
지난 시간 복습
지난 시간에는 해당 정보를 저장할 스키마를 정의하고 해당 오퍼레이터가 정상적으로 작동하는지 테스트까지 해보았다.
is_api_available ?
우리가 어떤 페이지에서 유저 정보를 rest_api 형태로 가져올 예정이다. 그런데 해당 api가 사용가능한 형태인지 먼저 체크하는 것이 우리가 api 정보를 불러오는 코드가 잘못된 것인지, 해당 api가 잘못된 것인지 분리할 수 있기 때문에 sensor를 사용하면 추후 파이프라인을 관리하기 용이해진다.
https://randomuser.me/
우리가 사용할 user information을 랜덤하게 제공해주는 서비스http provider 설치
터미널에서 해당 provider를 설치하자.
pip install apache-airflow-providers-http==2.0.0
http provider sensor 활용하기
is_api_available = HttpSensor(
task_id='is_api_available',
http_conn_id="user_api",
endpoint="api/"
)(endpoint: 해당 http 주소 마지막에 붙는 문자)
해당 dag에 위의 업무를 추가적으로 정의한다.
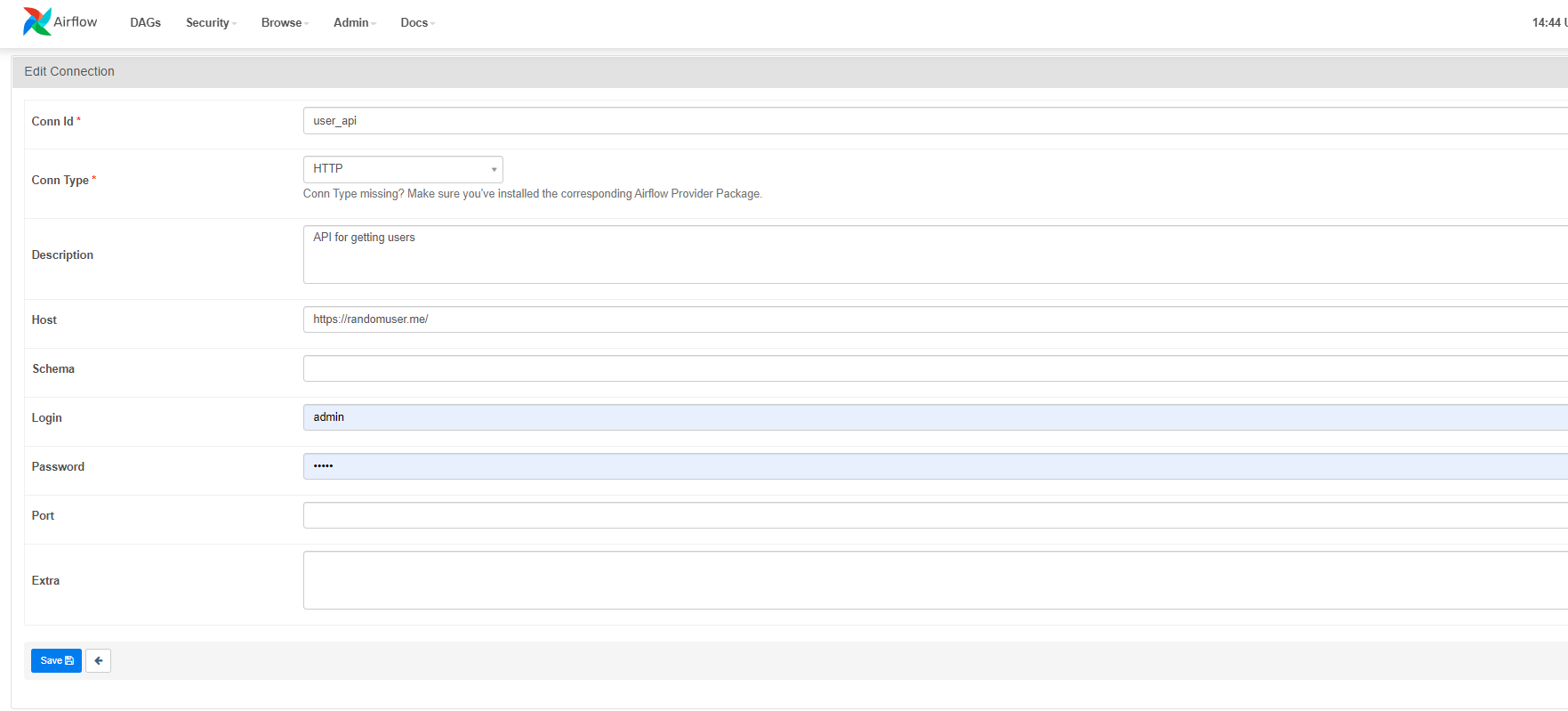
후에 Admin 에서 아래와 같이 내용을 입력해서 어디에서 가져올 것인지 메타 데이터를 정의해준다.
위의 task를 test 해보자
airflow tasks test user_processing is_api_available 2022-01-01
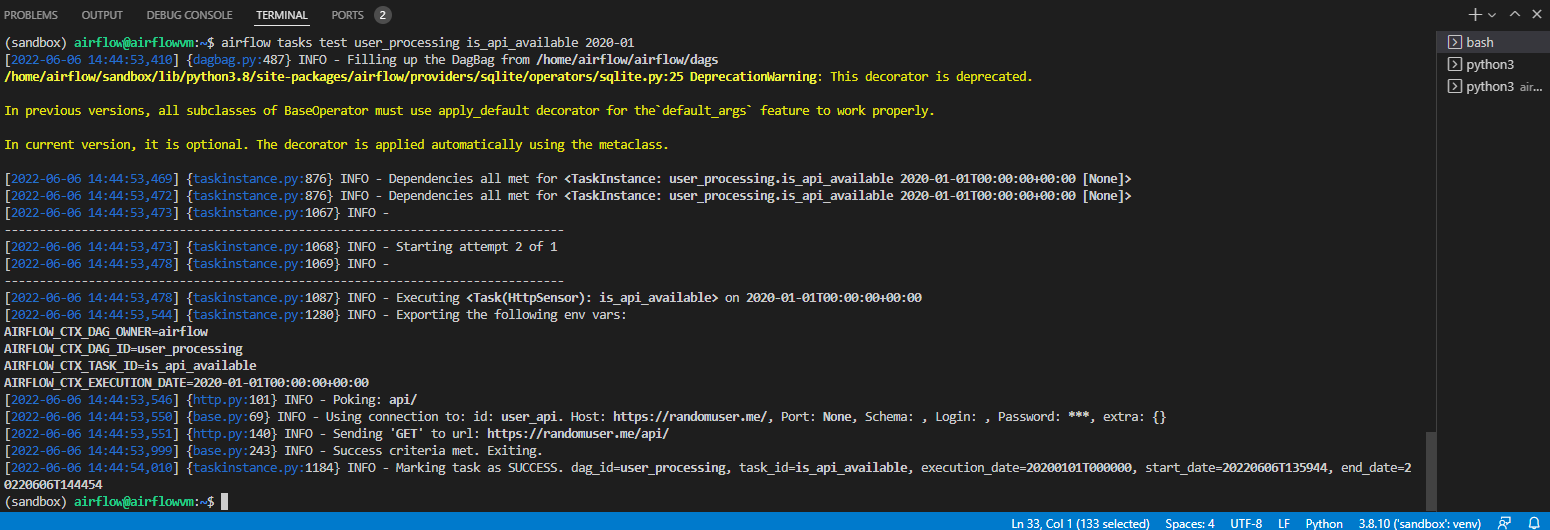
위와 같이 정상적으로 작동한다.
위의 센서는 get method를 활용하여 해당 api에 적절하게 작동하는지 확인해주었다.
User information Extracting 해보기
우리는 위에서 해당 api가 정상적으로 작동하는 것을 확인했다.
이제 위의 페이지에서 get 메소드를 통해 가져오기만 하면 된다.
extracting_user = SimpleHttpOperator(
task_id="extracting_user",
http_conn_id='user_api',
endpoint='api/',
method='GET',
response_filter=lambda response: json.loads(response.content),
log_response=True
)위의 페이지에서 json 형태로 우리에게 데이터를 전송하므로 우리는 response의 내용만 가져와서 json을 파이썬 객체에 맞게 불러온다.
airflow tasks test user_processing extracting_user 2022-01-01
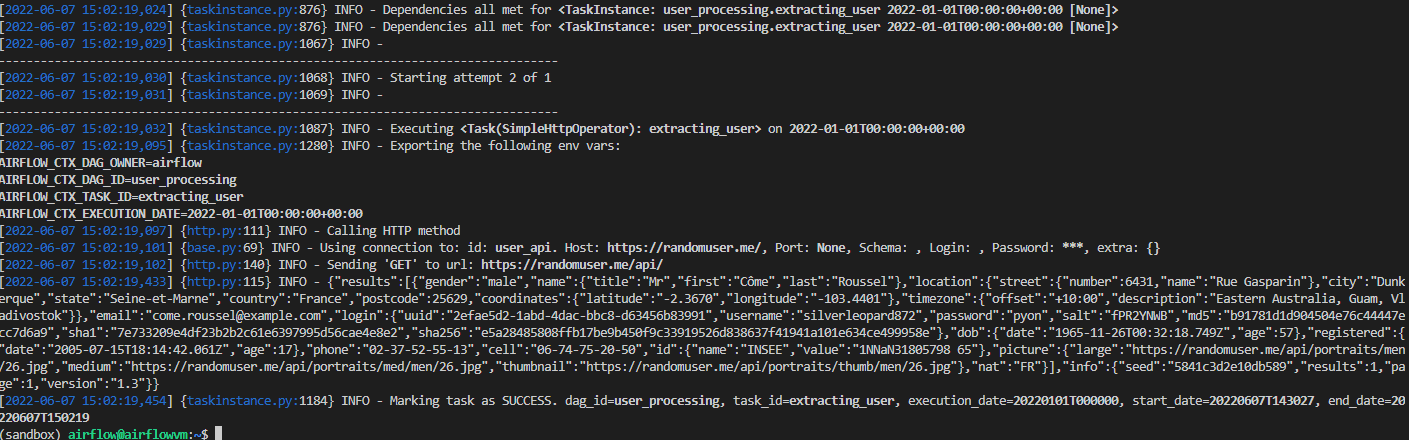
정상적으로 불러와졌다.
이제 우리의 스키마에 맞게 데이터를 변환(Transform)해야 한다.
user information Transform 해보기
해당 내용에 앞서서 Xcom을 활용하여 dag 내부에서 작은 내용의 데이터를 옮기려 한다.
Airflow의 task는 독립적으로 실행되기 때문에 기본적으로는 서로 통신할 수단이 없다. 하지만 막상 작업 흐름을 만들다 보면 이전 작업의 결과, 요소 등을 다음 작업에 전달하면 깔끔하게 진행되는 경우가 있기 때문에 Xcom을 이용해 데이터를 전달할 수 있게 만들었다.
대용량 데이터 처리를 위한 방법이 절대 아니다!!!!
https://airflow.apache.org/docs/apache-airflow/stable/concepts/xcoms.html?highlight=xcom
위의 링크에서 xcom에 대해 더욱 자세히 알아볼 수 있다. (추후 xcom에 대해 리뷰할 예정!)
우리가 받아오는 데이터 형식은 아래와 같다. 해당 json 객체를 스키마에 맞게 변형시키는 함수이다.
{"results":[{"gender":"male","name":{"title":"Mr","first":"Arttu","last":"Karjala"},"location":{"street":{"number":786,"name":"Myllypuronkatu"},"city":"Laukaa","state":"Finland Proper","country":"Finland","postcode":83837,"coordinates":{"latitude":"-8.5418","longitude":"-61.6985"},"timezone":{"offset":"-2:00","description":"Mid-Atlantic"}},"email":"arttu.karjala@example.com","login":{"uuid":"1451762d-e317-4f14-bd34-78bc8a4b260b","username":"brownfrog507","password":"stinks","salt":"6nfB9fsR","md5":"69d7f40026aad27c8297c4a9b5daf884","sha1":"a062e9da71d779e0e59fefb06922d34974a469a6","sha256":"8f28b7d03266270b57157525be430d26cb0a782ba1fc028d854ee040e5af5bea"},"dob":{"date":"1971-11-19T08:20:39.888Z","age":51},"registered":{"date":"2015-02-21T16:21:34.809Z","age":7},"phone":"06-626-140","cell":"047-531-21-26","id":{"name":"HETU","value":"NaNNA969undefined"},"picture":{"large":"https://randomuser.me/api/portraits/men/80.jpg","medium":"https://randomuser.me/api/portraits/med/men/80.jpg","thumbnail":"https://randomuser.me/api/portraits/thumb/men/80.jpg"},"nat":"FI"}],"info":{"seed":"4d80ac4de2dfffcf","results":1,"page":1,"version":"1.3"}}
먼저 from airflow.operators.python import PythonOperator 와 from pandas import json_normalize 를 해준다.
dag 바깥에 아래의 함수를 정의 해준다. 해당 함수는 xcom을 이용하여 추출한 데이터들을 전달받아서 user 객체에 저장한 후 우리가 원하는 방향으로 데이터를 추출한다.
def _processing_user(ti):
users = ti.xcom_pull(tasks_id=['extracting_user'])
if not users or 'results' not in users[0]:
raise ValueError('User is empty')
users = users[0]['results'][0]
processed_user = json_normalize({
"firstname": user['name']['first'],
"lastname": user['name']['last'],
"country": user['city']['country'],
"username": user['login']['username'],
"password": user['login']['password'],
"email": user['email']
})
processed_user.to_csv('./tmp/processed_user.csv', index=None, header=False)후에 dag를 아래와 같의 정의해준다.
processing_user = PythonOperator(
task_id="processing_user",
python_callable=_processing_user
)airflow tasks test user_processing processing_user 2022-01-01 를 입력해 해당 노드가 정상적으로 작동하는지 체크해보자.
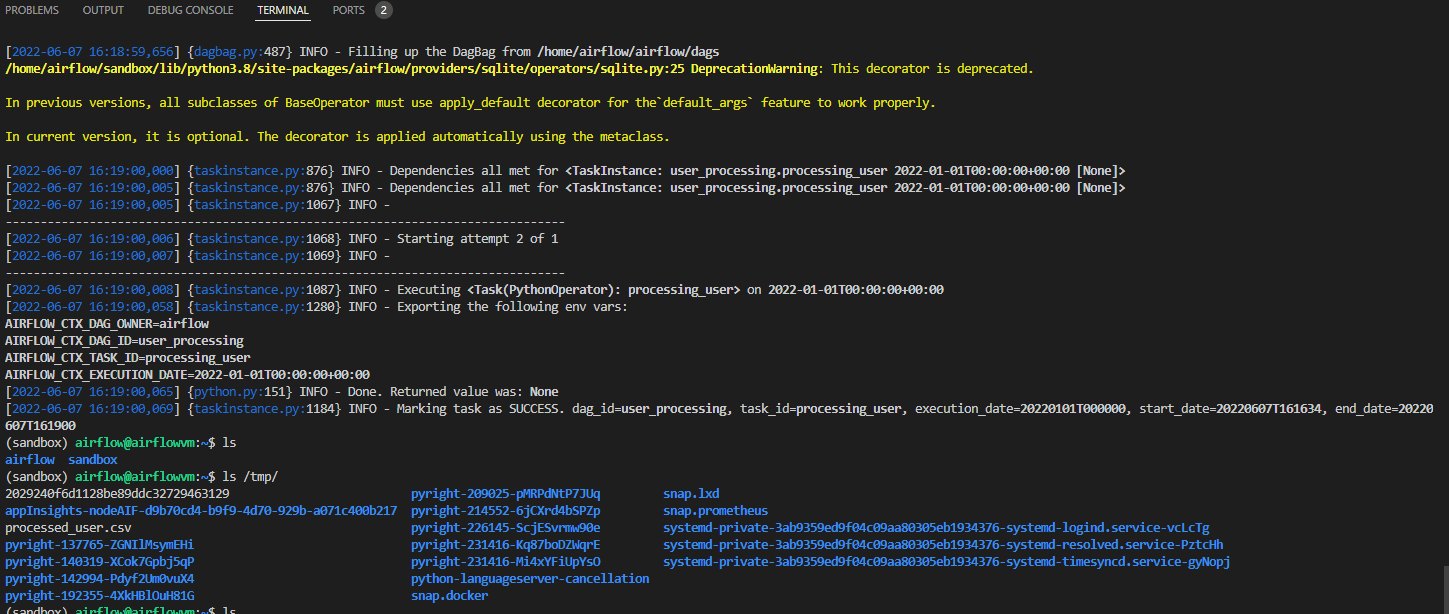
정상적으로 잘 작동한다.
Load User data to Database!!!
이제 다 왔다. 해당 csv 파일에 저장되어 있는 내용들을 sqlite에 저장하기만 하면 된다.
storing_user = BashOperator(
task_id='storing_user',
bash_command='echo -e ".separator ","\n.import /tmp/processed_user.csv users" | sqlite3 /home/airflow/airflow.db'
)
위의 bash command 내용은 오른쪽에서 부터 보면 된다.
sqlite3를 airflow.db 실행 > 우리가 저장한 csv 파일을 sqlite3 user table로 임포트 한다는 내용이다.
airflow tasks test user_processing storing_user 2020-01-01 을 입력하자.

creating_table >> is_api_available >> extracting_user >> processing_user >> storing_user
마지막으로 dependency를 설정하고 트리거를 당기면 끝이 난다.
디펜던시를 설정한 후 그래프 !!

정상적으로 각 노드들이 작동하고 있다.

DAG가 끝나고 난 후 user table 조회하기

스카마에 맞게 정상적으로 모두 load 되었다.
끝으로....
airflow database 스키마를 정의하고 데이터를 추출한 후 데이터를 변형한 뒤 데이터를 저장하는 dag를 하나 구성해 보았다. 물론 이런 간단한 작업은 해당 dag를 만드는 것보다 직접적으로 하는 것이 편리하고 빠르다. 하지만 해당 프로세스는 로그가 남지 않고 자동화할 수 없다. 앞으로 우리는 지금 당장은 더 수고스럽지만 추후에 더 빠르고 편리하게 동작할 수 있도록 airflow를 익히려고 노력할 것이다.
