네이버 블로그 크롤링(p.161)
함수 작성 전 기본 틀
nvCrawler_blog.py
# nvCrawler_blog.py : 네이버 블로그 크롤링
import os, sys
import urllib.request
import datetime, time
import json
client_id = 'gU8d1rrQSmi4RprCt2ys'
client_secret = 'AqaCX_Xjil'
# [CODE 1]
def getRequestUrl(url):
# [CODE 2]
def getNaverSearch(node, srcText, start, display):
# [CODE 3]
def getPostData(post, jsonResult, cnt):
# [CODE 4]
def main():
if __name__ == '__main__':
main()
네이버 블로그 크롤링 코드
nvCrawler_blog.py
# nvCrawler_blog.py : 네이버 블로그 크롤링
import os, sys
import urllib.request
import datetime, time
import json
client_id = 'gU8d1rrQSmi4RprCt2ys'
client_secret = 'AqaCX_Xjil'
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2]
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
# [CODE 3]
def getPostData(post, jsonResult, cnt):
title = post['title']
link = post['link']
description = post['description']
bloggername = post['bloggername']
pDate = post['postdate']
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'link': link, 'pDate': pDate, 'blogger': bloggername})
# [CODE 4]
def main():
node = 'blog'
srcText = input('검색어를 입력하세요 : ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
print('전체 검색 : %d 건' % total)
# indent=4 : 들여쓰기
with open('./data/%s_naver_%s.json' % (srcText, node), 'w', encoding='utf-8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print('가져온 데이터 : %d 건' % cnt)
print('%s_naver_%s.json SAVED' % (srcText, node))
if __name__ == '__main__':
main()/robots.txt
robots.txt 10분 안에 끝내는 총정리 가이드 : https://seo.tbwakorea.com/blog/robots-txt-complete-guide/
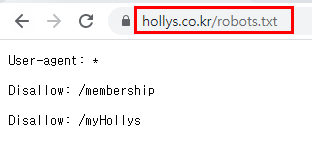
정적 웹페이지 크롤링
실습 사이트 - 할리스 : https://www.hollys.co.kr/store/korea/korStore2.do
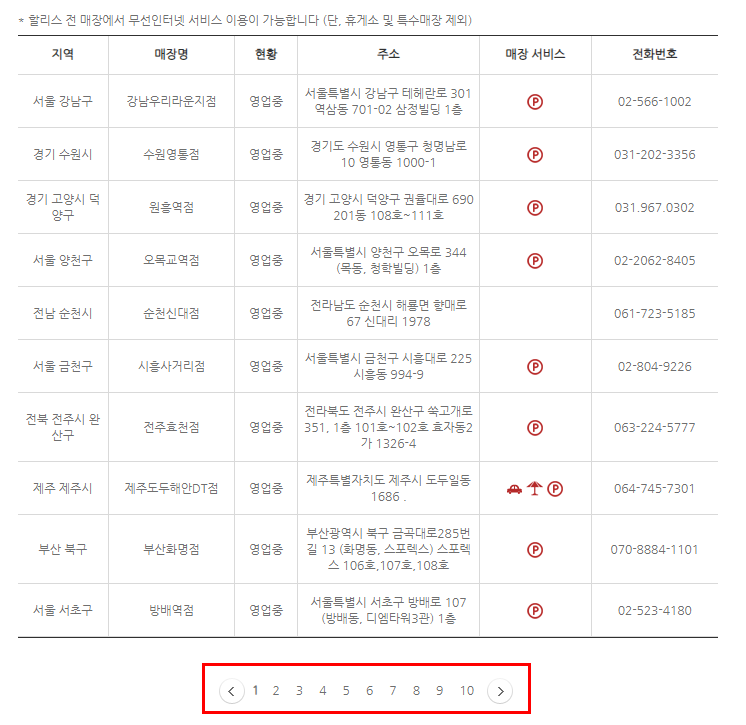

ch06/ex2.py : 할리스 매장 정보 크롤링
# ch06/ex2.py : 할리스 매장 정보 크롤링
from bs4 import BeautifulSoup as bs
import urllib.request
import pandas as pd
def hollys_store(result):
for page in range(1, 54): # p.173에 59로 잘못 표기(폐업으로 인한 매장 수 감소)
hollys_url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=%d&sido=&gugun=&store=' % page
# print(hollys_url)
html = urllib.request.urlopen(hollys_url)
soupHollys = bs(html, 'html.parser')
tag_body = soupHollys.find('tbody')
# print(tag_body)
for store in tag_body.find_all('tr'):
store_td = store.find_all_next('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
# print('%s %s %s %s' % (store_name, store_sido, store_address, store_phone))
result.append([store_name] + [store_sido] + [store_address] + [store_phone])
def main():
result = []
hollys_store(result)
hollys_tbl = pd.DataFrame(result, columns=('store', 'sido_gu', 'address', 'phone'))
hollys_tbl.to_csv('./data/hollys.csv', encoding='cp949', mode='w', index=True)
print('------ 완료 ------')
del result[:]
if __name__ == '__main__':
main()
동적 웹페이지 크롤링
커피빈 : https://www.coffeebeankorea.com/store/store.asp
selenium 추가
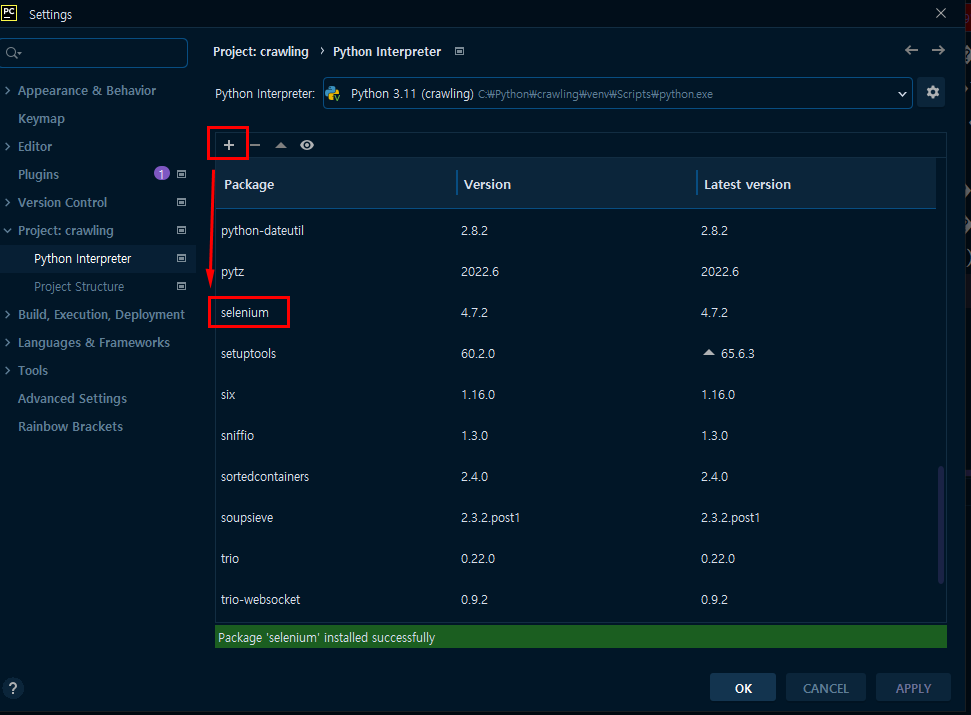
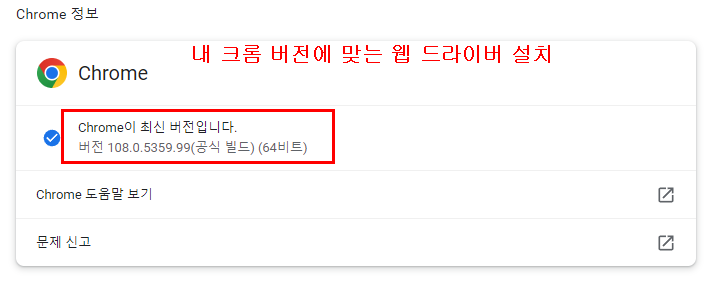
크롬 드라이버 설치 : https://chromedriver.chromium.org/downloads
→ https://chromedriver.storage.googleapis.com/index.html?path=108.0.5359.71
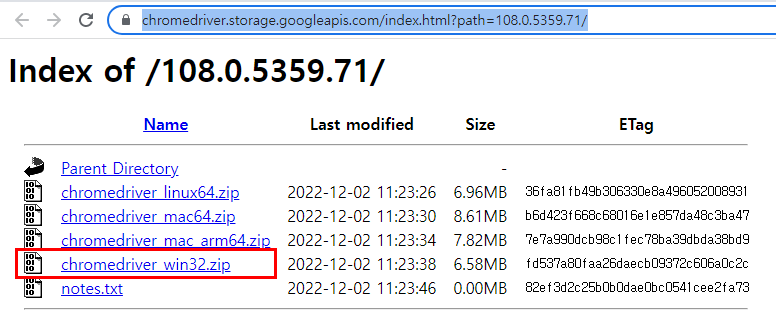
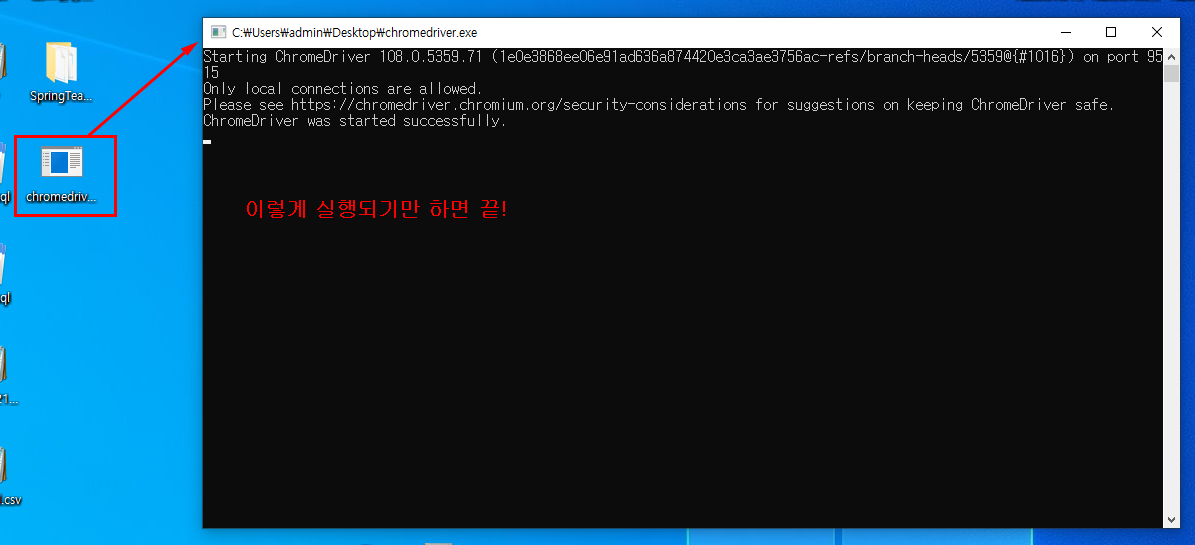
chromedriver.exe를 지정한 위치에 저장
ch06/ex3.py : chromedriver.exe를 지정한 위치에 저장
# ch06/ex3.py : chromedriver.exe를 지정한 위치에 저장
from selenium import webdriver
wd = webdriver.Chrome('./WebDriver/chromedriver.exe')
wd.get('https://www.hanbit.co.kr/')실행하면 해당 웹페이지가 켜졌다가 바로 닫힘 → 제대로 실행 된 것.
커피빈 매장찾기(동적 웹 크롤링)
ch06/ex4.py : 커피빈 매장찾기(동적 웹 크롤링)
# ch06/ex4.py : 커피빈 매장찾기(동적 웹 크롤링)
from bs4 import BeautifulSoup as bs
import urllib.request
import pandas as pd
import datetime, time
from selenium import webdriver
# [CODE 1]
def coffeeBean_store(result):
coffeeBean_URL = 'https://www.coffeebeankorea.com/store/store.asp'
wd = webdriver.Chrome('./WebDriver/chromedriver.exe')
for i in range(1, 370): # 233 -> 234 매장 수 만큼 반복
wd.get(coffeeBean_URL)
time.sleep(1) # 웹페이지 연결할 동안 1초 대기
try:
wd.execute_script('storePop2(%d)' % i)
time.sleep(1) #스크립트 실행 동안 1초 대기
html = wd.page_source
soupCB = bs(html, 'html.parser')
store_name_h2 = soupCB.select('div.store_txt > h2')
store_name = store_name_h2[0].string
# print('%d : %s' % (i, store_name))
store_info = soupCB.select('div.store_txt > table.store_table > tbody > tr > td')
store_address_list = list(store_info[2])
# print(store_address_list)
store_address = store_address_list[0]
store_phone = store_info[3].string
result.append([store_name] + [store_address] + [store_phone])
except:
continue
# [CODE 0]
def main():
result = []
print('CoffeeBean store Crawling~~~~~~~~')
coffeeBean_store(result)
cb_tbl = pd.DataFrame(result, columns=('store', 'address', 'phone'))
cb_tbl.to_csv('./data/coffeeBean.csv', encoding='cp949', mode='w', index=True)
print('완료')
if __name__ == '__main__':
main()
웹 크롤링 실습
교촌 영업 매장 크롤링 (정적 웹 크롤링)
교촌 홈페이지 : http://www.kyochon.com/shop/domestic.asp
html = 'http://www.kyochon.com/shop/domestic.asp?txtsearch=&sido1=%s&sido2=%s'kyochon_crawler.py(내 답)
# ch06/kyochon_crawler.py : 교촌 영업 매장 크롤링 (정적 웹 크롤링)
from bs4 import BeautifulSoup as bs
import urllib.request
import pandas as pd
import datetime, time
from selenium import webdriver
num = 0
def kyochon_store(result):
for sido in range(1, 18):
for gu in range(1, 46):
try:
kyochon_url = 'http://www.kyochon.com/shop/domestic.asp?txtsearch=&sido1=%s&sido2=%s' % (sido, gu)
html = urllib.request.urlopen(kyochon_url)
soupKyochon = bs(html, 'html.parser')
ul_tag = soupKyochon.find("div", {"class": "shopSchList"})
for store_data in ul_tag.findAll('a'):
store_name = store_data.find('strong').get_text()
store_address = store_data.find('em').get_text().strip().split('\r')[0]
store_sido_gu = store_address.split()[:2]
result.append([store_name] + [store_sido_gu] + [store_address])
print(store_name)
except:
pass
def main():
result = []
kyochon_store(result)
kyochon_tbl = pd.DataFrame(result, columns=('store_name', 'store_sido_gu', 'store_address'))
kyochon_tbl.to_csv('./data/kyochon.csv', encoding='cp949', mode='w', index=True)
print('------ 완료 ------')
del result[:]
if __name__ == '__main__':
main()
kyochon_store.csv
파일 참고페리카나 영업 매장 크롤링(정적 웹 크롤링)
페리카나 홈페이지 : https://pelicana.co.kr/main.html
html = 'http://www.pelicana.co.kr/store/stroe_search.html?&branch_name=&gu=&si=&page=%s'pelicana_crawler.py (내 답)
# ch06/pelicana_crawler.py : 페리카나 매장 정보 크롤링
from bs4 import BeautifulSoup as bs
import urllib.request
import pandas as pd
def pelicana_store(result):
for page in range(1, 108):
pelicana_url = 'http://www.pelicana.co.kr/store/stroe_search.html?&branch_name=&gu=&si=&page=%s' % page
# print(pelicana_url)
html = urllib.request.urlopen(pelicana_url)
soupPelicana = bs(html, 'html.parser')
tag_body = soupPelicana.find('tbody')
# print(tag_body)
for store in tag_body.find_all('tr'):
store_td = store.find_all_next('td')
# print(store_td)
store_name = store_td[0].string
store_address = store_td[1].string
store_phone = store_td[2].string
print('%s %s %s' % (store_name, store_address, store_phone))
result.append([store_name] + [store_address] + [store_phone])
def main():
result = []
pelicana_store(result)
pelicana_tbl = pd.DataFrame(result, columns=('store', 'address', 'phone'))
pelicana_tbl.to_csv('./data/pelicana.csv', encoding='cp949', mode='w', index=True)
print('------ 완료 ------')
del result[:]
if __name__ == '__main__':
main()pelicana_store.csv
파일 참고해설
교촌치킨
ch06/kyochon_crawler_2.py
교촌 영업 매장 크롤링 (정적 웹 크롤링) 해설
# ch06/kyochon_crawler_2.py : 교촌 영업 매장 크롤링 (정적 웹 크롤링) 해설
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime, time
from itertools import count
import ssl # 접속보안 허용
def get_request_url(url, enc='utf-8'):
req = urllib.request.Request(url)
try:
# [SSL: CERTIFICATE_VERIFY_FAILED] 에러 뜰때
ssl._create_default_https_context = ssl._create_unverified_context # 접속보안 허용
response = urllib.request.urlopen(req)
if response.getcode() == 200:
try:
rcv = response.read()
# 한글로 변환
ret = rcv.decode(enc)
except UnicodeDecodeError:
# replace : 에러 발생시 ?로 변환이 된다
ret = rcv.decode(enc, 'replace')
return ret
except Exception as e:
print(e)
print('[%s] Error for URL : %s' % (datetime.datetime.now(), url))
return None
def getKyochonAddress(sido1, result):
for sido2 in count():
url = 'http://www.kyochon.com/shop/domestic.asp?txtsearch=&sido1=%s&sido2=%s' % (str(sido1), str(sido2))
# print(url)
try:
rcv_data = get_request_url(url)
soupData = BeautifulSoup(rcv_data, 'html.parser')
ul_tag = soupData.find('ul', attrs={'class': 'list'})
# print(ul_tag)
for store_data in ul_tag.findAll('a', href=True): # a 태그 내에 href가 있는 a태그만 가져와라
store_name = store_data.find('strong').get_text()
# print(store_name)
store_address = store_data.find('em').get_text().strip().split('\r')[0]
store_sido_gu = store_address.split()[0:2]
result.append([store_name] + store_sido_gu + [store_address])
except:
break
return
def cswin_Kyochon():
result = []
print('Kyochon Address Crawling Start')
for sido1 in range(1, 18):
getKyochonAddress(sido1, result)
kyochon_table = pd.DataFrame(result, columns=('store', 'sido', 'gungu', 'store_address'))
kyochon_table.to_csv('./data/kyochon3.csv', encoding='cp949', mode = 'w', index=True)
del result[:]
print('-------------끝--------------')
if __name__ == '__main__':
cswin_Kyochon()페리카나
ch06/pelicana_crawler_2.py
# ch06/pelicana_crawler.py : 페리카나 매장 정보 크롤링
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime, time
from itertools import count
import ssl # 접속보안 허용
def get_request_url(url, enc='utf-8'):
req = urllib.request.Request(url)
try:
# [SSL: CERTIFICATE_VERIFY_FAILED] 에러 뜰때
ssl._create_default_https_context = ssl._create_unverified_context # 접속보안 허용
response = urllib.request.urlopen(req)
if response.getcode() == 200:
try:
rcv = response.read()
# 한글로 변환
ret = rcv.decode(enc)
except UnicodeDecodeError:
# replace : 에러 발생시 ?로 변환이 된다
ret = rcv.decode(enc, 'replace')
return ret
except Exception as e:
print(e)
print('[%s] Error for URL : %s' % (datetime.datetime.now(), url))
return None
def getPelicanaAddress(result):
for page_idx in count():
# print(page_idx)
# time.sleep(1)
url = 'http://www.pelicana.co.kr/store/stroe_search.html?&branch_name=&gu=&si=&page=%s' % str(page_idx + 1)
# print('[Pelicana Page] : [%s]' % str(page_idx + 1))
rcv_data = get_request_url(url)
soupData = BeautifulSoup(rcv_data, 'html.parser')
store_table = soupData.find('table', attrs={'class': 'table mt20'})
tbody = store_table.find('tbody')
# print(tbody)
bEnd = True
for store_tr in tbody.findAll('tr'):
bEnd = False
tr_tag = list(store_tr.strings)
store_name = tr_tag[1]
store_address = tr_tag[3]
store_sido_gu = store_address.split()[:2]
result.append([store_name] + store_sido_gu + [store_address])
if(bEnd == True): # 확인용 코드
print(result[0])
print('== 데이터 수 : %d ' % len(result))
return
return
def cswin_pelicana():
result = []
print('Pelicana Address Crawling Start')
getPelicanaAddress(result)
pelicana_table = pd.DataFrame(result, columns=('store', 'sido', 'gungu', 'store_address'))
pelicana_table.to_csv('./data/pelicana4.csv', encoding='cp949', mode='w', index=True)
del result[:]
print('------------- 끝 -------------')
if __name__ == '__main__':
cswin_pelicana()네이버 금융 국제증시 상위 100 기업 크롤링
naver_finance_crawler.py
# naver_finance_crawler.py : 네이버 금융 국제증시 거래상위 100 기업 크롤링
import requests
from bs4 import BeautifulSoup
def get_top100(top100_url, top100_name):
url = 'https://finance.naver.com/sise/sise_quant.nhn'
result = requests.get(url)
html = BeautifulSoup(result.content.decode('euc-kr', 'replace'), 'html.parser')
top100 = html.find_all('a', {'class': 'tltle'})
for i in range(100):
url = 'http://finance.naver.com' + top100[i]['href']
# print(url)
top100_url.append(url)
company_name = top100[i].string
# print(company_name)
top100_name.append(company_name)
return (top100_url, top100_name)
def get_company(top100_name):
company_name = input('주가를 검색할 기업이름을 입력하세요 >> ')
for i in range(100):
if company_name == top100_name[i]:
return(i)
if i == 100:
print('입력한 기업은 거래상위 100 목록에 없습니다.')
# 검색한 기업 이름으로 url 크롤링링
def get_company_stockPage(company_url):
result = requests.get(company_url)
company_stockPage = BeautifulSoup(result.content, "html.parser")
return company_stockPage
def get_price(company_url):
company_stockPakage = get_company_stockPage(company_url) # code3
no_today = company_stockPakage.find('p', {'class': 'no_today'})
blind = no_today.find('span', {'class': 'blind'})
now_price = blind.text
return now_price
def main():
top100_url = []
top100_name = []
top100_url, top100_name = get_top100(top100_url, top100_name)
print('현재 네이버 금융 거래 상위 100 기업 목록')
print(top100_name)
print()
company = int(get_company(top100_name))
if company == 100:
print('입력한 기업은 거래 상위 100 목록에 없습니다.')
else:
now_price = get_price(top100_url[company]) # code 4
print('%s 기업의 현재 주가는 %s 입니다.' % (top100_name[company], now_price))
if __name__ == '__main__':
main()