SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
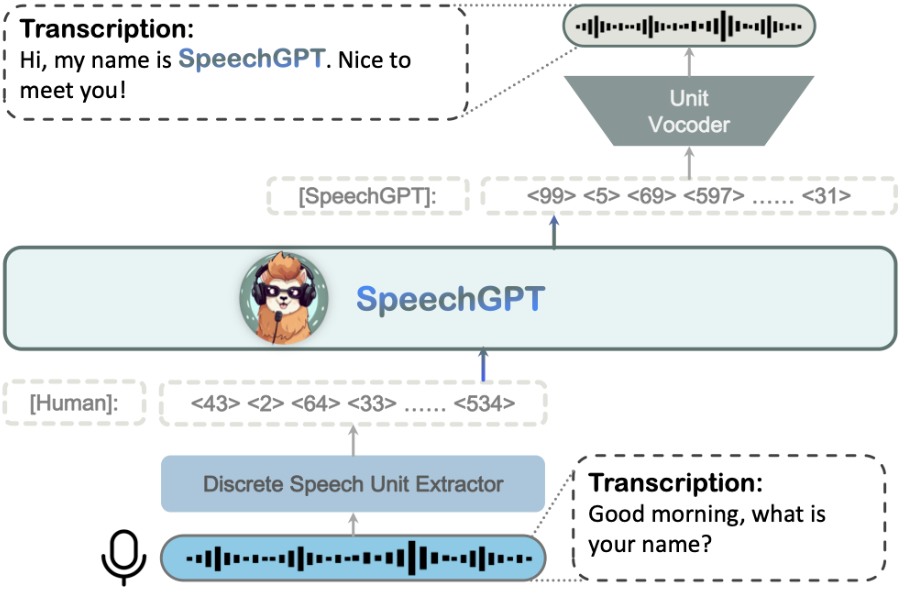
1. Background
현재 Multimodal의 한계
- 현재의 Multimodal은 다중 모달리티를 잘 인식하나, 다중 모달리티를 생성하지는 않음.
기존 음성 처리 모델링의 한계
- 음성과 같은 연속 신호는 이산 토큰 단위로 수신하는 LLM에 직접 적용 불가능하기 때문에 언어 모델링처럼 이산 토큰을 추출하여 음성 생성 모델을 구축하여 활용하였음.
- 하지만 Text에서 Speech를 생성하거나 Speech에서 Text를 생성하는 Cross Modality 생성이 아닌 Speech로부터 Speech를 생성하는 단방향 변환만 가능함.
모달리티 통합 제안
- 모델이 음성과 텍스트 다중 모달리티를 처리하고 원하는 Modality의 답변을 자연스럽게 생성하게끔 하기 위해 음성 신호를 이산 토큰으로 인코딩하여 직접 LLM에 통합하는 방법을 제안.
2. Construct Instruction Dataset
Base Dataset
- 음성과 텍스트 데이터 모두를 잘 결합하고 이해할수 있도록 Base Dataset으로부터 Instruction Dataset 구축.
- Base Dataset으로 GigaSpeech, Common Voice, LibriSpeech 데이터셋을 사용하여 speech-text 쌍의 데이터셋을 구축.
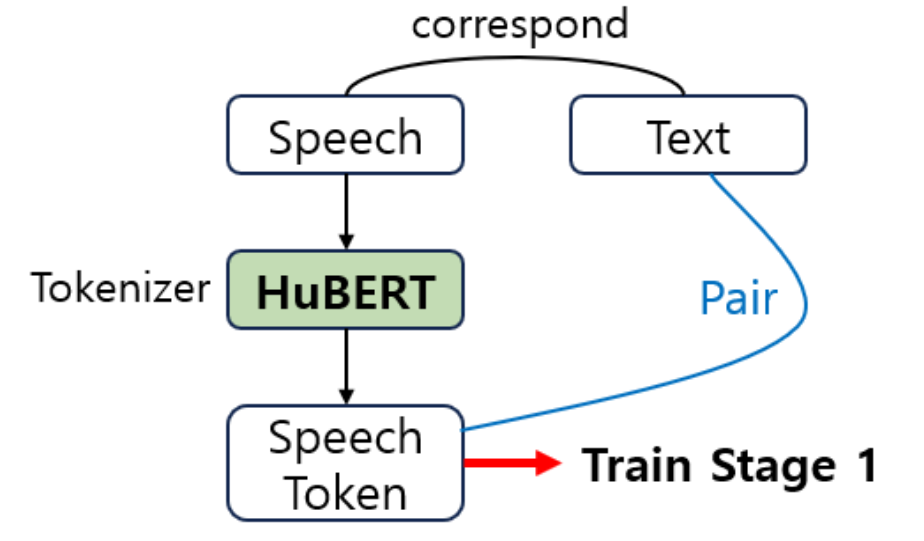
- Speech는 mHuBERT2 토크나이저로 speech token으로 변환하고, Text는 text2unit 모델을 학습시켜 text token으로 변환하여 최종 speech token-text token 쌍의 Base Dataset을 구축.
Cross-Modal Instruction Dataset
- Speech-Text Cross Modality의 Mapping 능력을 학습시키기 위한 데이터셋.
- LLM의 input으로 speech token이 들어가면 output으로 동일한 의미의 text token이 나오게끔 Instruction Tuning으로 Pair를 생성.
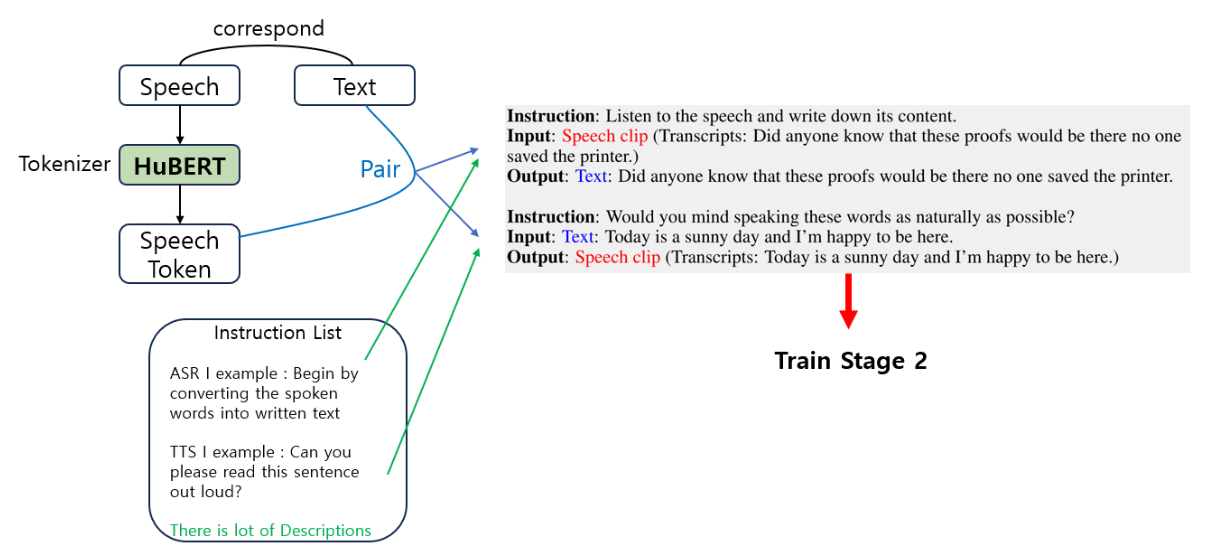
Chain-of-Modality Instruction Dataset
- Speech-Text Cross Modality의 Generation 능력을 학습시키기 위한 데이터셋.
- LLM을 사용하여 text token으로부터 Response text token을 얻고, 이를 TTS를 사용하여 Response speech token을 얻음으로써, 총 speech token, text token, response speech token, response text token 4개를 쌍으로 데이터셋 구축.

3. Model Architecture
- HuBERT : Speech를 Token으로 추출하기 위한 Extractor
- LLM BackBone : LLaMA 13B
- HiFi-GAN : Speech Response Token을 Speech로 복원하기 위한 Vocoder
4. Train

- 이후 아래 3가지 방법 순서대로 학습 진행
Train Method
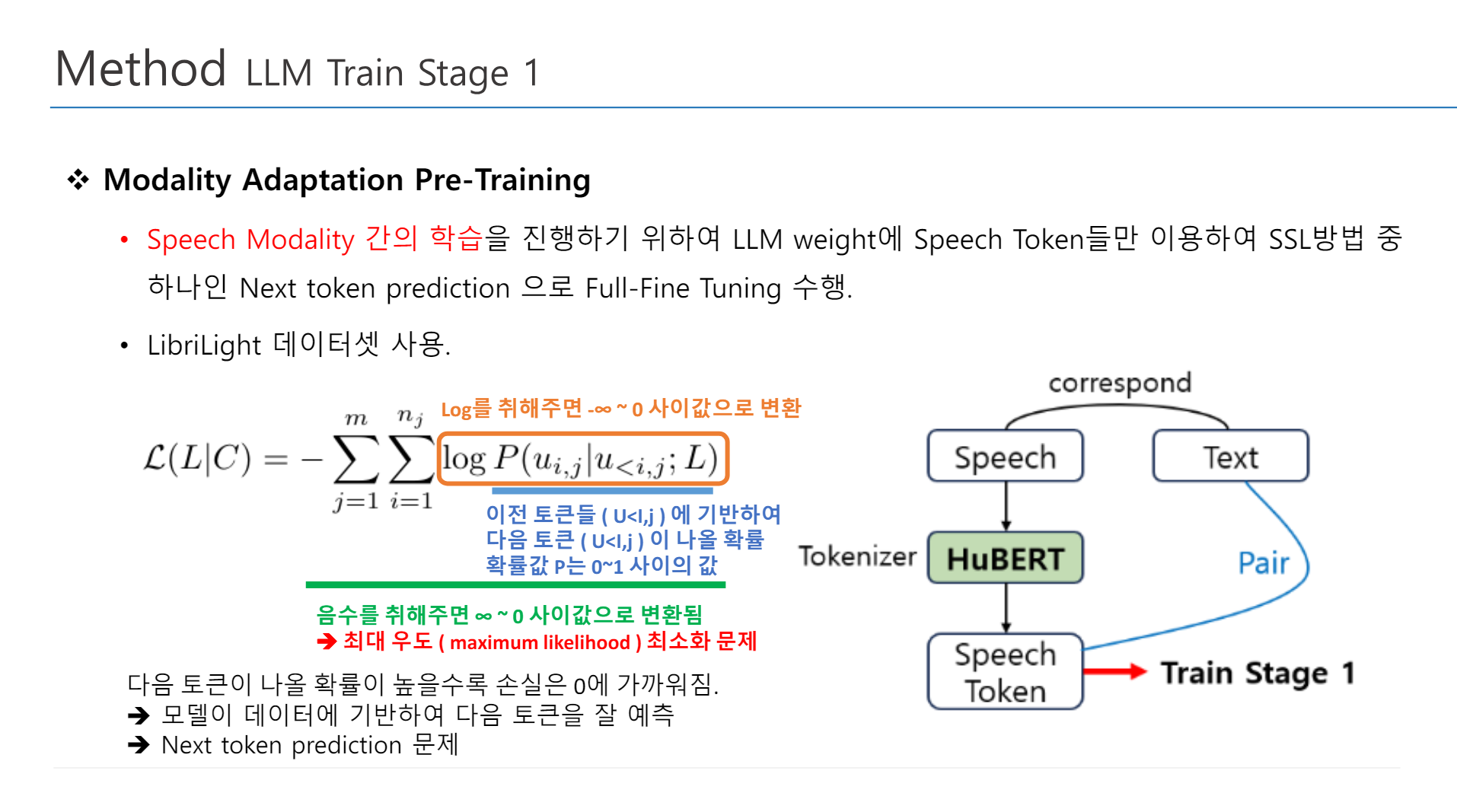
1. Modality Adaptation Pre-Training
Speech Modality 간의 학습을 진행하기 위하여 NLP에서의 LLM Pretrain 방법과 동일하게 LLM weight에 speech token들만 이용하여 SSL Method로 Full-Fine Tuning 수행
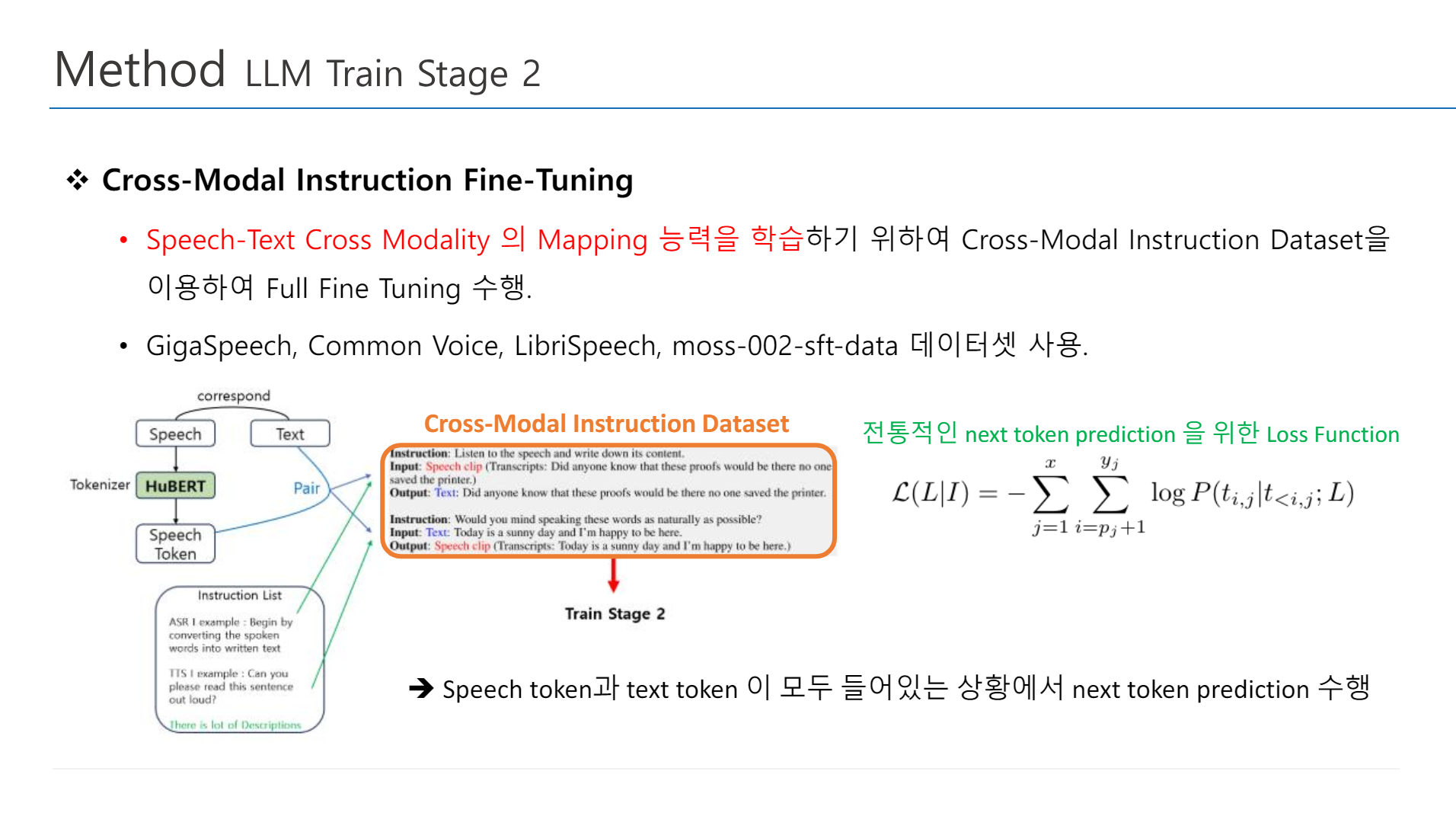
2. Cross Modal Instruction Fine Tuning
Speech-Text Cross Modality의 Mapping 능력을 학습하기 위하여 Cross-Modal Instruction Dataset을 이용하여 Full-Fine Tuning 수행
3. Chain of Modality Instruction Fine Tuning
Speech-Text Cross Modality의 Generation 능력을 학습하기 위하여 Chain-of-Modality Instruction Dataset에서 Speech token, Text token, Speech Response token, Text Response token을 랜덤하게 적절히 섞어 Pair를 생성한 후, 해당 데이터를 사용하여 LoRA Fine Tuning 수행.

5. Discussion
Limitation
- Speech에서 감정이나 성조를 생성하는 능력 부족
- Text Response 를 획득해야 Speech Response 획득 가능
- Context 길이 제한으로 Multi-Turn 대화 불가능
Opinion
- 이 논문에서 결과가 있기는 하다.
- 그런데 결과가 input output 보여주고는 잘 따랐다! 대답을 잘했다! 하고 끝이 난다.
- Result 부분이 매우 빈약해서 너무 아쉽다.

고려대학교 인공지능학과 SLP Lab 석사과정생