🎡 크롤링
크롤링이란?
💡 크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부름.
웹 상에는 데이터가 점점 많아지면서 필요한 데이터를 추출하는 것이 매우 힘들다. 하지만, 크롤링을 이용하면 필요한 데이터를 빠르게 뽑아낼 수 있다. 이러한 크롤링 방식에도 두 가지 방식이 존재한다.
웹 크롤링
spider라고 불림- 웹 페이지의 내부 링크를 따라 인터넷을 체계적으로 검색하여 컨텐츠를 검색하는 독립 실행형 봇
- 쉽게 말해서, 구글이나 네이버 검색 엔진이라 생각하면 된다.
- URL의 모든 콘텐츠를 추출한다.
- 기존 내용을 모두 추출해 복사본을 생성하는 느낌이다.
웹 스크래핑
- 특정 데이터를 추출하는 프로세스
- 특정 사이트의 특정 데이터를 가져오기 위해 사용되는 방식이다.
- 이를 수행하기 위해서는 웹 크롤링 작업을 먼저 수행해야 한다.
크롤링을 무작정하면 어떻게 될까? 크롤링해서는 안되는 데이터가 있을 수도 있고, 수많은 크롤링 봇들이 웹 사이트에 접속하게 되면 과도한 트래픽 또한 발생할 수 있다. 이러한 규제를 만들기 위해서는 robots.txt 파일을 이용한다.
봇배제표준(robots.txt)이란?
💡 서버에 엑세스하는 봇에 대한 규칙을 입력해 놓은 웹 서버 파일
- 봇이 웹사이트에 엑세스하기 전에
robots.txt파일을 확인하도록 프로그래밍 해야함. - 봇이
robots.txt의 규칙을 확인하고 이를 따라야함.
https://naver.com/robots.txt 와 같이 주소창 뒤에 robots.txt 를 입력하면 다운받아 확인할 수 있다.
User-agent: * -> 모든 크롤링 봇
Disallow: /m
Disallow: /login
Disallow: /gateway
Allow: / -> 사이트의 모든 페이지를 제한 없이 탐색 가능
Disallow 페이지는 탐색하지 말란 뜻❓ robots.txt 가 없으면 어떤 문제가 발생할까?
- 크롤링 봇이 무차별적으로 웹사이트를 탐색하기 때문에 과도한 트래픽이 발생할 수 있다.
- 탐색 경로에 제한을 두지 않으면 법적으로 문제가 될 수 있는 데이터를 수집할 수 있다.
❓ robots.txt 규칙을 지키지 않으면 어떻게 될까?
- 국제 권고안이기 때문에 강제력은 없다.
- ‘권고 요청’ 정도 이기 때문에 처벌이 내려지거나 하는 일은 없다.
- 하지만, 그 외 생길 수 있는 법적 문제가 있기 때문에 웬만하면 따르는 것이 좋다.
사용자 에이전트란?
- 사용자를 대신해서 일을 수행하는 소프트웨어 에이전트
- 웹 맥락에서는 브라우저를 의미
- 웹 페이지를 긁어가는 봇, 다운로드 관리자, 웹에 접근하는 다른 앱도 사용자 에이전트
사용자 신분을 대신할 수 있는 소프트웨어이기 때문에, 웹과 관련된 맥락에서는 일반적으로 브라우저 종류나 버전 번호, 호스트 운영체제 등의 정보를 의미한다.
- 웹 페이지에서 F12를 눌러 개발자 모드로 들어간 후, 콘솔창에
navigator.userAgent를 입력해 실행하면 user-Agent 값을 확인할 수 있다.'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36’
🍻 LRU 캐시
웹에서는 특정 사이트에 접속하면 불러온 페이지를 캐시에 저장한다. 그렇다면 왜 저장을 하는 것이고 어떤 알고리즘이 사용되는 것일까?
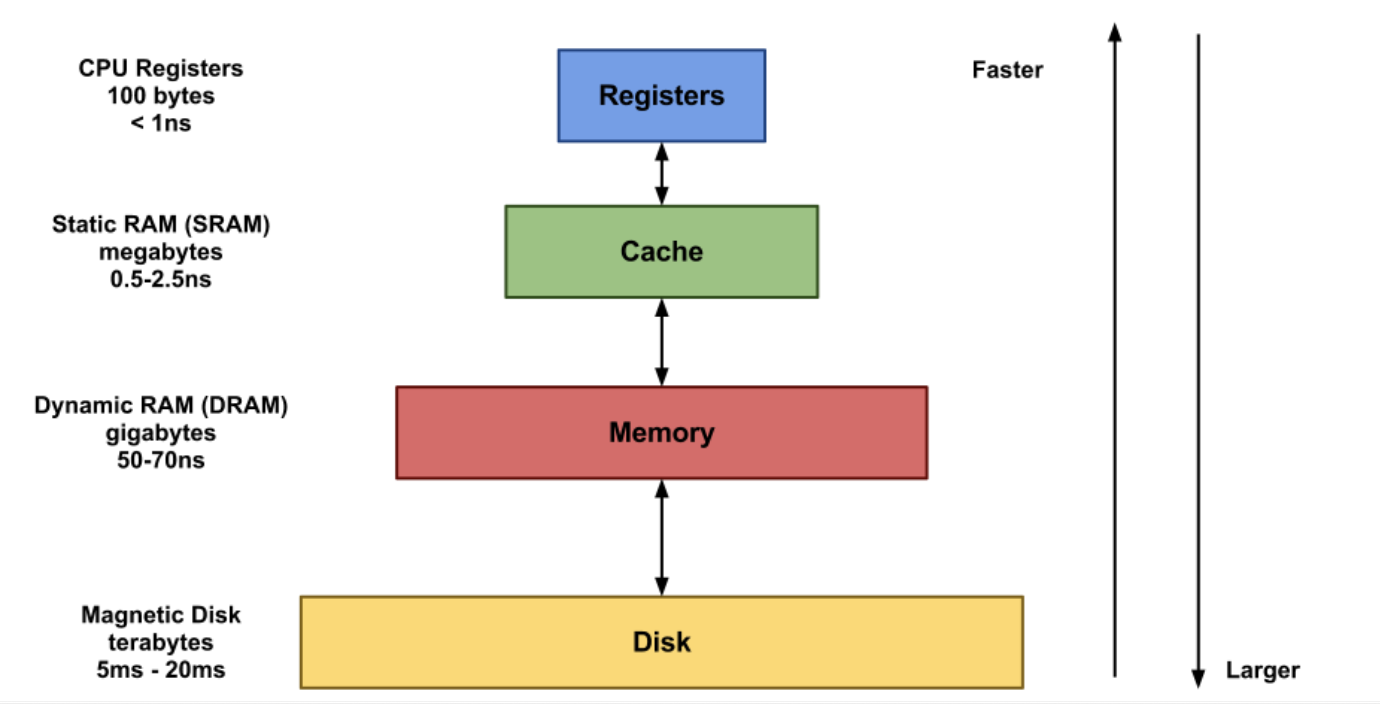
Cache
- 연산에 필요한 데이터, 값을 저장해두는 임시 메모리
- CPU에서 주ㆍ보조 기억 장치까지 도달하는 비용이 매우 크다
- 하지만, 캐시는 CPU 바로 옆에 있기 때문에 접근 비용이 적다.
=> 따라서, 캐시는 CPU에서 참조하는 시간을 줄여 성능을 높일 수 있는 임시 메모리를 의미한다.
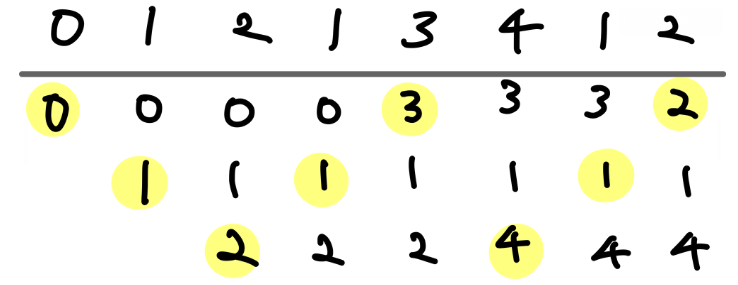
LRU (Least Recently Used)
- 운영체제 페이지 교체 알고리즘 중 하나
- 페이지를 교체할 때 가장 오랫동안 사용되지 않은 페이지를 교체 대상으로 삼는 기법
LRU Cache
- 캐시는 용량이 제한되어 있기 때문에 캐시가 가지고 있는 데이터를 업데이트 해줘야한다.
- 그러므로, 캐시 공간이 부족할 때 LRU 알고리즘을 사용한다.
Doubly Linked List와HashMap으로 구현할 수 있다.- Kotlin 에서는
Doubly Linked List와HashMap을 결합한LinkedHashMap을 이용하여 LRU 알고리즘을 구현할 수 있다.
❓ 왜 LinkedHashMap 을 사용해야 하는 것일까?
- 캐시 데이터 접근
- Map을 활용하여 데이터에 바로 접근할 수 있다.
- Tail에 새 데이터 추가 및 Head에 오래된 데이터 삭제
- 가장 오랫동안 사용되지 않은 데이터가 무엇인지 파악하기 위해서는 사용된 데이터들의 순서를 기억하고 있어야 하기 때문에 Doubly Linked List를 사용해야한다.
⇒ 결과적으로 시간복잡도는 O(1) 이 된다.
⇒ 데이터들의 순서를 기억하는 메모리가 필요하기 때문에 기존의 HashMap보다 메모리 사용량이 더 높다.
의문점
LinkedHashMap 을 사용하고 초기 용량을 5로 지정해주었다. 근데 초기용량을 셋팅해놔도 다른 배열의 초기 용량을 셋팅해놓는 것과 다르게 오류가 나지 않았다. 어떤 식으로 동작하는 것인가?
val map = LinkedHashMap<String, Int>(5)
map["김일이"] = 26
map["김이삼"] = 24
map["김삼사"] = 21
map["김사오"] = 20
map["김오육"] = 18
map["김육칠"] = 18
println(map.toString())- 초기 용량을 5로 지정했는데 6개의 키, 값의 쌍을 추가하였다.
- 근데도 오류가 발생하지 않았다.
그 이유는 HashMap에 데이터를 추가하게 되면 일정 시점에서 해시 테이블이 꽉찬다. 그러면 새로운 해시테이블을 생성하고 기존에 있던 데이터들을 옮긴다. 그렇게 되면 불필요한 데이터 복사를 발생시키므로 성능이 저하되기 때문에 초기 용량을 설정하여 큰 해시테이블을 미리 생성하여 불필요한 복사를 피할 수 있다.
그러므로, 이 경우에도 5의 용량을 지정하였지만 6개의 데이터가 들어가여도 다른 해시테이블이 생성되어 데이터 복사가 된다. 그러므로 오류가 발생하지 않는 것이다.
참고로 해시맵의 기본 초기 용량은 16이다.
참고 자료
