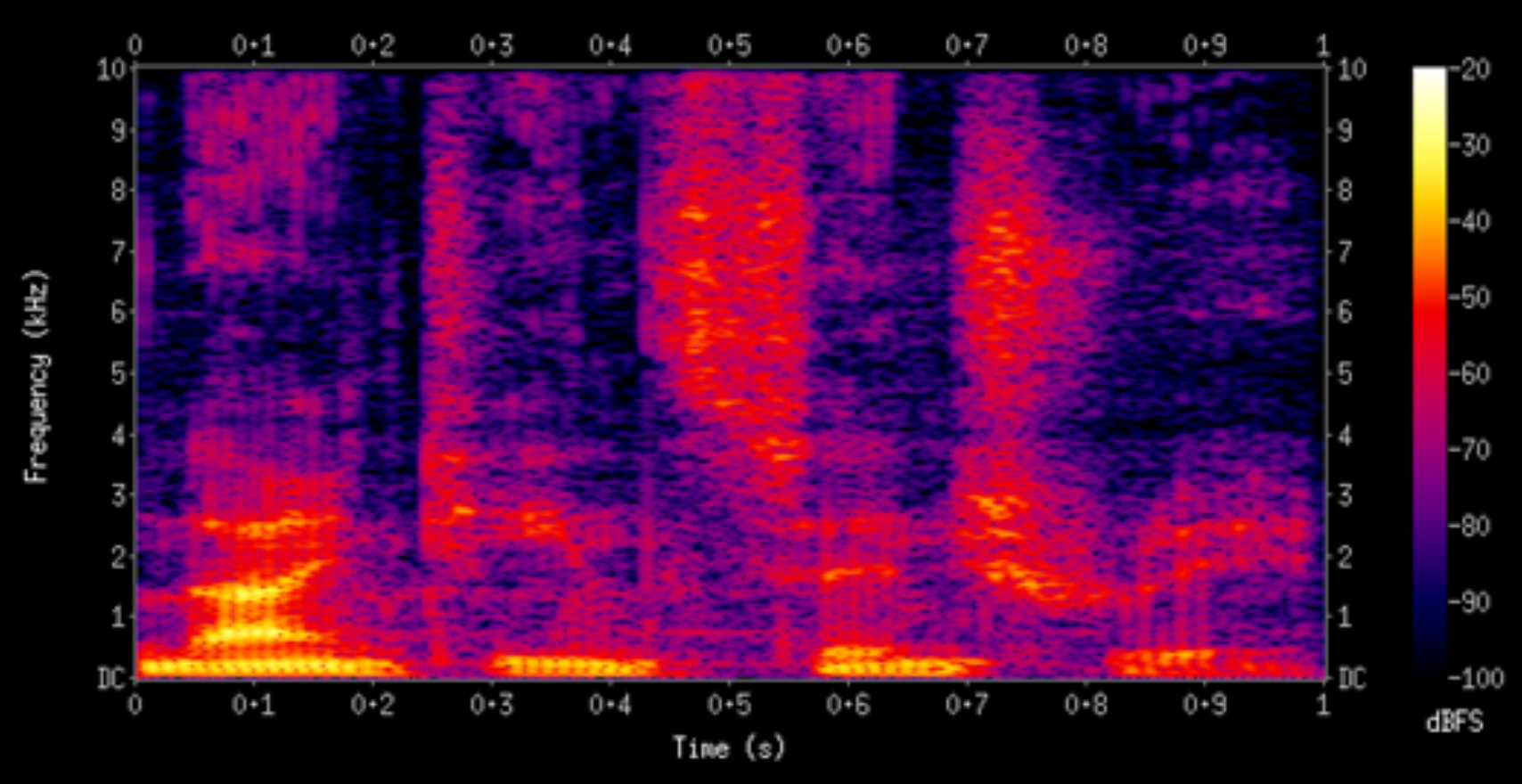
- 가로축은 시간대별, 세로축은 주파수 대역별, 색깔은 강도(Amplitude) 의미.
Linguistic Feature
- 언어적 특징을 의미.
- 발음정보(Phonemes), 언어정보(Graphemes) 등이 음소 특징임.
Phonemes
- 가장 작은 단위의 음성 발음기호 (음소)
- 발음정보
Graphmes
- 가장 작은 단위의 문자 또는 문자의 집합 (문자소)
- 언어정보
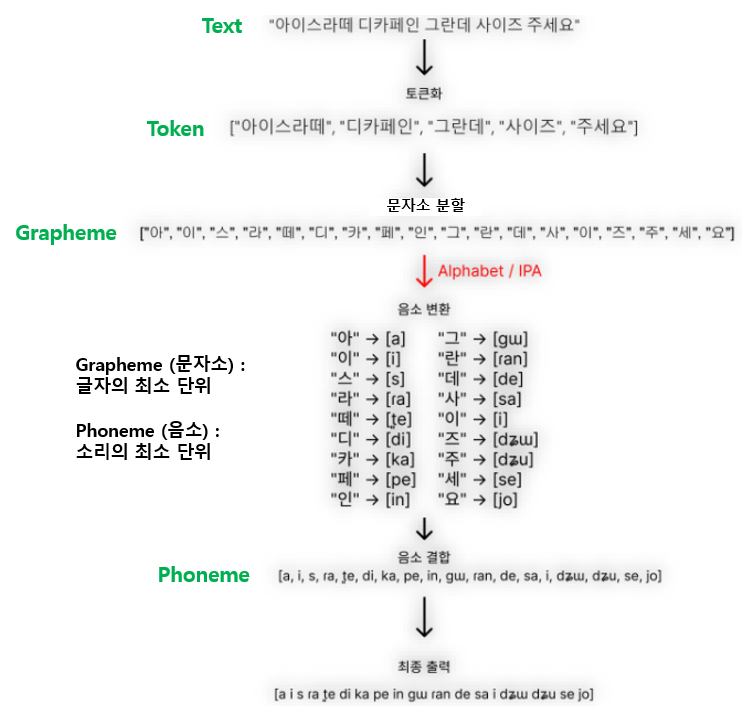
발전 과정
TTS
딥러닝 발전 이전 Process

- Text(Grpaphmes) 로부터 Linguistic Features(Phonemes) 를 추출하고, 이를 음향 모델에 넣어 Acoustic Features(Mel-Spectrogram)를 획득한 후, 이를 Vocoder에 넣어 Waveform으로 변환.
LLM 등장 이전까지의 Process

- Text로부터 바로 Acoustic Features(Mel-Spectrogram)을 추출한후, 이를 Vocoder에 넣어 Waveform으로 변환.
LLM 등장 이후 현재까지의 Process

- Text로부터 Mel-Spectrogram 과 Vocoder 없이 바로 Waveform 생성.
정리
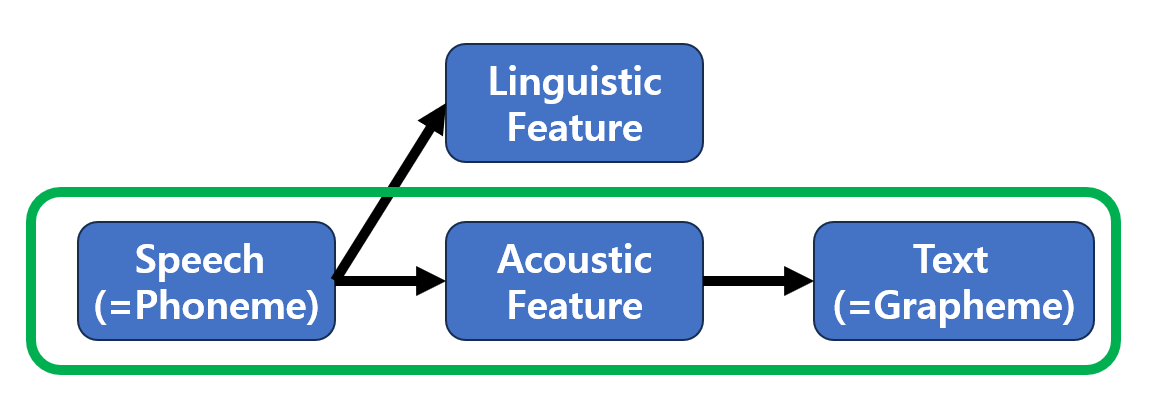
- 녹색 박스친 부분이 ASR(=STT) 과정이며, TTS는 이 역순이라고 보면 된다.
- SOTA 모델인 OpenAI Whisper의 경우, Acoustic Feature(Mel)에서 Text로 만드는 과정에서 text를 직접 cross-attention으로 명시적으로 음향 Feature에 넣어준다.

고려대학교 인공지능학과 SLP Lab 석사과정생