[Paper Review] Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Paper Review
목록 보기
17/20
Segment Any Text (SAT): A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
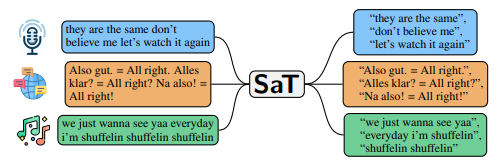
1. Introduction
문제 정의
- 문장 분리 Task (Sentence Segmentation)
기존 연구 동향
1. Rule-Based Approach
- 구두점을 활용하여 문장 분리 (Moses, Spacy)
- If-else 로 사람이 정한 규칙에 따라 분리하는 접근법 (모델 활용 X)
- 구두점이 없는 텍스트(ASR, SNS 등)에 대한 성능 저하
2. Supervised Approach
- 구두점을 활용하여 문장 분리
- 모델 활용하여 분리 (모델 활용 O)
- 구두점에 매우 의존한다는 한계
3. Unsupervised Approach
- 구두점의 패턴을 학습하여 문장 분리
- 낮은 정확도, 비정형 텍스트에서 활용도 매우 낮음
최신 연구 동향
WtP
- 기존 문장 분리 연구들은 모두 구두점이 존재해야 한다는 한계가 있음
- 기존 연구인 구두점 기반 분리가 아닌 문장 구분(\n)을 예측하도록 학습
- 학습 과정에서 구두점을 random하게 삭제함으로써, 구두점 의존도를 낮추게 되어 구두점 없이 동작
- 웹 데이터 크롤링 데이터로 학습하였으며, 웹에서 보통 \n 기호는 문장 분리할때 많이 사용됨.
- 각 문자 다음에 \n 이 나올 확률을 예측하는 방식으로 문장 구분 task에 활용됨
LLM
- Inference 과정에서 1-shot prompting 을 진행하면 문장 분리 가능 (2개짜리)
- finetuning을 통해 성능 개선을 할 수 있지만, 문장 분리만을 목적으로 finetuning하기에는 비효율적 (문장분리에 활용한 데이터셋은 UD, OPUS100)
- 구두점 없을때 문장분리 성능 저하 - ASR, SNS 에서 성능저하
- 긴 문장에서 성능 저하 (논문, 기사 등) - 긴 문서에서 핵심정보 찾기 힘듬
- 같은 입력이라도 prompt에 따라 문장 분리 결과 변동성이 큼
기존 연구의 한계
- 구두점에 의존 - 구두점 부재시 성능 저하
- 도메인 적응력 부족 - 특정 도메인에서의 성능 저하
- 비효율성 - 최신 모델일수록 모델이 무거워지고, 성능저하에 의해 실용성 부족
SAT 제안
- (구두점 의존성) - 구두점을 랜덤하게 제거하여 구두점 없이 동작
- (도메인 적응력) - LoRA finetuning
- (비효율성) - Subword based Model로 한번에 여러 문자처리하여 속도향상 + Lookahead를 적용하여 문장 분리에 있어 너무 먼 미래를 보지 않게 제한 걸어둠
2. Method
- SAT는 XLM Roberta 모델을 finetuning 한 것임.
Finetuning 방법
- XLM-Roberta 모델을 활용하여 문장 분리 - 다국어 지원 가능
- 문자 단위가 아닌 subword 단위로 학습 수행 - WtP 대비 3배 속도 향상
- 학습 데이터 10% 가량 모든 구두점, 대소문자 제거 + 공백을 random 변형 - 구두점 없어도 됨
- Lookahead 기법으로 최대 토큰 48개로 제한 - 긴문장, 짧은 문장 모두 잘 구분함
- finetuning 이후에 추가 lora finetuning - domain adaptation 가능
SAT = Full Finetuning XLM-Roberta + LoRA Finetuning
3. Experimental Setup
1. Dataset
General Text
- UD - 다국어 문장 분리 데이터셋
- OPUS100 - 다국어 뉴스, 자막 데이터
- Ersats - 뉴스 문장 분리 데이터
Noisy Text
- Seep-NLG - TED 강연 ASR
- Tweets - 트위터 (세르비아, 슬로베니아)
- Code-Switching - Reddit, 번역 데이터
Domain Specific
- MultiLegalSBD - 다국어 법률 문서
- Verses - 35000곡 가사 데이터
2. Evaluation Metrics
F1-Score
- Precision - 예측한 문장 경계 중 실제로 문장 경계인 비율
- Recall - 실제 문장 경계를 얼마나 잘 찾아냈는지
Short Sequence Acc
- 완벽하게 분리되면 100, 하나라도 틀리면 0 부여
3. Baseline
Related
- NLTK, SPacy - Rule based
- Ersats - 뉴스 데이터 기반 문장 분리 모델
- WtP - 웹 데이터 기반 문장 분리 모델
- WTPPUNCT - 구두점 확률을 추가 학습한 WtP
- SAT - XLM-R을 Full Finetuning
- SAT-SM - 문장 분리 데이터셋으로 추가 학습한 SAT
- SAT-LoRA - 특정 도메인 적응을 위해 LoRA 학습
LLM
- LLaMA3 8B, Cohere Command R
4. Result
General Text Evaluation
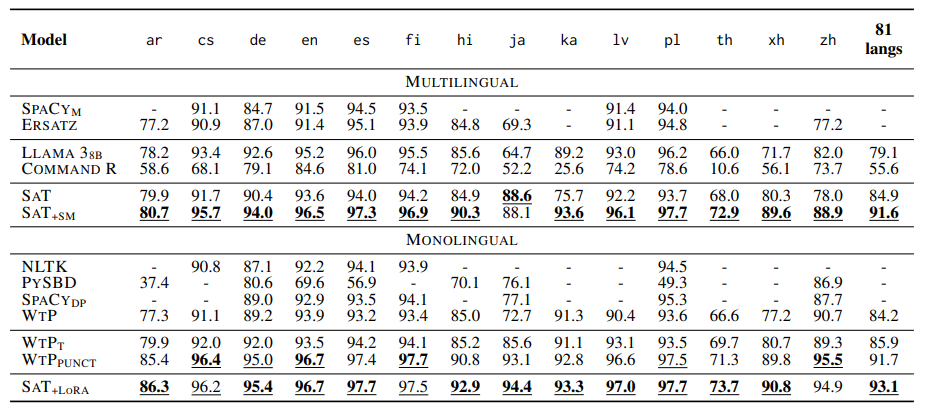
- 기존 모델들보다 SAT들이 더 좋고, 도메인에 강점이 있다
- LLM은 zero-shot prompting에서 성능이 박살난다
5. Opinion
- 결과를 더 읽어줄 수가 없었다. 뭐 자기 방식이 제일 뛰어나다고 주장할텐데... 제대로 평가할 거였으면 LLM에서 prompting을 주었을 때를 평가해야 하지 않나 라는 생각이 든다. 그리고 efficiency 운운하는데 llama 1B 짜리도 사용하지 않고 문장분리는 간단한 task라면서 8B짜리로 평가해높고 efficiency 운운한다. 개인적으로 llm과 비교평가 했다고 하는데 전혀 공정한 평가가 되지 못한다고 생각하며, 솔직히 prompt tuning만으로 제안하는 모델보다 성능이 뛰어날 것으로 생각된다.

고려대학교 인공지능학과 SLP Lab 석사과정생