numpy
교재 110p.
numpy 설치
- cmd창에서 설치
- 파이참에서 설치
ch04
ex1.py : numpy 사용
# ch04/ex1.py
# numpy 사용해보기(교재 110p)
import numpy as np
# print(np.__version__)
ar1 = np.array([1, 2, 3, 4, 5])
print(ar1) # [1 2 3 4 5]
print(type(ar1)) # <class 'numpy.ndarray'>
ar2 = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])
print(ar2)
ar3 = np.arange(1, 11, 2) # 1에서 11까지의 범위, 증가값 2 (리스트로 리턴)
print(ar3) # [1 3 5 7 9]
ar4 = np.arange(1, 31, 3) # 1에서 31까지의 범위, 증가값 3 (리스트로 리턴)
print(ar4) # [ 1 4 7 10 13 16 19 22 25 28]
ar5 = np.array([1, 2, 3, 4, 5, 6]).reshape(3, 2) # 3행 2열로 출력
print(ar5) # [[1 2]
# [3 4]
# [5 6]]
ar6 = np.zeros((2, 3)) # 0값을 2행 3열로 출력
print(ar6) # [[0. 0. 0.]
# [0. 0. 0.]]
ar7 = np.array([[10, 20, 30], [40, 50, 60]])
ar8 = ar7[0:2, 0:2] # 0:2에서 0은 인덱스 번호, 2는 가져올 개수
print(ar8) # [[10 20]
# [40 50]]
ar9 = ar7[0:]
print(ar9) # [[10 20 30]
# [40 50 60]]
ar10 = ar7[0, :] # index 0번째 데이터만 다 가져오기
print(ar10) # [10 20 30]
ar11 = np.array(([1, 2, 3, 4, 5]))
ar12 = ar11 + 10 # 배열 내부의 각 데이터에 10씩 더함
print(ar12) # [11 12 13 14 15]
ar13 = ar11 + ar12 # [1, 2, 3, 4, 5] + [11 12 13 14 15]
print(ar13) # [12 14 16 18 20]
ar14 = ar13 * 2 # [12 14 16 18 20] * 2
print(ar14) # [24 28 32 36 40]ex2.py : pandas 사용
# ch04/ex1.py
# pandas 사용해보기
import pandas as pd
print(pd.__version__)
data1 = [10, 20, 30, 40, 50]
data2 = ['1반', '2반', '3반', '4반', '5반']
sr1 = pd.Series(data1) # Series 자료형
print(sr1) # 0 10
# 1 20
# 2 30
# 3 40
# 4 50
# dtype: int64
sr2 = pd.Series(data2)
print(sr2) # 0 1반
# 1 2반
# 2 3반
# 3 4반
# 4 5반
# dtype: object
sr3 = pd.Series([101, 102, 103, 104, 105])
sr4 = pd.Series(['월', '화', '수', '목', '금'])
sr5 = pd.Series(data1, index=[1001, 1002, 1003, 1004, 1005]) # 인덱스 값 지정 가
print(sr5) # 1001 10
# 1002 20
# 1003 30
# 1004 40
# 1005 50
# dtype: int64
sr6 = pd.Series(data1, index=data2)
print(sr6) # 1반 10
# 2반 20
# 3반 30
# 4반 40
# 5반 50
# dtype: int64
sr7 = pd.Series(data2, index=data1)
print(sr7) # 10 1반
# 20 2반
# 30 3반
# 40 4반
# 50 5반
# dtype: object
sr8 = pd.Series(data2, index=sr4)
print(sr8) # 월 1반
# 화 2반
# 수 3반
# 목 4반
# 금 5반
# dtype: object
print(sr8[2]) # 자리값 inde의 값 : 3반
print(sr8['수']) # 지정한 index의 값: 3반
print(sr8[-1]) # 뒤에서 첫번째 인덱스의 값 : 5반
print(sr8[0:4]) # 월 1반
# 화 2반
# 수 3반
# 목 4반
print(sr8.values) # ['1반' '2반' '3반' '4반' '5반']
print(sr1 + sr3)
# 0 111
# 1 122
# 2 133
# 3 144
# 4 155
# dtype: int64
print(sr4 + sr2)
# 0 월1반
# 1 화2반
# 2 수3반
# 3 목4반
# 4 금5반
# dtype: objectex3.py : data frame 사용
# ch04/ex3.py
import pandas as pd
data_dic = {
'year': [2018, 2019, 2020],
'sales': [350, 480, 1099]
}
print(data_dic) # {'year': [2018, 2019, 2020], 'sales': [350, 480, 1099]}
df1 = pd.DataFrame(data_dic) # 데이터를 틀에 맞게 가공해줌
print(df1)
# year sales
# 0 2018 350
# 1 2019 480
# 2 2020 1099
data2 = ['1반', '2반', '3반', '4반', '5반']
df2 = pd.DataFrame([[89.2, 92.5, 90.8], [92.8, 89.9, 95.2]],
index=['중간고사', '기말고사'], columns=data2[0:3])
print(df2)
# 1반 2반 3반
# 중간고사 89.2 92.5 90.8
# 기말고사 92.8 89.9 95.2
data_df = [['20201101', 'Hong', '90', '95'],
['20201102', 'Kim', '93', '94'],
['20201103', 'Lee', '87', '97']]
df3 = pd.DataFrame(data_df)
print(df3)
# 0 1 2 3
# 0 20201101 Hong 90 95
# 1 20201102 Kim 93 94
# 2 20201103 Lee 87 97
df3.columns = ['학번', '이름', '중간고사', '기말고사'] # df3에 컬럼 추가
print(df3)
# 학번 이름 중간고사 기말고사
# 0 20201101 Hong 90 95
# 1 20201102 Kim 93 94
# 2 20201103 Lee 87 97
print(df3.head(2)) # 위에서 2행 출력
print(df3.tail(2)) # 밑에서 2행 출력
print(df3['이름'])
# 0 Hong
# 1 Kim
# 2 Lee
df3.to_csv('./data/score.csv', header=True, encoding='utf-8-sig')
df3.to_csv('./data/score1.csv', header=False, encoding='utf-8-sig')
df4 = pd.read_csv('./data/score.csv', encoding='utf-8', index_col=0)
print(df4)
# 학번 이름 중간고사 기말고사
# 0 20201101 Hong 90 95
# 1 20201102 Kim 93 94
# 2 20201103 Lee 87 97
df5 = pd.read_csv('./data/score.csv', encoding='utf-8', index_col='학번')
print(df5)
# 0 이름 중간고사 기말고사
# 학번
# 20201101 0 Hong 90 95
# 20201102 1 Kim 93 94
# 20201103 2 Lee 87 97ex4.py : 시각화
# ch04/ex5.py
import matplotlib.pyplot as plt
x = [2016, 2017, 2018, 2019, 2020]
y = [350, 410, 520, 695, 543]
plt.plot(x, y)
plt.title('Annual Sales')
plt.xlabel('year')
plt.xlabel('sales')
plt.show()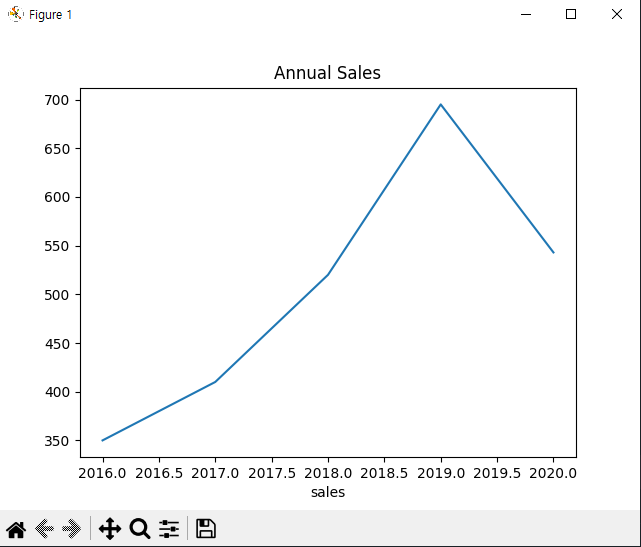
ex5.py : 시각화(막대그래프)
# ch04/ex5.py
import matplotlib.pyplot as plt
y1 = [350, 410, 520, 695]
y2 = [200, 250, 385, 350]
x = range(len(y1))
print(x) # range(0, 4)
plt.bar(x, y1, width=0.7, color='blue')
plt.bar(x, y2, width=0.7, color='red', bottom=y1) # 막대그래프 두개를 쌓은 모양
plt.title('Quarterly Sales')
plt.xlabel('Quarters')
plt.ylabel('Sales')
xLabel = ['first', 'second', 'third', 'fourth']
plt.xticks(x, xLabel, fontsize=10)
plt.legend(['chairs', 'desks']) # 범례
plt.show()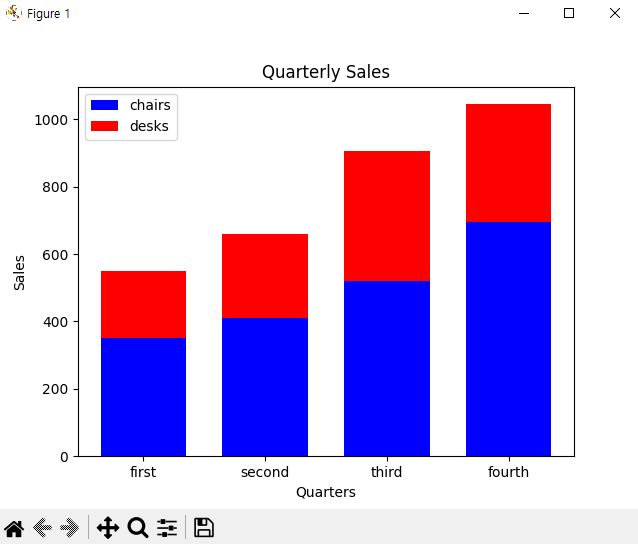
네이버 API를 이용한 크롤링
준비 : 네이버 개발자 센터 회원가입
https://developers.naver.com/main/
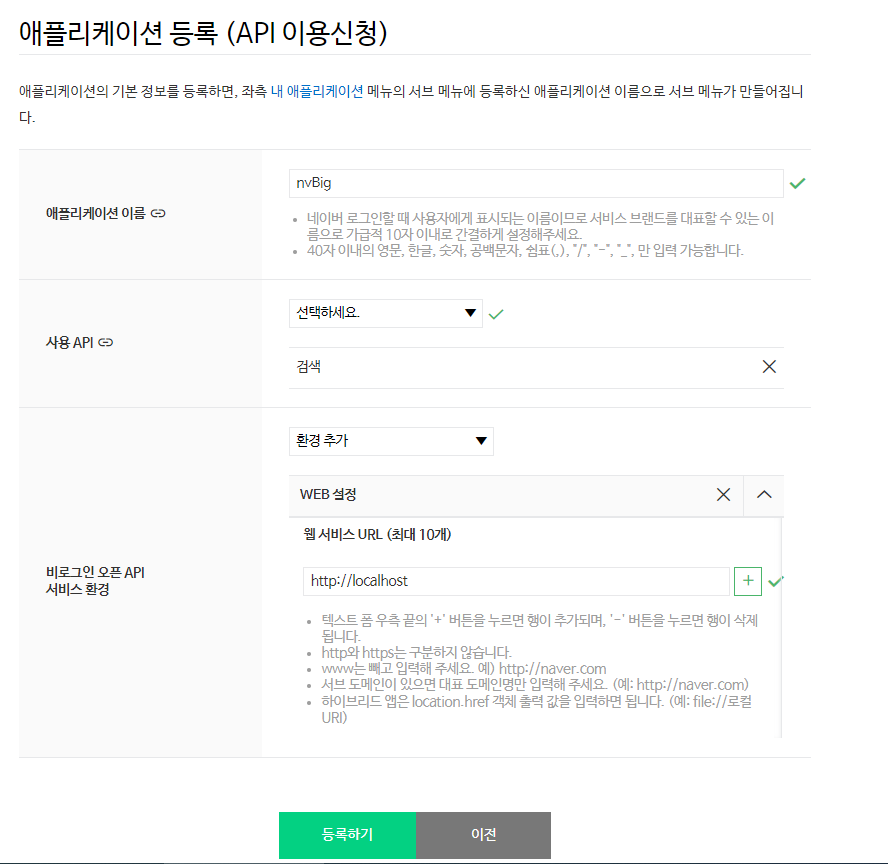
https://developers.naver.com/docs/serviceapi/datalab/search/search.md#python
ch05
nvCrawler.py : 크롤링 -> json 타입으로 파일 생성
# ch05/nvCrawler.py
import os, sys
import urllib.request
import datetime, time
import json
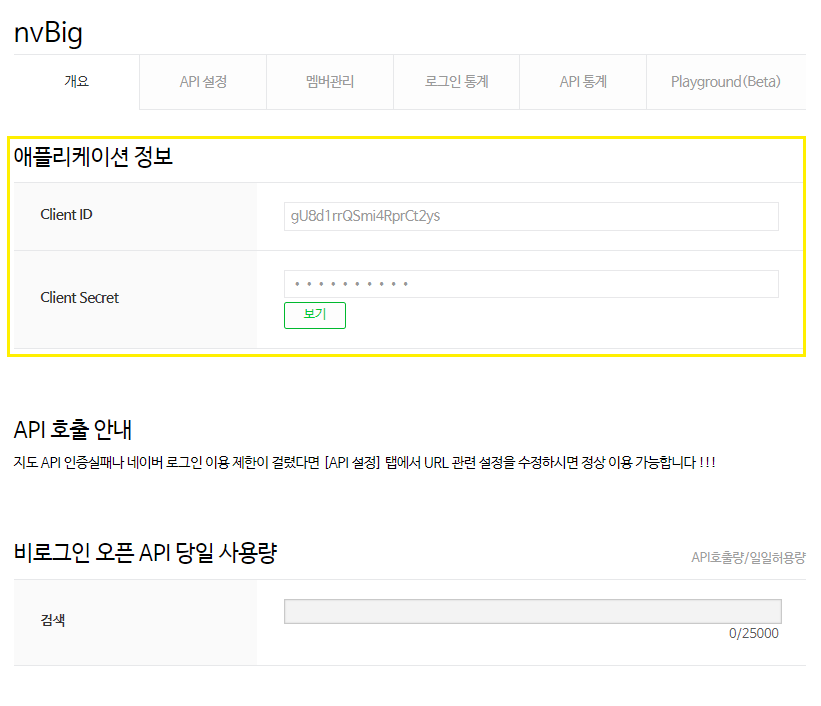
client_id = 'gU8d1rrQSmi4RprCt2ys'
client_secret = 'AqaCX_Xjil'
### [CODE 1] ###
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
### [CODE 2] ### : 네이버 뉴스를 반환하고, json 형식으로 변환
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
### [CODE 3] ### : json 데이터를 리스트 타입으로 변환
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'org_link': org_link, 'link': org_link, 'pDate': pDate})
return
### [CODE 0] ###
def main():
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
print('전체 검색 : %d 건' % total)
with open('./data/%s_naver_%s.json' % (srcText, node), 'w', encoding='utf-8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d 건" % (cnt))
print('%s_naver_%s.json SAVED' % (srcText, node))
if __name__ == '__main__':
main()
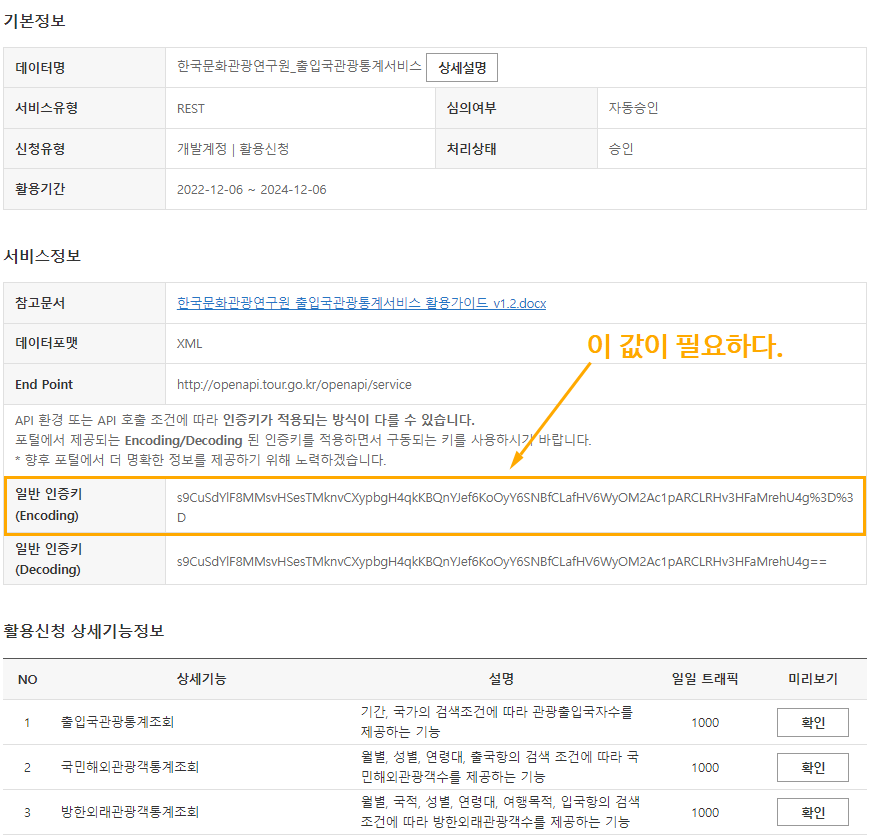
한국문화관광연구원_출입국관광통계서비스
https://www.data.go.kr/data/15000297/openapi.do
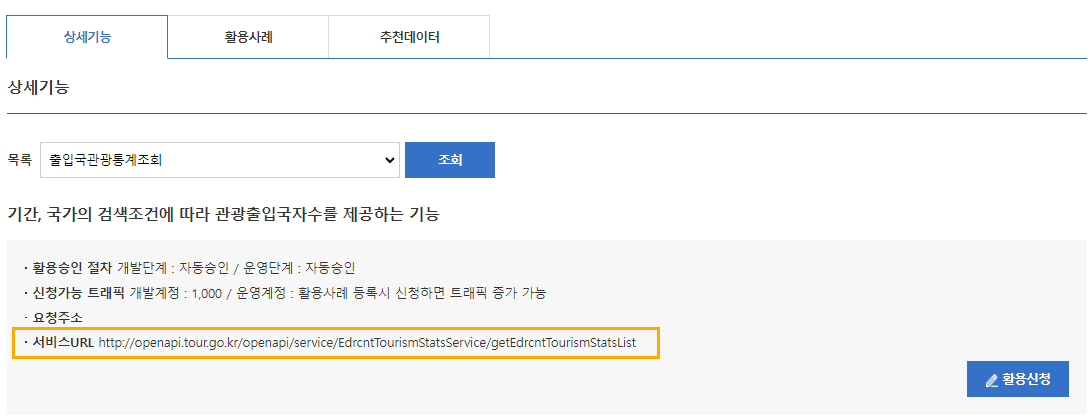
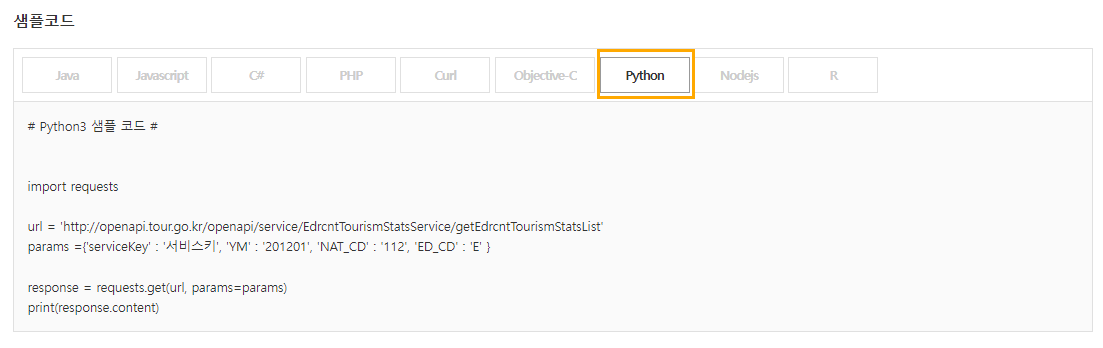
openapi_tour.py : xml 타입 api데이터 이용
# ch05/openapi_tour.py
import os, sys
import urllib.request
import datetime, time
import json
import pandas as pd
serviceKey = 's9CuSdYlF8MMsvHSesTMknvCXypbgH4qkKBQnYJef6KoOyY6SNBfCLafHV6WyOM2Ac1pARCLRHv3HFaMrehU4g%3D%3D'
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2] : url 구성하여 데이터 요청
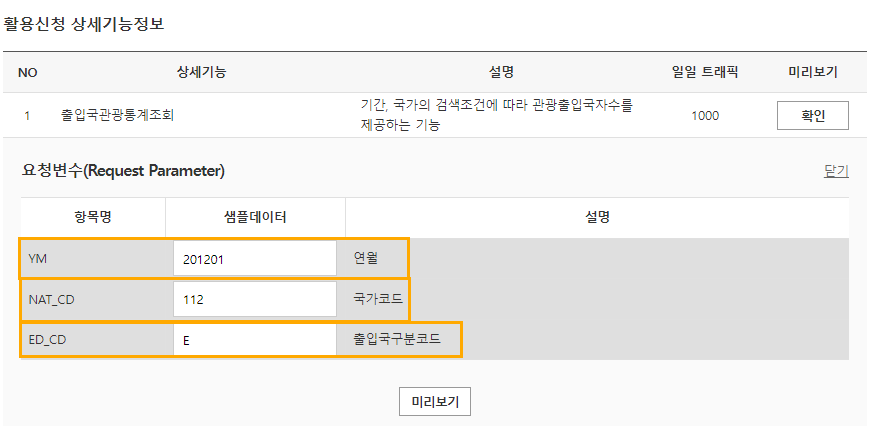
def getTourismStatsItem(yyyymm, national_code, ed_cd): # ed_cd : 방한외래관광객 or 해외 출국
service_url = 'http://openapi.tour.go.kr/openapi/service/EdrcntTourismStatsService/getEdrcntTourismStatsList'
parameters = "?_type=json&serviceKey=" + serviceKey # 인증키
parameters += "&YM=" + yyyymm
parameters += "&NAT_CD=" + national_code
parameters += "&ED_CD=" + ed_cd
url = service_url + parameters
retData = getRequestUrl(url) # [CODE 1]
if (retData == None):
return None
else:
return json.loads(retData)
# [CODE 3]
def getTourismStatsService(nat_cd, ed_cd, nStartYear, nEndYear):
jsonResult = []
result = []
natName = ''
dataEND = "{0}{1:0>2}".format(str(nEndYear), str(12)) # 데이터 끝 초기화
isDataEnd = 0 # 데이터 끝 확인용 flag 초기화
for year in range(nStartYear, nEndYear + 1):
for month in range(1, 13):
if (isDataEnd == 1): break # 데이터 끝 flag 설정되어있으면 작업 중지.
yyyymm = "{0}{1:0>2}".format(str(year), str(month))
jsonData = getTourismStatsItem(yyyymm, nat_cd, ed_cd) # [CODE 2]
if (jsonData['response']['header']['resultMsg'] == 'OK'):
# 입력된 범위까지 수집하지 않았지만, 더이상 제공되는 데이터가 없는 마지막 항목인 경우 -------------------
if jsonData['response']['body']['items'] == '':
isDataEnd = 1 # 데이터 끝 flag 설정
dataEND = "{0}{1:0>2}".format(str(year), str(month - 1))
print("데이터 없음.... \n 제공되는 통계 데이터는 %s년 %s월까지입니다."
% (str(year), str(month - 1)))
break
# jsonData를 출력하여 확인......................................................
print(json.dumps(jsonData, indent=4,
sort_keys=True, ensure_ascii=False))
natName = jsonData['response']['body']['items']['item']['natKorNm']
natName = natName.replace(' ', '')
num = jsonData['response']['body']['items']['item']['num']
ed = jsonData['response']['body']['items']['item']['ed']
print('[ %s_%s : %s ]' % (natName, yyyymm, num))
print('----------------------------------------------------------------------')
jsonResult.append({'nat_name': natName, 'nat_cd': nat_cd,
'yyyymm': yyyymm, 'visit_cnt': num})
result.append([natName, nat_cd, yyyymm, num])
return (jsonResult, result, natName, ed, dataEND)
# [CODE 0]
def main():
jsonResult = []
result = []
natName = ''
print('<< 국내 입국한 외국인의 통계 데이터를 수집합니다.>>')
nat_cd = input('국가 코드를 입력하세요(중국: 112 / 일본: 130 / 미국: 275) :')
nStartYear = int(input('데이터륾 몇년부터 수집할까요?'))
nEndYear = int(input('데이터륾 몇년까지 수집할까요?'))
ed_cd = 'E' # E : 발한외래관광객, D : 해외출국
jsonResult, result, natName, ed, dataEND = getTourismStatsService(nat_cd, ed_cd, nStartYear, nEndYear)
if (natName == ''):
print('데이터가 전달되지 않았습니다. 공공데이터포털의 서비스 상태를 확인하시기 바랍니다.')
else :
# 파일 저장 : json 파일
with open('./data/$s_$s5, %d_%s.json' % (natName, ed, nStartYear, dataEND), 'w', encoding='utf-8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
# 파일 저장 : ccsv 필요
if __name__ == '__main__':
main()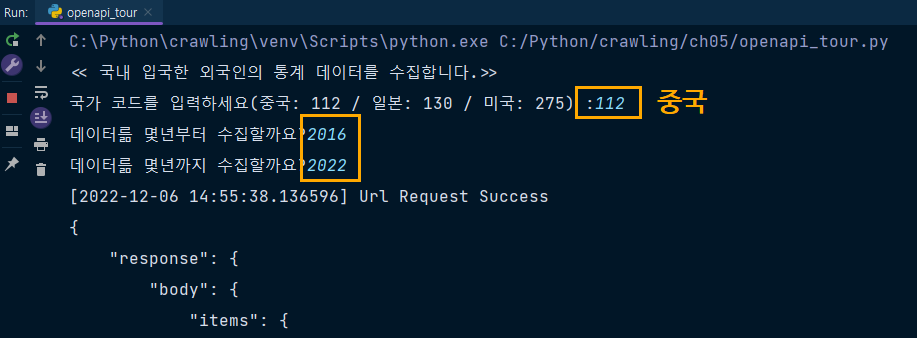
openapi_seoul.py
민주주의 서울 자유제안 정보
https://data.seoul.go.kr/dataList/OA-2563/S/1/datasetView.do
# ch05/openapi_seoul.py
import os, sys
import urllib.request
import datetime, time
import json
import pandas as pd
#서울열린광장에서 받은 개인 인증키
serviceKey = "5155506b6173696d37357446486963"
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2] '서울 열린테이터 광장 : 한 page에 5개만 display됨.
def getPage(start):
url = 'http://openapi.seoul.go.kr:8088/' + serviceKey + '/json/ChunmanFreeSuggestions/%d/%d' % (start, start + 4)
retData = getRequestUrl(url) # [CODE 1]
if (retData == None):
return None
else:
return json.loads(retData)
#[CODE 3] "서울 열린데이터 광장" : 최대 1000개까지만 제공
def getItemsAll():
result = []
for i in range(1000//5):
jsonData = getPage(i*5 +1) #[CODE 2]
if (jsonData['ChunmanFreeSuggestions']['RESULT']['CODE'] == 'INFO-100'):
print("인증키가 유효하지 않습니다!!")
return
if(jsonData['ChunmanFreeSuggestions']['RESULT']['CODE'] == 'INFO-000'):
for i in range(5):
SN = jsonData['ChunmanFreeSuggestions']['row'][i]['SN']
TITLE = jsonData['ChunmanFreeSuggestions']['row'][i]['TITLE']
CONTENT_link = jsonData['ChunmanFreeSuggestions']['row'][i]['CONTENT']
DATE = jsonData['ChunmanFreeSuggestions']['row'][i]['REG_DATE']
result.append([SN, TITLE, CONTENT_link, DATE])
return result
# [CODE 0]
def main():
jsonResult = []
result = []
print("<< 현재 기준 '민주주의 서울 자유 제안' 데이터 1000개를 수집합니다. >>")
result = getItemsAll()
# 파일 저장(csv)
columns = ['SN', 'TITLE', 'CONTENT_link', 'DATE']
result_df = pd.DataFrame(result, columns = columns)
result_df.to_csv('./data/민주주의서울자유제안.csv', index=False, encoding='cp949')
if __name__ == '__main__':
main()