프로세스
실행 중인 프로그램
프로그램을 실행하면 OS로부터 자원을 할당받아 프로세스가 된다
프로세스의 자원을 이용해서 실제로 작업을 수행하는 것이 쓰레드
CPU의 코어는 한번에 하나의 작업만 수행 가능
코어가 짧은 시간 동안 여러 작업을 번갈아 가면 수행하여 여러 작업들이 동시에 수행되는 것 처럼 보이게 함
멀티쓰레딩
하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것
장점
1. CPU의 사용률 향상
2. 자원을 효율적으로 사용
3. 사용자에 대한 응답성 향상
4. 작업이 분리되어 코드가 간결해짐
단점
1. 동기화 문제
2. 데드락 문제
쓰레드 구현 방법
- Thread클래스 상속
다른 클래스를 상속 받을 수 없는 단점 존재함
Thread 클래스의 메서드를 직접 호출가능 - Runnable 인터페이스를 구현
재사용성 높고 코드의 일관성 유지할수 있음
Thread 클래스의 메서드를 호출하기 위해서는 .currentThread()를 사용해야함
start() 와 run()
run() 은 쓰레드를 실행시키는 것이 아니라 단순히 클래스에 선언된 메서드를 호출하는 것
start() 은 새로운 쓰레드를 생성해서 run()을 호출하고 종료됨
쓰레드 예외
한 쓰레드가 예외가 발생하여 종료되어도 다른 쓰레드는 종료되지 않는다.
싱글쓰레드와 멀티쓰레드
두 개의 작업을 하나의 쓰레드로 처리하는 경우 : 한 작업 끝내고 다음 작업
두개의 쓰레드로 처리하는 경우 : 두 쓰레드가 번갈아 가며 작업을 수행
작업 수행시간은 거의 같고 context switching 에 시간이 걸려 두개의 쓰레드로 처리하는 경우가 조금 더 오래 걸린다.
단순히 CPU만을 사용하는 계산작업이라면 싱글쓰레드로 프로그래밍하는 것이 더 효율적이다.
두 쓰레드가 서로 다른 자원을 사용하는 작업의 경우에는 싱글쓰레드 보다 멀티쓰레드가 더 효율적이다.
쓰레드의 우선순위
쓰레드는 멤버변수로 priority를 가지고 있다
이 값에 따라 쓰레드가 얻는 작업시간이 달라진다.
우선순위 값의 범위는 1~10
숫자가 높은수록 우선순위가 높다
우선순위는 쓰레드를 생성한 쓰레드로부터 상속받는다
main쓰레드는 우선순위 값이 5
setPriority(int newPriority) 으로 우선순위 지정가능
쓰레드의 우선순위와 관련된 구현이 JVM마다 다를수 있다.
이는 OS의 스케쥴러에 종속적인 부분
확실하게 하려면 우선순위 큐를 사용하여 우선순위가 높은 작업을 먼저 실행시키도록 한다.
쓰레드 그룹
서로 관련된 쓰레드를 그룹으로 다루기 위한 것
폴더처럼 그룹 안에 다른 그룹을 포함시킬 수 있다.
보안산의 이유로 도입된 개념
자신이 속한 그룹이나 하위 그룹은 변경 가능, 다른 그룹의 쓰레드는 변경 불가
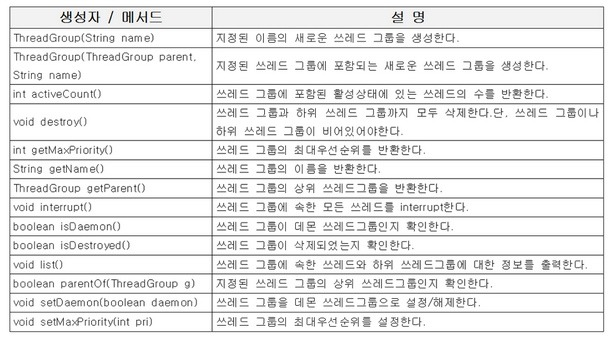
그룹을 지정해두지 않으면 자신을 생성한 쓰레드와 같은 쓰레드 그룹에 속하게 된다.
자파 어플리케이션이 실행되면 JVM은 main, system 쓰레드 그룹을 만든다.
main 쓰레드 그룹은 main 메서드를 실행하는 쓰레드를 포함
system 쓰레드 그룹은 가비지컬렉션을 수행하는 쓰레드를 포함
데몬 쓰레드 (daemon thread)
다른 일반 쓰레드의 작업을 돕는 보조적인 역할을 수행하는 쓰레드
일반 쓰레드가 모두 종료되면 데몬 쓰레드는 강제 자동 종료됨
ex) 가비지컬렉터, 워드프로세서 자동저장, 화면자동갱신
무한루프와 조건문을 이용해서 실행 후 대기하고 있다가 특정 조건이 만족되면 작업을 수행하고 다시 대기하도록 작성함
데몬 쓰레드가 생성한 쓰레드는 자동으로 데몬 쓰레드가 됨
쓰레드 실행제어 메서드
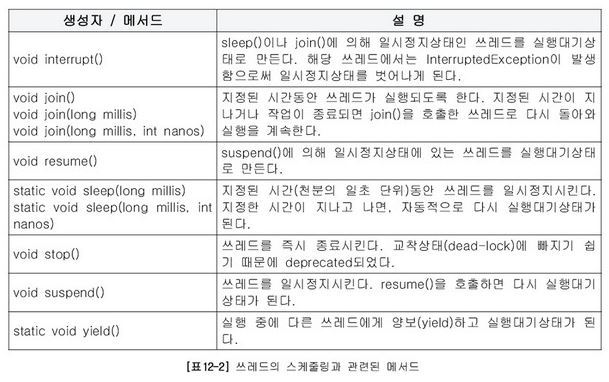
suspend, stop은 데드락 발생시키기 쉬워 권장되지 않는다
쓰레드의 상태
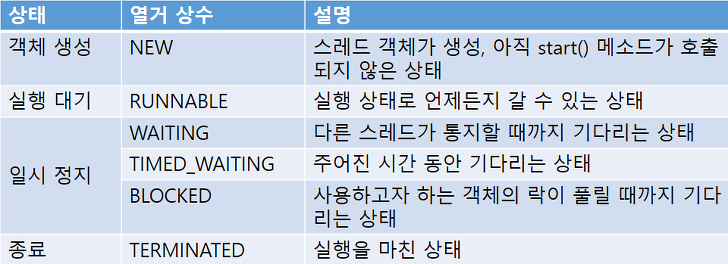
쓰레드의 동기화
한 쓰레드가 진행중인 작업을 다른 쓰레드가 간섭하지 못하도록 막는 것
다른 쓰레드가 작업 중이던 공유 데이터를 변경하면 작업 결과가 의도치 않게 나올 수 있음
-
메서드 앞에 synchronized 를 붙인다
메서드 전체가 critical section으로 설정된다. -
메서드 내부 코드 일부를 블럭으로 감싸고 'synchronized(참조변수)'를 붙인다.
블럭 안으로 들어가면 참조변수로 설정한 객체의 lock을 얻고
밖으로 나가면 lock을 반납한다.
critical section 설정을 프로그램 성능에 큰 영향을 미치므로 범위를 최소화 해야한다.
wait(), notify()
wait() : 특정 쓰레드가 객체의 락을 가진 상태로 코드를 수행하다 작업을 당장 하기 힘든 상황이라면 wait을 사용하면 쓰레드가 락을 반납하고 대기한다.
notify() : 이후 작업을 진행할 수 있게 되었을때 notify를 사용하면 다시 락을 얻어 작업을 진행할 수 있다.
wait, notify는 선별적인 통지가 불가능하여 여러 쓰레드가 lock을 얻기위해 서로 경쟁하는 race condition이 된다.
Lock
lock 클래스 : JDK1.5에서 추가됨
ReentrantLock : 재진입이 가능한 가장 일반적인 배타 lock
ReentrantReadWriteLock : 읽기를 위한 lock과 쓰기를 위한 lock을 제공
읽기 lock이 걸려 있으면 쓰기 lock은 바로 얻을 수 없고 풀릴때 까지 기다려야함
StampedLock : 읽기를 위한 lock, 쓰기를 위한 lock, 낙관적 읽기를 위한 lock
낙관적 읽기 lock은 쓰기 lock 얻으면 바로 풀림
이후 쓰기 lock이 풀리면 다시 lock 얻어와서 읽음
Condition
특정 쓰레드에 lock을 주는 방법
lock.newCondition 으로 생성한뒤
await, signal로 wait, notify 가능
starvation, race condition을 조금 줄여줌
volatile
코어는 메모리에서 읽어온 값을 각 코어의 캐시에 저장하고 캐시에서 값을 읽어서 작업한다
작업 도중에 메모리에 저장된 변수의 값이 변경되어도 캐시에 갱신되지 않아서 값이 다른 경우가 발생할 수 있다
변수 앞에 volatile을 붙이면 코어가 해당 변수 값을 읽어올때 캐시가 아닌 메모리에서 읽어오기 때문에 불일치 문제를 해결할 수 있다
8 바이트 타입을 읽거나 쓸때 4바이트 단위로 읽기 때문에 읽는 중간에 다른 쓰레드가 끼어들 수 있다
이때 변수에 volatile을 붙이면 atomic하게 되어 다른 쓰레드가 끼어들수 없다
fork & join 프레임웍
JDK1.7 부터 추가됨
하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게해줌
ForkJoinPool : 프레임 웍에서 제공하는 쓰레드 풀, 지정된 수의 쓰레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게함
쓰레드 반복 생성하지 않아도 됨
쓰레드 생성 수 제한하여 성능 저하 막아줌
수행해야하는 작업을 큐에 담에서 순서대로 처리함
fork 로 큐에 작업을 추가
join으로 작업의 결과 확인, 작업이 안끝났으면 끝날때 까지 기다렸다가 결과 반환
작업을 나누고 합치는데 걸리는 시간이 있어 더 느릴수도 있음
테스트를 해보고 이득인 경우에 사용
