본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 06. Model-based Collaborative Filtering
모델 스스로 룰(패턴)을 배우느냐 아니면 사람이 직접 룰을 만들어주는 것의 차이일 뿐, 룰도 모델의 일종이라고 생각해볼 수 있다.
상호 연관관계
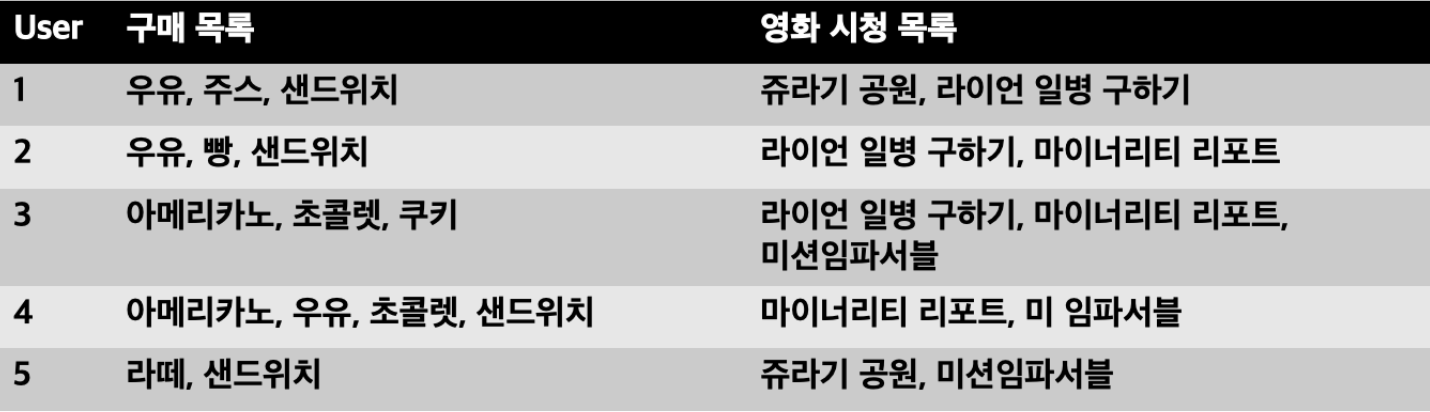
- 위 데이터 속에서 상호 연관관계 찾을 수 있음
- 여러 같이 등장한 아이템들을 보고 서로 연관관계가 있지 않을까 찾아볼 수 있다
- 구매목록: {우유, 샌드위치}, {아메리카노, 초콜렛}
- 영화 시청목록: {마이너리티 리포트, 미션임파서블}
- 상호 연관관계를 바탕으로 특정 룰을 만들고, 그 룰을 바탕으로 새로운 유저가 A 아이템을 구매했다면 A와 상호 연관관계인 B 아이템을 추천 가능
모델기반 협업필터링 feat. Association Rule
-
데이터의 모델
- 데이터의 관계, 접근과 흐름 파악을 위한 추상화된 모형
- 데이터 구조 결정
-
데이터의 여러 특징 파악해서 모형화 ➡️ 모델링
- 데이터 간의 연관 법칙을 찾는 data mining 기법 중 하나
-
기존 데이터를 기반으로 Association Rule(연관 규칙)을 만듦
Association Rule Mining
1. 정의
- Minimum Support와 Minimum Confidence 값을 넘는 Rule 찾는 과정
- 데이터에서 흥미로운 관계 찾는 Rule-based machine learning 기법 중 하나
- 특정 measure 통해 interestingness를 평가 ➡️ Rules 중에서도 Strong Rules 찾는 과정
2. Association Rule의 Support(지지도)
- 데이터 관계 설정을 위해 아이템이 동시에 발생할 확률
- 전체 데이터 중 규칙 (A, B)를 포함하는 데이터 비율 (즉, 규칙 (A,B)가 몇 번 등장하는지 보자)
3. Association Rule의 Confidence(신뢰도)
- 특정 아이템 A가 선택된 상태에서 다른 아이템 B를 선택할 확률(다른 아이템 C, D 등이 아닌)
- (A, B)의 관계를 가정하고, A를 선택한 사람이 B를 선택한 비율
4. Association Rule의 Lift(향상도)
- (A, B)의 관계를 직접적으로 나타내는 measurement
- 1보다 큼: 이어서 B를 선택할 확률이 높음
- 1보다 작음: 확률이 높지 않음
1. Support
- 0과 1 사이의 값
- 1에 가까울수록 A와 B 관계가 중요
- 0에 가까운 연관관계 먼저 제거 ➡️ 자주 발생하지 않는다는 것
- 중요한 단점: 와 의 차이점 파악 불가능
- A와 B가 함께 등장하는 것을 카운트하는 것이기때문에 A➡️B인지 B➡️A인지가 중요한 것이 아니라 그 둘이 얼마나 같이 등장하는 것인지가 더 중요
- 그래서 등장한 것이 Confidence
- A와 B가 함께 등장하는 것을 카운트하는 것이기때문에 A➡️B인지 B➡️A인지가 중요한 것이 아니라 그 둘이 얼마나 같이 등장하는 것인지가 더 중요
2. Confidence
- 0과 1사이의 값
- A를 선택했을 때 B를 선택할 확률 (반대로 B를 선택했을 때 A를 선택할 확률은 달라질 수 있는 것!)
- 1에 가까울수록 A는 B에 많은 영향 받음 ➡️ minimum support 중 가장 큰 confidence 선택
- confidence 값이 크면 중요한 연관관계라는 것
- 와 와 다르게 A와 B 사이의 관계 파악 가능
3. Lift
- 0과 1사이의 확률값이 아닌 A와 B 사이의 관계 파악 용도로 사용됨
- : 상호대체 ➡️ A와 B는 반비례
- : 상호보완 ➡️ A와 B는 정비례
- : 독립 ➡️ A와 B는 서로에게 영향 끼치지 않음
More on Association Rule Mining
-
Brute Force : heavy한 계산량
- 연관관계에 대해 하나씩 전부 평가
- Minimum Support Threshold, Minimum Confidence Threshold
-
Frequent Itemset Generation (Brute Force를 좀 더 효율적으로)
- 빈도수 높은 관계 위주로 후보군 축소하여 rule mining
- Apriori Principle: 데이터 발생빈도를 바탕으로 연관관계 파악에 사용
-
User-based CF & Item-based CF ➡️ Rule-based로 생각해볼 수 있음
- ex) User-based: 내가 어떤 user와 비슷하다는 것을 thres hold를 정해놓고 룰을 만들 수 있겠지
-
이산형 변수로 데이터 profile 통해 association rule 적용
- Profile Association Rule
