Why Lift so Heavy? Slimming Large Language Models by Cutting Off the Layers

1. Background
기존 연구 방향성
- 현재 LLM은 성능 향상을 위해 layer를 깊고 복잡하게 만드는 방향으로 발전하고 있음 (Layer Stacking)
- e.g) GPT-2 XL은 48개, Llama2는 32개의 transformer decoder layer를 쌓음
Layer Stacking의 한계
- 모델 파라미터 대폭 증가
- 높은 학습 비용
PEFT의 한계
- LLM의 높은 학습 비용 문제를 해결하기 위한 목적
- LLM의 파라미터 freeze 또는 apaptor 모듈 추가하여 학습시키는 다양한 연구
- 장점) 학습 비용 절감, 성능 향상에 성공
- 단점) 모델 크기 자체는 줄지 않음. -> 저장, 추론에 큰 자원이 필요
Layer Pruning 제안
- 모델 구조를 유지하면서 모델 Layer자체를 제거하여 모델 크기를 대폭 감소
2. Method
Layer Pruning
- top-layer removing 전략 사용
- 모델의 마지막 Layer부터 차례로 하나씩 제거하여 실험
- 모델 앞 N개의 Layer만 남기고 실험 진행
- 앞에서부터 1,2,12,24,48 개 layer만 남겼을 때의 성능 기록
3. Experimental Setting
- Classification 데이터셋에 대해서만 실험 진행
- prompt based ft(LM), classification head를 단 ft(P-CLS), 전통적인 classification ft(CLS) 3가지 방법으로 실험 진행.
Prompt based fine tuning
- 분류 데이터셋에서 텍스트, 레이블을 쌍으로 prompt로 만들어서 학습
- Self-Supervised Learning (SSL) 방법인 Next Token Prediction으로 학습
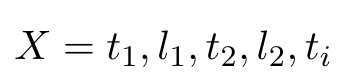
- t1은 text1, l1은 label1, t2는 text2, l2는 label2
- e.g) I am happy, positive, I am sad, negative, ...
- Result에서 LM으로 표기함 (denoted as LM)
Prompt based Classification head fine tuning
- 모델의 막단에 Classification head를 달아서 fine tuning 수행
- Supervised Fine Tuning 수행 (SFT)
- input은 t1,l1 쌍이 주어지며, label은 l1 이 됨.
- e.g) input : {I am happy, positive}, label : {positive}
- Result에서 P-CLS으로 표기함 (denoted as P-CLS)
Conventional Classification fine tuning
- 전통적인 분류 문제
- SFT 수행
- input은 t1, label은 l1
- e.g) input : {I am happy}, label : {positive}
- Result에서 CLS으로 표기함 (denoted as CLS)
Experimental Dataset
AGNews
- 뉴스 주제 분류 데이터셋
- label 4개
EmoContext (EmoC)
- 감정 분류 데이터셋
- label 4개
SST-2
- Stanford Sentiment Treebank Dataset
- label 2개
- 데이터셋 자세한 설명 https://velog.io/@hyunku/NLP-Evaluation-Metric
TREC
- 질문 유형 분류 데이터셋
- label 6개
4. Result
LM Training
- Prompt based fine tuning 결과에서 layer pruning 했을 경우 성능 비교
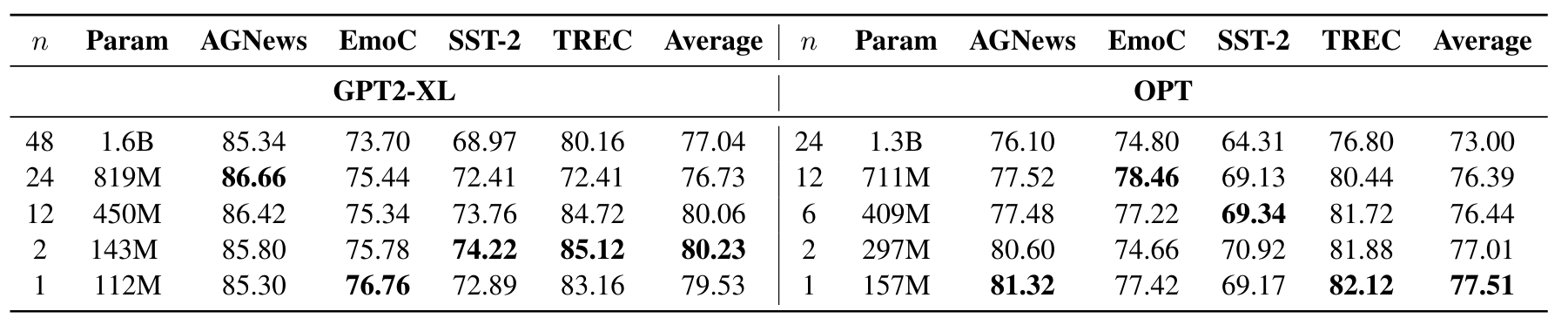
- 전반적으로 Layer Pruning 결과 성능 저하가 없음
- 오히려 앞에서 1~2개 Layer만 사용하는 것이 최고 성능을 기록함
- GPT2-XL 에서는 15억개 파라미터, OPT에서는 11억 4천만개 파라미터 절감
P-CLS Training
- Prompt based classification head fine tuning 결과에서 layer pruning 했을 경우 성능 비교
- LM Training 에서는 분류 문제를 Next Token Prediction으로 해결하였으므로, Layer Pruning 시 일관된 성능이 나오는 이유가 Next Token Prediction 에서 language modeling head(다음 토큰 예측 분포)로 인해서 유지되는 것인지 language modeling head에 대한 의존성 테스트를 위한 실험
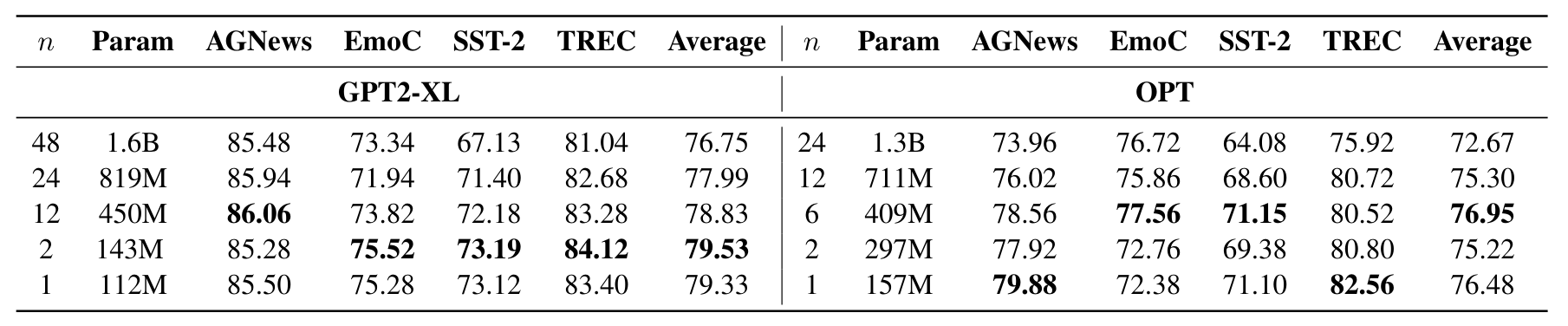
- Classification Layer를 추가해주는 경우에도 성능 저하로 이어지지 않고, 오히려 성능이 향상됨.
- Layer Pruning 이후 성능 유지가 Language Modeling Head에 의존하지 않음을 보임.
CLS Training
- Conventional Classification fine tuning 결과에서 layer pruning 했을 경우 성능 비교
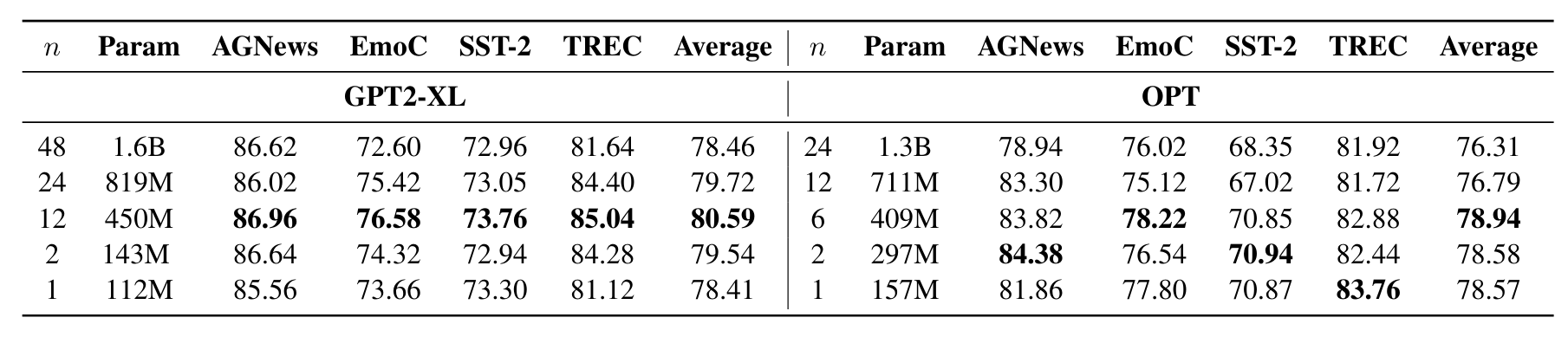
- Layer Pruning은 성능 감소에 큰 영향을 미치지 않음
- Layer Pruning 전후로 일관된 성능 기록
Comparision
- 3가지 방법의 Layer Pruning 시의 성능 결과의 평균을 비교
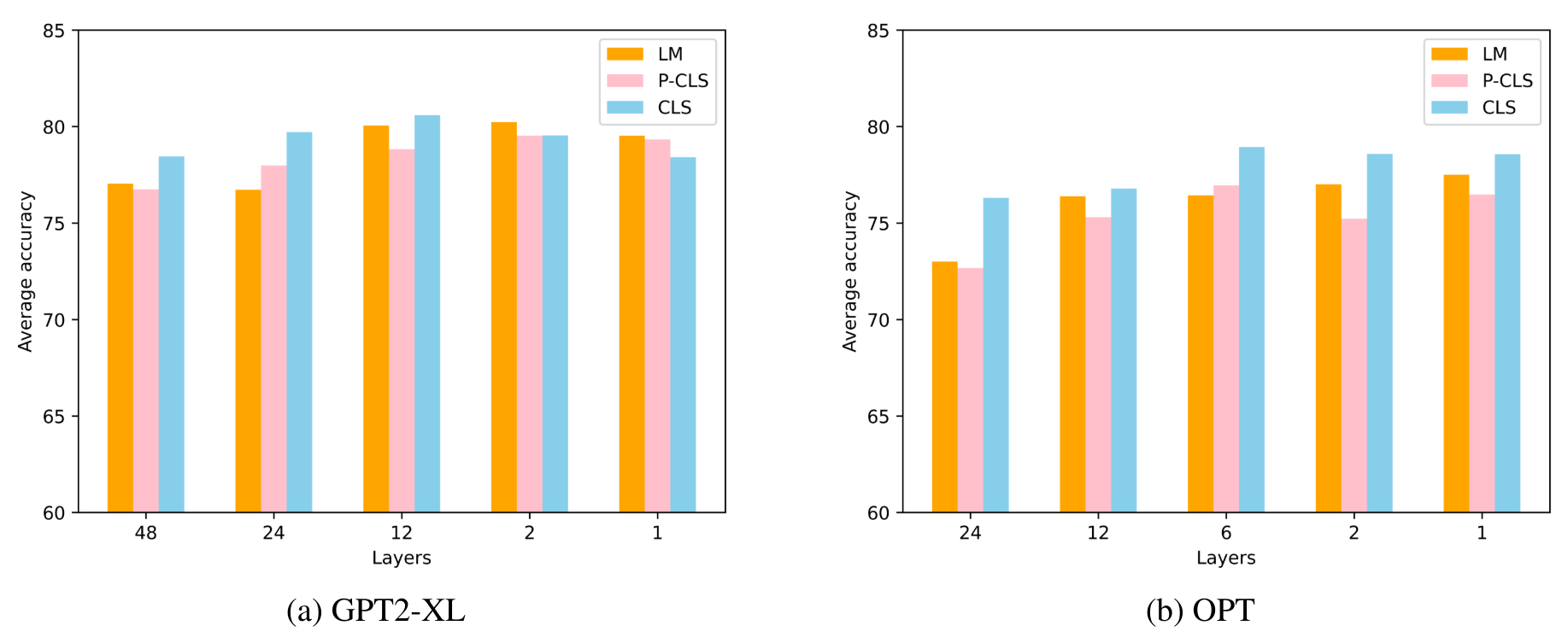
- 해당 3가지 방법들은 유사한 결과를 나타냄
- Layer 수가 모델 성능에 거의 영향을 미치지 않는다는 의미
- 종종 적은 수의 Layer를 가진 모델이 전체 Layer를 가진 모델보다 성능이 좋음
- Language Modeling Head, Classification Head, Layer Decreasing 이 모두 모델 성능과 관련이 없음
- 따라서, 분류 task에서 학습 및 저장 자원을 절약으로 자원 최적화가 가능.
5. Conclusion
Summary
- 본 논문에서는 LLM의 layer 수가 변해도 분류 작업의 성능 저하가 발생하지 않는다는 것을 확인하였음.
- LLM의 parameter를 줄이기 위한 유용한 방법을 보여줌.
Limitation
- Classification Task에만 한정하여 실험하였음 -> QA, Summary 등 다양한 NLU Task에 대해서는 실험하지 않음
- Layer 수 감소에서 일관된 성능을 보이는 근본적인 이유에 대해서는 탐구하지 않았음.

고려대학교 인공지능학과 SLP Lab 석사과정생