데이터베이스의 지연
DB에서 집계함수를 사용해 지연이 몇 분이나 기다리게 된다면 작업 효율을 극적으로 떨어진다. 구체적으로 우리는 쿼리문을 통해 db에 질의를 한다. 물론 나혼자만 하면 기다리면 된다. 그러나 db의 경우는 다른 여러 작업들도 수행한다.
우리는 위와 같은 문제를 해결하기 위해 2가지 방법을 채택한다.
- 작은 데이터의 경우 모든 데이터를 메모리에 올린다.
- 압축과 분산을 통해 지연을 줄인다.
우리가 구체적으로 다룰 방법은 2번이다. 1번의 경우 기존의 rdbm에서도 제공해주기 때문이며 우리는 큰데이터를 어떻게 하면 빠르게 사용할 수 있을지가 고민이기 때문이다.
압축과 분산
데이터를 가능한 작게 압축하고 그것들을 여러 디스크에 분산하면 데이터의 저장비용과 불러오는 시간을 줄일 수 있지 않을까?
분산된 데이터를 멀티 코어를 활용하여 디스크 인풋 아웃풋을 병렬처리 하는 아키텍쳐를 우리는 아래와 같이 부르기로 했다.
MPP: Massive Parallel Processing
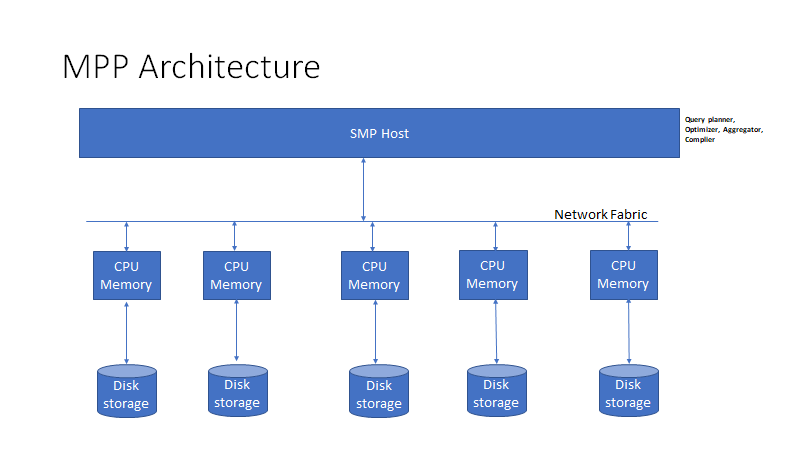
위와 같은 아키텍쳐는 대량의 데이터 분석을 하기 위해 데이터베이스에서 이미 널리 사용되고 있으며 구체적으로 aws redshift, gcp의 bigquery등이 존재한다.
열 지향형 데이터베이스
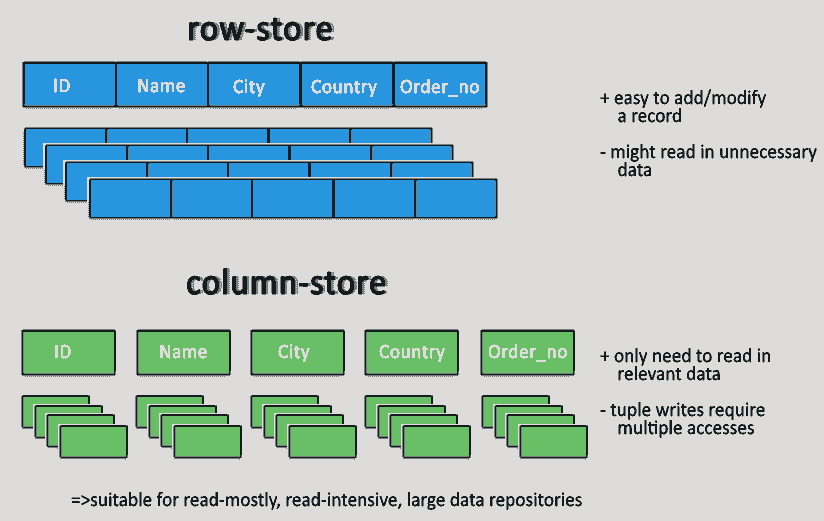
대량의 데이터를 그냥 렘에 올려서 빠르게 읽어 오는 것이 좋다는 것은 누구나 알고 있지만 메모리 용량은 한정적이다. 그렇다면 디스크에 저장해야만 한다.
우리가 DWH를 데이터 분석을 위해 구축하며 조인문들은 데이터 분석에 가장 큰 적이다.(시간을 많이 잡아먹기 때문!!) 때문에 미리 모두 조인해 둔 Star Schema의 형태로 구성된다.
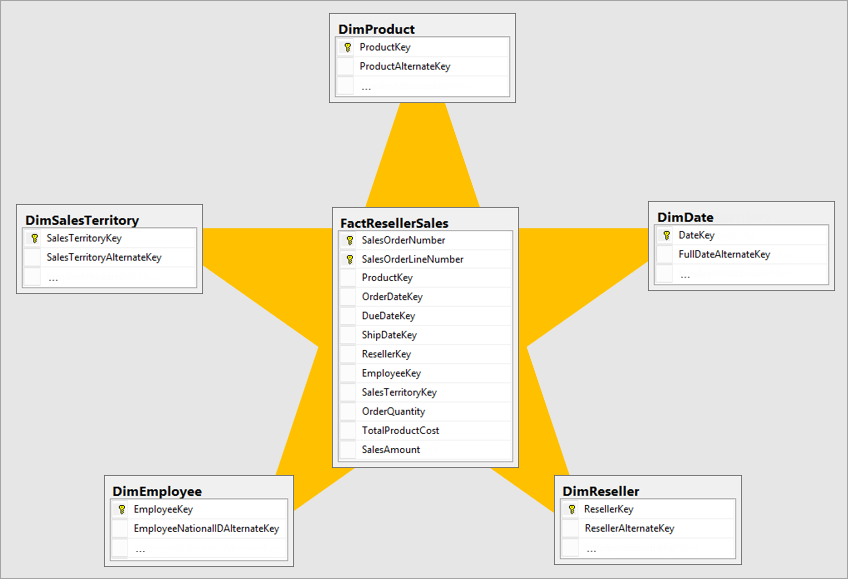
때문에 각각의 피쳐들은 많이 존재한다. 이러한 경우 필요한 컬럼(피쳐)만 불러온다면 효율적으로 작동 할 것이다.
또한 열지향형 데이터 베이스는 데이터의 압축 효율도 우수하다. (일반적으로 반복되거나 비슷한 내용이 많거나 비어 있는 경우도 있기 때문!! sparce 하다고 한다.)
그러나 열지향형 데이터베이스의 경우 치명적인 약점이 존재한다.
바로 일관성을 보장하지 못한다.
기존의 rdbm(행지향형)은 acid의 원칙을 철저하게 지킨다.
그러나 열지향형은 열별로 데이터를 보관하기 때문에 일관성의 원칙이 지켜지는지 지속적으로 확인하기 어렵다.
MPP 아키텍쳐를 활용한 DB 활용
기존의 행지향형 DB에서는 하나의 쿼리에 하나의 쓰레드에서 실행이 된다.
때문에 cpu 코어가 아무리 많다한들 하나의 쿼리 수행능력은 일정하다.
mpp에서는 하나의 쿼리를 다수의 작은 테스크로 분할하고 이 테스크들을 각 쓰레드로 할당해 병렬로 작업을 수행한다. 이후 각 태스크들의 결과를 집계해 결과를 리턴해준다. (하나의 컴퓨터에서 동작하는 맵 리듀스 느낌)
따라서 cpu의 코어수가 많아질수록(코어당 2개의 쓰레드가 존재한다고 가정할 때) 데이터의 집계는 더욱 빨라진다.
MPP 아키텍쳐 열지향형 DB사용에서 주의할 점
하나의 쿼리에 다수의 코어를 할당하게 되면서 시스템의 모든 리소스를 쉽게 소진할 수 있는 문제점이 나오게 된다.
이러한 문제는 잘못된 쿼리를 통해 과부하가 오면서 서버가 터지는 경우도 존재한다.
때문에 주기적으로 리소스를 주의깊게 살피며 이용자 별로 리소스를 제한하여 전반적인 서버의 과부하를 견제해야만 한다.
