[Paper Review] Towards Good Practices for Missing Modality Robust Action Recognition
Paper Review
목록 보기
15/20
Towards Good Practices for Missing Modality Robust Action Recognition
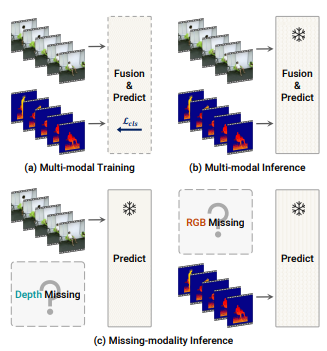
1. Background
기존 연구 동향
Action Recognition (행동 인식)
- 행동인식이란, 비디오 데이터로부터 특정 행동을 인식하는 모델임
- 다양한 모달리티(RGB, Depth, Infrared 등) 데이터를 받아 최종 행동을 예측하는 Task
- 기존 다중 모달리티 기반 행동인식 연구는 학습 및 추론 단계에서 동일한 모달리티를 사용하는 것을 전제로 함. 즉, 학습할 때 모달리티를 3개를 이용하여 학습했으면, 추론할 때에도 모달리티를 3개를 이용해야 함.
기존 연구의 한계
- 실생활에서는 다양한 이유로 인해 모달리티가 결여되는 상황이 있으며, 이러한 경우에는 성능 저하가 매우 큼
- e.g. 센서 고장, 보안 문제 등
- 추론 시 특정 모달리티가 없어도 성능을 유지할 수 있도록 하는 접근법이 필요함
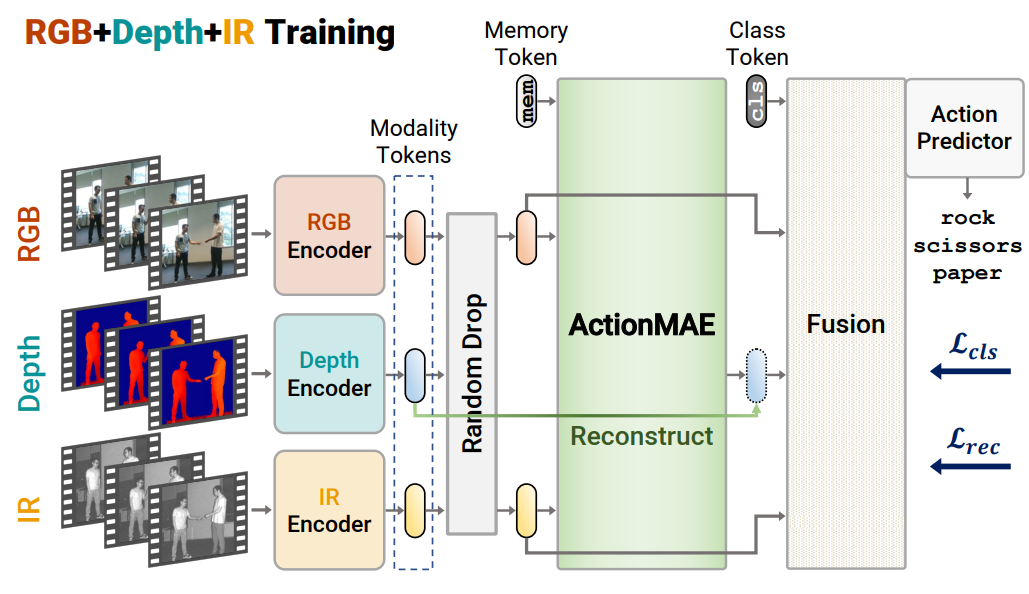
ActionMAE 제안
- (모달리티 결여 시에도 성능 유지 가능) 모달리티를 drop시키면서 학습시켜서 모달리티 결여 시에도 Robust한 성능 기록
2. Architecture
Modules
Spatial-Temporal Encoder
- (Spatial) 각 frame (비디오의 개별 이미지)에서 공간적인 특징을 추출
- (Temporal) 여러 frame 사이의 시간적 변화를 분석하는 단계이며, transformer를 사용하였음

- Time Encoder, Fusion 기법을 고정시켜서 Spaitial Encoder의 성능만 비교하였을 때, ResNet34를 사용하는 것이 가장 좋은 성능을 보였고, Saptial Encoder로 ResNet34 선택하였음
Fusion Unit
- Encoder를 통과한 Feature들을 어떻게 Fusion하여 최종 예측을 수행할 것인지
- Fusion 방법으로 Sum, Concat, Transformer 로 Test 수행
- Sum : ActionMAE를 통해 나온 모든 모달리티 임베딩 벡터들 값들을 더한 값들로 Classification 수행
- Concat : ActionMAE를 통해 나온 모든 모달리티 임베딩 벡터들 값들을 쭉 이어붙인 값들로 Classification 수행
- Transformer : ActionMAE를 통해 나온 모든 모달리티 임베딩 벡터들 값들을 쭉 이어붙여서 통으로 Transformer에 태워서 나온 값들로 Classification 수행
- Fusion 방법으로 Sum, Concat, Transformer 로 Test 수행
최종 구조
- Encoder(Spatial+Temporal) - ActionMAE - Fusion Module 의 구조
- ResNet34+Transformer - ActionMAE - Transformer 로 이루어져 있음
Augmentation
- overfitting 문제를 해결하기 위한 목적으로 Augmentation 기법을 적용하였고, 어떤 방법을 사용하면 좋을지에 대한 실험을 진행한 후, 최종 Augmentation 기법을 적용하였음
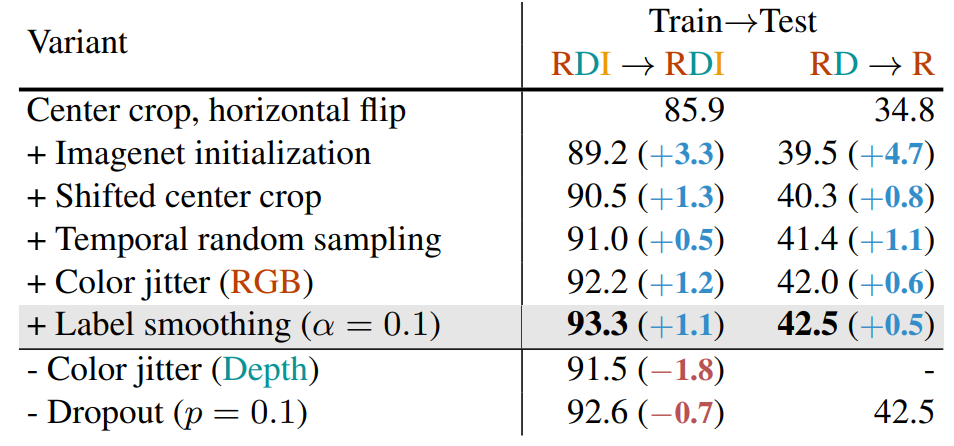
- 최종 모델 (ResNet34+Transformer + ActionMAE + Transformer)에서 일반화 성능을 평가한 결과이며, Center Crop, Horizontal flip, Imagenet init, Shifted center crop, temporal random sampling, color gitter, label smoothing을 적용하였을 때가 가장 좋은 성능을 보였고, 해당 augmentation 기법들을 적용하였음
Fusion Unit
- 서로 다른 모달리티를 어떻게 결합할지에 대한 방법
- Sum, Concat, Transformer가 존재
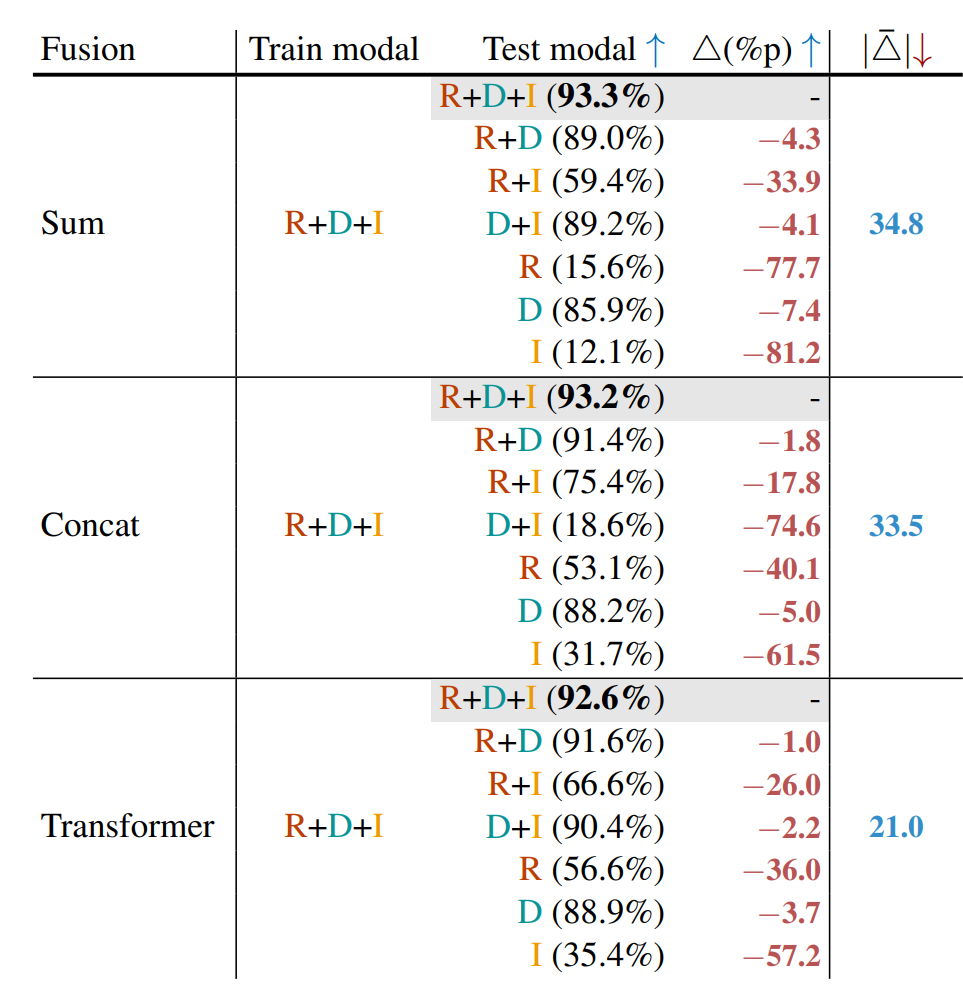
- 전체 데이터로 학습 시켰고, 다른 경우의 빈 모달리티로 예측을 수행하였을 때의 성능 저하량의 평균값이 Transformer에서 가장 적었으며, 최종 Fusion Unit으로 결정하였음
3. Method - ActionMAE
- 모달리티 결여 상황을 처리하기 위한 모듈
- 관찰된 모달리티로부터 결여된 모달리티를 예측하는데에 focus 맞춤
- 관찰된 모달리티를 Latent Representation으로 만들고, 이를 기반으로 결여된 모달리티를 예측하여 재구성
- Transformer encoder-decoder 구조에서 잔존 모달리티 정보를 바탕으로 결여된 모달리티를 복원하는 모델
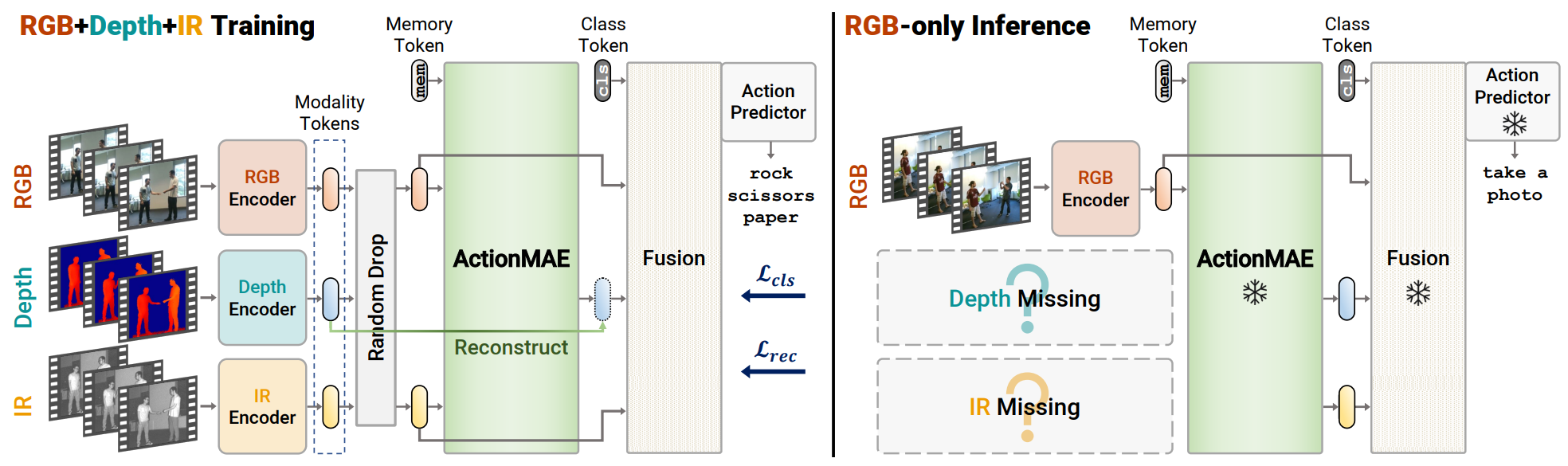
Training Recipe
- Random Drop 을 통해 입력 모달리티 중 일부를 제거하고 나머지 모달리티로만 학습 수행
- Loss는 Reconstruction Loss + Classification Loss를 합쳐서 사용
4. Result
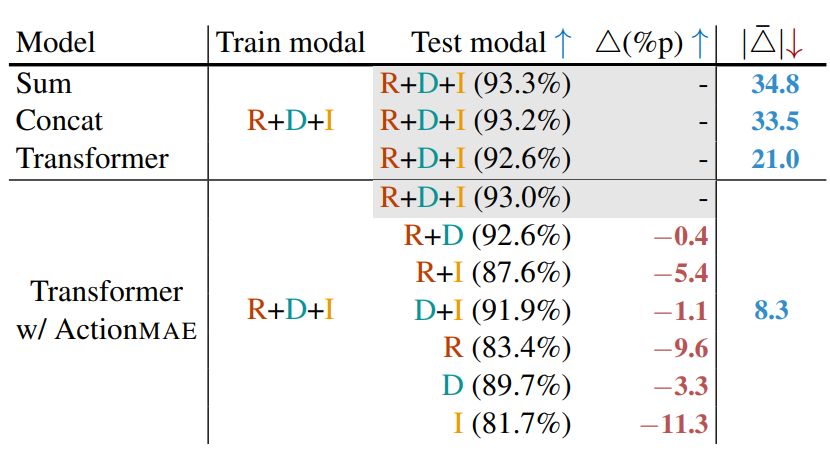
- ActionMAE 모듈을 추가하였을 때와 추가하지 않았을 때의 성능 비교
- ActionMAE 모듈을 달았을 때, 빈 모달리티 예측을 포함하였으며, 높은 Robustness와 정확도를 보여줌

고려대학교 인공지능학과 SLP Lab 석사과정생