DINOv2: Learning Robust Visual Features without Supervision
- 목적 : Self-Supervised Learning -> Representation을 잘 뽑는 범용적인 모델 생성
1. Introduction
Backgroud
- Text에서의 pretraining은 성공적이였으며, vision에서도 ssl을 이용한 많은 pretraining 방법론들이 제안되고 있음
Related Works
- Text-Supervised
- ex) CLIP : text-image 쌍으로 학습 / (한계) : 텍스트는 이미지의 풍부한 정보를 다 담기 어렵고, 픽셀 수준 정보는 거의 학습되지 않음.
- Self Supervised Learning (SSL)
- ex) DINO, iBOT, BYOL, SimCLR 등 / (한계) : 대부분 작은 크기의 정제된 데이터셋으로 학습하여 범용성 부족
- Limitations : 비정제 데이터에 대해 학습시 성능저하 심했으며, 이는 데이터 품질과 다양성 부족이 원인
DINOv2
- 대규모 정제된 데이터셋 구축
- 새로운 SSL Algorithm 제안 (DINO + IBOT + SwAV)
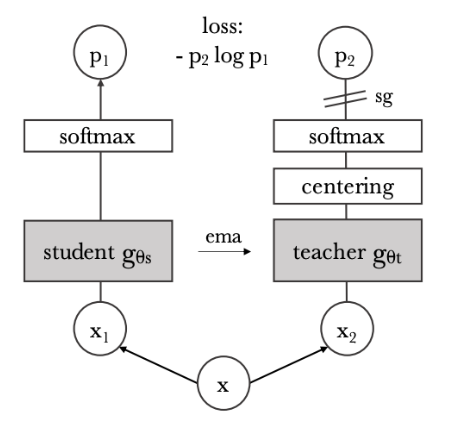
DINO
- label 없이 teacher가 student로부터 생성되는 구조에서, soft target을 활용하여 스스로 distillation 하는 구조
- Multi-View Distillation 개념 활용
- EMA (Exponential Moving Average) 개념을 활용하여 teacher를 update
- DINO에서는 soft target으로 VIT의 class token을 활용했었음
IBOT
- VIT의 Class token이 아닌 Patch-Level token에서 softmax로 soft target을 생성해서 Distillation을 수행
- Masked View를 활용
SWAV
- Prototype based Clustering, Sinkhorn Knopp Algorithm 사용
2. Method
DINO + SWAV
- Self-Distillation with NO labels 의 약자로, label 없이 teacher가 student로부터 만들어지는 구조
- 하나의 image에 대해서 2개의 global view와 6개의 local view 생성
- Teacher는 global view만 보며, student는 자기 자신을 제외한 global view 1개와 6개의 local view, 총 7개의 view를 봄
- trainable한 prototype(=cluster의 centroid)에 representation을 균등하게 할당하는 SinkHorn Knopp 알고리즘 활용
- softmax는 각 prototype에 대한 확률을 의미
Process
- teacher : img1로 vit encoder, projection을 통과하여 representation을 얻은 뒤, representation들과 prototypes들을 내적한 행렬을 획득한 뒤, 그 행렬에 대해 sinkhorn알고리즘을 통해 reprsentation 들이 균등한 prototype에 할당되도록 내적 행렬을 조정하고, softmax값을 구해서 soft target 생성. Teacher network는 학습하지 않음
- student : img2로 vit encoder, projection을 하고, softmax를 통해서 soft prediction 생성. Student network는 학습함
- Loss : soft prediction이 soft target을 따라가도록 cross entropy로 학습.
- EMA Update : Student의 vit encoder weight를 teacher의 vit encoder weight에 ema 로 update 수행.
- DINO Loss : 1~4 과정은 img1, img2 하나의 pair에 대한 process. 자기 자신 global view를 제외한 총 7개 view pair를 만들어서 Cross entropy loss들을 7개를 평균내서 최종 dino loss 생성됨
Sinkhorn Knopp Algorithm
Representation과 Prototype들을 내적한 Score matrix에 적용하는 normalization으로, 각 prototype에 균등한 개수의 representation들이 할당되게 함으로써, 학습에 모든 prototype이 고르게 사용되도록 유도
IBOT
- VIT output의 각 patch에 대해 random masking 수행하여, Masked patch prediction task를 푸는 MSE Loss Term 구성
DINOv2 Loss (DINO + SWAV + IBOT)
- 최종 Loss Term은 MSE(Masked Patch Prediction) + CE(teacher-student간 Prototype Assignment)

고려대학교 인공지능학과 SLP Lab 석사과정생