https://www.acmicpc.net/problem/18870
문제
수직선 위에 N개의 좌표 X1, X2, ..., XN이 있다. 이 좌표에 좌표 압축을 적용하려고 한다.
Xi를 좌표 압축한 결과 X'i의 값은 Xi > Xj를 만족하는 서로 다른 좌표의 개수와 같아야 한다.
X1, X2, ..., XN에 좌표 압축을 적용한 결과 X'1, X'2, ..., X'N를 출력해보자.
입력
첫째 줄에 N이 주어진다.
둘째 줄에는 공백 한 칸으로 구분된 X1, X2, ..., XN이 주어진다.
출력
첫째 줄에 X'1, X'2, ..., X'N을 공백 한 칸으로 구분해서 출력한다.
제한
- 1 ≤ N ≤ 1,000,000
- -109 ≤ Xi ≤ 109
예제 입력
5
2 4 -10 4 -9
예제 출력 1
2 3 0 3 1
예제 입력 2
6
1000 999 1000 999 1000 999
예제 출력 20
1 0 1 0 1 0
파이썬 풀이
# 18870 좌표 압축 / 정렬 / 실버2
import sys
from collections import defaultdict
read = sys.stdin.readline
N = read()
nums = list(map(int, read().split()))
dic = defaultdict(int)
cnt = 0
for n in sorted(nums):
if n not in dic:
dic[n] = cnt
cnt += 1
for n in nums :
print(dic[n], end=' ')문제를 처음에 보면 이해가 안 될 수가 있는데, 요점은 배열에서 각 수보다 적은 수가 몇 개 있냐는 뜻이다.
따라서 입력받은 숫자 리스트를 정렬한 후, 각 수에 대한 적절한 값을 딕셔너리에 넣으면 된다.
예를 들어 배열이 2 4 -10 4 -9라서 -10 -9 2 4 4로 정렬되고 나면 -10이 키값이면 밸류는0으로 넣으면 된다. 그리고 밸류를 1 증가시키는데, 그 다음 값은 당연히 이전 원소보다 크기 때문이다. 그렇다면 다음 차례에서 -9가 키값이면 밸류는1로 들어간다.
자바 풀이
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.HashMap;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int N = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int value = 0;
int[] arr = new int[N];
for (int i = 0; i < N; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
int[] arr2 = Arrays.copyOf(arr, N);
Arrays.sort(arr);
HashMap<Integer, Integer> hm = new HashMap<>();
for (int i = 0; i < N; i++) {
if (!hm.containsKey(arr[i]))
hm.put(arr[i], value++);
}
for (int i = 0; i < N; i++)
sb.append(hm.get(arr2[i])).append(" ");
System.out.println(sb);
}
}사실 자바로 1년 전에 푼 문제다. (코테 언어를 파이썬으로 바꿔서 다시 풀어봄...)
결과
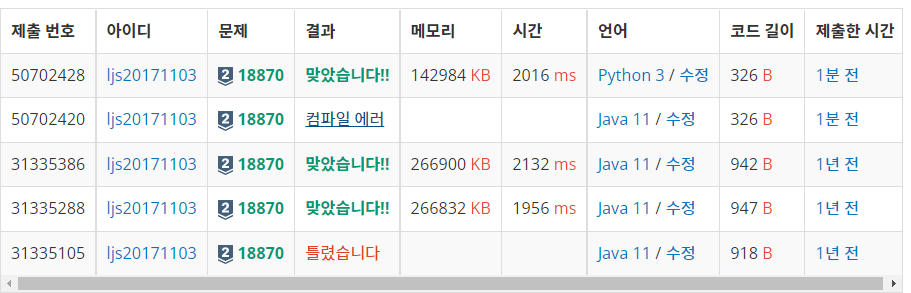
실행시간은 둘다 비슷하다.

일단 뭐라도 해보는 중