마이페이지에서 사용자의 카페관련 활동 기록을 조회할 수 있는 기능이 있습니다. 크게 세 가지로
- 북마크한 카페 목록 조회
- 좋아요한 카페 리뷰 목록 조회
- 내가 작성한 카페 리뷰 목록 조회
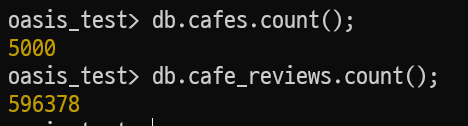
해당 api 성능을 테스트하기 위해 cafes 컬렉션 document 사이즈가 5000, cafe_reviews 컬렉션 사이즈가 500,000 이상의 데이터를 삽입하고 테스트를 진행해보니 응답이 많이 지연됐습니다.
| size(n) | |
|---|---|
| user | 10,000 |
| cafe | 5,000 |
| bookamark(per cafe) | 50 ~ 500 (random) → total: 2,523,130 |
| cafe review | 596,374 |
| like_uesrs(per review) | 0 ~ 750 (random) → total: 53,620,378 |
초기 세 기능에 대한 api 성능은 아래 사진과 같이 성능이 매우 처참...
물론 인덱스도 사용하지 않고 50만개가 넘는 document를 full-scan 하므로 쿼리가 많이 지연될 수 밖에 없다.
그 중에서도 좋아요한 카페 리뷰 목록 조회 api는 카페 리뷰 데이터 + 해당 리뷰의 카페 데이터 또한 포함해 제공하기 위해서는 cafe_reviews 컬렉션과 cafes 컬렉션 간에 join 연산이 필요해 더욱더 지연이 발생했습니다.
db.cafe_reviews.aggregate( [
{
$match: { "like_users.liked_email": email },
},
{
$lookup: {
from: "cafes",
localField: "cafe_id",
foreignField: "_id",
as: "cafe_info",
},
},
{
$unwind: "$cafe_info",
},
{
$project: {
cafe_id: 1,
reviewer: 1,
content: 1,
date: 1,
"cafe_info.cafe_name": 1,
"cafe_info.address": 1,
"cafe_info.image_link": 1,
},
},
] )위의 mongodb query는 기존에 좋아요한 리뷰를 조회하는 쿼리로, aggregate와 $lookup 연산을 이용해 cafe_id를 키로 조인해서 카페 데이터를 가져왔습니다.
기존 방식은 크게 두 가지 개선점이 보였습니다.
첫 번째는 cafes 컬렉션과 cafe_reviews 컬렉션 간 1:1 조인 방식은 조인을 통해 반환된 결과 값에 한 카페에 좋아요한 리뷰가 복수면 중복으로 카페 정보가 포함되어 있다는 점입니다. 중복된 카페 데이터는 네트워크 전송량과 디스크 I/O 비용을 상승시킬 수 있습니다.
두 번째는 카페 상세 정보를 조회하는 api가 호출될 때 조회된 카페 데이터를 일정 시간동안 레디스에 캐싱하므로 디스크에서 카페 정보를 접근하는 것이 불필요할 수 있다는 점입니다.
아래와 같이 세 가지로 케이스를 분류해 각 케이스 성능 비교를 실험해봤습니다. 성능 비교 방법은 먼저 “like_users.liked_email” 필드에 대해 인덱스를 생성한 후, k6을 이용해 1분 동안 300명의 가상 사용자가 해당 api를 요청하는 상황을 가정해 진행했습니다.

import http from "k6/http";
import { check, sleep } from "k6";
import { htmlReport } from "https://raw.githubusercontent.com/benc-uk/k6-reporter/main/dist/bundle.js";
export const options = {
stages: [{ duration: "1m", target: 300 }],
};
const HOST = __ENV.HOST;
const SESSION_COOKIE_NAME = "connect.sid";
// 각 VU 별로 한 번만 로그인 후 쿠키를 저장하기 위한 변수
let sessionCookie;
export default function () {
// 최초 실행 시 로그인 수행
if (!sessionCookie) {
const email = `test_email${__VU}`; // 각 VU에 고유한 이메일 지정
const password = "1234";
const loginRes = http.post(
`http://${HOST}:8080/users/login`,
JSON.stringify({ user_type: "customer", email, password }),
{ headers: { "Content-Type": "application/json" } }
);
if (!loginRes.cookies[SESSION_COOKIE_NAME]) {
console.error(`[VU ${__VU}] 로그인 실패`);
return;
}
sessionCookie = loginRes.cookies[SESSION_COOKIE_NAME][0].value;
}
// 저장된 세션 쿠키를 사용하여 리뷰 조회 요청 수행
const res = http.get(`http://${HOST}:8080/users/me/liked-reviews`, {
headers: { "Content-Type": "application/json" },
cookies: { [SESSION_COOKIE_NAME]: sessionCookie },
});
check(res, {
"status 200": (r) => r.status === 200,
});
sleep(1);
}
export function handleSummary(data) {
return { "summary.html": htmlReport(data) };
}
- 로그인을 안 한 가상 사용자면 로그인 후 세션 획득 후에 좋아요한 카페 리뷰 조회 요청
- 테스트 결과를 html 파일로 반환
Case 1. 기존 쿼리
기존 방식인 1:1 조인 + disk 접근 방식으로 테스트한 결과는 1분 동안 요청 수 1346, 데이터 수신 속도 14.70mB/s 의 결과가 나왔습니다.
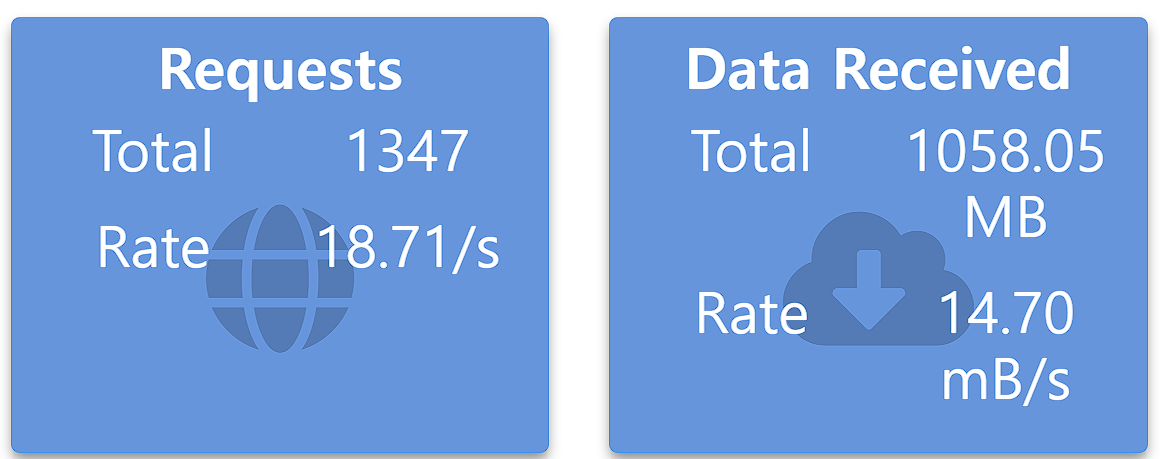
대략 초당 18.71번의 요청이 이루어진 셈입니다.
Case 2. cafe_id 키로 group
case 2는 기존 방식에서 join 연산을 제거하고 cafe_reviews 컬렉션에서 $group 연산을 통해 cafe_id를 키로 묶어 리뷰를 반환하도록 변경했습니다. 그리고 service 레이어로 로직을 다음과 같이 위임했습니다.
- repository에서 반환된 결과에서 cafe_id 값들을 추출해
ids리스트 생성 - 해당 ids를 조건으로 cafes 컬렉션에 조회
- 조회한 카페 데이터와 리뷰 데이터를 합쳐 최종 결과 값 생성
// repository/CafeReview.js
async findReviewsByLikedEmail(email) {
const pipeline = [
{
$match: { "like_users.liked_email": email },
},
{
$group: {
_id: "$cafe_id",
reviews: {
$push: {
reviewer: "$reviewer",
content: "$content",
likes: "$likes",
date: "$date",
},
},
},
},
{
$project: {
cafe_id: "$_id",
reviews: 1,
_id: 0,
},
},
];
const result = await db.query(this.collection, "aggregate", pipeline);
return result;
// service/CafeReviewService.js
async findMyLikedReviews(email) {
...
const reviews = await CafeReview.findReviewsByLikedEmail(email);
const cafeIds = reviews.map((r) => r.cafe_id.toString());
const cafes = await Cafe.findCafesByIds(cafeIds);
let cafeMap = cafes.reduce((map, cafe) => {
map[cafe._id.toString()] = cafe;
return map;
}, {});
return reviews.map((review) => {
const cafeId = review.cafe_id.toString();
const cafeInfo = cafeMap[cafeId];
return {
cafe_info: {
cafe_id: cafeId,
cafe_name: cafeInfo.cafe_name,
address: cafeInfo.address,
image_link: cafeInfo.image_link,
},
reviews: review.reviews,
};
});
...
},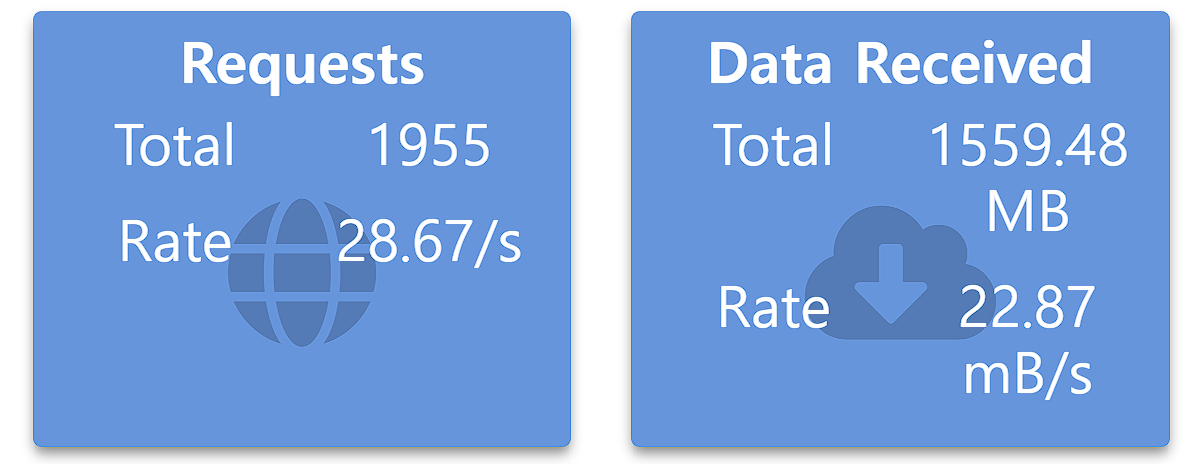
k6을 통해 테스트 결과 초당 대략 28.67번 요청이 이뤄졌습니다. 기존 방식보다 RPS(Request Per Second) 53% 이상 개선이 됐다고 할 수 있습니다.
테스트 데이터 셋이 한 카페에 여러 리뷰가 포함되어 있는 경우가 많아 1:1 조인보다 효율적으로 나온 것으로 판단됩니다.
Case 3. group + caching
마지막 케이스는 기존 case 2번에서 캐싱 기능을 적용해 테스트를 진행했습니다. 레디스에 캐싱된 카페 데이터가 이미 있으면 disk까지 접근하지 않고 메모리에서 가져오는 방식으로 변경했습니다.
- case 2 방식과 동일하게 cafe_id 리스트 ids를 생성
- 해당 ids 리스트를 조건으로 레디스에서 조회
- 레디스에 캐싱되지 않은 카페 ids 배열
missingIds리스트를 생성 - missingIds 리스트를 조건으로 cafe_reviews 컬렉션에서 조회
- 메모리와 디스크에서 가져온 카페 데이터와 리뷰 데이터를 합쳐 최종 결과 값 생성
// repository/CafeReview.js
async findReviewsByLikedEmail(email) {
...
// 동일
...
}
// service/CafeReviewService.js
async findCustomerMyLikedReviews(email, pageNum) {
...
const cachedCafes = await CafeCache.getCafesByIds(cafeIds);
const { found: cachedMap, missing: missingIds } = cafeIds.reduce(
(result, cafeId, idx) => {
const cachedCafe = cachedCafes[idx];
if (cachedCafe) {
result.found[cafeId] = cachedCafe;
} else {
result.missing.push(cafeId);
}
return result;
},
{ found: {}, missing: [] }
);
let cafeMap;
if (missingIds.length) {
const cafes = await Cafe.findCafesByIds(missingIds);
cafeMap = cafes.reduce((map, cafe) => {
map[cafe._id.toString()] = cafe;
return map;
}, cachedMap);
await CafeCache.setCafesByIds(missingIds, cafes);
} else cafeMap = cachedMap;
...
},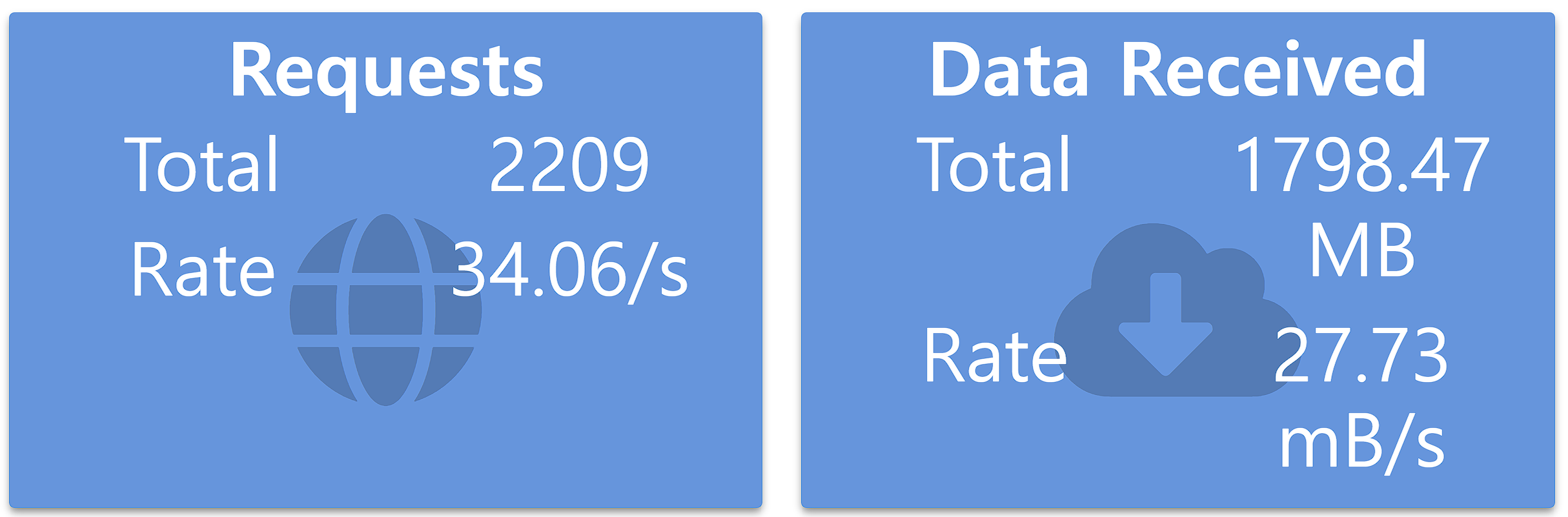
마지막 케이스 테스트 결과는 위 사진과 같이 초당 대략 34.06번 요청이 이뤄졌습니다. case 1 보다 RPS가 82% 이상, case 2 보다 응답 지연이 18% 이상 개선을 이뤘습니다. 애플리케이션 프로세스가 디스크에 접근하는 비용을 메모리로 변경해 디스크 I/O를 감소시킬 수 있고, 또한 레디스에 캐싱되지 않은 카페 데이터를 별도로 디스크에서 가져오는 작업을 추가해 데이터 무결성을 보장할 수 있었습니다.
세 가지 케이스를 비교한 결과를 다시 한번 정리하면 위의 표와 같습니다.
| 조건 | RPS | Data Rate |
|---|---|---|
| case 1 | 18.71/s | 14.70 mB/s |
| case 2 | 28.67/s | 22.87 mB/s |
| case 3 | 34.06/s | 27.73 mB/s |
앞서 말했듯이 동일한 카페의 리뷰 개수와 캐싱된 카페 유무 등 테스트 데이터 셋에 따라 성능은 위와 다를 수 있지만, 실제 서비스 운영에 있어 카페 정보를 캐싱하는 비용이 적어 오래/많이 캐싱이 가능하다는 점 등을 고려해 충분히 유의미한 개선을 이뤘다고 판단됩니다!!

제목이 인상적이네요 잘 읽었습니다 !