
what is the DAG?
Directed Acyclic Graph : 방향성 비순환 그래프 > 순환하는 사이클이 없는 그래프의 형태
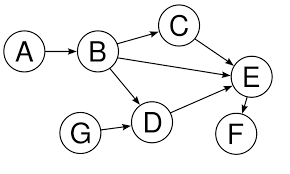
DAG in Airflow
Node: Task(작업)
Edge: Dependency(의존성)
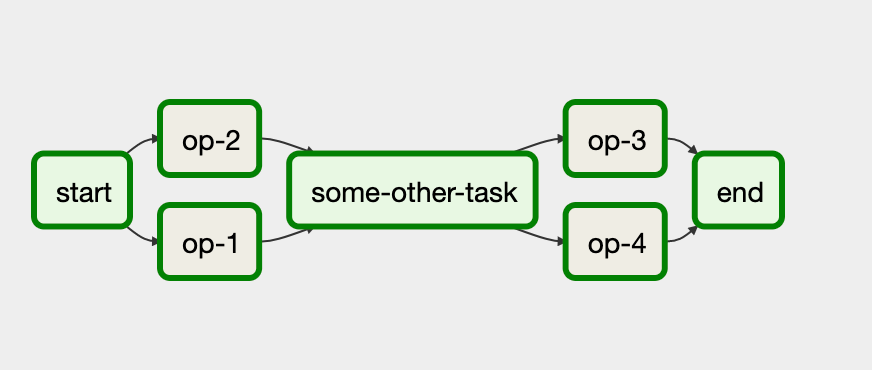
위의 그림에서 예시를 들자면 start node > [op-2 > op-1] > some-other-task > [op-3 > op-4] > end 순으로 작업을 진행하라고 DAG를 정의하였다.
DAG를 구성하기 전에 반드시 알아둬야 할 점
one operator 는 one task만 할당한다.
구체적인 예를 들어 위에서 우리는 cleaning 과 processing을 PYTHON operator로 수행할 예정이다. 때문에 아래와 같이 하나의 operator에 전부 넣지말고, 하나의 operator에 하나의 task만 할당해준다.
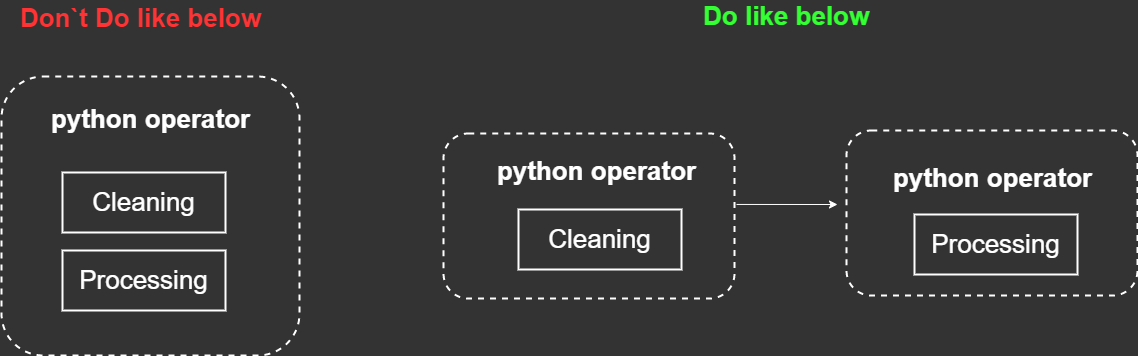
왜 그래야할까?
생각해보자. cleaning data 작업이 잘 마무리 되었다고 가정했을 때, processing data를 처리해야 한다. 그런데 하나의 오퍼레이터에 여러가지 일을 넣어 놓았을 때에는 앞에 아무리 여러일을 완벽히 수행했다 하더라도, 마지막 task인 processing data가 실패하였을 경우 다시 retry를 해야하는데 위의 오퍼레이터를 다시 시작하면 위에 성공한 일들도 마찬가지로 다시 수행해야 한다. 때문에 오버헤드가 발생한다.
3가지 타입의 Operator
Action operators: Execute an action.(ex> python operator, bash operator)Transfer Operator: Transfer data. (sql을 수행하는 등 데이터를 전송하는 오퍼레이터)Sensosrs: This is used in order to wait for something to happen before moving to the next task. (ex>sql sensor: database로 파일들을 전송시켰을 때 해당 데이터베이스에 잘 올라 왔는지 체크한 후 다음 것들을 수행 시켜야 할 때 사용한다.)
간단하게 DAG를 구성해보기
아래의 그림과 같이 DAG를 만들려고 한다.
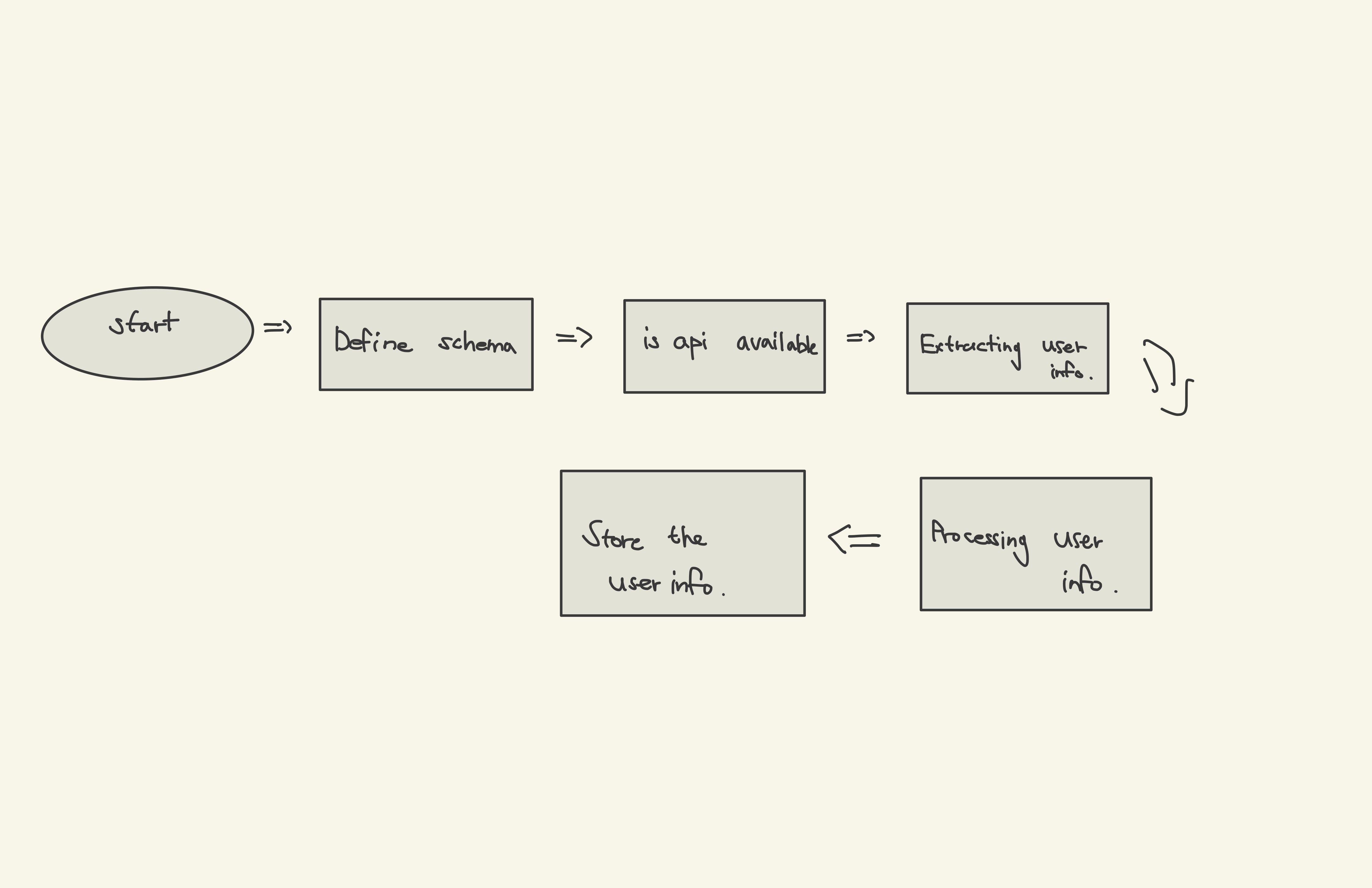
해당 DAG를 사용하기 위해서는 sqlite provider 를 설치해야 한다.
pip install 'apache-airflow-providers-sqlite'
를 배쉬에서 입력해서 해당 provider 를 설치하자.
해당 프로바이더가 잘 설치되었는지 확인해보자.
airflow providers list
sqlite provider가 정상적으로 설치가 되었다.
1. sqlite schema 정의하기
from airflow.models import DAG
from datetime import datetime
from airflow.providers.sqlite.operators.sqlite import SqliteOperator
default_args = {
'start_date': datetime(2020, 1, 1)
}
with DAG('user_processing',
schedule_interval='@daily',
default_args=default_args,
catchup=False) as dag:
# Define tasks/operators
# Create table using by sqlite..
creating_table = SqliteOperator(
task_id='creating_table',
sqlite_conn_id='db_sqlite',
sql='''
CREATE TABLE users (
firstname TEXT NOT NULL,
lastname TEXT NOT NULL,
country TEXT NOT NULL,
username TEXT NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL PRIMARY KEY
);
'''
)아래 링크에서 sqlite에 대한 reference를 찾아 볼 수 있다.
https://airflow.apache.org/docs/apache-airflow-providers-sqlite/stable/operators.html
airflow webserver 에서 DAG를 확인해보자.

정상적으로 해당 DAG가 airflow webserver ui에 출력되는 것을 볼 수 있다.
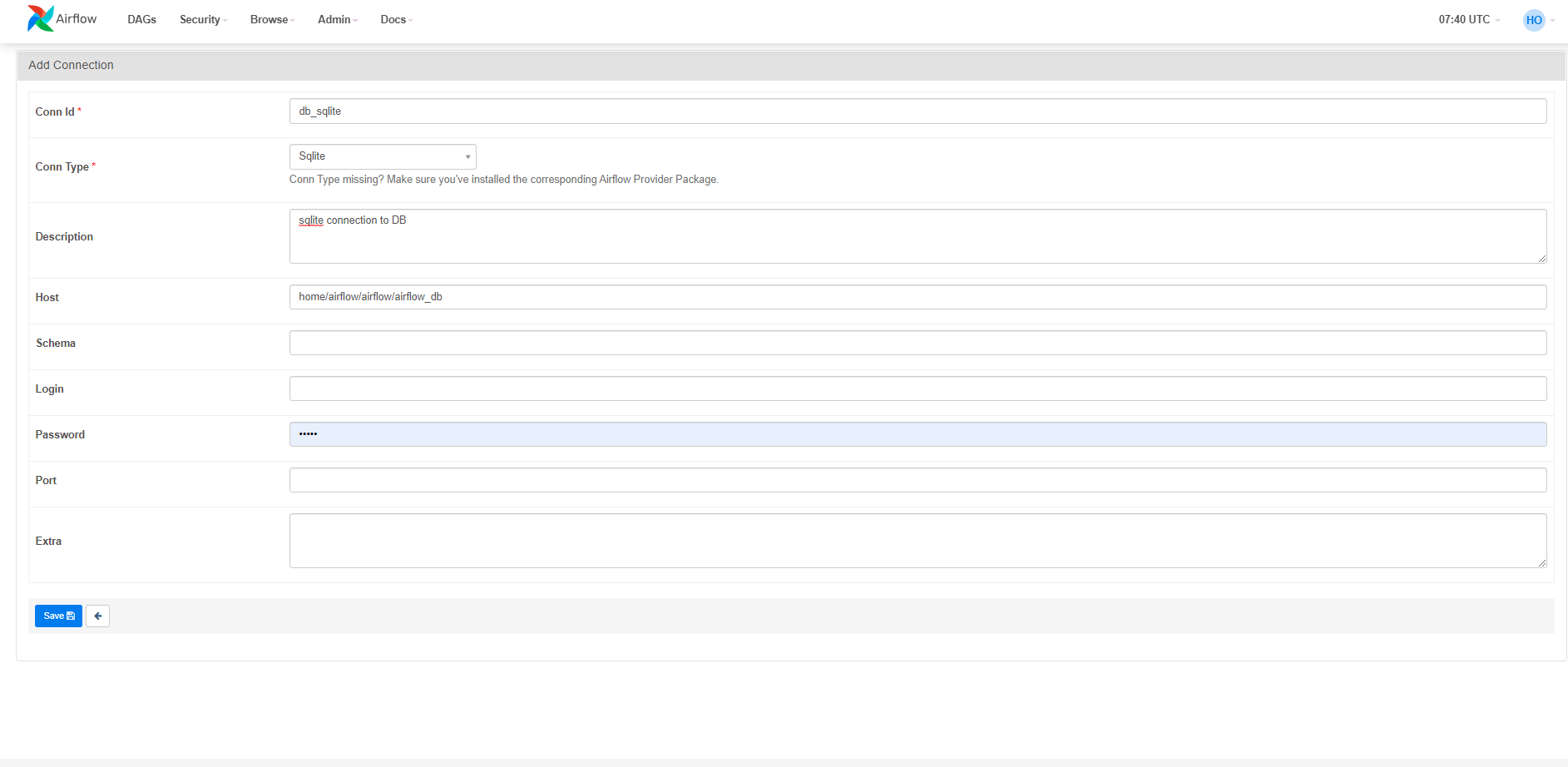
airflow webserver 에서 connection 생성하기
admin > connection > connection 추가하기
위의 과정을 진행하면 아래와 같은 페이지가 나오게 된다.
conn_id 는 위에서 우리가 정의한 sqlite 오퍼레이터와 일치 시켜준다.
또한 호스트를 우리 airflow 폴더에 있는 airflow_db와 매핑시켜준다.
데이터 파이프라인에 task를 추가할 때 반드시 해야할 것
에어플로우에서 해당 task를 테스트 해야만 한다. 해당 데이터 파이프라인을 전체 돌려볼 수는 없으므로 해당 task만 고립시켜서 반드시 테스트를 거쳐야만 한다.
테스트 명령어는 아래와 같이 구성하면 된다.
airflow tasks test <dag_name> <operator_id> <date>따라서 우리는 아래와 같이 입력할 예정이다.
airflow tasks test user_processing creating_table 2020-01-01
정상적으로 해당 프로세스가 실행되었다.
그럼 sqlite 에서 해당 스카마가 잘 정의되었는지 확인해보자.
sqlite3 airflow_db
.schema

sqlite에서도 해당 스키마가 잘 정의되어있는 것을 확인할 수 있다.
