현재 토이프로젝트로 개발 중인 웹 서비스의 핵심 기능은 카페 관련 정보를 제공하는 것이다. 해당 서비스는 카페의 상세 정보(이미지, 카페 소개, 운영 시간대 등)를 제공하며 또한, 각 카페에 사용자들이 간단한 내용과 평점을 함께 리뷰를 작성할 수 있다.
cafe와 관련된 데이터는 추가 확장의 용이성을 생각해 mongodb를 이용해 저장하고 있다. 기존 각 카페의 상세 정보를 저장하는 cafes/cafe_reviews collection의 document의 한 예는 아래와 같다.
// cafes
{
_id: ObjectId('6787afe309b5ac9cc72393e2'),
cafe_name: 'test cafe 1',
cafe_type: '카페',
address: 'test 장소',
business_hours: '',
phone_number: '',
connection_site: '',
image_link: 'http://${HOST}:8080/oasis_logo.png',
starring: '0.66',
visitor_review: 761,
blog_review: 312,
description: '',
latitude: '35.4903159',
longitude: '129.4529095',
bookmark_users: [
'test_email1191', 'test_email579', 'test_email1514', 'test_email5955',
'test_email3047', 'test_email5625', 'test_email9339', 'test_email3629',
'test_email9852', 'test_email1421', 'test_email8055', 'test_email4379',
...
]
},
// cafe_reviews
{
_id: ObjectId('67a10b30723a34041f5a55d0'),
cafe_id: ObjectId('679678553e232a6706cea90f'),
reviewer: 'test_email7245',
content: "679678553e232a6706cea90f: 7245' review",
starring: 3,
date: ISODate('2025-02-03T18:30:07.962Z'),
likes: 95,
like_users: [
{
liked_email: 'test_email7389',
date: ISODate('2025-02-03T18:30:07.962Z')
},
{
liked_email: 'test_email2636',
date: ISODate('2025-02-03T18:30:07.962Z')
},
{
liked_email: 'test_email1390',
date: ISODate('2025-02-03T18:30:07.962Z')
},
...
}카페 리뷰 기능은 크게 3가지 정도로 나눌 수 있다
1. 카페 리뷰 작성(내용과 평점 수반)
2. 카페 리뷰 삭제(작성자만)
3. 카페 리뷰 좋아요
기능적으로 구현한 뒤에 dump data를 삽입해 테스트 중 몇 가지 이슈가 있어 이번 포스팅에서는 어떻게 해결했는지 정리해보겠다.
Frist Issue
Issue
- 특정 카페 상세 화면에서 각 카페에 대한 리뷰 조회 및 생성 가능
- 현재 test로 cafe size 5,000, 각 cafe 당 random으로 0 ~ 1000 크기의 데이터를 생성
→ total review size 596,374 dump data - 한 카페의 리뷰들을 조회하는 api 성능이 약
7000ms

-> 각 카페의 리뷰를 가져올 때 cafe_id 필드 값이 일치하는 document들을 가져오는데 단순하게 모든 document를 full-scan하므로 시간이 상당히 소요!
db("oasis_test")
.collection("cafe_reviews")
.find({ cafe_id: ObjectId("") })
.explain("executionStats");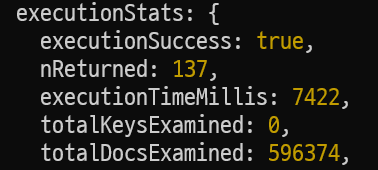
- 137개의 document를 return
- 7422ms가 소요
- total 596374개의 document를 탐색 -> full-scan
Solve
- Index 생성
db('oasis_test').collection('cafe_reviews').createIndex({cafe_id: 1});- mongodb에도 각 key에 대해 index 생성 가능
- 1 이면 오름차순, -1은 내림차순 의미
- 7000ms →
7ms성능 향상
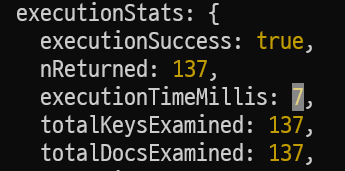
-> index 생성 후 137개의 document만 탐색!
-
Pagination
skip, limit 함수 사용
// find -> 10ms db("oasis_test") .collection("cafe_reviews") .find( { cafe_id: new ObjectId("66d5db9501eff5c79e7c83da") }, { projection: { cafe_id: 0, like_users: 0 } } ) .skip(20) .limit(20); // aggregate -> 10ms db("oasis_test") .collection("cafe_reviews") .aggregate([ { $match: { cafe_id: new ObjectId("66d5db9501eff5c79e7c83da") } }, { $skip: 20 }, { $limit: 20 }, { $project: { cafe_id: 0, like_users: 0 } }, ])- aggregate를 사용하거나 find를 사용하든 두 query에 성능 차이는 X
cafe_id에 대한 index 없이 date 컬럼을 기준으로 정렬하면 두 query 8초대
- date 컬럼을 기준으로 정렬할 필요 X → _id 값 자체가
timestamp를 내포
db.collection.find().limit(20) db.collection.find().sort({_id: 1}).limit(20);- 두 쿼리는 내부적으로 동일
-
Application 구현(api 수정)
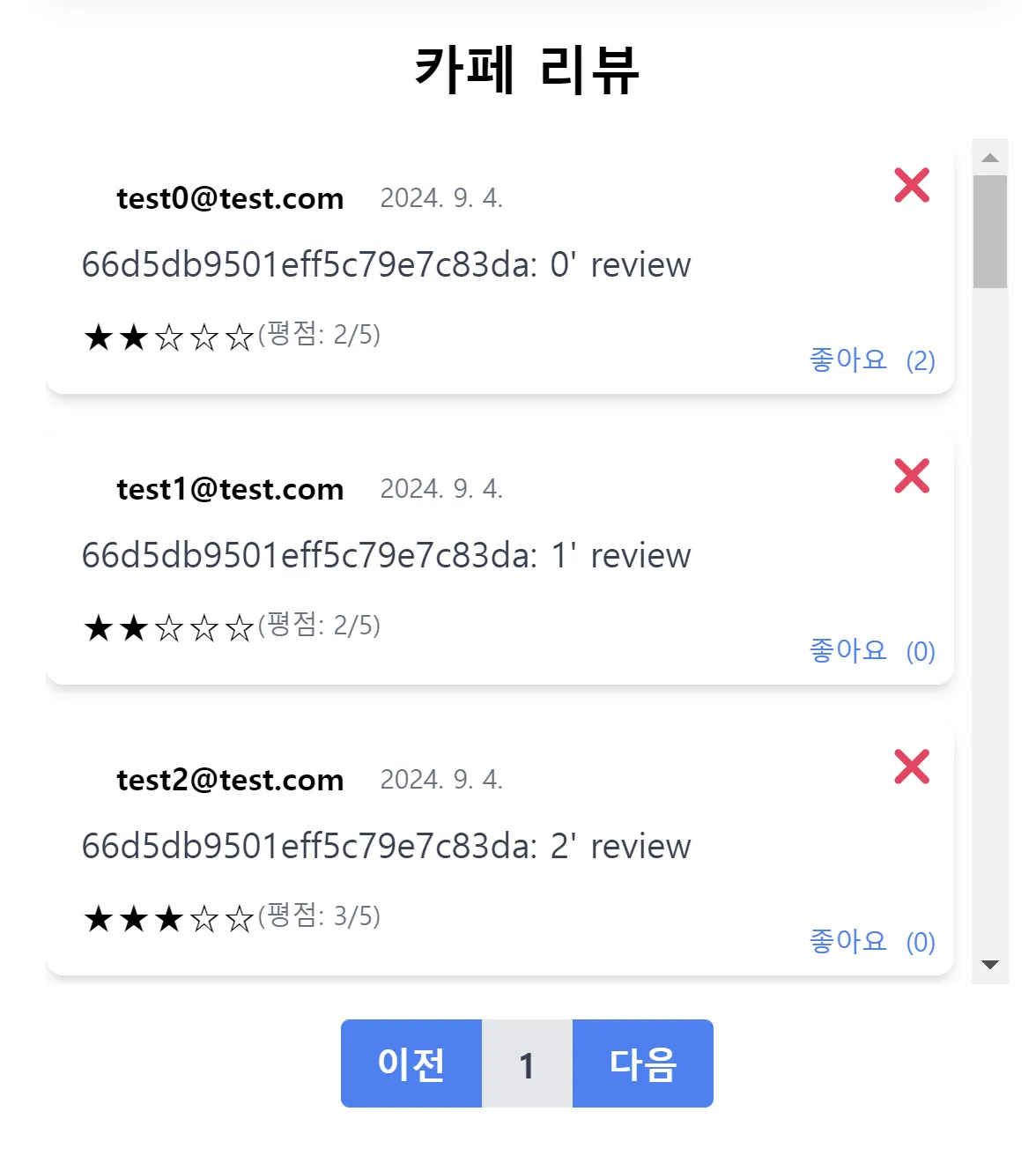
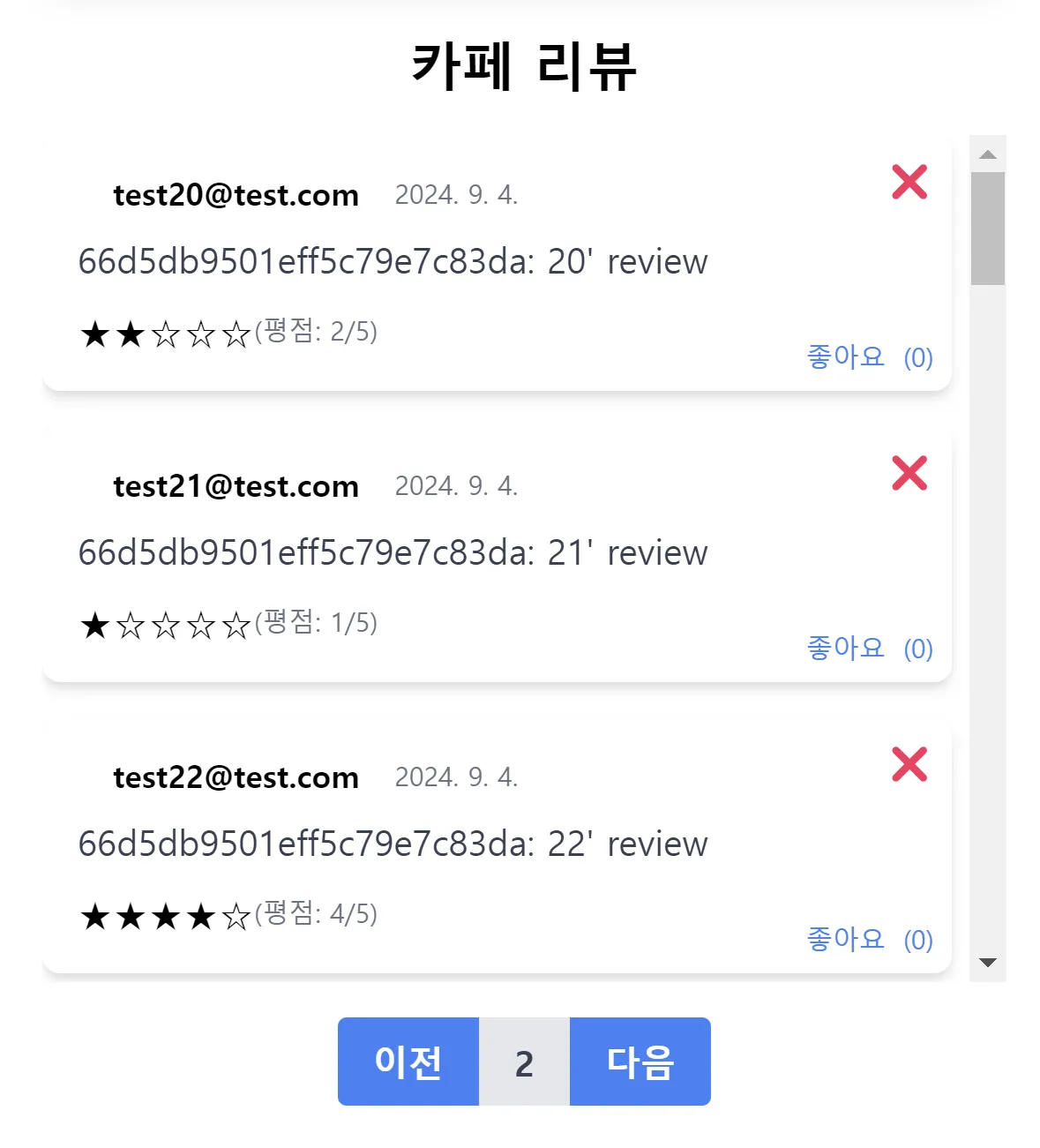
Query string 사용
pageNumquery string 사용
/cafes/reviews/:cafe_id?pageNum=[Num]
CafeReview Repository module 변경
// db/mongo_db.js async function query(collection, operation, ...params) { const db = await connect(); const col = db.collection(collection); const result = await col[operation](...params); if (operation === "find" || operation === "aggregate") return result.toArray(); return result; } // repository/CafeReview.js async findCafeReviewsByCafeId(cafe_id, pageNum, pageSize = 20) { const skip = (pageNum - 1) * pageSize; const pipeline = [ { $match: { cafe_id: new ObjectId(cafe_id) } }, { $skip: skip }, { $limit: pageSize }, { $project: { cafe_id: 0, like_users: 0 } }, ]; const reviews = await db.query(this.collection, "aggregate", pipeline); return reviews; },- query 로 입력 받은 (pageNum - 1) 과 pageSize(==20)을 곱해 skip할 document 수를 구함
- 기존의 query 메소드는 find 연산 후 바로 toArray()로 변환해 skip, limit 연산을 적용하기 어려움 → aggregate 연산을 이용해 skip, limit 값을 파라미터로 사용
|
|
Second Issue
Issue
- 사용자는 작성된 각 카페 리뷰에 좋아요 기능을 사용가능
- 좋아요 버튼을 클릭시 좋아요 수가 1 증가하며 cafe_reviews like_uesrs 배열에 해당 사용자가 추가
- 개발 단계에서 issue가 생길 만한 요소로 “카페 리뷰에 좋아요 요청 시 read-write 동기화 문제로 인한 race condition 발생”을 예상
초기 리뷰 좋아요 기능은 review_id와 일치하는 reviews의 likes 값을 1)read 후 +1 값을 2)write하도록 총 2단계로 구성했다.
해당 이슈를 확인하기 위해 총 1000번의 좋아요 patch을 동시에 요청하는 테스트를 진행했다.
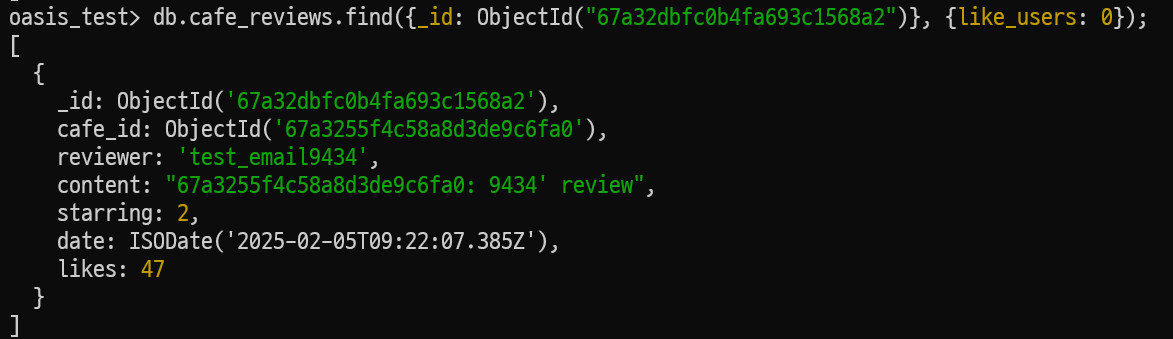
테스트 전에 리뷰의 likes 값은 47로 race condition이 발생하지 않았다면 1047의 값이 나와야한다.
테스트 결과 예상과 같이 likes 값이 105로 race condition이 발생됨을 확인할 수 있었다.

|
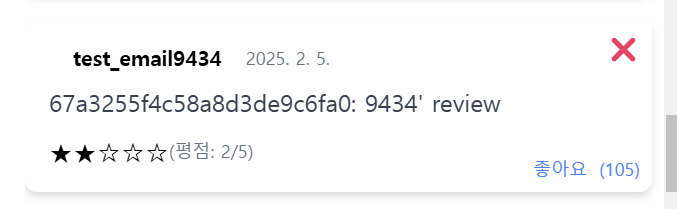
|
Solve
데이터베이스에서 발생하는 동시성 이슈(레이스 컨디션)를 해결하기 위한 대표적인 방법으로 3가지 정도가 있다.
1. Locking 메커니즘 사용
2. Transcation Isolation Leveles 조정
3. 원자적 연산(Atomic Operation) 활용
결과적으로 해당 이슈를 해결하기 위해 원자적 연산, mongodb에서는 $inc 연산자를 활용했다.
💡$set, $inc 연산자 모두 단일 document에 대해서 원자적으로 처리되나, 좋아요 증가 api는 기존의 likes 값에서 +1을 증가하므로 $inc 연산자를 사용하면 하나의 query로 구현이 가능하다.$set Vs. $inc 연산자 비교
- $set 연산자
- 지정한 필드의 값을 새로운 값으로 설정
- 기존 값이 무엇이든 관계없이 명시된 값으로 덮어씌우며, 필드가 없으면 새로 추가
- $inc 연산자
- 지정한 필드의 값을 주어진 숫자만큼 증가(또는 감소)
- 해당 필드가 없으면, 필드를 생성하고 그 값을 증감값으로 초기화
- Query 수정
- 기존 update시 $set 연산자 사용
- $inc 연산자를 이용해 +1 증가
db("oasis_test")
.collection("cafe_reviews")
.update(
{
_id: new ObjectId(reviewId),
"like_users.liked_email": { $ne: email },
},
{
$inc: { likes: +1 },
$push: { like_users: { liked_email: email, date: new Date() } },
}
);- Application 구현(api 수정)
- 이미 like_uers 배열에 포함되어 있으면 증가 x
-> Service layer에서 false 반환
// CafeReview.js
async updateReviewLike(reviewId, email, addedCnt) {
const queryJson = {
_id: new ObjectId(reviewId),
"like_users.liked_email": { $ne: email },
};
const updateJson = {
$inc: { likes: +addedCnt },
$push: { like_users: { liked_email: email, date: new Date() } },
};
const result = await db.query(
this.collection,
"updateOne",
queryJson,
updateJson
);
return result;
},
// cafeReviewService.js
async addLikeToReview(reviewId, email) {
try {
const likes = await CafeReview.findReviewLikesById(reviewId);
const result = await CafeReview.updateReviewLike(
reviewId,
email,
likes + 1
);
if (result.modifiedCount > 0) return true;
else return false;
} catch (err) {
throw new Error("email or review_id that does not exist");
}
},Result
기존의 like 좋아요 기능은 read-write로 2 step 과정을 거치는데 $inc 연산자를 이용해 단일 문서 내의 원자적 연산으로 변경했다.
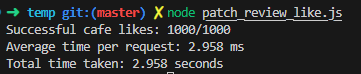
테스트 전 test review의 likes 값이 0인 리뷰에 대해 이전과 같이 1000번의 patch 요청을 테스트한 결과는 아래와 같다.
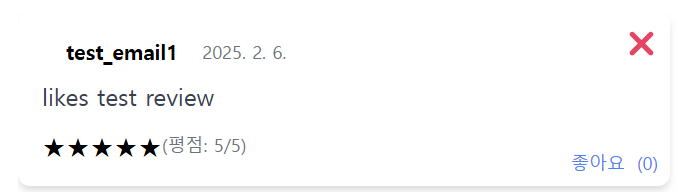
|
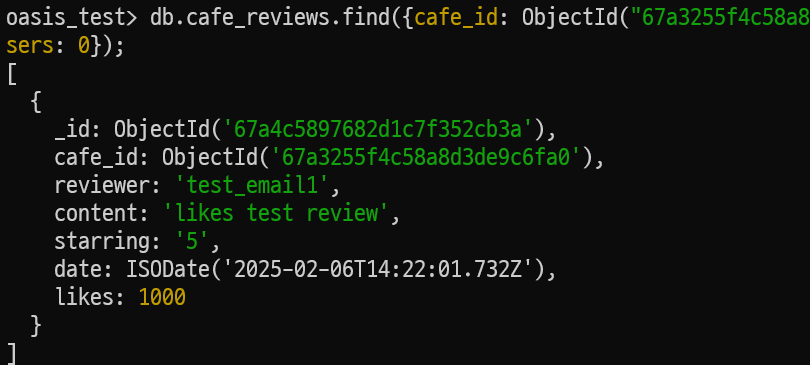
|
사진과 같이 정상적으로 +1000 값이 증가됐으며 또한, 기존 쿼리는 disk에 2번의 접근을 했는데 $inc 연산자를 이용함으로써 1번의 접근으로 변경돼 성능 또한 개선됐다고 판단된다.
Reference
https://node-js.tistory.com/40
https://velog.io/@moongq/MongoDBMongoose-퍼포먼스-향상시키기
https://www.mongodb.com/ko-kr/docs/v6.0/reference/operator/update/inc/
