Robust Speech Recognition via Large-Scale Weak Supervision

1. Background
최근 연구 동향
Self-Supervised Learning (SSL)
- 최근 음성 인식 분야에서 SSL 방법론을 많이 채택하고 있음
- e.g) Wav2Vec 2.0
- Label 없이 오디오를 직접 학습할 수 있어, 대규모의 음성 데이터를 효과적으로 활용할 수 있게됨
SSL의 한계
- SSL방법으로 학습된 모델은 대용량의 데이터를 학습하여 Encoder는 뛰어난 기능을 갖고 있지만, Decoder는 Encoder만큼 뛰어난 성능을 갖지 못하기에, Task에 따라 Fine Tuning이 필요함
Whisper 제안
- (Fine Tuning 한계 해결) Weak Supervision 방법을 사용하여 Fine Tuning 없이 높은 성능 기록
- (Fine Tuning 한계 해결) 다국어에도 광범위하게 적용 가능
2. Method
Pre-Processing
- 텍스트에 정규화를 거의 하지 않는 등 전처리 최소화
- 이로 인해 최대한 원본 텍스트를 학습하도록 함
- 인터넷에서 대규모의 오디오-텍스트 pair 데이터를 수집
- 품질이 좋지 않기에, 별도의 필터링 방법 개발
- (휴리스틱) 특수문자 제거, 대문자는 ASR System이 생성했을 확률이 높음
- VoxLingua107를 Fine Tuning 시켜 오디오 감지기로 이용하여 Pair가 맞지 않다고 판단되면 사용하지 않음
- 품질이 좋지 않기에, 별도의 필터링 방법 개발
- 30초 Segment로 분할하고, Segment에서 Transcription과 매칭시킴
- 비음성 구간도 일부 학습시켰으며, 해당 구간은 VAD 학습에 사용됨
- 중복 제거 및 수동으로 추가 필터링 수행
Architecture
- Transformer Encoder-Decoder 구조
- 16000Hz Resampling
- 80channel Log-Mel을 25ms window, 10ms stride 로 Feature 추출하고, -1~1 사이값으로 스케일링
Multitask format
- 음성처리 분야에는 다양한 Task들이 있고, 제안하는 모델은 VAD와 ASR을 모두 제공함
- 오디오 Segment에 음성이 없다면, <|nospeech|> 를 뱉고, 음성이 있다면 <|transcribe|> 또는 <|translate|> 토큰을 뱉고 Segment에 대해 ASR를 수행하고, TimeStamp도 기록
- 즉, 30초단위 Segment에 대해 ASR, 그 구간에 대한 Timestamp 기록
- TimeStamp가 있는 데이터로 학습시켰으며, 텍스트 토큰의 앞뒤로 시작, 끝 time token 주입시키고, 임베딩에 추가하여 학습가능하도록 만듬
- Segment 단위 ASR 이후에 TimeStamp를 예측할때, 단위는 20ms임.
- 16000Hz 데이터를 25ms window, 10ms stride를 사용했기에, 오디오의 10ms 구간마다 mel을 뽑았으며, encoder가 20ms 구간마다 feature를 뽑기에 TimeStamp 기록 단위가 20ms가 되는 것임
- Encoder : 20ms의 frame에서 텍스트를 예측하며, 해당 텍스트가 어느 시간대에 발생했는지를 예측
- Decoder : 이 정보를 사용해 타임스탬프를 텍스트에 부여하며, 각 텍스트 토큰에 대해 가장 근접한 20ms 단위의 시간 정보를 제공
3. Experimental Setup
Zero-Shot Evaluation
- 데이터셋이 학습된 적이 없을 때, 그 데이터셋에서 얼마나 잘 작동하는지를 측정
- Fine Tuning 등의 추가 훈련 없이 다양한 데이터셋에서 성능 측정
Evaluation Metric
WER (Word Error Rate)
- ASR의 성능을 평가하는 대표적인 지표
- 예측된 텍스트와 실제 텍스트 간의 차이를 측정
- WER = (삽입된 단어 수 + 삭제된 단어 수 + 대체된 단어 수) / 실제 단어 수
- 측정할 때 생성된 결과에 각 데이터셋에 맞는 포맷으로 역 텍스트 정규화를 수행
RER (Relative Error Reduction)
- 성능 평가에서 모델 A와 모델 B 간의 성능 차이를 비교할 때 사용되는 지표
- ASR Task에 대해 새 모델이 기존 모델에 비해 오류율을 얼마나 줄였는지를 상대적으로 보여줌
- 기존 모델로 Wav2vec2.0, 새 모델로는 Whisper 사용
- {기존결과(label) - 제안결과(pred)} / 기존결과(label) * 100
BLEU
- 번역의 품질을 평가하는 데 사용되는 지표로, 번역된 텍스트가 기준 텍스트(reference text)와 얼마나 유사한지를 측정
ASR Task
- 기존의 모델들은 sota였음에도 불구하고, 데이터셋이 달라지면 성능이 낮아져서 인간보다 성능이 떨어졌음
- Train/Test 모두 같은 데이터셋으로 수행했기 때문에 Out-of-distribution generalization이 발생함
- 제안하는 모델은 인터넷에서 수집할 수 있는 아주 방대한 데이터를 모두 학습시켰기에, 데이터셋마다 특징이 다른 out-of-distribution generalization 문제를 해결했을 여지가 있음
4. Experiment
ASR Performance
Dataset Robustness on ASR
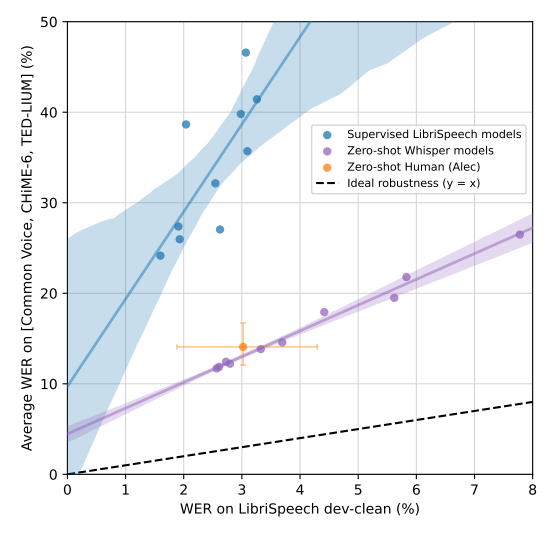
- 점선이 이상적인 Robustness 성능을 가진 선이며, y=x 의 직선.
- LibriSpeech WER과 다른 데이터셋의 평균 WER 값이 똑같아야 매우 Robust 하다는 것이기에, y=x 직선이 Robust한 이상적인 직선임
- 파란선은 LibriSpeech Supervised 학습된 모델인데, 다른 데이터셋에 대해 WER이 급격하게 상승하여 Robustness가 매우 Weak하다고 할 수 있는 반면, 보라색 선은 Whisper 성능인데, Supervised 모델들보다 매우 Robust한 경향을 보임
- 주황색 영역은 사람의 성능인데, Whisper가 때때로는 사람보다도 성능이 좋았음
ASR Performance
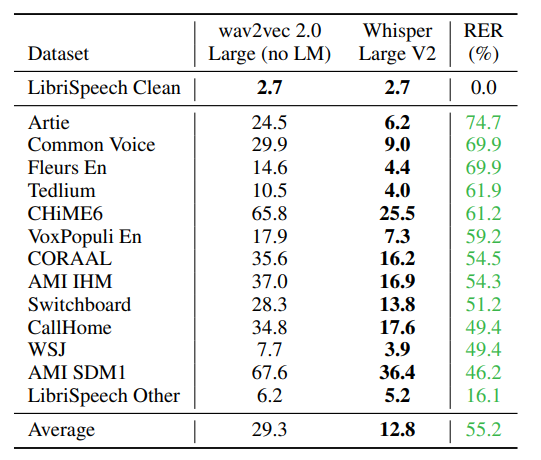
- Wav2vec2.0 과 Whisper 모두 LibriSpeech 데이터셋에 대해서는 동일하게 매우 낮은 WER를 기록하였음
- 대신, 다른 데이터셋으로 테스트를 진행하였을 때, Wav2vec2는 WER이 높아진 반면, Whisper는 Wav2Vec 에 비해서 WER이 낮았음. 이는 Wav2Vec에 비해 성능은 유지하면서 Robustness를 매우 강화하였으며, 훨씬 Generalized되었다고 볼 수 있음
- RER 지표를 이용하여 각 다른 테스트 데이터셋에 대해 Wav2vec에 비해 얼만큼의 성능이 개선되었는지 기록하였는데, 아주 큰 폭으로 Generalize 성능이 개선되었다고 볼 수 있음
Multilingual ASR Performance & Translation Performance
Amount of Data vs WER
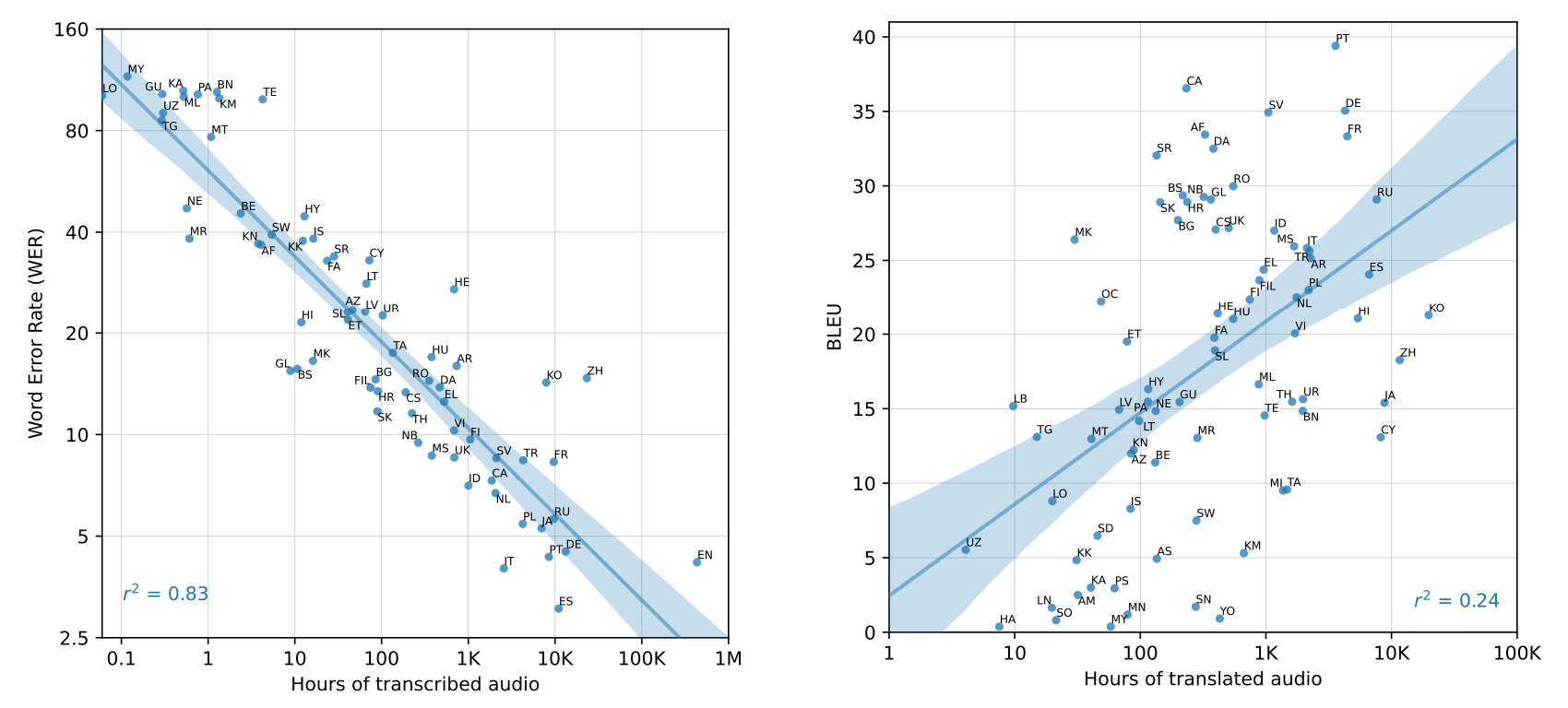
- (좌) transcribe(오디오->언어) 데이터 총량과 WER의 관계
- 전사된 오디오 데이터가 많을수록 ASR성능이 좋음(WER이 낮아짐)
- r² = 0.83은 전사된 오디오의 시간과 WER 간의 강한 상관관계를 나타내며, 오디오 데이터의 양이 증가할수록 WER이 감소하는 것을 보임
- e.g) 영어(EN)는 매우 많은 훈련 데이터를 가지고 있으며, 그 결과 매우 낮은 WER을 보여주지만, 데이터가 적은 언어(e.g: Lao, MY, KA 등)는 높은 WER을 보여줌
- (우) translate(언어->타언어) 데이터 총량과 WER의 관계
- 번역된 오디오 데이터가 많을수록 BLEU 점수가 높아지는 경향이 있음
- 그러나 BLEU 점수와 번역된 오디오 데이터의 양 간의 상관관계는 WER과 전사된 오디오 데이터 간의 상관관계보다 약함 (r² = 0.24)
- 번역의 품질이 데이터의 양 외에도 여러 다른 요인에 의해 영향을 받을 수 있다는 것을 의미하는데 예를 들어, 한국어(KO)와 중국어(ZH)는 상당히 많은 번역 데이터를 가지고 있으며, 높은 BLEU 점수를 기록하고 있지만, 번역된 데이터가 적은 언어들은 낮은 BLEU 점수를 보임
- ASR Task에서 데이터의 양이 성능을 개선하는데 중요한 요소임
Multilingual ASR Performance
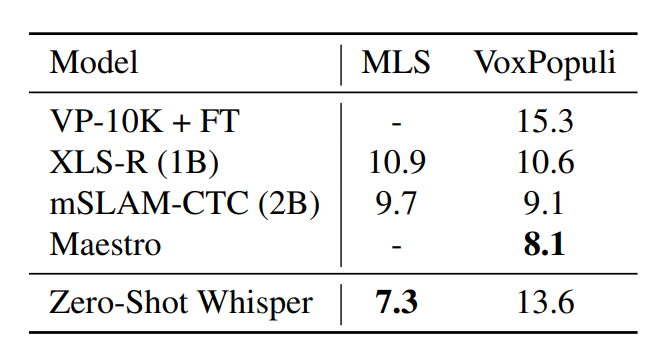
- MLS 데이터셋에서는 성능이 좋아졌지만, VoxPopuli에서는 좋아지지 않았음
Translation Performance
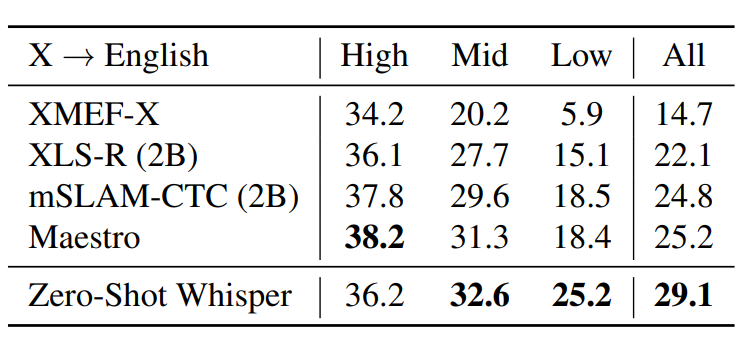
- 여러 모델들이 다양한 언어에서 영어로 번역하는 성능을 비교한 결과
- High, Mid, Low는 학습 데이터가 많았던/보통의/적었던 언어들에 대한 평균 성능
- BLEU 점수 활용했으며, 높을수록 좋음
- 학습 데이터가 많지 않았던 언어들에 대해서 좋은 성능을 기록함
- 하지만 데이터가 많았던 언어에서는 Maestro 모델(38.2)이 더 높은 성능을 보여줬음
- Whisper 모델은 자원이 적은 환경에서의 번역 성능에서 강점을 보이며, 다양한 언어에서 균형 잡힌 성능을 제공함
Language Identification
- 어떤 언어인지 식별하는 Task

- Fleurs 데이터셋에서의 언어 식별 성능을 평가
- 높을수록 좋은 성능이지만, 특정 데이터셋에서는 다른 모델들보다 다소 낮은 성능을 보였으며, 최소한의 성능은 유지하고 있음
Robustness to Additive Noise
- Noise에 대한 강건성 평가
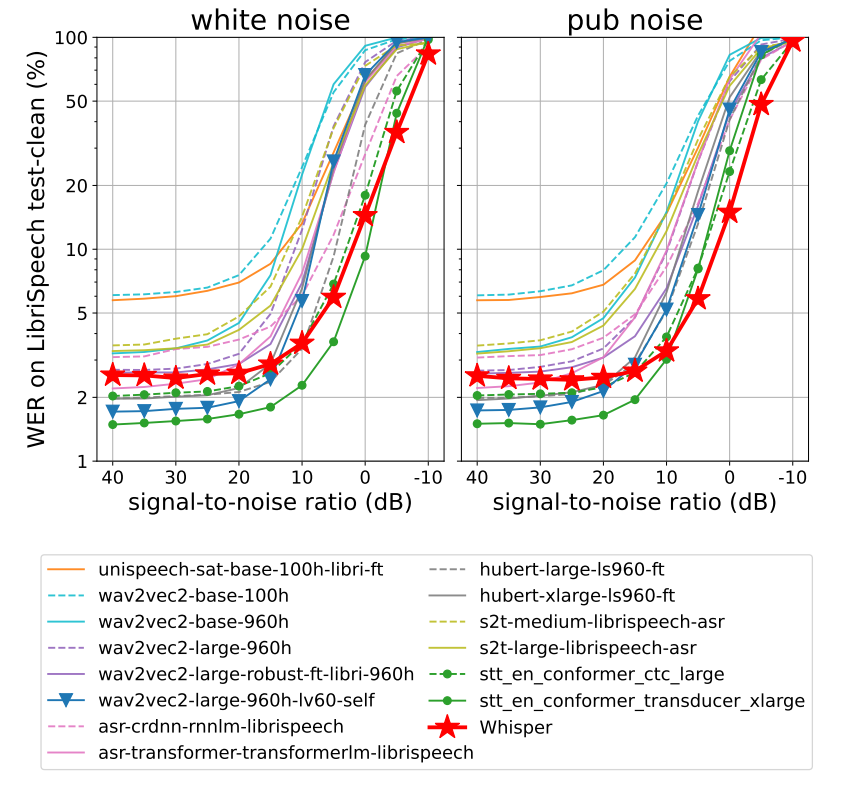
- 신호 대 잡음비(Signal-to-Noise Ratio, SNR)에 따른 성능을 보여줌
- 두 개의 그래프는 각각 다른 잡음 환경(white noise, pub noise)에서의 성능을 보임
- Whisper 모델(빨간 별)은 다양한 잡음 환경에서 일관된 성능을 보여주며, 특히 낮은 SNR 환경(잡음이 많은 환경)에서 다른 모델들에 비해 상대적으로 낮은 WER을 보여주었음
- 이는 Whisper 모델이 잡음이 많은 환경에서도 Robust한 성능을 보여준다는 것을 의미
Long form Transcription & Comparision with Human Performance
- 긴 문장도 전사를 잘 하는지 테스트
- 7개의 다양한 길이의 문장이 포함된 데이터셋으로 테스트
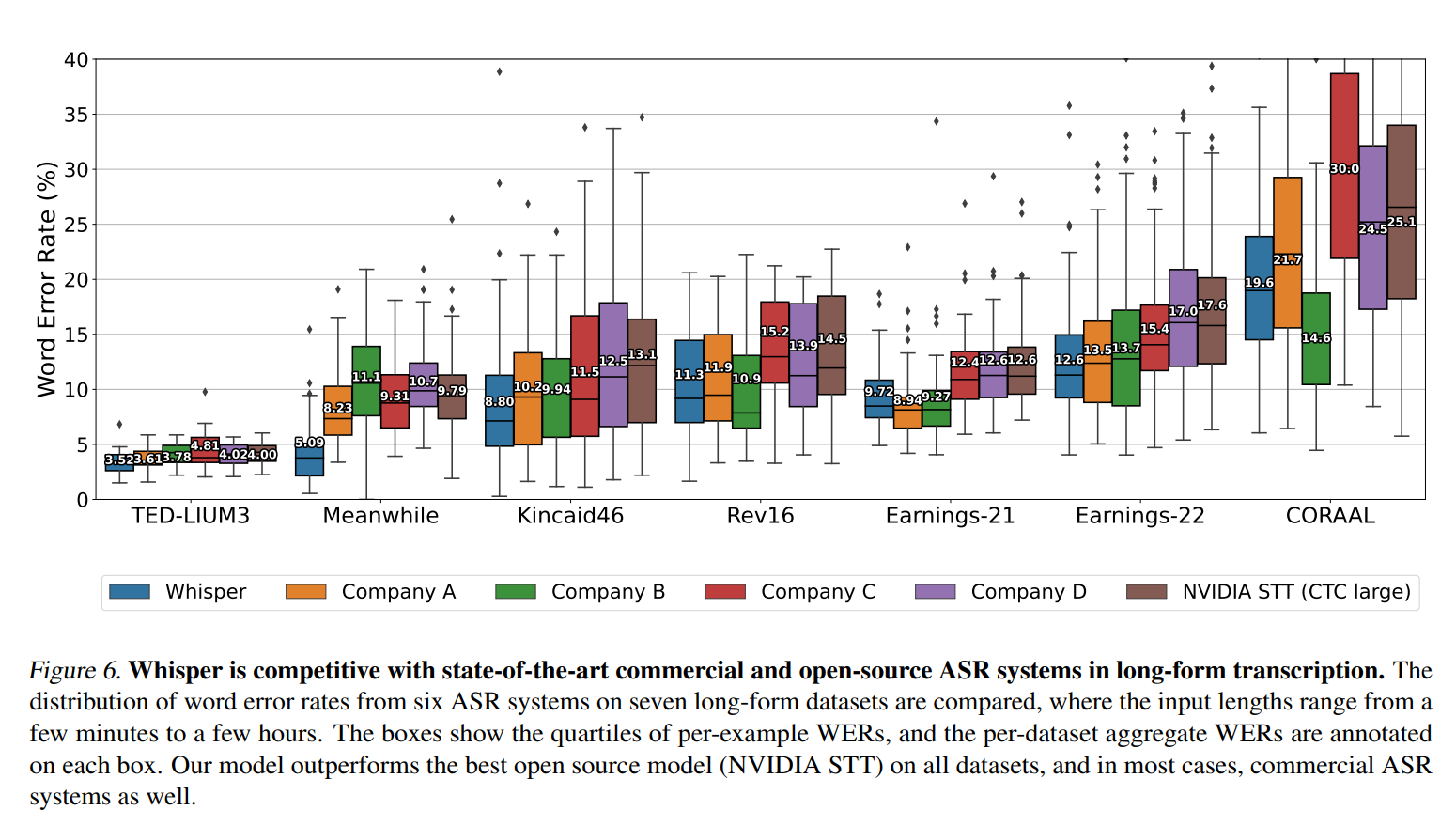
- 타 사 제품들에 비해 WER값이 낮았음
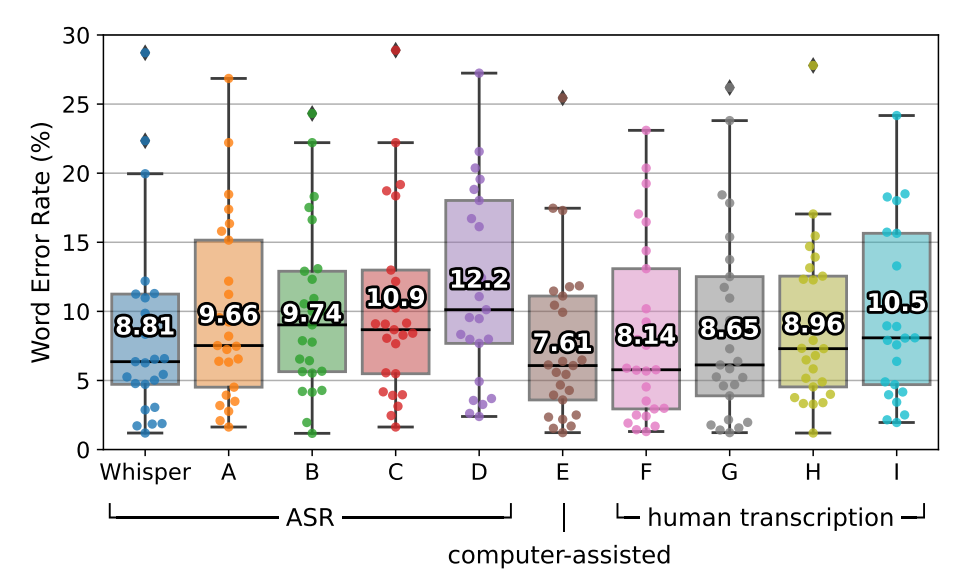
- 타 사 제품들에 비해 WER이 낮았으며, 인간과 비슷한 성능을 보여줌
5. Sensitivity Analysis
Relationship between model size and performance
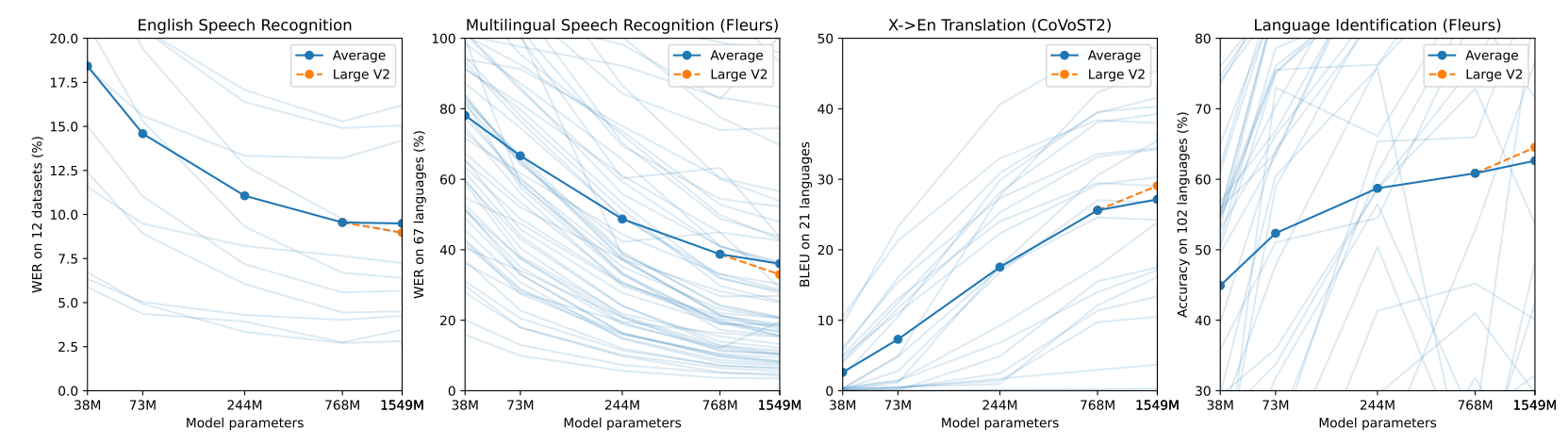
- ASR, Multilingual ASR, Translation, Language Identification 4가지 경우 모두 모델 규모가 커질수록 성능이 좋아지는 경향을 보임
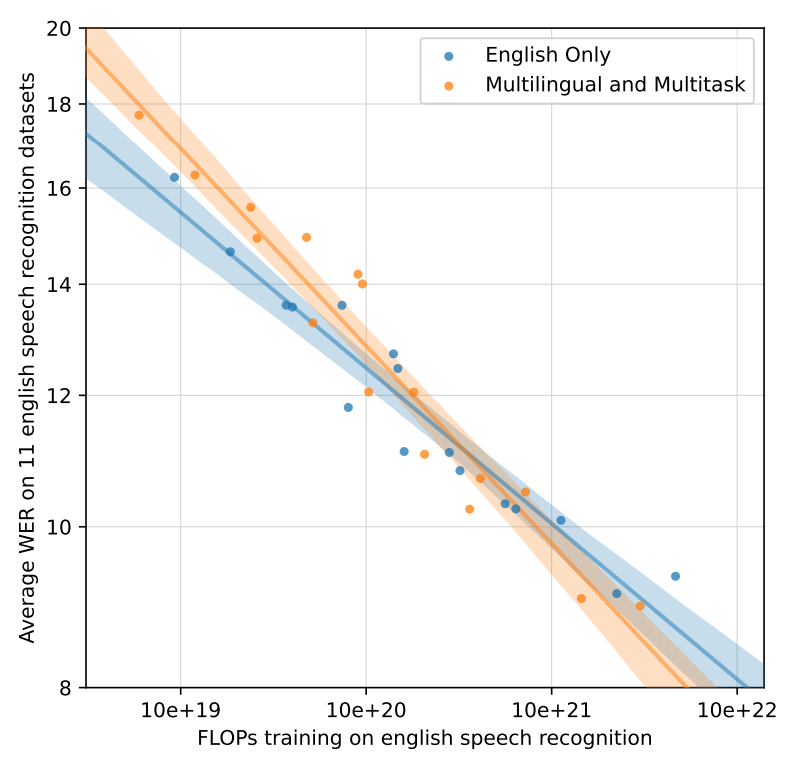
- ASR/Multilingual ASR 2가지 Task에서 모두 FLOPs(연산량)가 커질수록(=모델 규모가 커져서 연산량이 증가할수록) 성능이 좋아짐(WER낮아짐)
Relationship between dataset size and performace
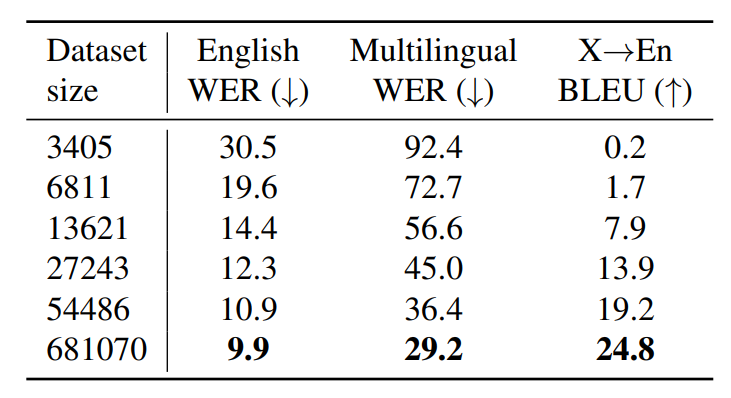
- ASR, Multi ASR, Translate 3가지 Task에서 모두 학습 데이터의 규모를 키울수록 성능이 좋아짐
Ablation Study about Techniques
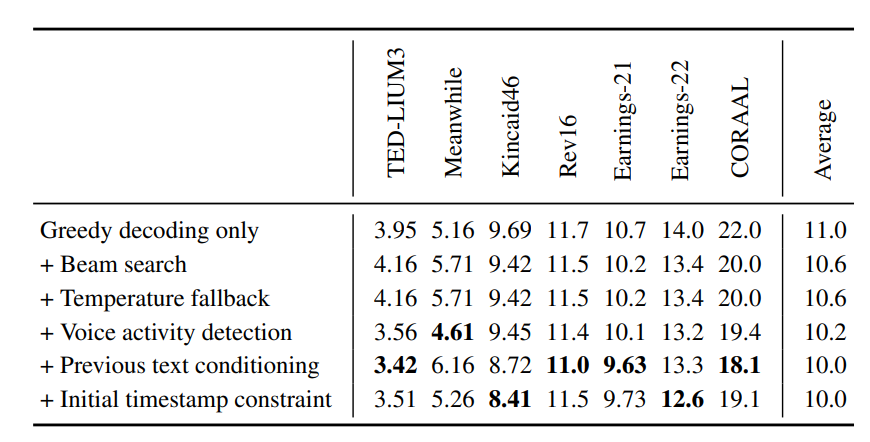
- Greedy decoding only - 기본적인 음성 인식 프로세스이며, 가장 높은 확률의 단어를 선택하는 방법
- +beam Search - 기본 프로세스에 빔 서치 추가 - 단어선택 경로를 추가하여 동시에 고려하는 방법
- +Temperature fallback - temperature parameter(출력 분포 조율 파라미터) 추가 - 높은값은 창의성, 낮은값은 확실성
- +voice activity detection - 음성인식에 음성/비음성 구분하여 처리하는 VAD모듈 추가
- +previous text conditioning - 이전에 예측된 데이터를 현재의 예측에 활용하는 방법 추가
- +initial timestamp constraint - 초기 timestamp 제약하는 방법 추가
- Greedy decoding만 사용할 때보다 다양한 기법들을 단계적으로 추가했을 때 전반적으로 WER이 감소하여 성능이 향상되었음
- 특히, Previous text conditioning과 Initial timestamp constraint를 추가했을 때 큰 성능 향상이 있었는데, 이는 문맥 정보와 타임스탬프 제약이 음성 인식의 정확도를 높이는 데 매우 중요한 요소라는 것을 보임

고려대학교 인공지능학과 SLP Lab 석사과정생