LaCo: Large Language Model Pruning via Layer Collapse
1. Background
최근 연구 동향
- LLM은 계속해서 모델 크기 확장으로 발전하고 있음
- 이에 비용 문제 해결을 위한 다양한 연구가 진행되고 있음.
경량화 방법과 한계
Quantization
- 모델의 Weight를 낮은 정밀도의 소수점 또는 정수 표현으로 변환하여 모델 크기를 줄임
- e.g) SmoothQuant, GPTQ, QLoRA, OmniQuant 등
- 성능 저하가 심하다는 한계
- 특정 하드웨어에서만 작용한다는 한계
Knowledge Distillation
- 큰 모델의 지식을 작은 모델로 주입.
- 작은 모델 훈련하는데 많은 비용 소모
Pruning
- 모델 Parameter를 Sparse하게 만들거나 제거
- 모델 Layer를 drop하는 Structed, Weight를 Sparse하게 만들어주는 Non-Structed 로 구분
- e.g) SparseGPT, spQR, LLM-Pruner, ShearedLLaMA 등
- Non-Structed 의 경우 성능 저하가 심함
Layer Collapse (LaCo) 방법 제안
- 모델의 뒤쪽 layer를 앞의 layer에 병합하여 모델 크기 감소, 모델 구조 유지
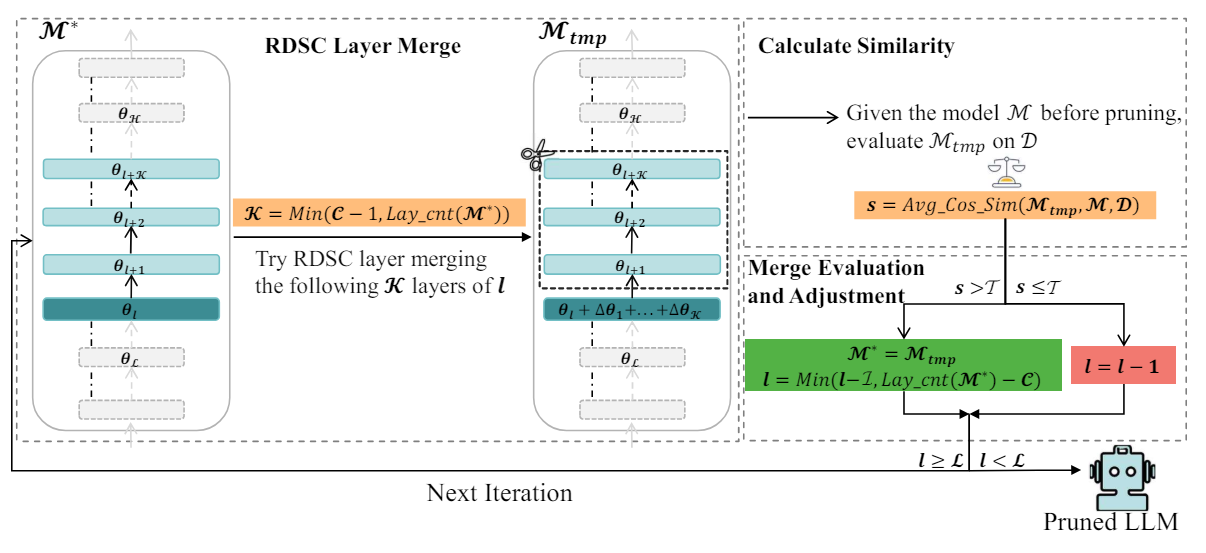
2. Method (LaCo)
Reserving-Differences-while-SeekingCommon Layer Merge (RDSC)
- 여러 Layer의 파라미터를 합치는 알고리즘
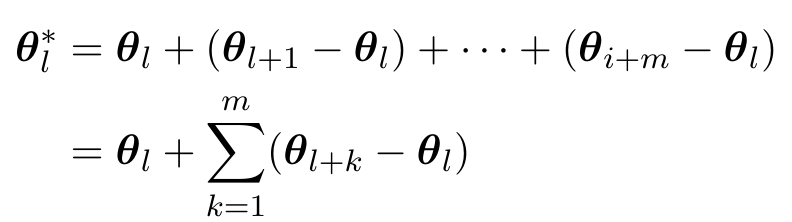
- θl* : updated된 weight
- m : 연속된 m개 layer
- (θl+k - θl) : l번째 layer와 범위 내 연속된 다른 layer들 간 파라미터 차이
예시
- 3,4,5층 3개 layer 병합하는 경우
- θ*3 = θ3 + (θ4 - θ3) + (θ5 - θ3)
- θ4,θ5는 폐기
Layer Collapse
- 위의 알고리즘을 사용하여 전체 모델에 적용하며 모델 경량화 수행하는 전체적인 방법

- M : Pruning 시킬 backbone 모델
- C : 병합할 layer 개수
- [L, H] : 고려할 Layer 범위
- L : 병합된 layer 사이의 간격(layer)
- D : Calibration Data Sample
- T : representation 들간 유사도 임계값(temperature)
수도코드 해석
- 원본 모델 M을 M*로 초기화
- layer pointer l을 H-C 로 정의하고, 포인터 l이 축소할 최소 범위 L에 도달할때까지 Pruning 과정을 반복해서 수행
- RDSC 알고리즘으로 Layer를 병합하고, 합친 layer들은 제거하여 축소된 모델 Mtmp 획득
- 원본 모델 M 과 축소된 모델 M* 에 각각 D를 넣어 나온 두 representation들의 유사도를 계산하여 유사도 s를 구함.
- 유사도 s가 임계값 T보다 크면 병합이 성공적으로 이루어진 것으로 판단하고 Mtmp를 M* 로 업데이트하며, 포인터 l을 L개의 layer만큼 줄임. 만약 s가 T보다 작거나 같다면, 병합을 진행하지 않을 것이고, 포인터 l을 1개만큼 감소시켜 다음 layer에서 RDSC 감소를 진행하게끔 함.
- 계속해서 RDSC 알고리즘을 사용하여 pruning 수행
- 포인터 l이 축소할 최소 범위 L에 도달하면 pruning 종료
예시
- 총 모델 layer 수 M : 24
- 병합할 layer 수 C : 3
- 고려할 layer 범위 [L, H] : 3~24
- 두 병합 layer 사이 간격 : 5
- 초기화 과정
M* = M
l = 24 - 3 = 21 - RDSC를 이용한 병합 과정
<1차병합 l=21>
병합할 layer : 21,22,23
Δθ22 = θ22 - θ21
Δθ23 = θ23 - θ21
update layer weight : θ21 = θ21 + Δθ22 + Δθ23
새로운 layer 수 : 24 - 2 = 22
포인터 l update : l = 21 - 5 = 16
<2차병합>
병합할 layer : 16, 17, 18
update layer weight : θ16 = θ16 + Δθ17 + Δθ18
새로운 layer 수 : 22 - 2 = 20
포인터 l update : l = 16 - 5 = 11
<3차병합>
병합할 layer : 11, 12, 13
update layer weight : θ11 = θ11 + Δθ12 + Δθ13
새로운 layer 수 : 20 - 2 = 18
포인터 l update : l = 11 - 5 = 6
<4차병합>
병합할 layer : 6, 7, 8
update layer weight : θ6 = θ6 + Δθ7 + Δθ8
새로운 layer 수 : 18 - 2 = 16
포인터 l update : l = 6 - 5 = 1 - 병합 종료
l=1 이 되어 고려할 layer 범위 3~24에 속하지 않으므로, 병합 종료
예시 요약
layer를 3개씩 병합하고, 병합 간격을 5개로 두어, 총 4번의 병합을 통해 24개 layer가 16개 layer로 감소함.
3. Experimental Setup
Model
- 영어 성능 평가를 위해 LLaMA2 7B, 13B
- 중국어 성능 평가를 위해 BaiChuan2 7B, 13B 사용
Benchmark
- OpenCompass evaluation framework 사용
- 해당 framework는 5가지 측면에서 평가 수행
- 추론(Reasoning), 언어(Language), 지식(Knowledge), 시험(Examination), 이해(Understanding)
Baseline
- LaCo는 Structed Pruning 방법임.
- 최신 Structed Pruning Method 중 LLM-Pruner, SparseGPT를 뛰어넘은 SliceGPT 를 사용
- Dense는 OpenCompass 리더보드의 official result, Dense*은 재현 결과
4. Result
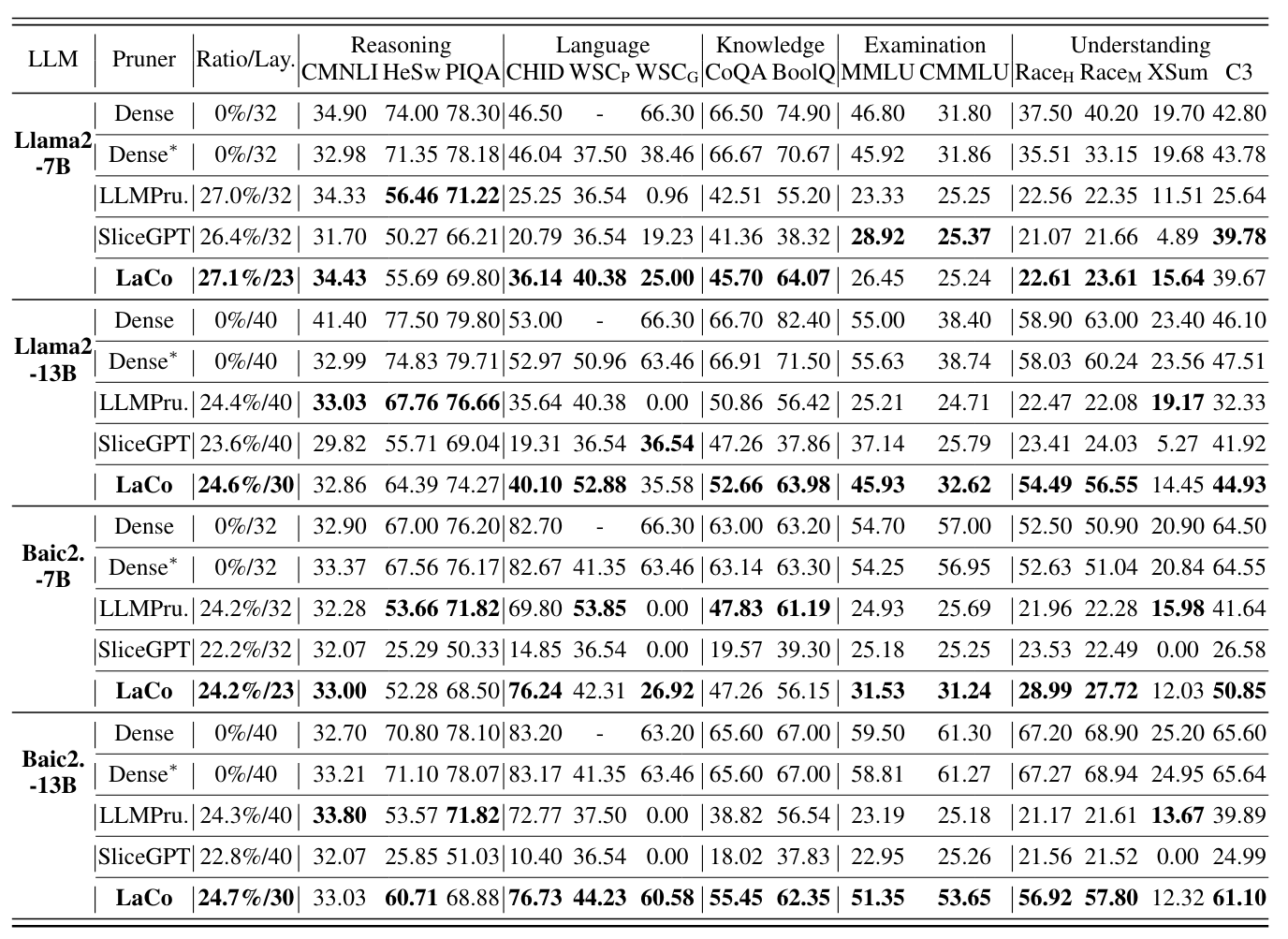
-
다양한 벤치마크에서 서로 다른 가지치기 방법을 적용한 네 가지 LLM의 결과
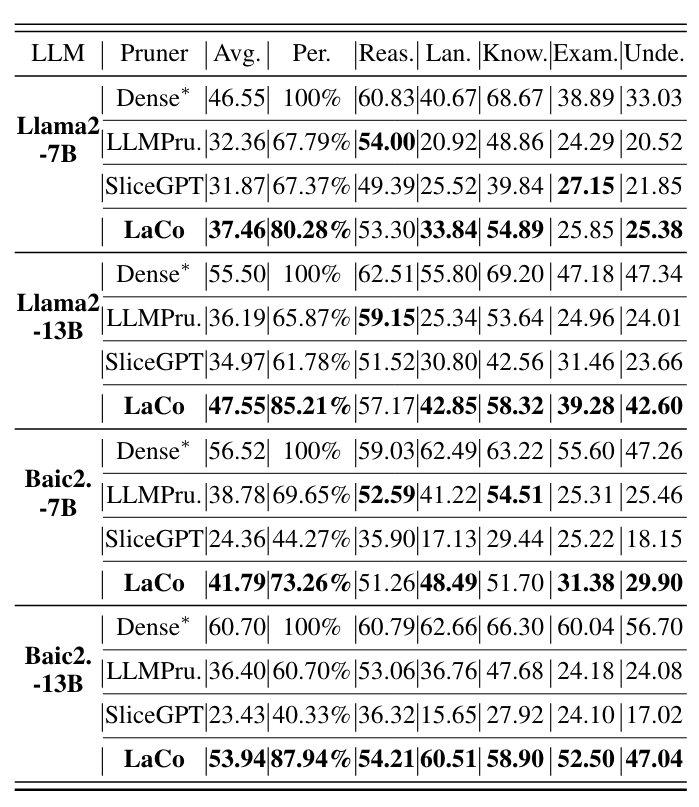
-
각 측면에서의 평균 성능 결과
-
공식 성능(Dense)과 재현 성능(Dense*)을 비교했을 때 차이 5% 이내 -> 실험에 오류 없음
-
LaCo 가 대부분의 조건에서 Sota 달성
-
LaCo로 가지치기된 모델은 대부분의 벤치마크에서 70% 이상의 성능을 유지함으로써 Baseline 대비 안정성이 뛰어남
5. Analysis
Post Training & Re-Pruning
- LaCo로 Pruning된 모델에 손실을 학습(Post Train)하고 그 모델에 다시 Pruning을 수행한 결과
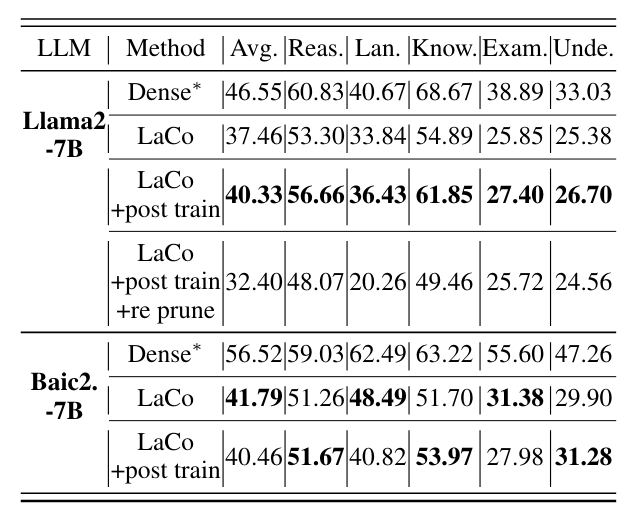
- post train을 수행하여 pruning loss를 학습하였을 경우 Llama2에서는 성능을 회복하였음
- post train 후 pruning을 수행하는 경우 원본 모델의 약 55%의 parameter만 사용함에도, 원본 성능의 70%를 유지하고 있음
Layer-Wise Similarity
- 어째서 인접한 layer들을 병합하는 아이디어를 제안하였는지에 대한 결과
- LLM의 인접 layer들간의 weight와 output representation들의 변화가 크지 않기 때문임.
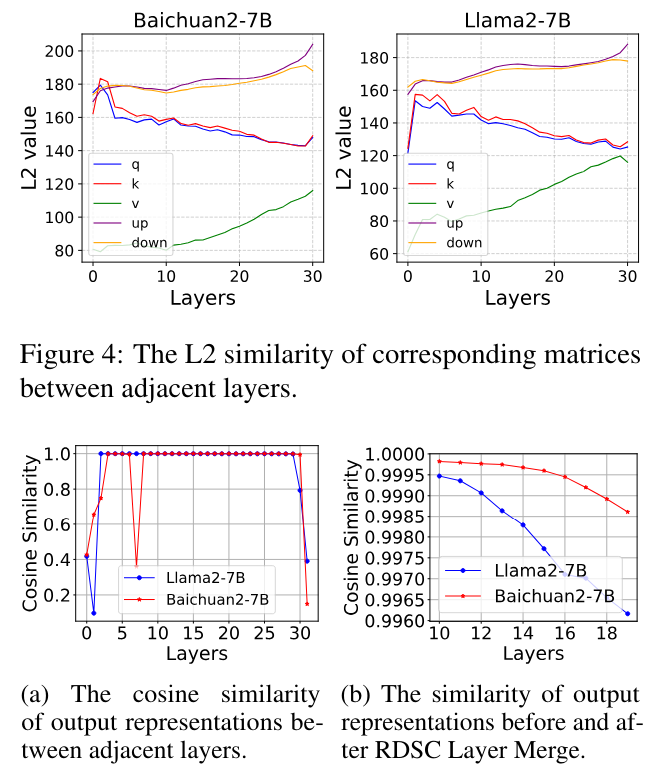
- 그림4에서 Weight의 분포가 인접 layer들에서 비슷함(L2 Sim)
- 그림5(a) 에서 인접 representation 의 similarity가 1에 가까움
- 그림5(b) 는 병합된 layer들과 마지막 layer 의 representation 간의 cos sim인데, 유사도가 거의 1임. 즉, RDSC방법이 representation을 유지하는데 효과적임을 보임.
6. Conclusion
Summary
- 후방 모델 레이어를 이전 레이어로 병합하여, 모델 크기를 빠르게 줄이면서도 모델 구조를 유지하는 방법인 LaCo 제안
- 25-30%의 가지치기 비율에서도 평균 성능을 80% 이상 유지함으로써, 기존 sota 구조적 가지치기 방법을 능가하였음
- 후처리 훈련 실험을 통해 LaCo가 최소한의 훈련으로 원래 모델의 Weight에 근사하게 복원할 수 있음을 확인
Limitaion
- Transformer 구조에서만 실험 진행
- RDSC의 파라미터에 크게 의존함

고려대학교 인공지능학과 SLP Lab 석사과정생