퓨삿 러닝은 제한된 라벨 데이터하에 관찰된 적없는 클래스를 예측하려고 학습을 진행하는 것을 목표로 한다. 이 과정에서 무한히 많은 알고리즘들이 등장하였는데, 저자는 이러한 알고리즘들의 비교를 하여 인사이트를 뽑아냈다. 1) 우선, 깊은 backbone network를 사용할수록 데이터셋에 따른 성능 차이가 줄어든다는 점을 발견하였다. 2) 또한, 수정된 베이스라인 메소드가 상당히 경쟁력 있는 성능을 내었다는 점, 3) 그리고 각 알고리즘들의 cross-domain generalization 능력을 평가할 수 있는 실험 환경을 새로 제안하였다.
1. Introduction
현 딥러닝 모델들은 새로운 시각적 개념을 배우는 데에 있어서 한계를 지니고 있다. 반대로, 인간의 시각은 단지 몇개의 라벨들을 통해서 새로운 클래스를 잘 분류해낼 수 있다. 이러한 이유로, 새로운 클래스를 구분해내는데에 있어 한정된 자원만을 이용하는 연구가 활발히 진행되고 있다.
Limitation
다만 이러한 퓨삿 분류 알고리즘은 두가지의 challenge가 있다. 첫번째로는, 구현 세부 사항의 불일치가 알고리즘들간의 상대적인 비교를 불가능하게 만든다. 그래서, 베이스라인 모델들이 상당수 과소평가되었을 가능성도 존재한다. 두번째로는, 현재의 평가지표는 제한된 학습 데이터로 새로운 클래스를 예측하는 것에 중점을 두었는데, 이러한 새로은 클래스는 사실 크게 보면 같은 데이터셋에서 등장했을 가능성이 크다. 예를 들어, 개, 고양이를 분류하는 모델로 여우를 분류하는 모델을 학습시킬 수 있는데, 동일하게 '동물' 데이터에서 등장하였다고 가정할 수 있다. 이 모델로 갑자기 차를 분류하는 모델로 학습시키면 어떻게 될까? 도메인이 급격하게 바꼈으므로 잘 학습이 되지 않을 가능성이 크다. 이런 식으로 도메인이 바뀌는 경우에 대한 평가지표가 불분명하다.
Our work & contributions
저자는 이를 해결하기 위해 여러가지 연구를 진행했다. 1) 여러 퓨삿 메소드를 동일한 환경에서 성능을 테스트 해보았다. 그 결과 깊은 백본 모델일수록 다른 여러 메소드 들간의 성능 차이가 줄어든다는 점을 볼 수 있다. 두번째로는, 선형 분류기를 거리 기반 분류기로 바꿈으로써 베이스라인 모델이 일반 소타모델과 비교하여 훨씬 경쟁력 있어졌다는 것을 볼 수 있다. 세번째로는, 기존 클래스와 새로운 클래스간의 domain shift가 발생하였을 때 실용적으로 평가할 수 있는 환경을 제안하였다. (예를 들어, 일반적인 카테고리에서 베이스 클래스를 샘플링하고, 새로운 클래스는 fine-grained(미세한?) 카테고리에서 샘플링을 하는 방법이다.) 이러한 세팅 하에서는 정교한 퓨삿러닝 알고리즘이 베이스라인에 비해 성능 측면에서의 발전을 제공하지 못한다는 점을 발견하였다.
1) 공정한 비교를 위해 알고리즘들간의 통합된 테스트배드를 제공한다.
2) 거리기반 베이스라인 모델이 훨씬 좋은 성능을 낸다.
3) 새로운 클래스와 베이스 클래스가 각각 다른 도메인에서 뽑혔을 때 공정하게 평가할 수 있는 환경 세팅을 제안하였다. 그 결과 현 퓨삿 알고리즘들은 domain shift가 발생하는 환경에서는 베이스라인 성능에 뒤쳐진다는 결과를 도출했다.
2. Related work
Initialization based methods: "learning to fine-tune"
이 접근법은 좋은 모델 초기화방법을 배우는 데에 목표를 둔다. 이를 통해 분류기가 적은 업데이트 스텝과 적은 라벨 데이터로도 효과적으로 학습할 수 있게끔 해주는 것이다. 다른 것은 optimizer 자체를 학습하는 것이다.
Distance metric learning based methods: "learning to compare"
해당 방법론은 두 이미지들의 유사성을 모델이 결정할 수 있다면, 이는 관찰되지 않은 이미지와 라벨링된 이미지들을 구분해낼 수 있다는 직관에서 비롯되었다. 이를 위해 distance나 metric을 고려하여 예측을 진행하도록 학습을 시켰다. 그 결과, 거리 기반 분류기 + 베이스라인 모델이 다른 정교한 알고리즘과 비교하였을 때 꽤 경쟁력있는 결과를 도출해냈다.
Hallucination based methods: "learning to augment"
이 방법은 모델의 베이스 클래스로부터 generator를 생성하고, 이러한 generator를 이용해 새로운 클래스 데이터에 적용하여 data augmentation하는 방법을 일컫는다. 하나는 베이스 클래스에 존재하는 모든 variation을 잘학습하는 것을 목표로 한다.(GAN) 다른 접근법은 무엇을 transfer할지는 명시하지 않았지만, 메타러닝 알고리즘에 generator를 통합한 방법이 있다고 한다. 다만 이 논문에서는 해당 접근법에 대해 따로 다루지 않았다.
3. Overview of few-shot classification algorithms
3.1 Baseline
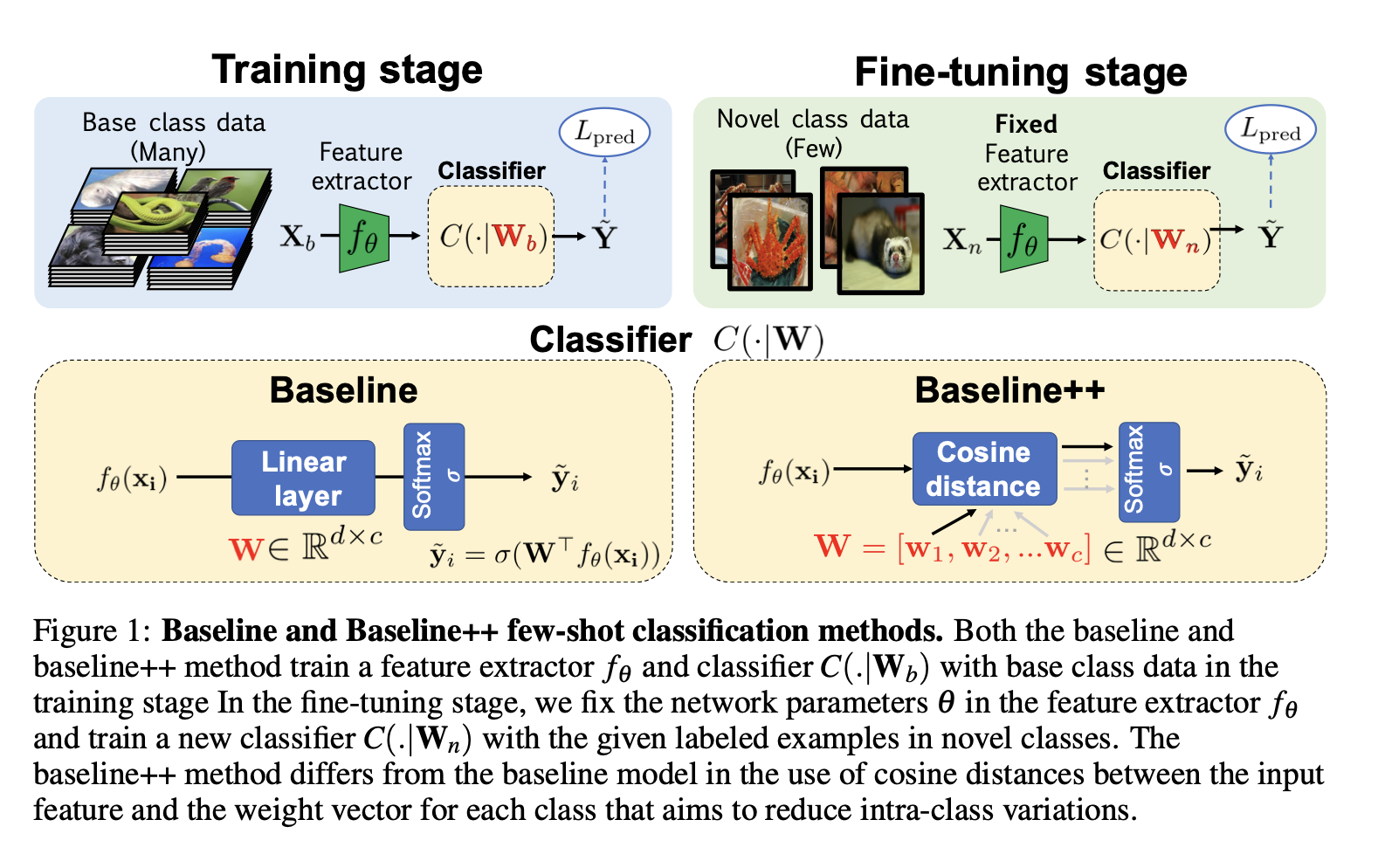
Training stage
저자는 feature extractor인 와 classifier인 를 cross entropy loss를 이용해 학습을 시켰다. 이때 인코딩된 feature은 d, output class의 개수는 c라고 지정하였다. classifier인 은 로 구성되었다.
Fine-tuning stage
새로운 클래스에 대해 모델을 학습시키기 위해, pretrained network인 는 fix시키고, 새로운 classifier인 을 학습시켰다.
3.2 Baseline++
더불어 학습 중 클래스 내 변이를 명시적으로 줄이는 모델인 Baseline++를 구현했다. 기존 모델과 유사하게 base class를 구분하는 weight인 와 새로운 클래스를 구분하는 weight인 을 지니고 있다. 이러한 디자은 베이스라인과는 사실 다른 형태를 띄고 있다. 를 만약 로 적어보았을 때, 각 class는 d차원의 weight을 지니고 있다. 학습 단계에서는 input feature과 각 클래스들의 weight vector들간의 유사도를 구한다. 처럼 구해지고, softmax 함수를 이용해 각 클래스에 속할 확률을 구해낸다. 이때 유사도로는 코사인 유사도를 사용한다.
3.3 Meta-learning Algorithms
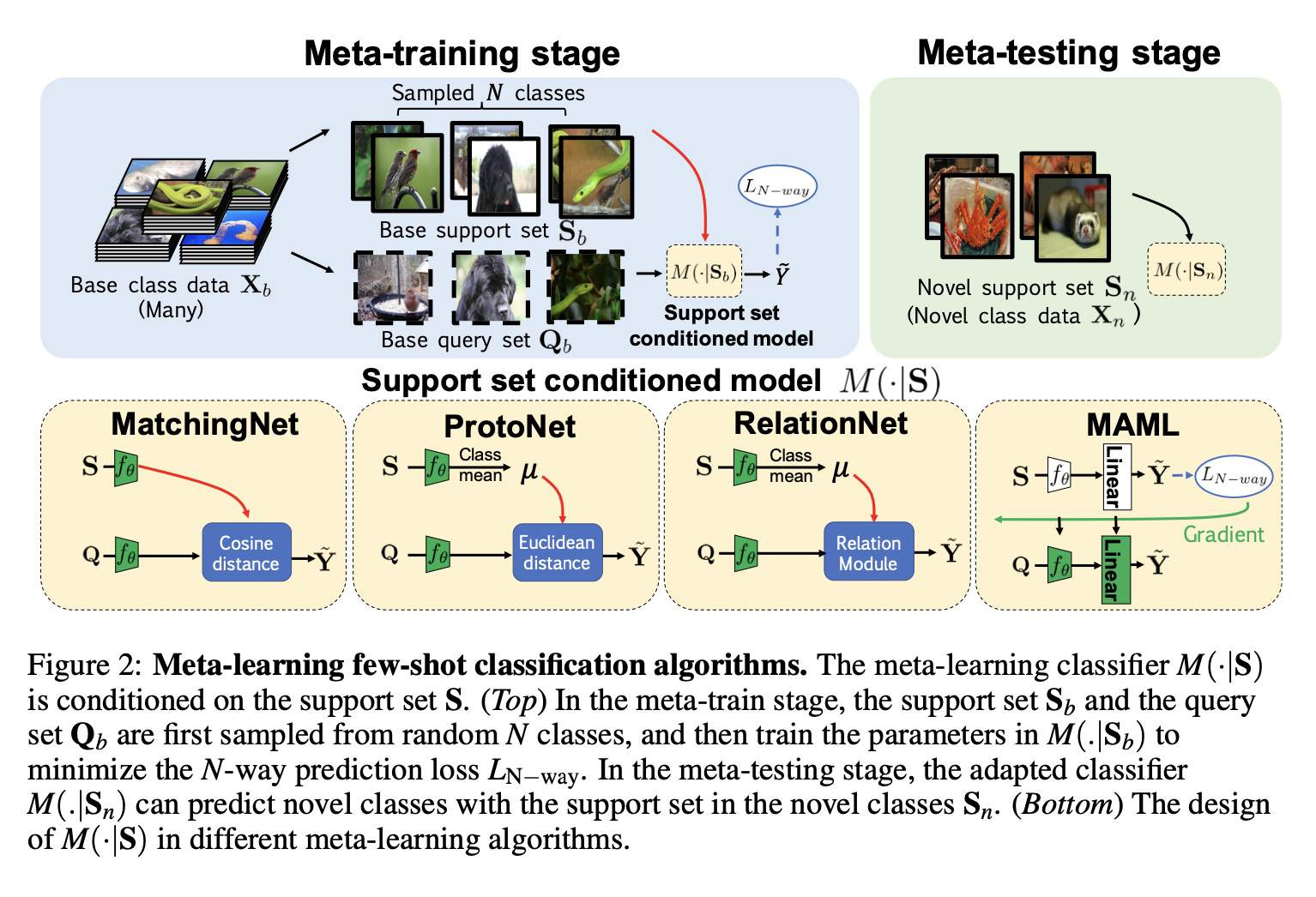
저자는 여러개의 메타러닝 메소드를 사용하였는데, mathingnet, protonet, relationnet 그리고 maml을 사용하였다.
meta-learning training stage에서는, 1) 우선 랜덤하게 n개의 클래스를 뽑는다. 그리고, 해당 클래스를 바탕으로 supprt set와 query set을 만든다. 이때 목표는 N-way Prediction loss를 줄이는 것을 목표로 하였다. 사이즈가 작은 support set을 기반으로 학습이 진행되었기 때문에, 모델은 적은 데이터가 주어졌을 경우 어떻게 학습을 해야하는지 자체를 배웠다고 볼 수 있다.
meta-learning testing stage에서는 새로운 클래스에 대한 support set의 클래스를 예측하도록 adapt시킨다. 그리고, 사용한 각 메소드들간의 설명은 아래와 같다.
- MatchingNet (Cosine distance)
- ProtoNet (클래스 간 평균의 유클리드 거리)
- RelationNet (Relation Module을 통해 자동으로 연산)
- MAML (support set이 몇번의 그래디언트 업데이트를 통해 파라미터를 초기화하는데 사용된다. 여러 support set의 loss를 통해 gradient update를 한다.)
4. Experimental results
4.1 Experimental setup
Datasets and scenarios
총 3가지 시나리오에서 few-shot classification 문제를 다뤄보았다.
1) generic object recognition
- ImageNet에서 추출한 100개의 클래스, 클래스당 600장의 이미지 포함
2) fine-grained image classification - 200개의 클래스, 총 11788 이미지
3) cross-domain adaptation - mini-ImageNet으로 pretrain, CUB으로 fine-tuning 및 validation
4.2 Evaluation using the standard setting
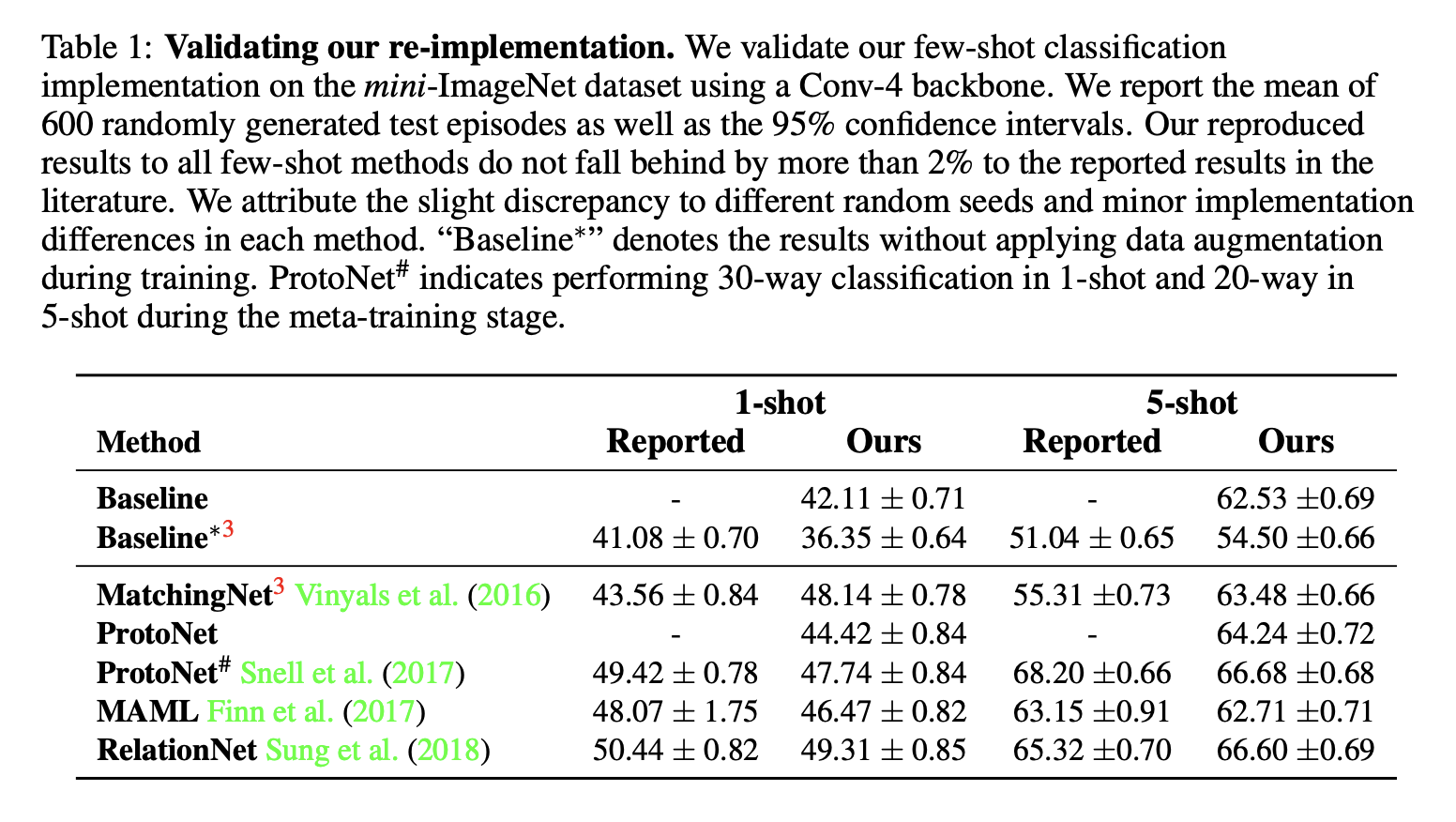
테스팅 환경을 동일화하고 난 후에는 모델들간의 성능 차이가 크지 않음을 알 수 있다. 성능 차이가 존재하는 부분은 Augmentation의 적용 혹은 Meta Learning에서 구현 디테일 차이에 의해 비롯됐다고 한다.
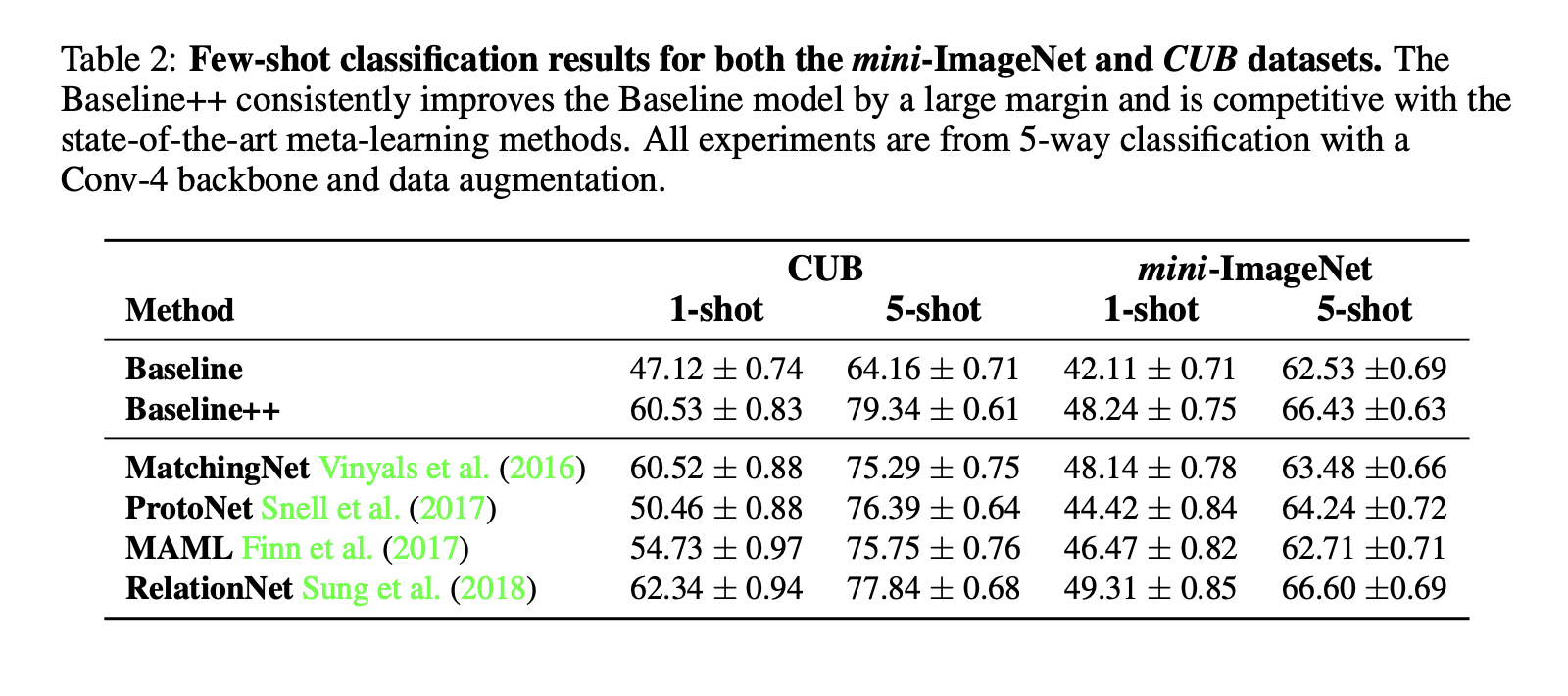
4.3 Effect of increasing the network depth
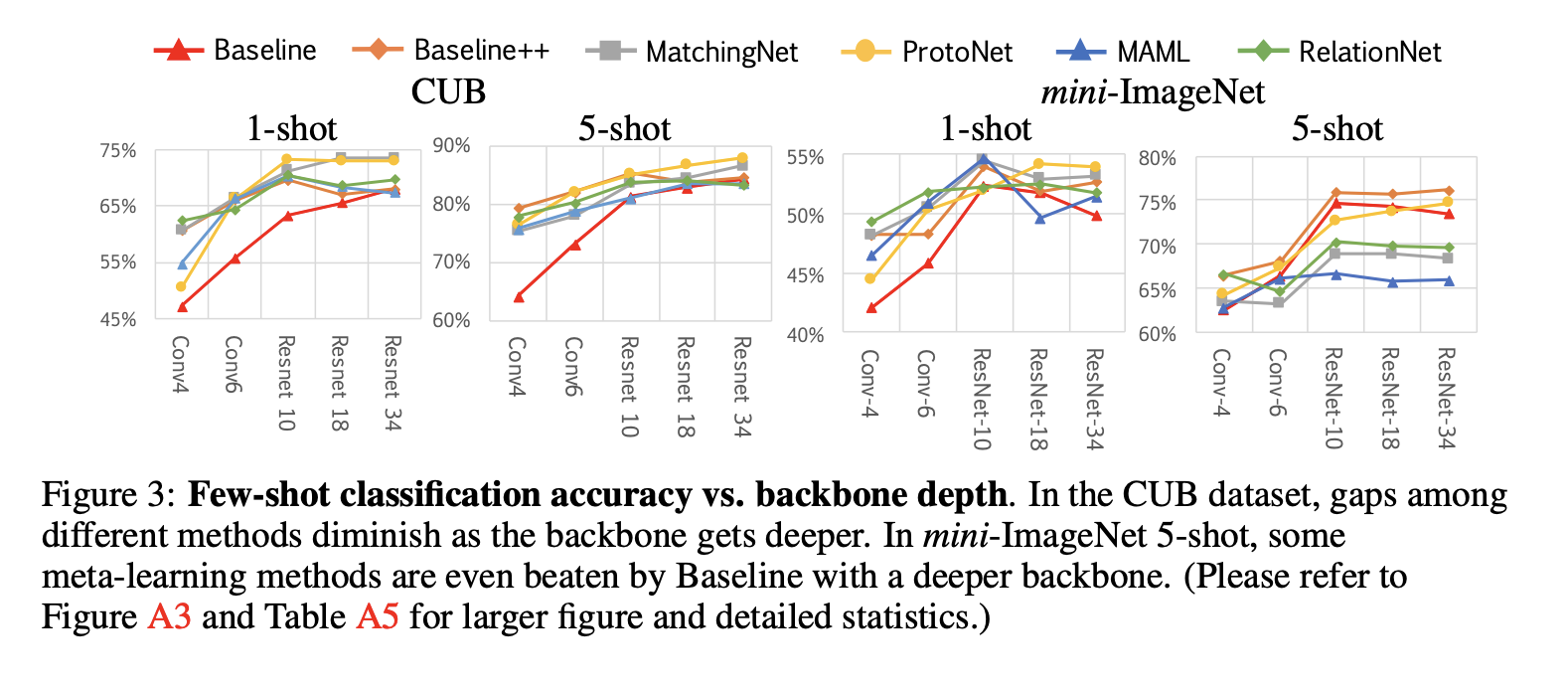
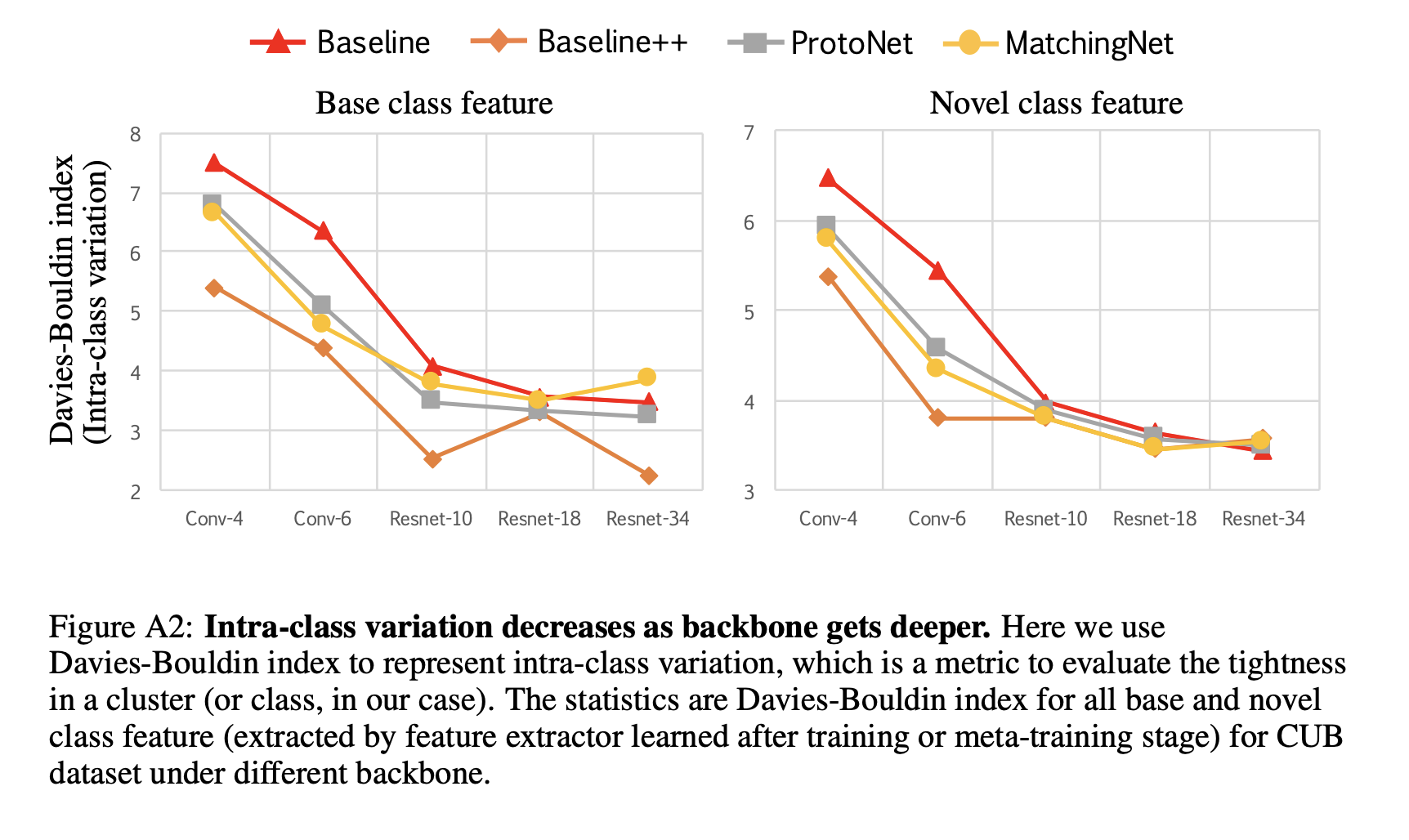
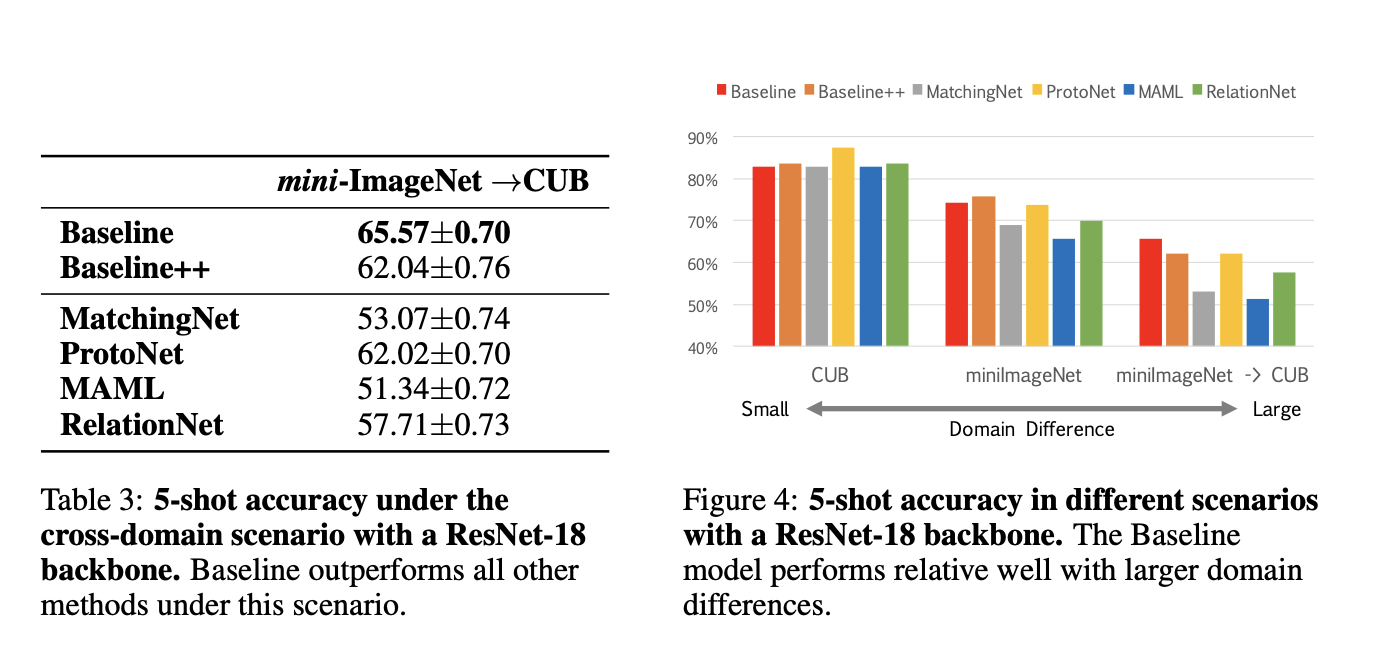
4.4 Effect of domain differences between base and novel classes
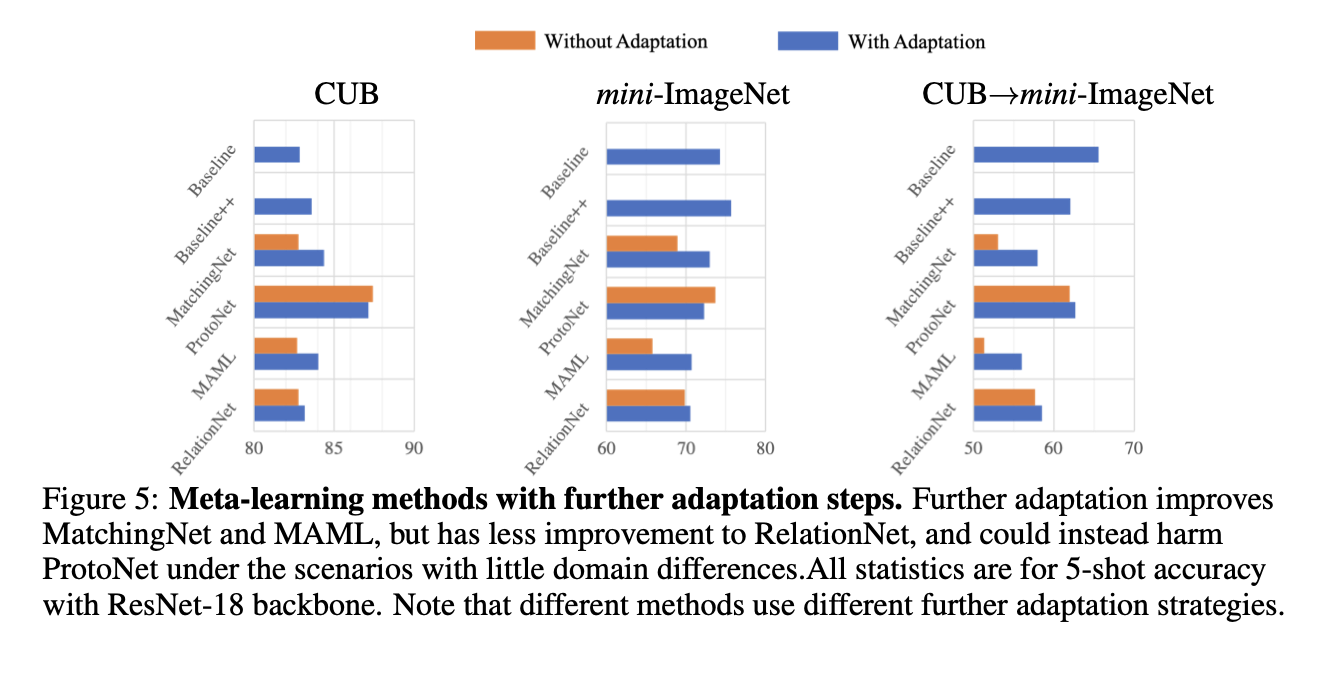
4.5 Effect of further adaptation
5. Conclusion
Baseline++ 모델이 경쟁력이 있고, Baseline 모델이 더 깊은 특징 백본을 사용할 때 CUB와 mini-ImageNet 벤치마크 데이터셋에서 좋은 성능을 발휘함을 알 수 있었다. 또한, 현실적인 시나리오(기존 클래스와 새로운 클래스 간에 도메인 이동이 존재하는 경우)에서는 Baseline 모델이 평가된 모든 메타 학습 알고리즘보다 우수한 성과를 보임을 알 수 있었다.
코드 github
