대용량 데이터 처리의 필요성
인터넷의 보급과 확산으로 전통적인 방식인 rdbm으로 처리할 수 없을 만큼 대량의 데이터가 쌓이기 시작했고 이러한 데이터를 처리하기 위해서는 기존과는 다른 패러다임을 요구했다.
Hadoop
하둡은 대량의 데이터를 분산처리 하기 위한 프레임워크이다.
나중에 구체적으로 언급하겠지만 하둡은 map, reduce라는 방식을 통해 동작한다.
작업을 분할하고 작업이 완료되면 부분 결과를 다시 조립하여 결과를 완성시킨다.
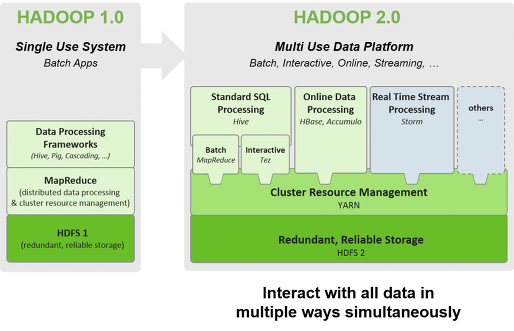
그러나 하둡은 작업 방식이 매우 불친절하고 자바로 동작하며 구체적으로 직관적이지 못하다. 때문에 Hive 가 등장하여 sql 형식으로 query를 날릴 수 있게 되었다.
그럼에도 불구하고 위와 같은 불편함 때문에 hadoop 2.0에서는 yarn 아키텍쳐를 도입해서 위와 같은 과정을 추상화하여 각각의 어플리케이션을 도와주는 역할을 하게 된다.
NoSQL DB
nosql은 기존의 rdb 의 제약조건들을 제거하려는 것을 목표로 탄생한 데이터베이스의 총칭이다. 종류는 아래와 같다.
- key value store
- document store
- wide-column store
기존 rdb 에서 제공하는 여러가지 제약조건을 만족하지 못하므로 안정적이지 않다.
- 구체적으로 데이터베이스 일관성이 보장되지 못한다.
- 데이터의 중복의 발생 가능성이 높다.
- 스키마가 없어서 데이터에 대해 전반적으로 살펴보기 어렵다.
- 데이터 업데이트시 모든 컬렉션에서 수행되어야 하므로 비효율이 발생한다.
그럼에도 위의 nosql을 사용하는 이유는 아래와 같이 강력한 요인이 많다.
-
스키마가 없기 때문에 유연하다. 즉 언제든지 데이터를 조정하고 새로운 필드를 추가할 수 있다.
-
수직 및 수평적 확장이 가능하므로 데이터베이스가 애플리케이션에서 발생시키는 모든 읽기 / 쓰기 요청 처리가 가능하다.
-
데이터는 애플리케이션이 필요로 하는 형식으로 저장된다.
분산 시스템의 비즈니스 이용 개척
기업에서는 축적된 데이터를 비즈니스에 활용하기 위해 DWH를 도입했다.
전통적인 DWH에서도 대량의 데이터를 처리할 수 있으며 오히려 하둡보다 뛰어난 면이 존재한다. 그럼에도 하둡을 사용하는 이유는 무엇일까?
그것은 장비의 제약과 스케일 업의 문제다.
우리의 정보는 축적되고 있으며 앞으로는 더욱 많아질 것이다. 이러한 데이터를 다루기 위해서는 기기의 사양도 높아져야한다.
그런데 우리의 초기비용과 추후 확장성을 계속 고민하면서 처음부터 고가의 장비를 도입하는 기업은 얼마나 될까? 쉽지 않은 결정일 것이며 현재의 고가의 장비는 빠르게 발전하는 기술의 속도에 뒤쳐지는 것도 생각해 봐야한다.
이러한 이유로 간단하게 스케일업 할 수 있게하는 하둡이 매력적인 이유이다.
클라우드 플랫폼의 발빠른 성장
위와 같은 상황과 맞물려 유동적인 컴퓨터 자원 소비와 비용 절감의 측면에서 클라우드 플랫폼이 부상하게 된다.
구글의 bigquery, 아마존의 redshift 등 cloud DWH의 등장과 클라우드 hadoop의 등장은 빅데이터와 클라우드는 같이 갈 수 밖에 없다.
