Reshape Dimensions Network for Speaker Recognition
1. Background
기존 연구 동향
- 기존 화자 인식 (Speaker Recognition) 분야에서는 CNN을 이용하여 음성 데이터를 처리하였음
- 1D conv는 time domain을 다루는데 강점이 있으며, 2D conv는 frequency domain을 다루는데 강점이 있음
- 기존 연구는 이 두 conv를 함께 통합하려는 시도가 많았음
1D, 2D 통합의 한계
- 1D feature, 2D feature 통합에 있어서 효율성 저하, 복잡성 증가라는 한계가 있었음
ReDimNet 제안
- (비효율성/복잡성 한계 극복) 차원 변경(Reshape Dimension) 기법 사용하여 1D, 2D 모두 효율적으로 활용하고, 모델 크기도 작아지면서 최고의 성능을 기록함
2. Architecture
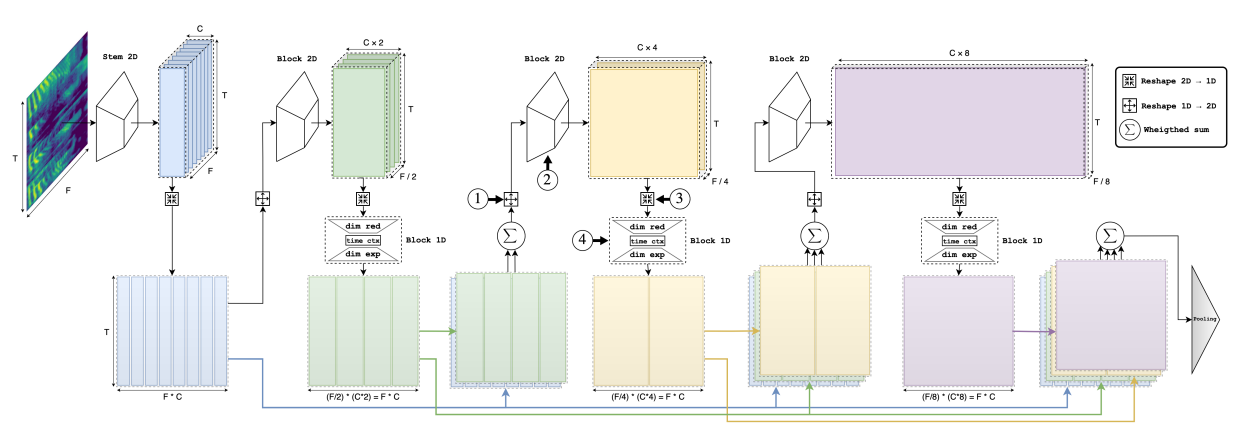
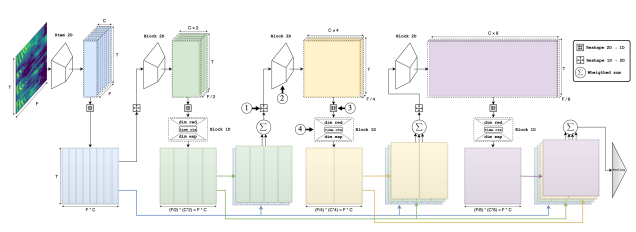
Dimensions Reshape
- 1D -> 2D로 변환하고 다시 2D -> 1D로 변환하는데, Feature Map의 크기를 유지함으로써, 자유로운 연산이 가능하게 함
2D -> 1D
- (B, C, F, T) -> (B, C*F, T) : 1D와 2D feature가 time axis에 대해 동일한 차원을 가지게 되어 더할 수 있게 됨
1D -> 2D
- (B, C*F, T) -> (B, C, F, T) : 2D로 다시 변환 시, Conv Block에 다시 태울 수 있음
Residual Connection
- 2D Feature Map에서 frequency axis의 stride를 일정하게 설정하고, Channel을 일정한 간격으로 증가시킴으로써, C와 F의 크기를 일정하게 유지시킴
- ConvBlock의 결과 Feature Map의 C, F를 일정하게 유지함으로써, Reshape을 통해 동일한 Shape의 1D Feature로의 변환이 가능해짐
- 이러한 기법을 사용하여, 1D 에서의 Feature map의 크기는 언제나 동일한 shape을 가지게 되고, 각 conv block을 통과한 feature들을 Residual connection으로 이어줄 수 있음
- Residual Connection은 Gradient Vanishing 문제를 완화하는 목적으로도 해석될 수 있고, 이전 Block의 Feature가 다음 Block의 Feature로 학습되게끔 하는 목적으로도 해석할 수 있음
Block Size
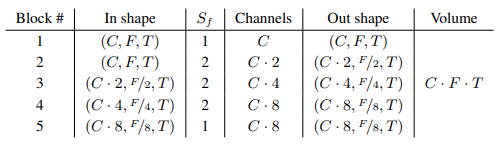
- Sf 는 Frequency Stride를 의미
3. Recipe
- Input Feature : 72차원의 mean-normalized Mel filter bank log-energies를 Feature로 사용하며, 25ms frame len과 15ms 간격으로 Mel filter bank log-energies로부터 feature 추출
- 이때,512 FFT Window를 사용하여 20-7600Hz 범위의 주파수 대역폭 사용
- Frame level Feature (log mel) 에서 Utterance Embedding(Input Feature)을 뽑을 때, Attentive Statistics Pooling을 사용해 각 프레임의 중요도를 학습하고, 발화 전체를 대표하는 임베딩을 생성
4. Experiment
Setup
- Dataset : VoxCeleb2 Dev Dataset
- Optimization : SGD
- momentum=0.9 : 이전 단계의 기울기 값을 90% 반영
- Weight Decay=2e-5 : 가중치 감소 -> 모델의 복잡도 감소 -> 과적합을 방지
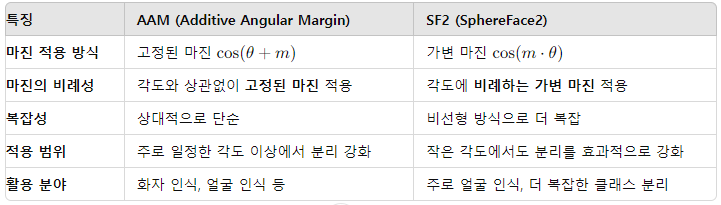
- Loss Func : Additive Angular Margin (AAM) Softmax / SphereFace2 (SF2) 비교
- AAM Softmax : 각 클래스 간의 각도 차이를 최대화하여 분류 성능을 높임
- 고정된 각도 margin을 사용하여 클래스 간의 구분을 강화
- SF2 : AAM 손실과 유사하게 각도 차이를 최대화하여 분류 성능을 높임
- 각도에 따라 마진을 비례적으로 적용하는 가변 margin을 사용하여 클래스 간의 구분을 세밀하게 조정
- AAM vs SF2
- AAM Softmax : 각 클래스 간의 각도 차이를 최대화하여 분류 성능을 높임
- Training Recipe : 짧은 Segement로 Pretrain, 긴 Utterance로 FineTuning (=Large Margin FT)
Training
Pre-Training
- 2초 단위의 Segment 사용
- MUSAN 데이터셋을 사용하여 Noise를 추가하여 Augmentation 수행
- MUSAN : 잡음(noise), 음악(music), 사람들의 대화 소음(babble)이 포함
- RIR 데이터셋(실제 방의 반향 응답)을 이용하여 음향 환경을 모사하여 다양한 음성 환경에서의 훈련을 재구성
- 데이터를 0.9배 또는 1.1배의 속도로 재생하여 다양한 음성 데이터를 생성
Fine Tuning
- 6초 단위의 Segment(=utterance) 사용
- Large Margin Fine Tuning 을 의미하며, Result에서 LM으로 표기
Test
-
VoxCeleb1의 Cleaned 를 사용
-
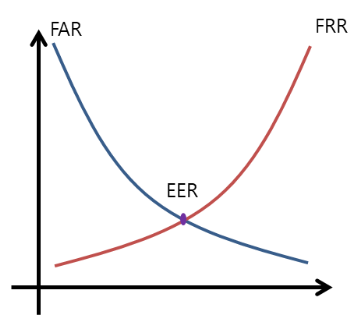
EER (Equal Error Rate) : 오탐률(false acceptance rate, FAR)과 미탐률(false rejection rate, FRR)이 동일해지는 지점을 의미하며, 작을수록 성능이 더 좋음
-
minDCF (Minimum Detection Cost Function) : 실제 시스템에서 발생하는 오류를 최소화
-
Adaptive S-Normalization (AS-Norm) : 추가적인 성능 향상을 위해 이용하였으며, 코사인 유사도를 안정화하는 목적으로 사용됨
- 유사도 높은 300개 임베딩 벡터를 선택하여 Normalization 수행
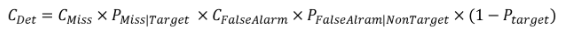
5. Result
- GMACs : 모델이 처리하는 Multiply-Accumulate Operations의 수
- 모델의 계산 복잡도를 측정하는 지표이며, 숫자가 클수록 더 많은 계산 리소스를 필요로 함
- LM : Large Margin Fine Tuning 유무. 앞서 기술하였음
- AS-Norm : Adaptive S-Norm을 적용했는지 유무. 앞서 기술하였음
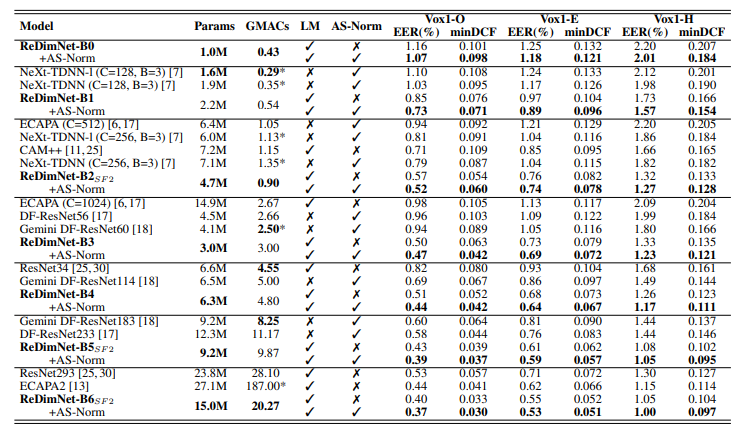
- ReDimNet 계열 모델들은 세팅에 따라 다양한 파라미터 수와 계산 복잡도를 가질 수 있으며, AS-Norm을 적용했을 때 성능이 크게 향상됨
- ReDimNet-B5SF2 모델은 파라미터 수가 비교적 적지만 매우 높은 성능을 기록
- ECAPA2와 ResNet293은 매우 많은 파라미터와 높은 계산 복잡도를 가지고 있지만, 그만큼 성능이 매우 뛰어남

고려대학교 인공지능학과 SLP Lab 석사과정생