GOAL
Prometheus 를 AWS k8s cluster 환경에 배포한다.
이전 포스팅에서 EFS를 사용한 pv,pvc까지 테스트하였다.
해당 포스팅에서는 프로메테우스를 배포해본다.
프로메테우스 서버 파드 배포과정에서 직면하게 된 에러를 고치는 과정이 본 포스팅의 핵심이다.
helm chart 수정 후 프로메테우스 배포
helm을 사용하여 prometheus를 배포한다. 이 때, 앞에서 만든 pv,pvc를 prometheus-server에 연결해줘야 하므로 helm chart를 수정해야한다.
helm fetch prometheus-community/prometheus
tar zvxf prometheus-15.18.0.tgzvalue.yaml을 알맞게 수정
k apply -f pv.yaml
k apply -f pvc.yaml
helm install prometheus ./prometheus
🤦♂️prometheus-server STATUS == CrashLoopBackOff
Kubernetes CrashLoopBackOFF 란?
CrashLoopBackOff는 Kubernetes에서 첫 번째 컨테이너를 실행할 때 발생할 수 있는 일반적인 오류이다. 포드가 시작되지 못했고, Kubernetes가 포드를 다시 시작하려고 시도했으며, 계속해서 실패했음을 나타낸다.
기본적으로 포드는 항상 restart 정책을 실행한다. 즉, 실패 시 항상 restart 한다. 포드 템플릿에 정의된 restart 정책에 따라 Kubernetes가 포드를 여러 번 다시 시작하려고 할 수 있다.
포드가 다시 시작될 때마다 쿠버네티스는 "백오프 지연"으로 알려진 더 길고 긴 시간을 기다린다. 이 프로세스 중에 Kubernetes는 CrashLoopBackOff 오류를 표시한다.
첫 번째 해결 방법 resource insufficient
worker1,2 의 available disk를 확인해보니 1.3, 1.4 Gi 였다. 각 볼륨을 8 -> 30으로 늘려서 사용해본다.
그래도 변화 없다.
두 번재 해결 방법 container log
⚡ root@master /etc k logs prometheus-server-5d4d6d64f4-82wj4 -c prometheus-server-configmap-reload
2022/11/16 01:48:21 Watching directory: "/etc/config"
⚡ root@master /etc k logs prometheus-server-5d4d6d64f4-82wj4 -c prometheus-server
level=info ts=2022-11-16T01:59:15.551Z caller=main.go:337 msg="Starting Prometheus" version="(version=2.19.0, branch=HEAD, revision=5d7e3e970602c755855340cb190a972cebdd2ebf)"
level=info ts=2022-11-16T01:59:15.551Z caller=main.go:338 build_context="(go=go1.14.4, user=root@d4cf5c7e268d, date=20200609-10:29:59)"
level=info ts=2022-11-16T01:59:15.551Z caller=main.go:339 host_details="(Linux 5.15.0-1022-aws #26-Ubuntu SMP Thu Oct 13 12:59:25 UTC 2022 x86_64 prometheus-server-5d4d6d64f4-82wj4 (none))"
level=info ts=2022-11-16T01:59:15.551Z caller=main.go:340 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2022-11-16T01:59:15.551Z caller=main.go:341 vm_limits="(soft=unlimited, hard=unlimited)"
level=error ts=2022-11-16T01:59:15.554Z caller=query_logger.go:87 component=activeQueryTracker msg="Error opening query log file" file=/efs/prometheus/server/queries.active err="open /efs/prometheus/server/queries.active: permission denied"
panic: Unable to create mmap-ed active query logprometheus-server-configmap-reload 는 특별한 점이 없다.
prometheus-server 는 err="open /efs/prometheus/server/queries.active: permission denied" 에러가 뜬다. 이 문제 때문에 crushLoopBackOff가 발생하는지는 모르겠지만 일단 해결해본다.
chown 1000:1000 /efs/prometheus/server
해결되지 않는다.
세 번째 해결 방법 Persistent Volume securityContext
configuration 파일에서 runAsUser 필드는 포드의 컨테이너에 대해 모든 프로세스가 runAsUser에 명시된 user ID로 실행되도록 지정한다.
runAsGroup 필드는 포드 컨테이너 내의 모든 프로세스에 대한 기본 group ID를 지정한다. 이 필드를 생략하면 컨테이너의 기본 그룹 ID는 0 이 된다.
runAsGroup 이 지정된 경우 생성된 모든 파일은 runAsUser와 runAsGroup에 의해 소유된다.
fsGroup 필드가 지정되면 컨테이너의 모든 프로세스도 보조 그룹 fsGroup ID의 일부가 된다. 볼륨 및 해당 볼륨에 생성된 모든 파일의 소유자는 fsGroup이 된다.
helm으로 설치한 values.yaml 파일의 securityContext는 다음과 같다.
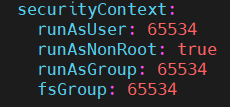
runAsUser, runAsGroup, fsGroup을 모드 0(root)로 바꿔준다.
Error: container's runAsUser breaks non-root policy (pod: "prometheus-server-7b46689765-z6l7s_default(eb37467d-04b4-4480-9fdf-37a2119f3b6c)", container: prometheus-server)
container의 runAsUser는 루트로 하면 안된다. 따라서 1000으로 바꿔준다.
마찬가지로 해결되지 않는다.
네 번째 해결 방법 Persistent Volume Access Mode
ReadWriteOnce
the volume can be mounted as read-write by a single node. ReadWriteOnce access mode still can allow multiple pods to access the volume when the pods are running on the same node.
ReadOnlyMany
the volume can be mounted as read-only by many nodes.
ReadWriteMany
the volume can be mounted as read-write by many nodes.
ReadWriteOncePod
the volume can be mounted as read-write by a single Pod. Use ReadWriteOncePod access mode if you want to ensure that only one pod across whole cluster can read that PVC or write to it. This is only supported for CSI volumes and Kubernetes version 1.22+.
pv.yaml, pvc.yaml ReadWriteOnce -> ReadWriteMany로 변경
마찬가지로 안된다.
다섯 번째 해결 방법: Instance-Profile Check
이전에 만든 role과 policy는 확인했을 때 EFS에 대한 엑세스가 맞게 되어있는 것 같다.
모든 노드에 인스턴스 프로필을 생성하고 그 인스턴스 프로필이 권한이 있는 것인데 어떻게 연결해주는건지 다시 확인할 필요성을 느꼈다.
⚡ root@master ~/prometheus aws ec2 describe-iam-instance-profile-associations연결되어있지 않았다... 😂
#인스턴스프로필 list 확인
aws iam list-instance-profiles
aws ec2 associate-iam-instance-profile --iam-instance-profile Name="" --instance-id "" 로 연결. 세 가지 프로필 모두 연결해주면 된다.
aws ec2 describe-iam-instance-profile-associations 로 확인 가능하다인스턴스 프로필 연결후에도 마찬가지로 에러가 해결되지 않는다.
여섯 번째 방법 코드 뜯어보기
Go라서 봐도 모르겠으니 일단 넘어간다.
일곱 번째 방법 prometheus remote storage Intergration 확인
원격 스토리지 결합에 추가 설정이 있을 수 있다.
프로메테우스의 로컬 스토리지는 단일 노드의 확장성과 내구성에 한계가 있다. 프로메테우스 자체에서 클러스터된 스토리지를 해결하려고 시도하는 대신 프로메테우스는 원격 스토리지 시스템과 통합할 수 있는 인터페이스를 제공한다.

프로메테우스는 세 가지 방식으로 원격 스토리지 시스템과 동합된다.
- 표준화된 형식으로 원격 URL에 수집하는 샘플을 작성할 수 있다.
- 다른 프로메테우스 서버에서 표준화된 형식으로 샘플을 수신할 수 있다.
- 표준화된 형식으로 원격 URL에서 샘플 데이터를 읽을 수 있다.
프로메테우스에서 원격 스토리지 통합을 구성하는 방법에 대한 자세한 내용은 프로메테우스 구성설명서의 원격 쓰기 및 원격 읽기 섹션을 참조.
하지만, 온프레미스 환경에서 NFS-server를 사용한 remote storage 연결이 된 점을 생각해보면 이 부분은 helm 으로 설치하는 과정에서 제대로 설정되어있을 수 있다. 물론, EFS 를 사용할 때 다를 수 있지만 알아보는 우선순위를 미룬다.
여덟 번째 방법 AWS - Prometheus 호환 확인
추가적인 설정이 필요할 수 있다.
아홉 번째 방법 aws-csi-driver-controller
현재 worker1 에만 aws-csi-driver-controller pod가 2대 띄워져있다. 이게 문제가 되는지 알아본다.
마지막 방법 prometheus hardway
helm 으로 설치하니 어떻게 구성되어있는지 몰라 디버깅이 어렵다. 수동으로 직접 설치해본다.
해결
If a parent directory has no execute permission for some user, then that user cannot stat any subdirectories regardless of the permissions on those subdirectories.
세 번째 해결 방법에서 PV securityContext를 수정해주고,
chown 1000:1000 /efs/prometheus/server 를 해주었다. 하지만 해결되지 않았는데 위의 코멘트 처럼 상위 디렉토리에는 권한이 없기 때문이다.
chown 1000:1000 /efs 를 해주니 해결 되었다.
배포는 values.yaml 을 직접 수정하지않고 아래 방법으로 한다.
✘ ⚡ root@master ~/prometheus
helm install prometheus prometheus-community/prometheus \
--set pushgateway.enabled=True \
--set alertmanager.enabled=True \
--set nodeExporter.tolerations[0].key=node-role.kubernetes.io/master \
--set nodeExporter.tolerations[0].operator=Exists \
--set nodeExporter.tolerations[0].effect=NoSchedule \
--set server.persistentVolume.existingClaim="prometheus-server" \
--set server.securityContext.runAsGroup=1000 \
--set server.securityContext.runAsUser=1000 \
--set server.service.type="LoadBalancer" \
--set server.storage.tsdb.path="/efs/perometheus/server"교훈

프로메테우스를 aws ec2에서 사용하려면 위 서비스를 사용해야하는가 싶은 생각도 들었다.
Reference
- https://helm.sh/ko/docs/intro/using_helm/: helm
- https://komodor.com/learn/how-to-fix-crashloopbackoff-kubernetes-error/: crashLoopbackoff
- https://kubernetes.io/ko/docs/concepts/configuration/configmap/#configmap-immutable
- https://github.com/prometheus/prometheus/issues/5976
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/
- https://prometheus.io/docs/prometheus/2.37/storage/#overview
- https://askubuntu.com/questions/812513/permission-denied-in-777-folder
- https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
