[Paper Review] WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Paper Review
목록 보기
14/20
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
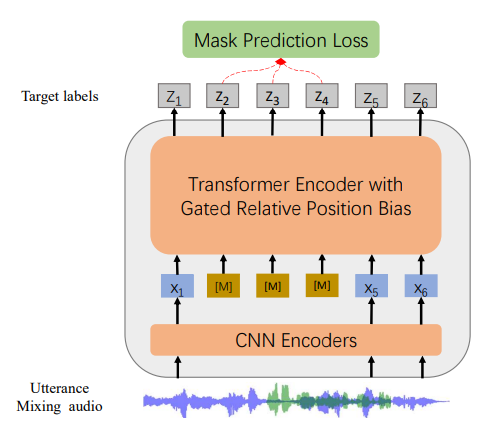
1. Background
기존 연구 동향
SSL
- 최근 NLP, ASR Task에서 SSL 방법을 매우 많이 활용하고 있음
특정 Task 대상 연구
- 기존 대부분의 SSL 연구는 특정 작업(e.g. ASR) 대상으로 모델을 학습시켰음
특정 Task 대상 연구의 한계
- ASR Task만을 목적으로 학습시키면 다른 음성 작업(e.g. Verification, Separation)에서는 성능이 좋지 못함
- 기존의 pretrained 모델들은 주로 LibriLight로 훈련되기에, 실제 사용과의 괴리가 있으며, 이는 데이터 편향과 직결됨
WavLM 제안
- (범용 사전학습 모델 제안) 다양한 음성처리 작업 수행이 가능한 사전학습 모델 제안
- (데이터 편향 문제 해결) 94000시간에 달하는 팟캐스트, 유튜브 등의 다양한 출처 데이터 사용
2. WavLM Information
Architecture
- Convolution Feature Encoder, Transformer Encoder 구조로 이루어져 있음
Convolution Feature Encoder
- 7개의 ConvBlock으로 구성됨
- 모두 512Channel을 가지며, stride=(5,2,2,2,2,2,2), kernel_size=(10,3,3,3,3,2,2) 로 세팅하여 Feature 뽑음
- Feature는 25ms 구간에서 20ms 구간씩 겹쳐서 뽑음
- 16000Hz = 1s 당 16000 sample = 1ms 당 16000/1000 => 16 sample, 25ms 당 400 sample, 20 ms 당 320 sample
# 입력 데이터 (64, 1, 16000)
batch_size, channels, num_samples = 64, 1, 16000
input_data = torch.randn(batch_size, channels, num_samples)
# 프레임 길이와 프레임 간 이동 계산
frame_length = 400 # 25ms
frame_step = 80 # 5ms (25ms - 20ms 겹침)
# 프레임 생성 (torch.unfold 사용)
input_data = input_data.squeeze(1) # (64, 16000)
frames = input_data.unfold(1, frame_length, frame_step) # (64, num_frames, frame_length)
frames = frames.permute(0, 2, 1) # (64, 400, 196) -> (64, 196, 400) # (batch, frame_len, frame_num)
print("프레임 데이터 shape:", frames.shape) # (64, 196, 400) # (batch, frame_len, frame_num)- 즉, Conv Encoder를 거친 출력이 의미하는 것은 25ms 구간에서 20ms로 겹친 오디오 특징을 의미
Transformer Encoder
-
Temporal Context Module로도 볼 수 있으며, self attention으로 모든 입력 Feature들간의 관계를 보고 동시에 모델링할 수 있음
-
Gated Relative Position Bias를 추가하여, 입력된 음성 Feature의 순서와 위치 정보를 더 잘 반영하도록 함
-
Relative Position Bias 에 Gating Mechanism을 추가하여, 입력 내용에 따라 위치 정보를 조정하도록 함
Gated Relative Position Bias
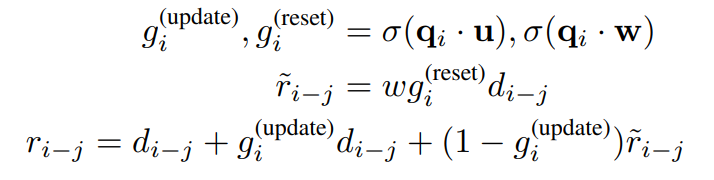
- 현재 timestep 의 Query 벡터에 trainable한 벡터를 각각 붙여서 sigmoid를 씌움으로써 Query에 영향력을 행사하는 Weight 로 만들어줌으로써, Update Gate, Reset Gate를 구현함
- Reset 시킬 값에 trainable한 Relative Position Bias 값을 먹여서 기존에 사용하던 Relative Position 값을 얼마나 잊을지/학습할지 학습할 수 있게 만들어줌
- 결국, 기존 Relative Position Bias(상대거리)를 얼마나 잊고 얼마나 학습할지도 학습하도록 하는 메커니즘
-
이렇게 상대거리를 Trainable하게 만들어주고, 본 논문에서는 거리가 클때/보통/작을때 3가지 Case로 나눠서 모델링을 수행하였음
Bucket Relative Position Embedding
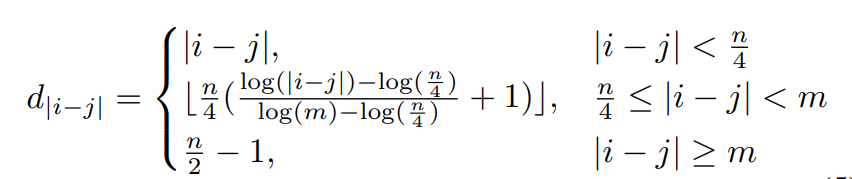
- n=320 이며, Relative Position Bias에 사용할 Embedding 개수
- m=800 으로, 최대 offset을 의미하며, 해당 값 이상으로는 모든 relative offset이 같은 임베딩에 할당됨
- 1번 경우 - 상대적 거리가 가까운 경우에는 크기 그대로 사용
- 2번 경우 - 상대적 거리가 중간 범위에 있는 경우이며, 이 경우에는 상대적 거리를 log scale로 mapping하여 bucket에 할당하여 사용(=group화하여, 해당 group에 속한 거리는 같은 값으로 mapping)
- 3번 경우 - 상대적 거리가 먼 경우(상대 거리가 max offset보다 큰 경우) - 모든 offset을 같은 임베딩에 할당하여, 고정된 값을 사용함 (n/2 - 1)
-
Masked Speech Denoising and Prediction
- 음성 신호의 일부를 masking하고, masking된 부분을 예측하면서 동시에 noise를 제거하면서 학습
Masked Seech Prediction
- Bert의 MLM에서 영감을 받음
- 음성 신호의 일부 구간을 무작위 masking한 다음, 모델이 masking된 부분을 예측하도록 함
- 전체 입력 신호의 15% 를 masking함
- masking된 입력 신호가 모델의 입력으로 주어지며, masking된 부분의 내용을 주변 문맥(context) 정보를 사용하여 예측해야 함
- (목표)이를 통해 모델은 음성의 문맥 또한 잘 학습하면서 feature를 압축하게 됨
Speech Denoising
- noise가 포함된 음성 신호에서 원래의 깨끗한 음성을 복원하도록 학습
- 배경 소음, 타 화자의 음성 등의 다양한 형태의 noise를 부여
- noise가 부여된 음성 신호가 모델의 입력으로 주어지며, 모델은 이 신호에서 원래 신호를 복원해야 함
- (목표) noise가 많은 환경에서도 정확하게 처리할 수 있게 됨
Pretrained Dataset
- LibriLight(60000시간, 오디오북 데이터셋, label X), GigaSpeech(10000시간, 팟캐스트, 유튜브 등 다양한 source, label X), VoxPoPuli(10000시간, 유럽 회의에서 기록된 다중 언어의 연설, label X) 사용
- 모두 label이 없는 데이터로, ssl로 학습하는데 사용됨
- 다양한 source, 언어, 억양, 발음을 포함하고 있어, 과적합 방지하고 일반화가 가능함
- 16Khz (16000Hz)의 Sampling Rate, 정규화 수행
3. Train Setting
Model Size
- 24개 Transformer Layer
- 각 layer는 1024 dim 가지며, 16개 attention head 가짐
Train Parameter
- 128 Batch Size
- 32000 step동안 Warm-up scheduler 사용, 초기 lr로 0.0015 사용
- AdamW optimizer
Environment
- 64개의 NVIDA V100 GPU로 2주동안 학습
4. Experimental Setting
Benchmark
- SUPERB Benchmark - 다양한 음성 작업에서 사전 학습된 모델을 평가하기 위한 standard testbed
- 5개 카테고리로, 15개 작업이 포함됨
- Content - 내용 인식 - PR(Phoneme Recognition), ASR, OOD-ASR(out of domain ASR), KS(Keyword Spotting), QbE(Query by Example)
- Speaker - 화자 관련 작업 - SID(Speaker Identification), ASV(Automatic Speaker Verification), SD(Speaker Diarization
- Semantics - 의미 분석 작업 - ST(Speech Trainslation), IC(Intent Classification), SF(Slot Filling)
- ParaL(Paralinguistics) - 준언어적 정보 분석 - ER(Emotion Recognition)
- Generation - 음성 생성 작업 - SE(Speech Enhancement), SS(Speech Synthesis), VC(Voice Conversion)
Setup
- SUPERB 구현과 동일하게 구현한 모델 사용
- Freeze WavLM Model
- Pretrain된 model에서 각 층에서 추출된 hidden state의 weighted sum을 추출하여 downstram model에 입력 (SUPERB의 정책에 따르는 것이며, 특정 층의 가중치가 높을수록 층의 기여도가 높은 것으로 봄)
5. Experiment
Overall
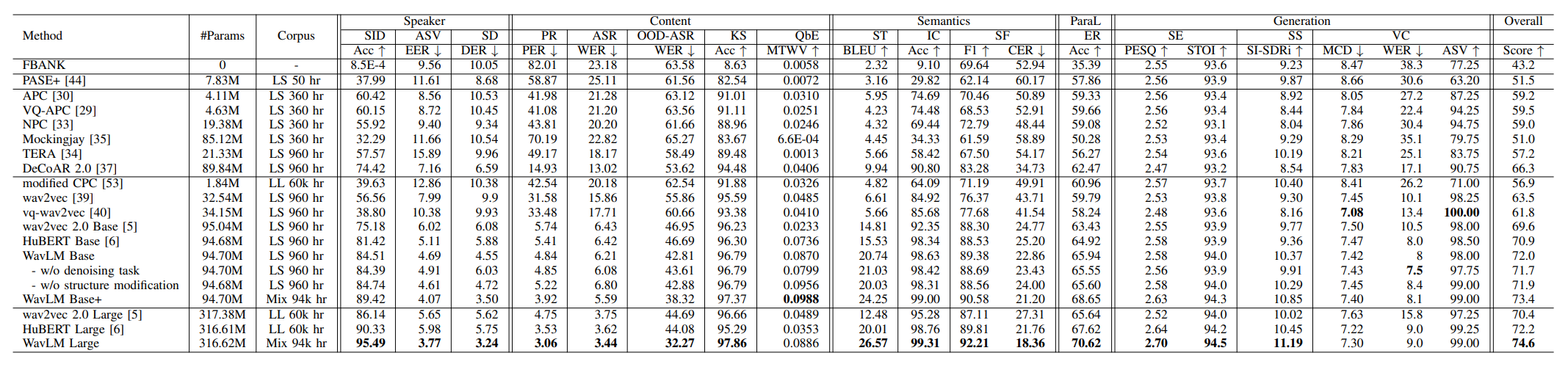
- HuBERT Large, wav2vec2.0 Large를 종합 점수에서 능가하여 sota 달성
- 특히 Speaker Diarization 작업에서 22.6% 높은 성능 보였는데, pretrain작업에서 speech overlapping을 하였기 때문
- ASV, OOD-ASR, IC, SF, ER 작업에서 큰 성능 향상을 보임
Speaker Verification
Define Task
- 음성 데이터와 참조 데이터가 같은 화자로부터 나왔는지 확인하는 Task
- Dataset은 오디오와 화자ID Pair 로 주어짐
- 두 음성이 동일한 화자로부터 나왔는지를 판단하는 Task
Dataset
- VoxCeleb1, VoxCeleb2 사용
Pre-Processing
- MUSAN, DNS, RIR Noise를 60% 확률로 부여함
- VAD는 적용하지 않음
Setup
- Downstram 모델로 ECAPA-TDNN 사용
- Audio에서 frame 단위로 추출된 feature를 input으로 하여 Speaker Representation을 추출하는 모델
- 해당 Experiment에서는 WavLM으로 Speech에서 음성 특징들을 추출한 후, 이것을 ECAPA-TDNN에 input으로 넣어 Speaker Represent를 뽑으면, shape은 (Speaker_num, Feature_dim) 으로 출력될 것이고, 화자 Lable은 없는 상태가 됨
- Segment 단위에서 추출한 Speaker Representation과 Reference에서 추출한 Speaker Representation의 유사도가 높으면 해당 Segment는 동일한 화자가 발화한 경우이고, 유사도가 낮으면 다른 화자가 발화한 경우
- 즉, Speaker Diarization과는 달리 Label정보가 필요 없음
Baseline
- Segment는 3초
- ECAPA-TDNN
- Vanilla ECAPA-TDNN 모델을 이용하여 Verification 수행
- Speech 에서 40차원 FBank Feature를 추출하여 모델을 학습하였으며, 25ms의 window와 10ms의 shift를 사용
- 165 Training Epoch
- HuBERT + ECAPA-TDNN
- HuBERT의 Representation을 ECAPA-TDNN 모델에 넣어 Speaker Representation을 뽑아서 학습
- Backbone을 Freeze시키고 ECAPA-TDNN을 20epoch 학습시킨 후, Backbone을 합친 Total Model을 5epoch 동안 FineTuning 수행
- WavLM + ECAPA-TDNN
- WavLM의 Representation을 ECAPA-TDNN 모델에 넣어 Speaker Representation을 뽑아서 학습
- Backbone을 Freeze시키고 ECAPA-TDNN을 20epoch 학습시킨 후, Backbone을 합친 Total Model을 5epoch 동안 FineTuning 수행
Result
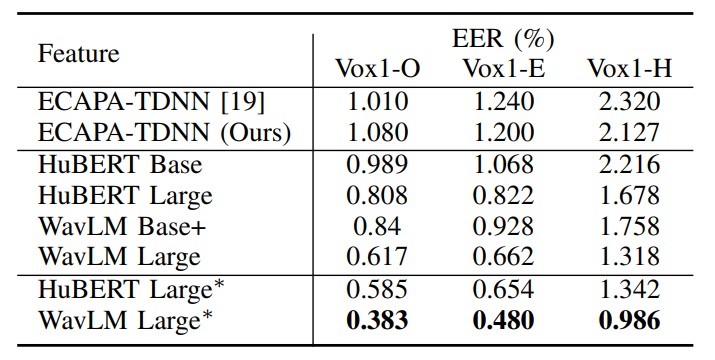
- VoxCeleb1 test dataset의 3가지 version으로 평가 수행
- 각각 Original, Extended, Hard를 의미하며, O/E/H 순으로 난이도가 오름
- ECAPA-TDNN을 원본 Style과 저자들이 구현한 Style을 비교하여 거의 동일한 성능을 보여줌으로써, 해당 Evaluation이 정확하게 이루어졌음을 보여었으며, 저자들이 구현한 ECAPA-TDNN을 사용하는데 당위성을 부여함
- Pretrained 모델에서 추출한 Feature를 사용하는 것이 FBank Baseline보다 좋은 성능을 보여줌
- 모든 면에서 WavLM이 SoTA 성능을 기록함
Speaker Diarization
Define Task
- Speech에서 각 frame당 하나 이상의 화자 Label을 할당하는 Task
- 같은 frame에서 여러 화자가 발화하는 경우 Speaker Overlap이라고 하며, 여러 화자 레이블을 할당함
- Speech에서 화자의 수를 예측하고, 각 frame에 대해 화자 Label을 할당하는 것이 목표
- 이 때, Speech에서 몇명의 화자가 있는지 모르기에, 모델은 이를 예측해야함
Dataset
- 학습 데이터로 Swithboard-2, Swithboard Celluar, NIST Speaker Recognition Evaluation 등의 다양한 단일 화자 음성 데이터를 사용하여 다중 화자 음성을 합성(Simulation) 하였음
- Simulated Data로, 총 7000시간 데이터 생성하여 학습하였음
- 평가 및 Fine Tuning 데이터로 CALLHOME 데이터셋 사용
- 500개의 다국어 전화 대화 session으로 구성되었으며, 각 session은 2~6명의 화자가 포함됨
Baseline
- Train 단계에서 Segment길이를 15초, Fine Tuning/Evaluation 단계에서는 30초 사용
- Kinoshita's EEND-Clustering
- Speech에서 frame 단위에서 Mel-FilterBank 특징을 추출하고, 특징들을 15초 단위로 묶어 Segment를 구성하고, 각 Segment에 대해 시간대를 기록하고 Speaker Representation을 뽑고 클러스터링(AHC)을 수행하여 Label 할당
- HuBERT + EEND-Clustering
- Mel-Filterbank 대신 Hubert의 Speech Representation을 EEND-Clustering의 input으로 사용
- WavLM + EEND-Clustering
- Mel-Filterbank 대신 Hubert의 Speech Representation을 EEND-Clustering의 input으로 사용
Result
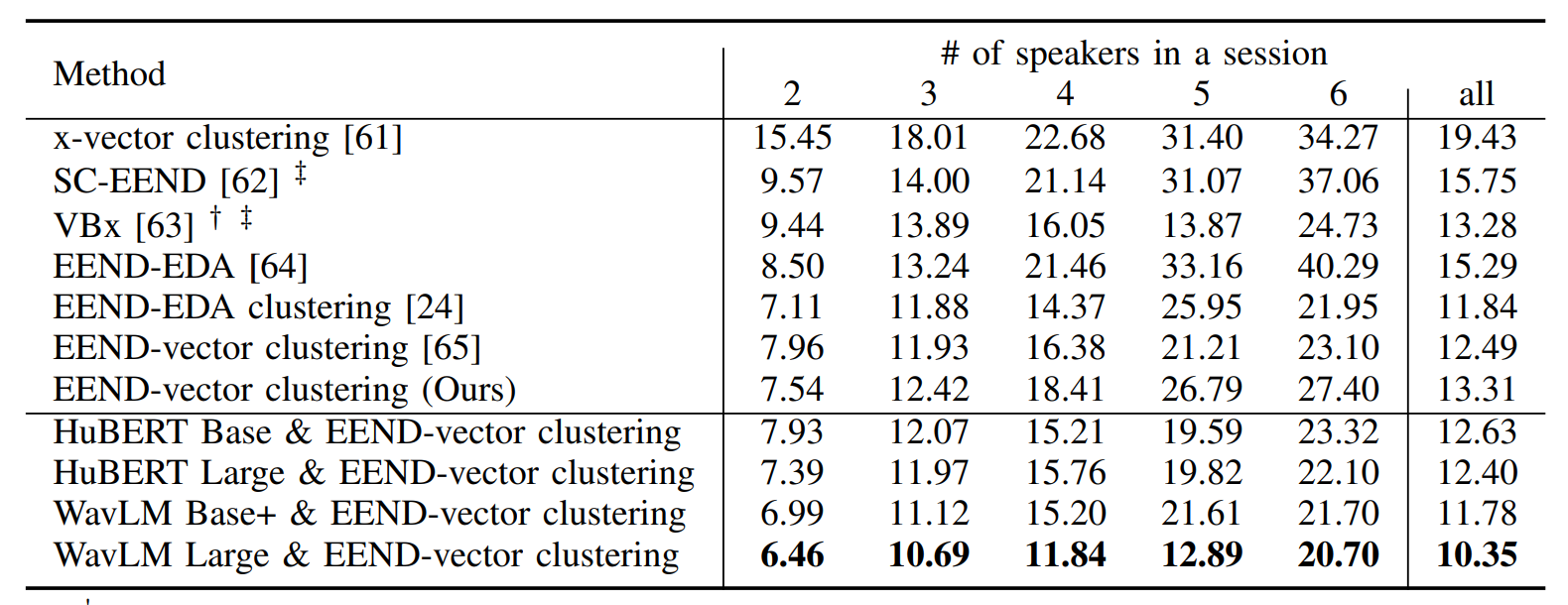
- 위 모델들은 Pretrained Representation을 사용하지 않고, frame별 특징을 input으로 하는 모델들
- 지표는 DER을 사용하였으며, WavLM이 SoTA를 보여주었음
- WavLM 평가에서 구현하였던 EEND-Clustering System이 원본보다 성능이 뒤떨어지는 것으로 보아, 실제 성능은 더 좋을 것으로 보임
Speech Separation
Define Task
- 중첩된 화자가 동시에 발화할 때, 혼합된 신호에서 개별 화자의 신호로 분리하는 Task
- Input으로 중첩 화자 데이터의 STFT, Output으로 중첩 화자 데이터의 STFT, 각 화자를 의미하는 Mask가 나오는 Task
Dataset
- 학습 데이터셋으로 219시간의 Simulated Data를 이용함
- WSJ1 데이터셋에서 무작위로 샘플링하여 사용
- WSJ1에서 한명 또는 2명의 화자를 무작위로 선택하고, simulated 된 RIR로 각 신호를 합성하고, 신호를 -5db~5db 사이의 energy 비율로 섞음
- 0-10db SNR로 Noise를 추가
- 평가 데이터로 LibriCSS를 사용
Baseline
- Sanyuan Chen's Conformer
- input으로 STFT, output으로 STFT, mask 에서 mask를 예측했음
- HuBERT + Conformer
- input으로 STFT 와 WavLM의 Represenation을 추가로 넣어서 mask를 예측
- WavLM + Conformer
- input으로 STFT 와 WavLM의 Represenation을 추가로 넣어서 mask를 예측
Result
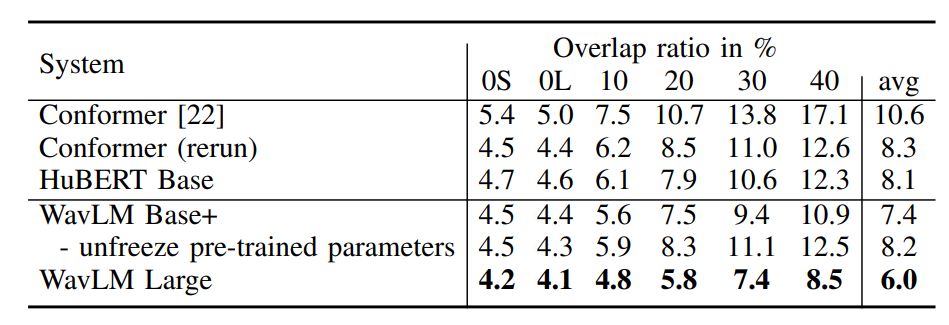
- sota 성능을 보여줌
- 공정한 평가를 위해 원본 system과 저자들이 구현한 system 의 차이를 보여줌
- pretrain parameter를 freeze하지 않으면 성능이 안좋아졌는데, 이는 freeze시키지 않으면 모델이 과적합 가능성이 있다고 보았음
Speech Recognition
Define Task
- 음성 신호에 대응하는 Transcription 텍스트를 생성하는 Task
Dataset
- Fine Tuning 데이터셋으로 1시간 10시간, 100시간, 960시간 4가지 경우 결과 뽑음
- 1시간 - LibriLight의 train-1h 짜리 사용
- 10시간 - LibriLight의 train-10h 사용
- 100시간 - LibriSpeech의 train-clean-100 사용
- 960시간 - 전체 LibriSpeech 사용
- 평가 데이터셋으로 LibriSpeech의 test-clean, test-other 사용
Baseline
- pretrained 모델로 뽑힌 Representation은 (batch, segment_num(=seq_len), feature_dim)
- (b,s,d) 에서 (b,s,vocab) 으로 선형변환 수행후, CTC Loss를 통해 텍스트와 speech의 align을 맞춰서 학습함
- loss = nn.CTCLoss(logits, targets, input_len, target_len)
- logits - (s,b,v)
- targets - (text_mapped,) - 1D tensor로, 모든 batch의 target sequence가 연결된 flat한 형태
- input_len - (b,) - 1D tensor로, 각 batch의 sequence_lengh
- e.g) logits가 (s,b,v) = (50,2,38) 라면, input_len은 [50,50] 이여야 함
- output_len - (b,) - 1D tensor로, 각 batch의 target sequence_lengh
- e.g) targets가 [1,43,6,23,12,8476,45] 이고, 1,45,6 까지가 첫번째 batch이고 나머지가 두번쨰 batch라면, [3,4] 여야 함
- wav2vec2.0 + Linear + CTC Loss
- HuBERT + Linear + CTC Loss
- WavLM + Linear + CTC Loss
Result
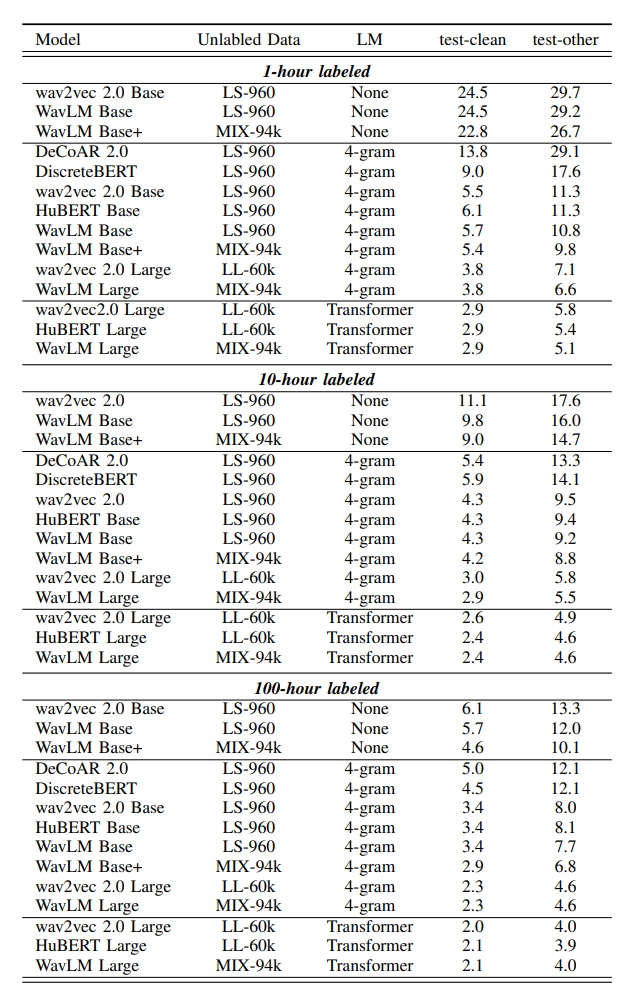
- 1h, 10h, 100h 모두에서 WavLM에서 사용한 MIX-94k 데이터셋으로 Pretrain 시켰을때 성능이 가장 좋았음(가장 낮은 WER)
- WavLM이 SoTA
- 후처리 과정으로 None, 4-gram, Transformer를 사용하였는데, Transformer 언어 모델을 사용하였을 때 WER가 가장 낮은 것으로 보아, 언어 모델로 후처리하는 것이 WER을 낮추는데 중요한 역할을 하였음
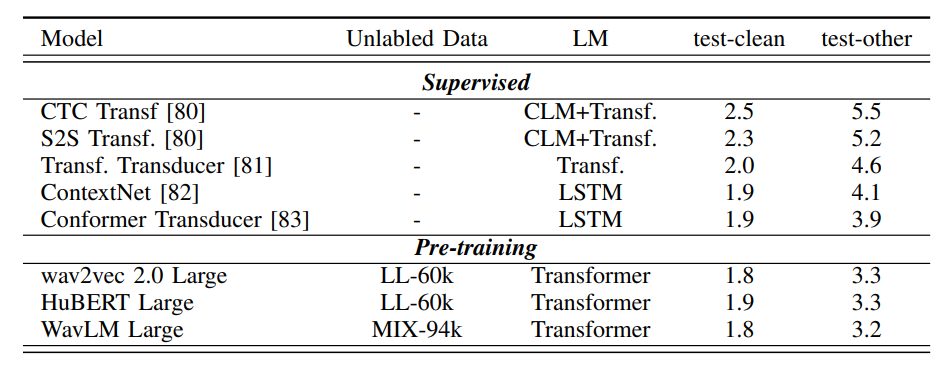
- 지도학습에서는 전반적으로 CTC Loss나 다른 Loss를 사용한 것보다 Transducer Loss를 사용한 것이 성능이 좋았으며, 후처리 언어 모델로 Transformer나 LSTM을 사용하는 것이 좋았음
- 대부분의 경우, Transformer 언어 모델로 후처리하는것이 성능이 좋았음
- 처음부터 Supervised로 학습하는 것보다, SSL로 학습하고, 이후에 CTC로 FT하는 것이 성능이 더 좋음

고려대학교 인공지능학과 SLP Lab 석사과정생