
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression

1. Background
LLM의 발전
- LLM은 매우 큰 모델 파라미터를 요구함.
- LLM을 경량화하는 방법에는 관점에 따라 효율적으로 추가학습을 진행하는 FineTuning, 추가 학습 없이 모델 자체를 줄이는 Compressing 방법이 존재.
기존 Compressing Method의 한계
- 기존 Compressing Method 로는 Quantization, Pruning, Knowledge Distillation, Low Rank Approximation 존재.
- Quantization은 모델의 Weight Matrix의 정밀도(Precision)를 감소시켜 모델을 압축하지만 3비트에서 8비트까지의 제한된 bit의 표현으로 정보의 손실이 발생하는 단점 존재
- Pruning은 Unstructed Pruning, Structed Pruning으로 구분되며, Structed Pruning은 Layer, Channel 등 Weight 자체를 직접 Drop하는 과정이며, Unstructed Pruning은 Weight 내부에서 Sparse 하게 Drop하는 과정임.
- Structed Pruning은 가중치 자체를 버림으로써 정보 손실이 과도하게 발생하고, Unstructed Pruning은 pytorch에서는 0값으로 만들지만 이는 실제 pruning이 진행되지 않기에, TensorRT 등의 하드웨어, cuda에 직접 접근해서 Pruning 해줘야 하는 특정 하드웨어에서만 효율을 자랑한다는 단점이 있음
- Knowledge Distillation은 Student 모델의 추가 학습이 필요하여 오랜 시간이 걸린다는 단점이 있음.
- Low Rank Approximation은 모델 Weight Matrix를 저차원의 여러 행렬로 분해하여 행렬 크기를 최소화함.(e.g. SVD) SVD의 경우, 중요하지 않은 특이값을 제거함으로써 데이터를 압축. 하지만 중요한 정보가 손실될 수 있으며, 이는 곧 성능 저하로 연결될 수 있음.
SVD를 이용한 Compressing Method의 한계
- 데이터 전처리의 부정확성 : SVD를 적용하기 전의 데이터 전처리 단계가 효과적이지 않을 경우, 데이터의 중요한 특성이 간과하거나 무시될 수 있음.
- 모델 파라미터 업데이트의 부재 : Weight Matrix의 특정 부분이 한번 절단되면, 이후 이 Parameter들에 대한 업데이트가 이루어지지 않음. 이는 압축 후 모델의 성능을 복원하는데 필요한 조정이 이루어지지 않는다는 의미.
정교한 SVD Compressing Method 제안
- Truncation-Aware Data Whitening
SVD로 Weight를 효과적으로 줄이기 위하여 input이 Whitening 상태로 만들어주게끔 Weight를 조정한 뒤, 조정된 Weight에서 SVD를 수행하여 Compressed 된 Weight 생성.
Whitening 상태는 모든 변수들이 서로 독립적이고 표준 정규분포를 따르는 상태.
변수들 간 상관관계를 제거함으로써 각 변수들이 모델에 독립적인 정보를 제공함.
모든 변수들의 분산을 1로 만들어줌으로써, 변수들이 모델에 미치는 영향력을 동일하게 만들어줌.- Layer-wise Closed-Form Update
특이값 절단 Process(Truncation-Aware Data Whitening) 를 한번에 진행하지 않고 각 층마다 순차적으로 진행함. 처음 층에서 Compressed된 Weight를 이용한 output과 본래 Weight를 이용한 output의 차이를 최소화시키는 Weight를 구함으로써, 기존 Weight에서 최소화되었을 때의 Weight으로 Update를 진행함. 해당 과정을 각 층마다 순차적으로 진행함으로써 현재 층에서 절단된 특이값으로 인해 발생하는 error가 다음 층에 누적되지 않게 되고, 이는 곧 최종 성능 저하를 보상하게 됨.
2. Method
Truncation-Aware Data Whitening
Compressed된 Weight를 얻는 과정
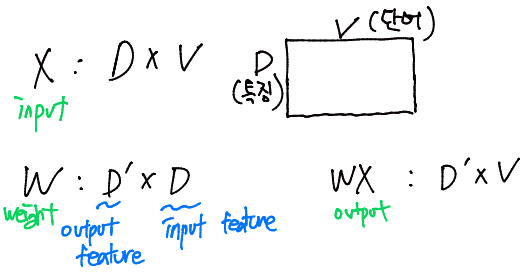
- 기존 LLM의 Weight를 사용한다면 X를 input, Weight를 W라고 할 때, layer의 output은 WX가 된다.
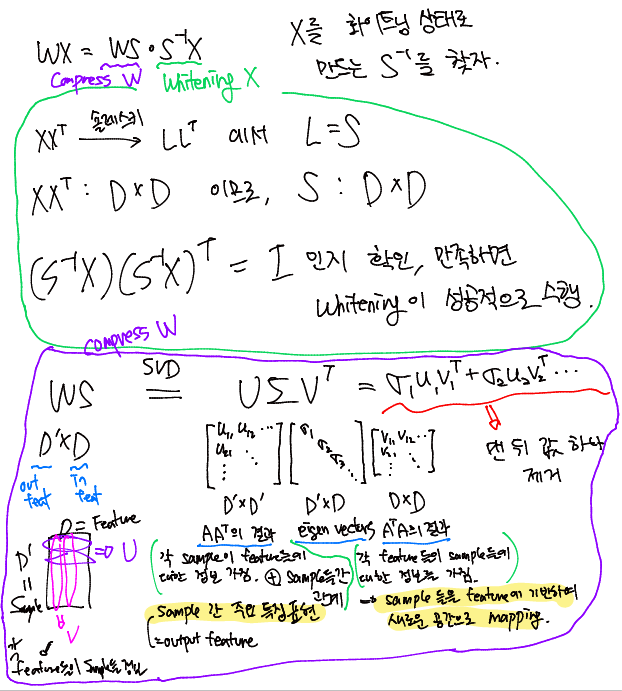
- SVD를 효율적으로 수행하기 위해 input X들이 Whitening Matrix가 되게끔 임의의 행렬 S를 곱해준다. WX = WS * S^-1X
- S는 XX^T(X의 공분산행렬)에서 Cholesky 분해를 진행한 하삼각행렬이다.
- 3번 과정에서 구한 S를 이용하여 (S^-1X)(S^-1X)^T = I 가 성립하는지 확인한다. 해당 수식이 성립한다면 X의 Feature들이 Orthogonal한 상태인 것이고, 이는 곧 X의 Feature들이 모두 독립이라는 의미이다. 또한, 정규화가 진행되었다는 의미이다.
- 4번 수식의 성립을 확인하였다면, 2번의 WS를 SVD를 진행하여 가장 작은 Eigen vector를 제거한다.
- 제거된 WS 에 S^-1를 곱해주어 제거 완료된 W'을 얻는다.
Layer-Wise Closed-Form Update
각 층별로 독립적으로 Compressed 된 Weight를 Update 하는 과정
- 기존 LLM 의 output은 WX, Compressed된 W'를 사용한 output은 X' 이라고 할 때, Error = |WX-W'X'|이다.
- Error를 최소화하는 W'를 찾는 문제로, E = WX-W'X' 는 최소제곱법으로 W'을 구할 수 있다.
- W' = WX(X')^T(X'(X')^T)^-1 로 pseudo inverse를 사용한 최소제곱법으로 W'를 구할 수 있다. X'가 full-rank가 아니거나 X'X'^T가 singular matrix인 경우, pseudo inverse (X'X'^T)^+ 를 사용하여 문제를 해결한다.
- 3의 수식 결과로 나온 W'를 최종 W'로 삼고, W를 W'로 Update를 진행한다.
- 위 1~4 과정을 각 Layer마다 순차적으로 진행하여 최종 Compressed 된 LLM을 얻을 수 있다.
예제
X(input) : (D V), W(LLM Weight) : (D' D), WX(output) : (D' * V) 라고 가정
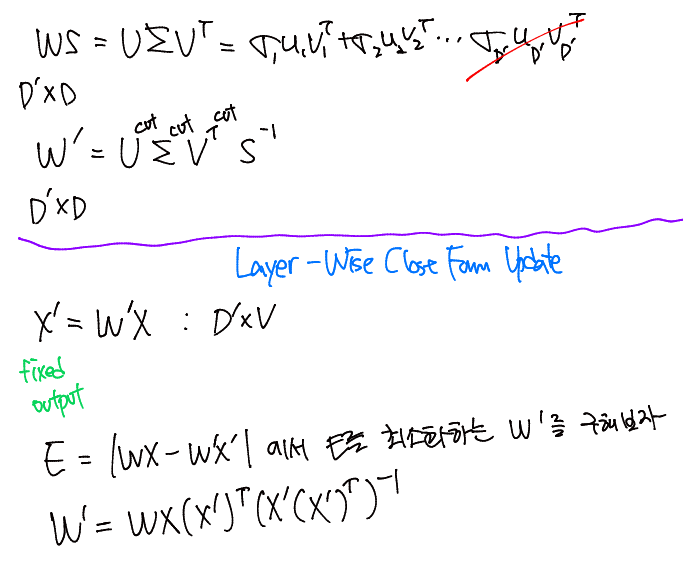
Summary
- 숄레스키 분해로 input X의 Feature들 Whitening 시키는 Matrix S를 구함
- (S^-1X)(S^-1X)^T = I 가 성립하는지 확인(검증)
- WS를 SVD하여 가장 작은 고유값 제거함으로써 W' 획득
- input이 W'를 통과하여 X'획득
- 원래 출력과 compressed 된 출력의 차이를 최소화하는 W'를 구하고, 해당 W'를 기존 LLM의 W 위에 Override하여 Update 수행
- 1~5 과정을 각 Layer마다 순차적으로 진행하여 최종 Compressed 된 LLM을 획득
3. Result
Evaluation
1. 다양한 압축 비율에서의 성능
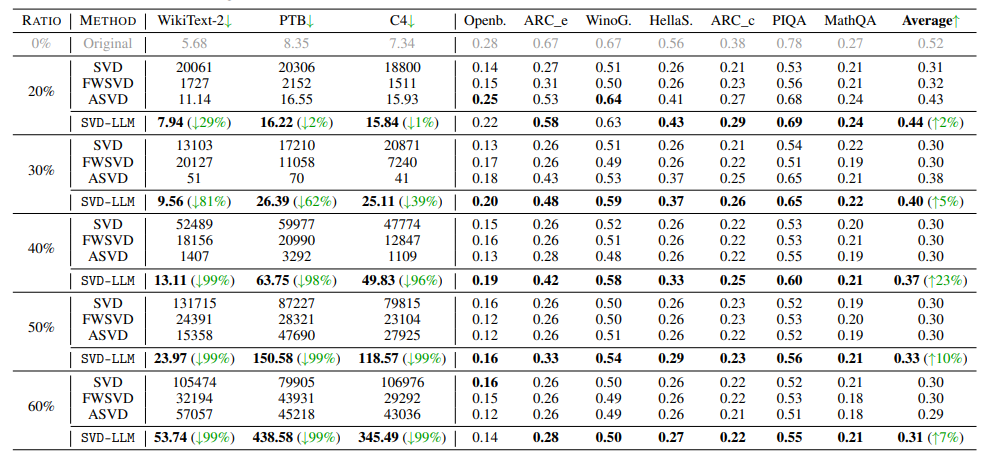
- 압축률에 따라 원본(Original), 여러 압축 기법들(SVD, FWSVD, ASVD) 과 제안하는 압축 기법(SVD-LLM) 들의 Perplexity를 계산하여 성능 평가.
- 7가지 상식 추론 데이터셋에 대한 정확도 비교
2. 다양한 LLM에서의 성능
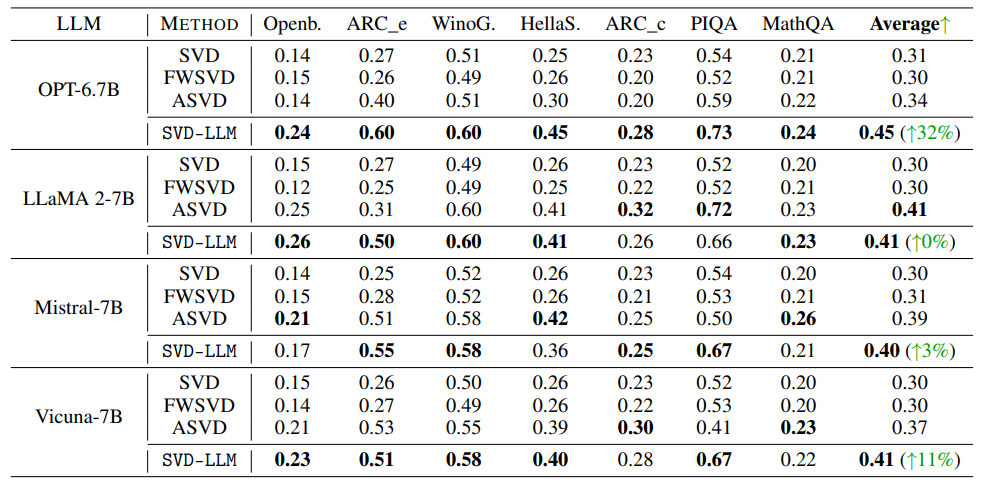
- 다양한 LLM에서 적용이 가능하다는 일반화를 하기 위한 실험.
3. 초거대 규모 LLM에서의 성능
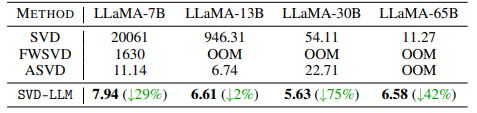
- 기존 기법들은 13B 모델부터 OOM 현상 발생하였지만, 본 방법은 일관된 성능을 기록.
4. 압축 속도 평가

- ASVD는 약 5.5시간이 걸리는 반면 SVD-LLM은 압축 과정을 15분만에 완료하여 32배 더 빠름.
Ablation Study
Sensitivity Study
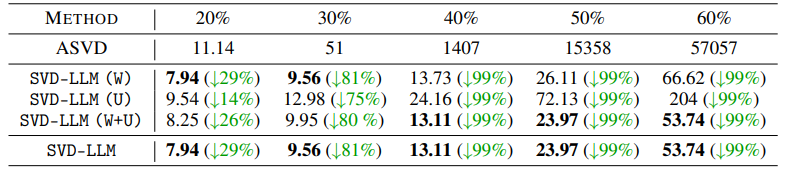
- W는 화이트닝만 수행, U 는 폐쇄형 W업데이트만 수행, W+U 는 둘 다 수행
- LLaMA2 7B 모델 기준 압축 비율이 높아질수록 W+U 가 매우 효과적임
Calibration Data Analysis
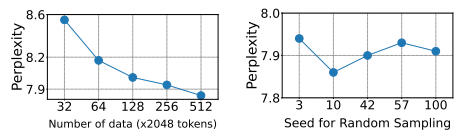
- 화이트닝된 데이터가 Compressing에 영향을 미치는지에 대한 결과
- 좌 - 화이트닝된 데이터 개수에 따른 Perplexity
- 우 - 화이트닝된 데이터 랜덤 샘플링 Seed에 따른 Perplexity
- 변경해도 최종 성능의 15% 미만의 작은 변동만을 기록.
4. Discussion
기타 등등
- 그 외에도 다른 Compression 기법들 (e.g. Pruning, Quantizing) 과 연계하였을 때 더욱 좋은 성능을 이끌어냈다고 함.
- 추론 속도의 향상에 대한 기록도 존재.
- 가중치가 압축이 되므로, 자동으로 KV Cache 또한 압축됨. KV 캐시의 압축은 타 Compression 기법과 다름.
Opinion
- SVD Compression 기법에 있어서 이론과 성능을 모두 잡은 최고의 SOTA라고 생각한다.
- 당연히 그에 마땅히 많은 Ablation Study 와 Evaluation 이 존재하여 탄탄한 주장을 대변한다.
- 아쉬운 점은 타 Compression 방법만 사용하였을 때에 대한 Ablation Study 가 없어서 아쉬웠다.
- SVD-LLM 과 Quantizing 의 결합, SVD-LLM 과 Pruning 결합에 대한 기록은 있으나, SVD-LLM 만 진행했을때, sota Quantizing 만 진행했을 때, sota Pruning만 진행했을 때 이 3가지에 대한 비교가 궁금하다.

고려대학교 인공지능학과 SLP Lab 석사과정생