
Index
- Slack 설정
- AlertManager 구성하기 1 - Node Labeling
- AlertManager 구성하기 1 - writing comfigMap
- AlertManager 구성하기 1 - writing rules
- Trouble 1 - 생각도 못한 에러: zsh
- Trouble 2 - CrashLoopBackOff
- Trouble 3 - 뭐가 문제인지 모르겠지만 알람이 작동하지 않는다. values.yml 갈아 엎기
- Alering 작동 성공, 테스트
- Trouble 4 - slack webhook은 되지 않음
- 테스트 성공. 시간이 걸린 요인 분석
Goal
프로메테우스 Alert 시스템을 구축한다.
AlertManager 배포 후 테스트까지 진행한다.
1. Slack 설정
alert message를 받을 앱으로는 Slack을 선택한다.
-
slack worksapce 및 채널 생성
-
worksapce에서 설정 및 관리 -> 앱 관리
-
검색창에 수신 웹 훅 검색 -> slack에 추가

-
웹 훅 받을 채널 지정 -> 웹훅 URL 메모
Slack에서의 초기 설정은 끝
AlertManager 구성하기
2. 구성하기 전 Node labeling
Why?
프로메테우스 컴포넌트들을 마스터 노드에 띄우기 위함.
Worker 노드에는 다른 파드들이 올라간다. 그렇기 때문에 특정 상황에서는 워커노드에 많은 파드들이 올라가며 노드의 불안정성이 커질 수 있기 때문에 프로메테우스 컴포넌트를 마스터 노드에 띄운다.
Label 설정
쿠버네티스는 노드를 라벨로 관리할 수 있다.
- label 조회
kubectl get nodes --show-labels
- node에 label 추가
kubectl label nodes [node_name] [key]=[value]
kubectl label nodes ip-10-0-3-65.ap-northeast-2.compute.internal key=worker
kubectl label nodes ip-10-0-3-70.ap-northeast-2.compute.internal key=worker
kubectl label nodes ip-10-0-3-181.ap-northeast-2.compute.internal key=master3. alertmanager configmap 작성
alertmanager 설정을 컨피그맵으로 만든다.
vi alert-notifier.yaml
apiVersion: v1
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: default
labels:
app: prometheus
app.kubernetes.io/managed-by: Helm
chart: prometheus-16.0.0
component: alertmanager
heritage: Helm
release: prometheus
name: prometheus-notifier-config
namespace: default
data:
alertmanager.yml: |
global:
slack_api_url: Slack-URL #여기에 웹 훅 URL을 넣으면 된다.
receivers:
- name: slack-notifier
slack_configs:
- channel: #monitoring
send_resolved: true
title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}'
text: >-
*Description:* {{ .CommonAnnotations.description }}
route:
group_wait: 10s
group_interval: 1m
repeat_interval: 5m
receiver: slack-notifierk apply -f alert-notifier.yaml
컨피그맵 어플라이 후 helm으로 install 한다.
앞의 배포와 마찬가지로 values.yaml을 참고해 적절하게 overwrite해준다.
helm install prometheus prometheus-community/prometheus \
--set pushgateway.enabled=True \
--set alertmanager.enabled=True \
--set nodeExporter.tolerations[0].key=node-role.kubernetes.io/master \
--set nodeExporter.tolerations[0].operator=Exists \
--set nodeExporter.tolerations[0].effect=NoSchedule \
--set alertmanager.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set alertmanager.tolerations[0].key=node-role.kubernetes.io/master \
--set alertmanager.tolerations[0].operator=Exists \
--set alertmanager.tolerations[0].effect=NoSchedule \
--set alertmanager.nodeSelector.key=master \
--set alertmanager.configMapOverrideName=notifier-config \
--set alertmanager.securityContext.runAsGroup=1000 \
--set alertmanager.securityContext.runAsUser=1000 \
--set alertmanager.service.type="LoadBalancer" \
--set alertmanager.persistentVolume.existingClaim="prometheus-alertmanager" \
--set alertmanager.mountPath="/efs/perometheus/alertmanager" \
--set server.tolerations[0].key=node-role.kubernetes.io/master \
--set server.tolerations[0].operator=Exists \
--set server.tolerations[0].effect=NoSchedule \
--set server.nodeSelector.key=master \
--set server.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set server.persistentVolume.existingClaim="prometheus-server" \
--set server.mountPath="/efs/perometheus/server" \
--set server.securityContext.runAsGroup=1000 \
--set server.securityContext.runAsUser=1000 \
--set server.service.type="LoadBalancer" \
--set server.storage.tsdb.path="/efs/perometheus/server"Overwrite Summary
prometheus-alertmanager, prometheus-server는 마스터 노드에 올린다.
nodeExporter는 모든 노드에 올린다.
alertmanger, server는 efs에 마운트한다.
nlb type으로 alertmanager, server를 외부에 노출한다.
SecurityContext 설정을 해준다.(runAsUser, runAsGroup)
4. 프로메테우스에서 알람 규칙 만들기
얼럿매니저를 배포한다고 얼럿이 가는게 아니다. 얼럿이 가기 위한 규칙을 설정해줘야 한다.
인스턴스가 다운 되었을 때 알람을 주는 룰을 만들어본다.
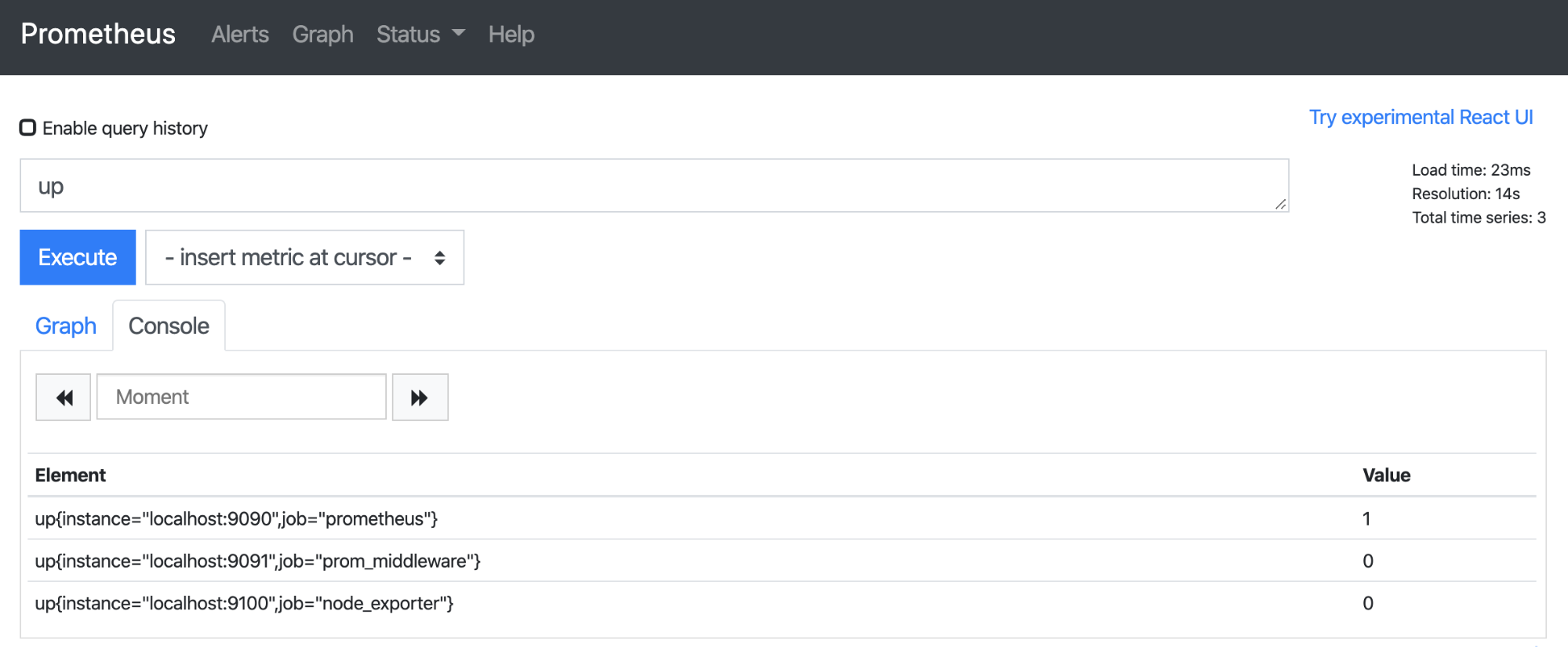
vi rules.yaml
groups:
- name: AllInstances
rules:
- alert: InstanceDown
# Condition for alerting
expr: up == 0
for: 1m
# Annotation - additional informational labels to store more information
annotations:
title: 'Instance {{ $labels.instance }} down'
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute.'
# Labels - additional labels to be attached to the alert
labels:
severity: 'critical'인스턴스 중 하나라도 1분 동안 down 될 경우 알람이 발동된다.
rules.yml 파일을 alert-notifier.yml에 연결하고 알람 구성을 추가해야한다.
apiVersion: v1
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: default
labels:
app: prometheus
app.kubernetes.io/managed-by: Helm
chart: prometheus-16.0.0
component: alertmanager
heritage: Helm
release: prometheus
name: prometheus-notifier-config
namespace: default
data:
alertmanager.yml: |
global:
slack_api_url: https://hooks.slack.com/services/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 #여기에 웹 훅 URL을 넣으면 된다.
receivers:
- name: slack-notifier
slack_configs:
- channel: #monitoring
send_resolved: true
title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}'
text: >-
*Description:* {{ .CommonAnnotations.description }}
route:
group_wait: 10s
group_interval: 1m
repeat_interval: 5m
receiver: slack-notifier
# Rules and alerts are read from the specified file(s)
rule_files:
- rules.ymlk apply -f alert-notifier.yml
rule을 추가한 컨피그맵을 재 배포 했으니 프로메테우스를 재설치 한다.
5. Unexpected Trouble - zsh
이전부터 helm install 을 해줄 때 아래와 같은 에러가 뜨며 설치가 되지 않았다.
zsh: no matches found: nodeExporter.tolerations[0].key=node-role.kubernetes.io/master그러다 어느 순간 해결이 되었는데, 알고보니 AWS EC2 인스턴스를 날리고 다시 만드는 과정에서 zsh을 설치하기 번거로워 기본 값인 bash를 써서 된 것이었다.
즉, zsh에서 아래 설치가 진행되지 않는다. 쉘의 차이로 설치가 되지 않았을거라는 생각을 하지 못해서 values.yaml 파일을 확인하며 헤맸다.
결과적으로 zsh 은 square-bracket 을 쓸 때 아래와 같이 back slash를 넣어줘야 한다.
helm install prometheus prometheus-community/prometheus \
--set pushgateway.enabled=True \
--set alertmanager.enabled=True \
--set nodeExporter.tolerations\[0\].key=node-role.kubernetes.io/master \
--set nodeExporter.tolerations\[0\].operator=Exists \
--set nodeExporter.tolerations\[0\].effect=NoSchedule \
--set alertmanager.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set alertmanager.tolerations\[0\].key=node-role.kubernetes.io/master \
--set alertmanager.tolerations\[0\].operator=Exists \
--set alertmanager.tolerations\[0\].effect=NoSchedule \
--set alertmanager.nodeSelector.key=master \
--set alertmanager.configMapOverrideName=notifier-config \
--set alertmanager.securityContext.runAsGroup=1000 \
--set alertmanager.securityContext.runAsUser=1000 \
--set alertmanager.service.type="LoadBalancer" \
--set alertmanager.persistentVolume.existingClaim="prometheus-alertmanager" \
--set alertmanager.mountPath="/efs/perometheus/alertmanager" \
--set server.tolerations\[0\].key=node-role.kubernetes.io/master \
--set server.tolerations\[0\].operator=Exists \
--set server.tolerations\[0\].effect=NoSchedule \
--set server.nodeSelector.key=master \
--set server.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set server.persistentVolume.existingClaim="prometheus-server" \
--set server.mountPath="/efs/perometheus/server" \
--set server.securityContext.runAsGroup=1000 \
--set server.securityContext.runAsUser=1000 \
--set server.service.type="LoadBalancer" \
--set server.storage.tsdb.path="/efs/perometheus/server" \
--set serverFiles.alerting_rules.yml=alerting_rules.yml \6. Trouble: CrashLoopBackOff
재설치 후 pod describe 해보니 crashLoopBackOff에 갇혀있다.
root@ip-10-0-3-181:~/prometheus# k get pod
NAME READY STATUS RESTARTS AGE
grafana-645d644bf6-jr7mw 1/1 Running 0 10h
prometheus-alertmanager-7f88dfcffb-pfrfx 1/2 CrashLoopBackOff 5 3m27s
이런경우 컨테이너 로그를 보면 자세히 알 수 있다.
root@ip-10-0-3-181:~/prometheus# k logs prometheus-alertmanager-7f88dfcffb-pfrfx -c prometheus-alertmanager
ts=2022-11-21T12:57:00.736Z caller=main.go:231 level=info msg="Starting Alertmanager" version="(version=0.24.0, branch=HEAD, revision=f484b17fa3c583ed1b2c8bbcec20ba1db2aa5f11)"
ts=2022-11-21T12:57:00.736Z caller=main.go:232 level=info build_context="(go=go1.17.8, user=root@265f14f5c6fc, date=20220325-09:31:33)"
ts=2022-11-21T12:57:00.799Z caller=coordinator.go:113 level=info component=configuration msg="Loading configuration file" file=/etc/config/alertmanager.yml
ts=2022-11-21T12:57:00.799Z caller=coordinator.go:118 level=error component=configuration msg="Loading configuration file failed" file=/etc/config/alertmanager.yml err="yaml: unmarshal errors:\n line 17: field rule_files not found in type config.plain"alert-notifier.yml 17 번 째 줄이 문제 인것 같다. config.plain 에 rule_files 타입이 없단다.
컨피그맵을 만들 때 rule_files를 넣어주는게 아닌 것 같다.
컨피그맵에 rule을 설정하지 말고 prometheus를 배포할 때 overwrite를 하는게 맞는 것 같다. values.yaml을 참고해보자.

prometheus.yml 은 alerting_rules를 규칙으로 사용한다.
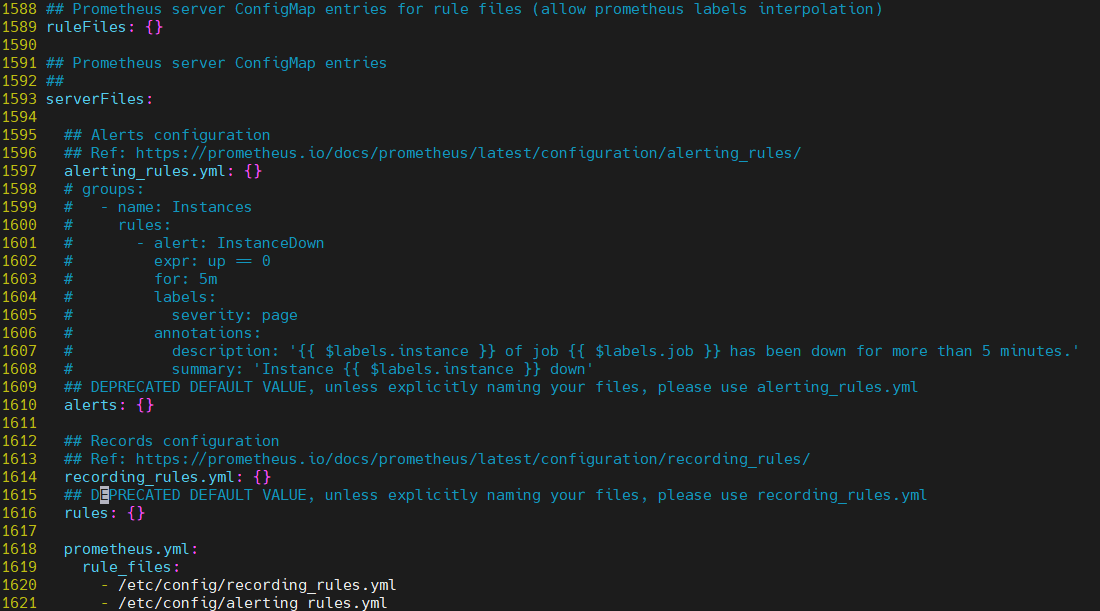
alerting_rules.yml 은 serverFiles 하위 목록이므로 여기에다가 overwrite를 해준다.
elm install prometheus prometheus-community/prometheus \
--set pushgateway.enabled=True \
--set alertmanager.enabled=True \
--set nodeExporter.tolerations\[0\].key=node-role.kubernetes.io/master \
--set nodeExporter.tolerations\[0\].operator=Exists \
--set nodeExporter.tolerations\[0\].effect=NoSchedule \
--set alertmanager.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set alertmanager.tolerations\[0\].key=node-role.kubernetes.io/master \
--set alertmanager.tolerations\[0\].operator=Exists \
--set alertmanager.tolerations\[0\].effect=NoSchedule \
--set alertmanager.nodeSelector.key=master \
--set alertmanager.configMapOverrideName=notifier-config \
--set alertmanager.securityContext.runAsGroup=1000 \
--set alertmanager.securityContext.runAsUser=1000 \
--set alertmanager.service.type="LoadBalancer" \
--set alertmanager.persistentVolume.existingClaim="prometheus-alertmanager" \
--set alertmanager.persistentVolume.mountPath="/efs/perometheus/alertmanager" \
--set server.tolerations\[0\].key=node-role.kubernetes.io/master \
--set server.tolerations\[0\].operator=Exists \
--set server.tolerations\[0\].effect=NoSchedule \
--set server.nodeSelector.key=master \
--set server.service.annotations."service\.beta\.kubernetes\.io/aws-load-balancer-type"=nlb \
--set server.persistentVolume.existingClaim="prometheus-server" \
--set server.persistentVolume.mountPath="/efs/perometheus/server" \
--set server.securityContext.runAsGroup=1000 \
--set server.securityContext.runAsUser=1000 \
--set server.service.type="LoadBalancer" \
--set server.storage.tsdb.path="/efs/perometheus/server" \
--set alertmanagerFiles.alertmanager.yml="alertmanager.yml" \
--set serverFiles.alerting_rules.yml="alerting_rules.yml" \7. Trouble: 파드도 정상작동하고 대시보드에도 접속 가능하지만 알람이 작동하지 않는다.
의심되는 원인이 너무 많다. 지속적으로 야기되는 문제는 --set 으로 필드를 overwrite를 하는 과정에서 적용이 되지 않는 경우들이 자주 발생한다. 이 부분이 배포 과정에서 속도를 더디게 만드는 점이다.
따라서, overwirte를 하지 않고 values.yaml 파일을 직접 수정한다.
한바탕 디버깅 후 install 에 성공. 자잘한 에러들은 생략한다.
helm install promethes ./prometheus
의심되는 원인
-
alertmanager target IP
-
Routing tree
-
rules 위치
-
configMap
8. Alert Test
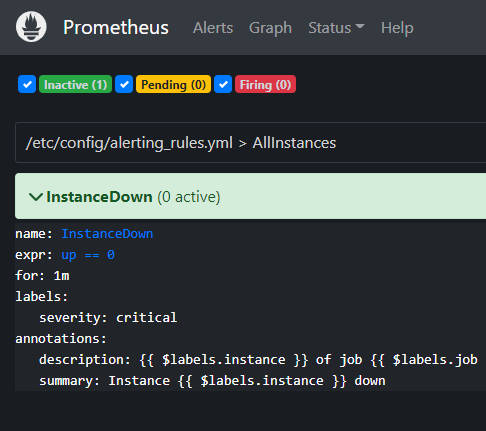
정상 작동 상태
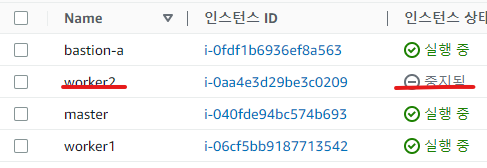
worker 노드 하나 중지시켜본다.
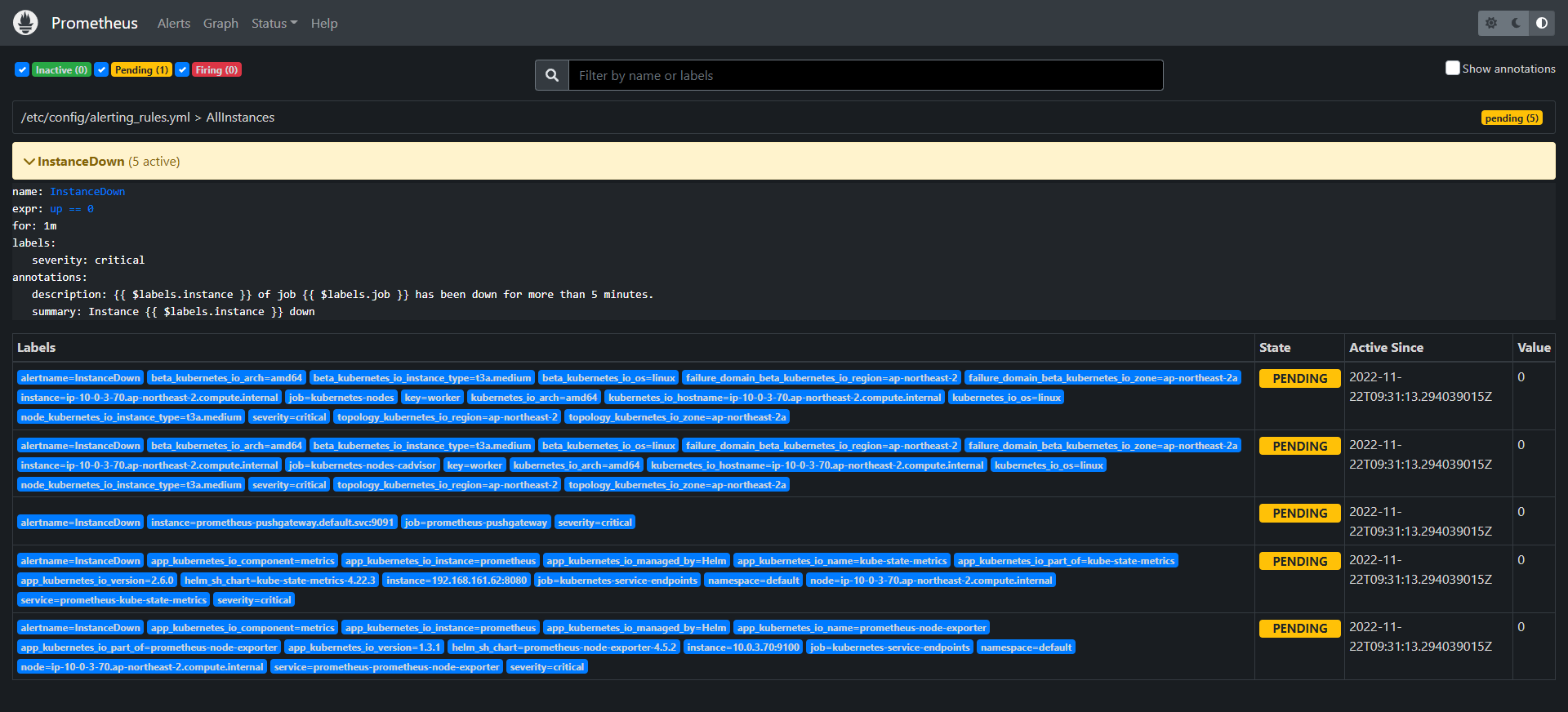
pending 상태
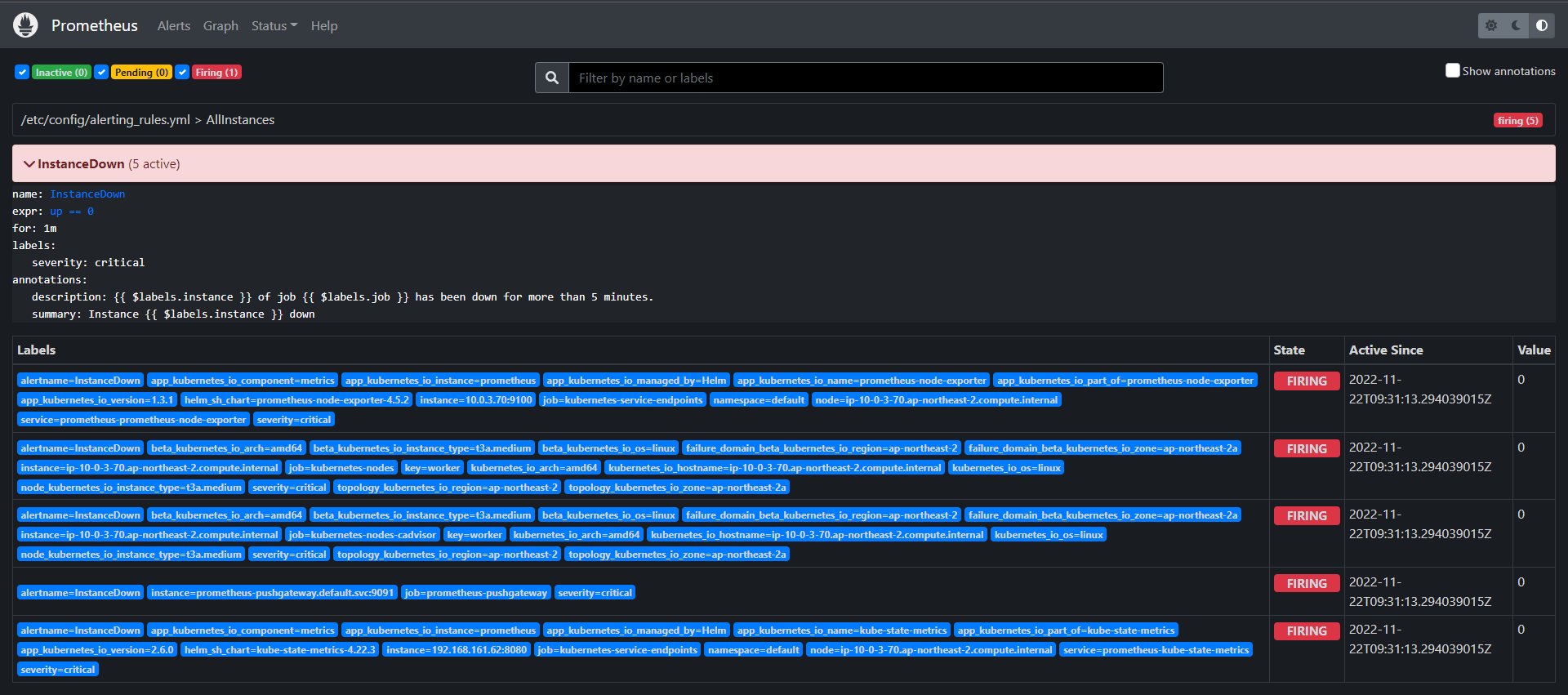
firing 성공!
9. Trouble 4 - slack webhook은 되지 않음
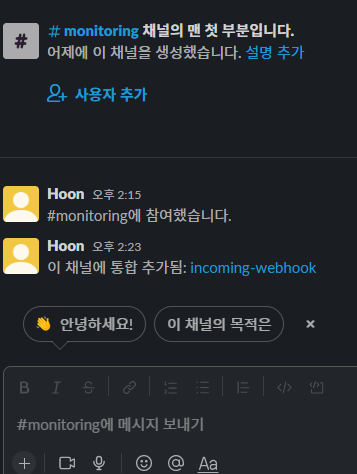
하지만 slack 은 잠잠하다 🤣
- route receiver 가 default 로 설정되어있었고 위와 같이 수정했다. -> 여전히 안됌
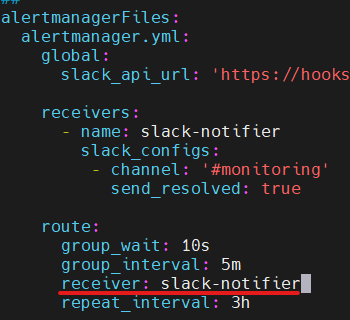
- 수신 웹훅 url 체크: 웹훅 url이 초기에 copy한 것과 달라져있었다. 수정. -> 여전히 안됌
- API TEST
curl -X POST -H 'Content-type: application/json' --data '{"text":"Hello, World!"}' <web_hook url>

API 는 문제 없다.
-
alertmanager.yml 순서 -> 공식 문서 보고 제대로 수정
-
configmap issue
⚡ root@ip-10-0-3-181 ~/prometheus k logs prometheus-alertmanager-557665ccf6-hwkb2 -c prometheus-alertmanager
ts=2022-11-23T02:13:14.108Z caller=main.go:231 level=info msg="Starting Alertmanager" version="(version=0.24.0, branch=HEAD, revision=f484b17fa3c583ed1b2c8bbcec20ba1db2aa5f11)"
ts=2022-11-23T02:13:14.108Z caller=main.go:232 level=info build_context="(go=go1.17.8, user=root@265f14f5c6fc, date=20220325-09:31:33)"
ts=2022-11-23T02:13:14.286Z caller=coordinator.go:113 level=info component=configuration msg="Loading configuration file" file=/etc/config/alertmanager.yml
ts=2022-11-23T02:13:14.287Z caller=coordinator.go:126 level=info component=configuration msg="Completed loading of configuration file" file=/etc/config/alertmanager.yml
ts=2022-11-23T02:13:14.295Z caller=main.go:535 level=info msg=Listening address=:9093
ts=2022-11-23T02:13:14.296Z caller=tls_config.go:195 level=info msg="TLS is disabled." http2=false
ts=2022-11-23T02:19:23.588Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=3 err="slack-notifier/slack[0]: notify retry canceled due to unrecoverable error after 1 attempts: channel \"#monitoring\": unexpected status code 403: invalid_token"
ts=2022-11-23T02:20:23.496Z caller=dispatch.go:354 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=5 err="slack-notifier/slack[0]: notify retry canceled due to unrecoverable error after 1 attempts: channel \"#monitoring\": unexpected status code 403: invalid_token"

configmap overriding을 하고 있었다.
2,000 줄이 넘는 values.yaml 을 수정하다 보니 일전에 configMapOverriding 부분에 컨피그맵을 연결해준 것을 놓쳤다. 수정했더니 최종적으로 슬랙에서 알람을 확인할 수 있었다.
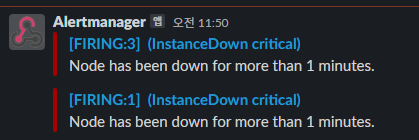
테스트 성공!

10. 시간이 걸린 요인
-
prometheus-alertmanager와 prometheus-server는 각각 프로메테우스 컴포넌트다. 프로메테우스 경보시스템 설정을 위해 alertmanager inner line(values.yml 에 alertmanager 와 server line이 구별 되어 있다.) 내부만을 수정하면 된다고 생각했다.
하지만, 공부를 해보니 alertmanager는 alert"manager"이다. 즉, 알람을 프로메테우스 서버에서 전달 받는다. 알림을 매니징 하는 역할이고, 알림을 만드는 역할은 프로메테우스 서버이기 때문에 프로메테우스 프로세스를 잘 알고 있었다면 보다 빠르게 프로메테우스 서버도 손봐야 한다는 것을 눈치챘을 것이다.
또한, values.yaml 마지막 부분에 prometheus.yml 과 serverFiles에 대한 설정이 있었다. 결국 전체 라인을 전부 봐야했는데 경우의 수가 많아 뒤늦게 확인했다.
-
컨테이너가 생성되며 컨테이너 내부에 생성되는 파일과 컨테이너 외부(호스트)에서 가져오는 파일을 혼동하여 다량의 삽질을 했다. 컨테이너 동작에 대한 개념을 튼튼하게 할 필요성을 느꼈다.
-
우리만의 환경에 배포하려면 커스터마이징을 해야하고, 문법과 프로세스에 대해 공부하는 시간이 소요되는건 당연한 듯
Reference
- https://prometheus.io/docs/alerting/latest/alertmanager/
- https://prometheus.io/docs/alerting/latest/configuration/
- https://awesome-prometheus-alerts.grep.to/rules.html#host-and-hardware
- https://grafana.com/blog/2020/02/25/step-by-step-guide-to-setting-up-prometheus-alertmanager-with-slack-pagerduty-and-gmail/
- https://kinopyo.com/en/blog/escape-square-bracket-by-default-in-zsh
