SimCSE: Simple Contrastive Learning of Sentence Embeddings
- 목적 : contrastive learning을 접목하여 문장 임베딩을 잘 추출하는 모델 개발
1. Introduction
Background
- (문장 임베딩 추출의 중요성) MT, QA, Retrieval, Text Classification 등 대부분의 NLP task는 문장의 의미를 이해하는 것에서 시작하기에, 문장 임베딩을 잘 추출하는 것은 아주 중요한 task임
- (기존 문장 임베딩 방법의 한계) 문장 임베딩 추출로 널리 이용되는 모델인 BERT/RoBERTa 의 경우에는 여러 한계가 존재
- Anisotropy 문제
임베딩들이 고차원의 latent space에서 특정 공간에 밀집되어, 모든 문장들간 구분력이 부족해지게 되고, 이는 상관 없는 문장끼리도 높은 similarity가 출력되는 결과로 이어짐Anisotropy 문제 발생의 증거
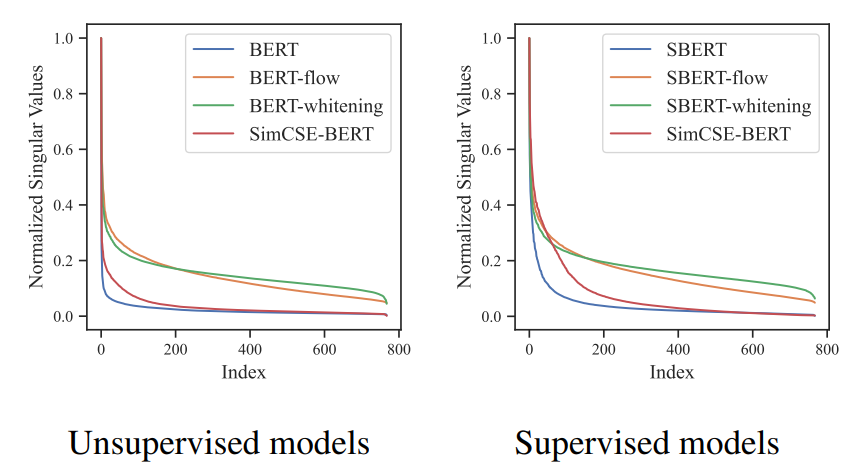
singular value들고 bert(파랑선)와 제안 모델(빨간선)을 비교했을 때, bert의 경우 총 768dim을 가진 latent space에서 처음 몇개(10~20개 dim)만 1에 가까운 큰 값을 갖고, 나머지는 0값을 가짐. 이는 대부분의 차원이 쓸모 없고 문장이 소수 차원으로만 표현된다는 의미. 최대 1로 normalize 했다는 것은, 단위가 1인 768공간에다가 embedding을 mapping 시켰다는 의미이며, 시각화를 위해 3차원 구로 보았을 때,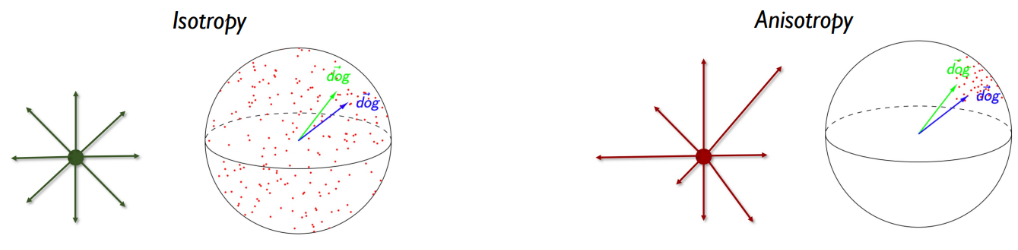
좌측이 제안 모델의 임베딩 분포, 우측이 BERT의 임베딩 분포라고 볼 수 있음 - 학습 목적의 차이
BERT는 token level prediction을 목적으로 학습(MLM + NSP)되어 sentence level similarity는 고려하지 않고, [CLS] token prediction 을 위해 설계되었기 때문에 문장 전체 의미를 포착하지 못함
- Anisotropy 문제
Related Works
Contrastive Learning
-
(SimCLR) Unlabled data에 대해 서로 다른 종류의 augmentation을 먹여서 두 data가 가까워지고, batch내 다른 sample들에 대해 멀어지게끔 학습
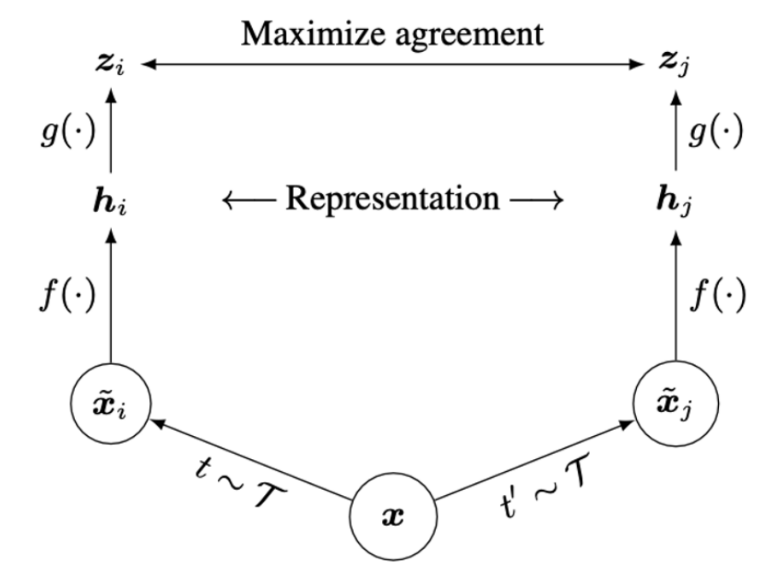
-
(Limitation) Discrete하다는 text의 특성 때문에 Augmentation이 어려웠음. 기존에는 word level에서 변형을 주는 방법으로 augmentation 했었는데, 성능 저하를 초래했음. positive pair 구성이 불명확
문장 임베딩 모델
- (SBERT) NLI dataset (문장1, 문장2, 긍정/부정/중립 label) 에 대해서 문장1, 문장2를 각각 bert encoder에 태워서 얻은 emb1, emb2 와 |emb1-emb2| 를 feautre로 삼아 bert classifier가 label을 맞추도록 학습
- (Limitation) Anisotropy 문제 (앞서 설명함)
Post Processing Method
- (BERT-Flow) BERT를 froze하고, flow model을 학습시켜 Anisotropy Distribution을 띄던 embedding들을 isotropic Distribution으로 mapping
- (BERT-Whitening) embedding의 모든 차원의 분산을 1로 만들어서 차원 간 상관관계를 제거하여 더 uniform한 분포로 만들어줌 (svd로 whitening matirx를 추출해서, 원래 임베딩에 whitening matrix 내적해주는 방식)
2. Method
- Dropout을 data augmentation으로 활용
Process
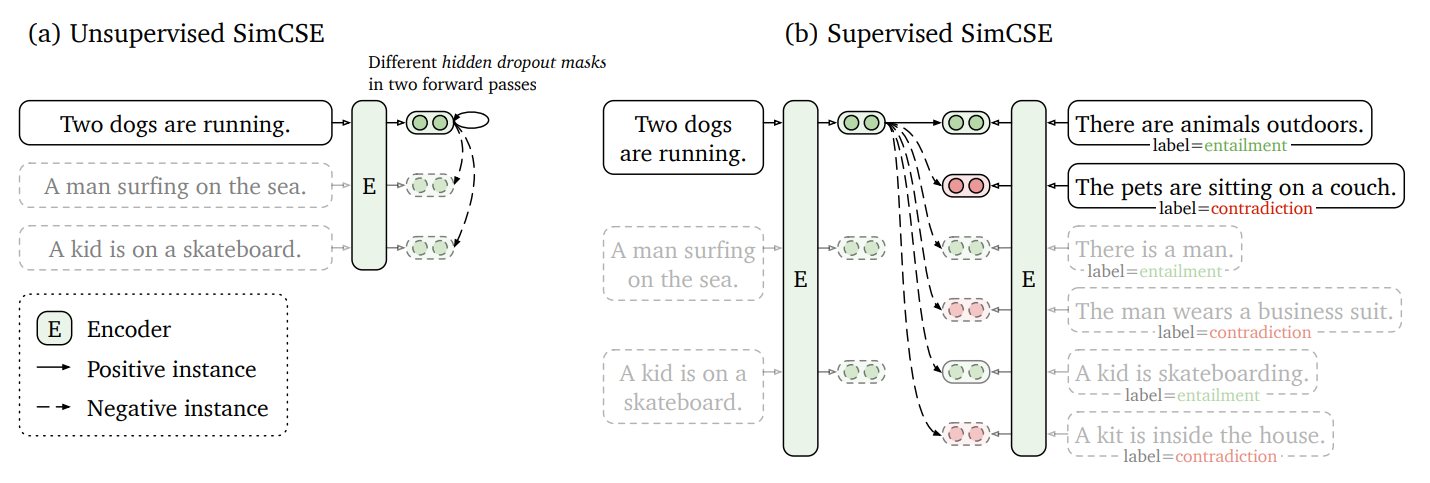
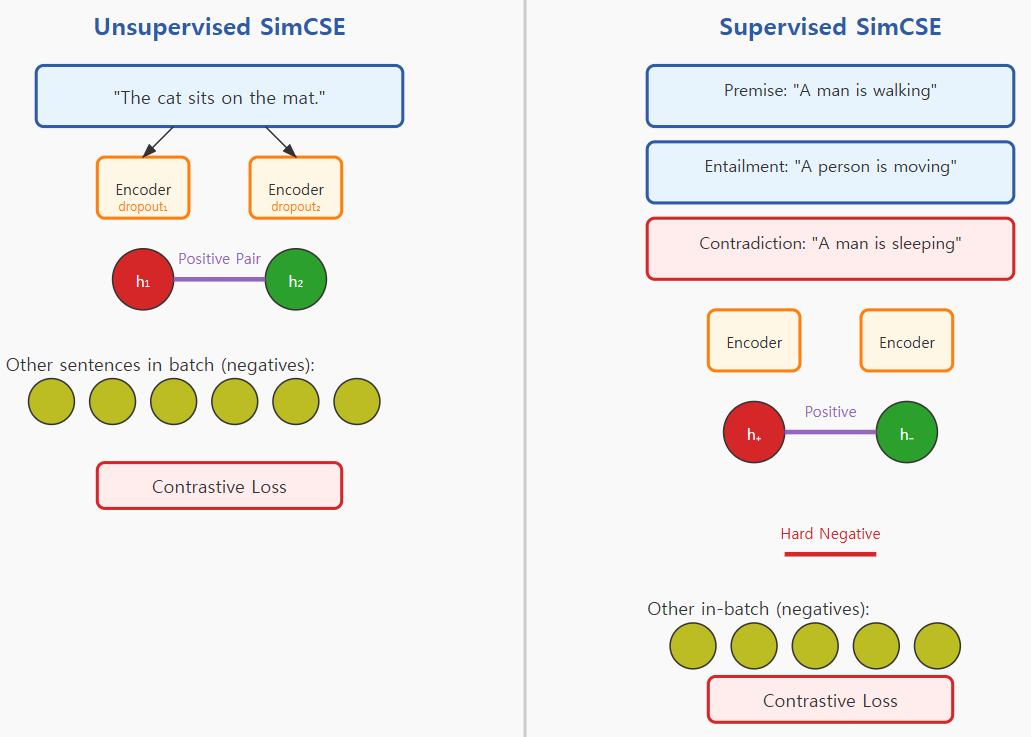
- (Unsupervised Contrastive Learning) 같은 문장을 같은 모델(BERT/RoBERTa)에 두번 통과시켜 각각 다른 dropout mask를 입혀서 생긴 다른 두 임베딩을 positive pair로 활용하여 contrastive learning 진행
- (Supervised Contrastive Learning) NLI 데이터의 entailment pair를 positive로, contradiction pair를 hard negative로 삼고, batch 내 다른 sample들은 nagative로 삼아서 hard negative와 negative를 합쳐서 최종 negative sample들로 활용하여 contrastive learning 진행

고려대학교 인공지능학과 SLP Lab 석사과정생