먼저 thread 개념을 알기 전에 os에서 프로세스의 개념 먼저 살펴보자.
Process
프로세스는 몇 가지 문장으로 쉽게 표현이 가능하다
- 프로그램이 돌아가고 있는 상태
- 프로그램이 실행돼 메모리에 올라간 상태
여기서 프로그램은 쉽게 말해 디스크에 저장되어 있는 일련의 코드, 코드 덩어리를 말한다.
→ “어떤 작업을 위해 실행할 수 있는 파일”단순히 위에 예시로 표현하기엔 프로세스를 설명하기엔 부족한 점이 많다. 지금부터 같이 알아보자.
일단 프로그램과 프로세스의 중요한 차이는 메모리에 올라갔느냐? 안 올라갔느냐의 load 여부가 중요하다.
프로그램을 실행하면 os 는 메모리 공간을 할당하는데 프로그램에 따라 하나의 프로세스로 실행될 수 있고, 여러개의 분리된 프로세스로 메모리에 올라갈 수도 있다.
사전적 의미로는 “메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)” 로 정의 가능하다.
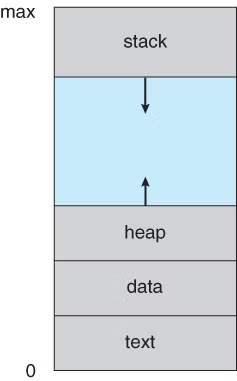
프로세스는 프로세스만의 주소 공간(독립된 메모리 영역, process image)을 가진다.
- Code(Text): 코드 자체가 저장
- Data: 전역 변수, 정적변수 등
- Heap: runtime에서 동적으로 메모리에 할당 되는 데이터
- ex, c 언어일 경우 malloc()을 이용해 공간을 할당 받을 때
- Stack: 함수가 실행될 때 생기는 데이터들, 지역 변수, parameter, return address
Process 특징
기본적으로 프로세스당 최소 1개의 thread(main thread)를 가진다.- 각 프로세스는 독립된 메모리 영역을 가지므로 일반적으로 다른 프로세스의 자료, 데이터에 접근할 수 없다.
- 프로세스간 통신을 하기 위해서는 IPC(inter-process communication)을 사용한다.
- Shared Memory
- Message Passing
thread part에서 설명할 내용이지만 thread는 process와 달리 thread 간 일정 메모리 부분을 공유하고 있기 때문에 multi-process 기법보다 multi-thread 기법이 각 thread간 context switching 오버헤드가 적다!
Context Switching(문맥 전환)
먼저 PCB(Process Control Blcok)에 대해 간단히 알아보자. pcb는 특정한 프로세스를 관리할 필요가 있는 정보를 포함하는 os kernel의 자료구조이다. 쉽게 말해 pcb는 os에서 프로세스를 표현한 모습이라고 할 수 있다.
각 프로세스는 하나의 pcb를 가지며 pcb는 kernel이 직접 관리한다. pcb는 프로세스의 다양한 정보를 가지는데 프로세스 상태, pc, registers, MMU info, pid 등이 포함된다.

Context Swtiching은 cpu가 한 프로세스에서 다른 프로세스로 전환할 때 발생하는 일련의 과정을 말한다. 시분할 기법으로 인해 한 core는 하나의 프로세스를 실행할 수 있는데 스케줄링 정책에 따라 프로세스가 교체될 때 다음에 실행할 프로세스가 cpu register에 로드되기 위한 과정이라고 볼 수 있다.
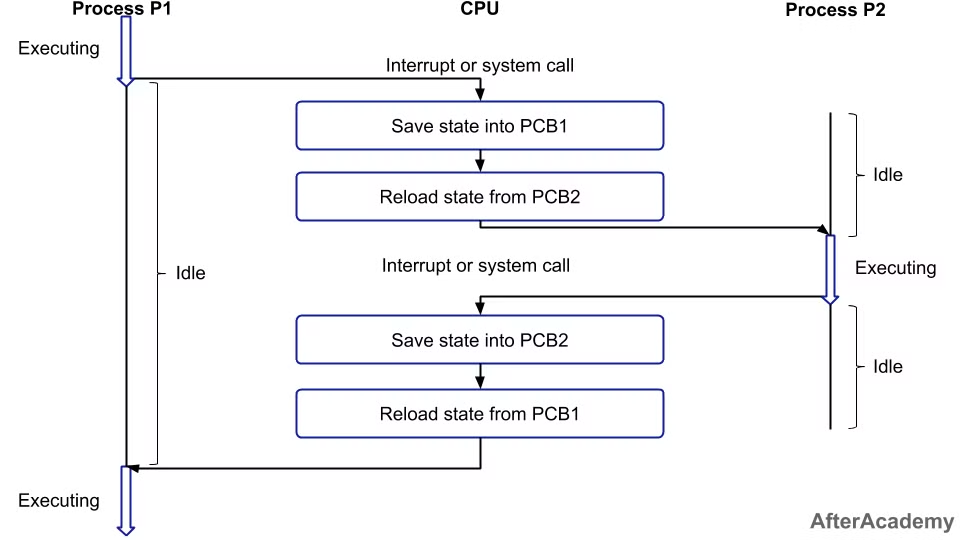
위의 그림을 통해 context switching 과정을 설명해보겠다.
실행 중인 p1 프로세스는 interrupt or system call로 인해 중단되 p1의 상태를 pcb1에 저장한다. p1은 waiting 상태로 돌입하며 p2 프로세스가 running 상태로 변경된다. 이 과정과 동시에 p2의 정보를 cpu register로 불러오기 위해 pcb2를 reload한다.
또 interrupt or system call로 인해 p2 프로세스가 중단되 waiting 상태로 변하며 현재 정보 pcb2에 저장, p1를 running 상태로 변경 및 pcb1 정보를 register에 불러오는 작업을 반복한다.
이러한 일련의 과정 모두를 Context Switching이라고 할 수 있다!
Thread
쓰레드는 영어 단어 뜻 자체로 ‘실’의 의미를 가지며, 하나의 프로세스 내에서 동시에 진행되는 작업 갈래, 흐름의 단위를 말한다.
프로세스 내에서 실제로 작업을 수행하는 주체를 의미하며 모든 프로세스에서는 한 개 이상의 스레드가 존재하여 작업을 수행한다. 프로세스가 둘 이상의 쓰레드를 가지는 방식을 multi-thread라고 한다.
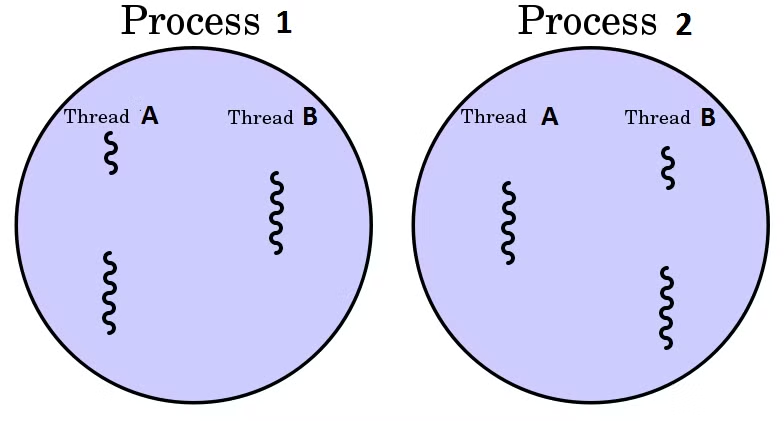
예시로 하나를 비유하자면 아래 post를 참고하자.
https://velog.io/@iamdudumon/python-기반-채팅-프로그램-2
전에 공부 겸으로 멀티 쓰레드 기반의 채팅 프로그램을 구현한 적이 있는데, multi-thread를 도입함으로써 한 쓰레드는 메세지를 보내는 로직을 실행하고, 다른 쓰레드는 메세지를 read 하는 로직을 실행이 가능해 blocking 없이 채팅 프로그램 구현이 가능했다. 만약 multi-thread를 사용하지 않으면 프로세스의 task 단위는 하나로 메세지를 read만 하거나 send만 가능해 정상적인 채팅이 불가능할 것이다.
자원 공유
thread는 process와 달리 같은 process 내 thread들끼리는 code, data, head 메모리 영역을 공유한다.
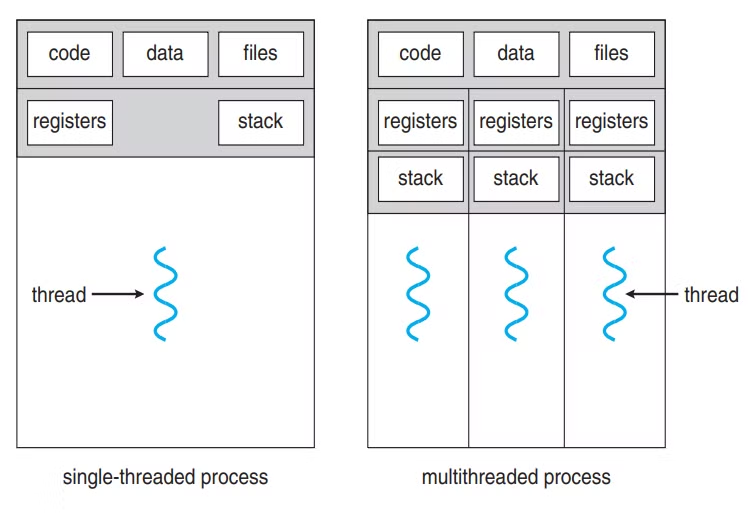
stack, register 메모리 영역만 thread 별 자신 만의 메모리 영역을 가진다. 프로그램 카운터(pc)도 독립적이어서 각 스레드가 서로 다른 코드 라인을 실행할 수 있다.
모든 스레드가 같은 프로세스의 주소 공간 내에 존재한다는 것은, 이론적으로 한 스레드가 다른 스레드의 스택이나 레지스터에 접근할 수 있다는 의미하지만 동기화의 이유로 권장되지 X
해당 스레드의 특성으로 멀리 프로세스 기법에서 멀티 스레드를 사용하는 이유가 나온다.
- 자원 효율성
- 일반적으로 프로세스를 생성하는 system call 비용보단 쓰레드를 생성하는 system call 비용이 적다.
- context switching 상황에서 단순히 cpu의 register만 교체되는 것이 아닌 ram과 cpu 사이의 캐시 메모리 또한 교체되는데 프로세스 간의 context switching 상황에서는 캐시 메모리에 대한 데이터까지 초기화되는 이유로 오버헤드가 크다.
- 통신 효율성
- 쓰레드는 동일한 addr space를 사용하므로 프로세스 간의 통신(IPC)보다 비용이 적다.
- Context Switching 상황에서 쓰레드는 stack 영역만 교체하면 된다.
Hardware Thread vs. Software Thread
cpu 상품을 구경하다보면 10core/16thread 이렇게 성능이 표시된 상품을 종종 볼 수 있다.

cpu가 n 코어 m 쓰레드일 때 n을 말 그래도 “물리적인” cpu core 유닛의 개수이고 m은 “논리적인” core 유닛의 개수이다. 그럼 n=4, m=8 일 때 core 한 개가 2개의 쓰레드를 실행한다는 의미인데 이런 로직을 가능하게 하는 기법이 SMT(aka. Hyper-Threading)이다.
https://en.wikipedia.org/wiki/Simultaneous_multithreading
os 입장에서 프로세스를 스케줄링 할 때, “동시에 실행 가능한 스레드 수”, 즉 할당 가능한 스레드의 슬롯은 m이다. 여기까지가 hardware thread의 개념이고 software thread는 메모리가 허용하는 한 얼마든지 생성이 가능하다. 최대 실행 중이 m개의 쓰레드 중 일부는 I/O 작업을 위해 대기 등의 이유로 소프트웨어적인 쓰레드가 m개 이상의 생성이 가능한 것이다.
Reference
https://inpa.tistory.com/entry/👩💻-프로세스-⚔️-쓰레드-차이
https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html
