
[CS/자료구조] 04. 해시 테이블(Hash Table)
⚡ 한 줄 요약: 임의의 키(Key)를 해시 함수를 통해 고유한 인덱스로 변환하여 데이터 저장 및 조회 성능을 로 극대화하고, 피할 수 없는 해시 충돌을 영리하게 해결하는 방법을 배웁니다.
1. 👋 들어가며: "데이터를 찾는 가장 빠른 방법"
우리는 매일 자바스크립트에서 obj['key'] 혹은 파이썬에서 dict['key']를 사용하여 데이터를 즉시 찾아냅니다.
데이터가 수만 개가 넘어가도 어떻게 우리는 인덱스 번호를 모른 채 '이름'만으로 데이터를 순식간에 찾을 수 있는 걸까요?
그 마법 같은 속도의 비밀인 해시 테이블의 내부 구조를 파헤쳐 봅니다.
-
🧐 Why:
- 데이터가 많아질수록 배열의 선형 탐색()은 한계에 부딪힙니다.
- 해시 테이블의 원리를 알면 대규모 데이터 처리 시 성능 병목을 예측할 수 있고, 기술 면접의 단골 질문인 '해시 충돌 해결책'에 대해 깊이 있는 답변이 가능해집니다.
-
🎯 Goal:
- 해싱(Hashing)의 메커니즘을 이해하고, 체이닝(Chaining)과 개방 주소법의 차이점을 명확히 구분하여 상황에 맞는 설계를 고민할 수 있습니다.
📂 2. 해시 테이블 및 해시 함수
📌 2-1. 핵심 개념
배열은 '0, 1, 2' 같은 인덱스 숫자만으로 접근해야 하는 제약이 있습니다.
반면 해시 테이블은 문자열과 같이 다양한 형태의 키를 사용할 수 있다는 독보적인 장점이 있습니다.
하지만 컴퓨터의 메모리는 결국 숫자로 된 주소 체계를 따릅니다.
따라서 문자열을 키로 쓰더라도 데이터가 저장될 특정 위치(인덱스)를 지정해 줘야 합니다.
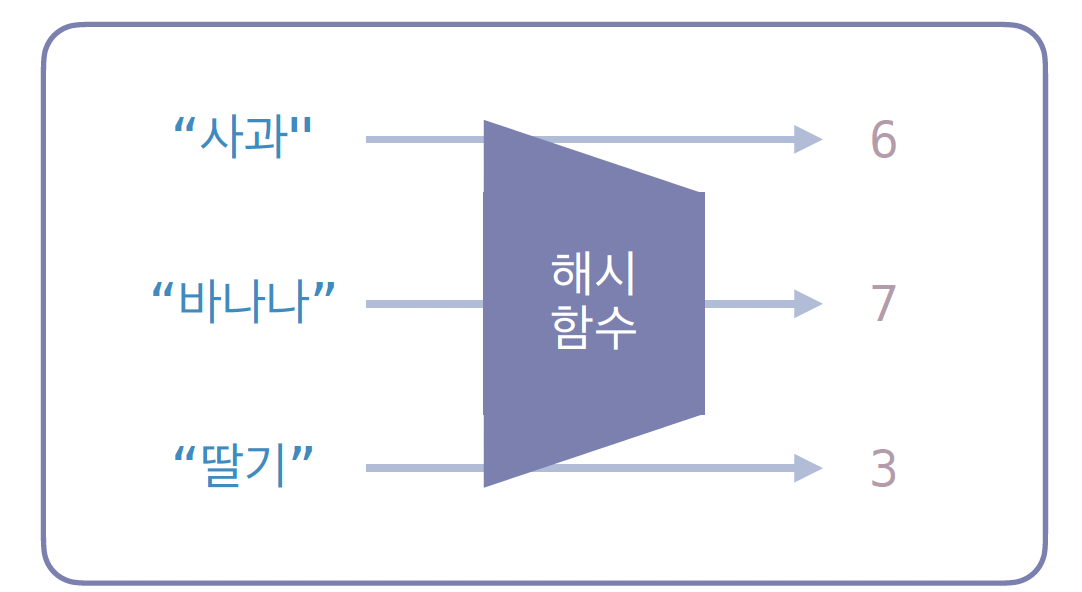
이때 사용되는 것이 바로 해시 함수(Hash Function)입니다.
-
해시 함수
- 어떠한 입력이 들어왔을 때 그 입력값을 특정 범위의 숫자로 변환해 주는 장치입니다.
-
해싱 과정
- 예를 들어 "사과"라는 키를 넣으면 해시 함수가 '6'이라는 숫자를 뱉어내고,
실제 메모리의 6번 인덱스 위치에 데이터를 저장하는 방식입니다. - 마찬가지로 "바나나"는 7, "딸기"는 3 같은 숫자로 변환되어 각각의 자리를 잡게 됩니다.
- 예를 들어 "사과"라는 키를 넣으면 해시 함수가 '6'이라는 숫자를 뱉어내고,
📌 2-2. 헷갈리기 쉬운 포인트 / 오해 정리
- 해시 테이블은 완전히 다른 메모리 저장 방식을 사용하나요?
- 아닙니다. 해시 테이블도 내부적으로는 배열을 사용합니다.
- 단지 사람이 이해하기 쉬운 문자열 키를 컴퓨터가 이해하는 숫자(인덱스)로 중간에서 번역해 주는 '해시 함수'가 있기 때문에 우리가 편리하게 사용할 수 있는 것입니다.
📌 2-3. 한 줄 정리
- 해시 테이블은 문자열 등 다양한 키를 해시 함수를 통해 숫자로 변환하여, 메모리 위치를 즉시 찾아가는 효율적인 자료구조입니다.
💻 참고
파이썬의
dict나 자바스크립트의Object,Map은 모두 이 해시 테이블 원리를 기반으로 구현되어 있습니다.실무에서
hash_table["apple"] = 100처럼 값을 추가하거나,del로 삭제하고,in연산자로 키 존재 여부를 확인하는 모든 과정이 내부적으로는 매우 빠른 숫자 변환과 인덱스 접근을 통해 이루어진다는 점을 기억하세요.
💡 비유로 이해하기
배열이 '번호가 매겨진 사물함'이라면, 해시 테이블은 '이름표가 붙은 사물함'입니다.
우리는 이름(키)만 대면 관리인(해시 함수)이 즉시 몇 번 사물함인지 알려주어 물건을 바로 꺼낼 수 있는 것과 같습니다.
📂 3. 해시 함수의 충돌과 해결 전략
📌 3-1. 해시 충돌(Collision)이란?
해시 함수는 입력 데이터를 특정 범위의 숫자로 매핑합니다.
이때 "서로 다른 입력이 동일한 해시 값을 가지게 되는 현상"을 충돌이라고 합니다.
각 문자의 ASCII 값을 단순히 더하는 해시 함수를 예로 들어보면
"abc"와 "cba"는 구성 문자가 같으므로 해시 결괏값이 동일하게 나옵니다.
이처럼 키가 다르더라도 해시 값으로 변환되었을 때 값이 겹칠 수 있으며,
이를 잘 해결하는 것이 자료구조의 신뢰성을 결정합니다.
📌 3-2. 좋은 해시 함수의 조건
-
계산 속도
- 로 빠르게 결과를 뱉어야 합니다.
-
결정론적(Deterministic)
- 같은 입력에는 항상 같은 값이 나와야 합니다.
-
낮은 충돌률
- 가급적 값이 겹치지 않아야 합니다.
-
고른 분포
- 특정 인덱스에 데이터가 쏠리지 않고 전체 공간에 골고루 퍼져야 성능이 유지됩니다.
📌 3-3. 충돌 해결 방법 1: 체이닝(Chaining)
가장 직관적인 방법으로 "같은 해시 값에 여러 데이터를 연결 리스트(Linked List) 형태로 매달아 관리"하는 방식입니다.
충돌이 발생했다고 해서 기존 데이터를 덮어쓰는 것이 아닙니다.
대신 연결 리스트를 사용해 데이터들이 서로 겹치지 않게 줄을 세웁니다.
이때 중요한 건 리스트에 '값'만 넣는 게 아니라 '키(Key)' 정보도 함께 저장한다는 점입니다.
그래야 나중에 동일한 해시 값을 조회했을 때, 리스트를 순회하며 우리가 찾는 진짜 키 값과 일치하는 데이터를 정확히 찾아낼 수 있습니다.
파이썬의 dict 자료형도 내부적으로 이 체이닝 방식을 활용하여 구현되어 있습니다.
📌 3-4. 충돌 해결 방법 2: 개방 주소법
충돌이 발생하면 리스트를 만드는 대신, "배열 내부의 다른 빈 공간을 찾아 떠나는" 방식입니다.
-
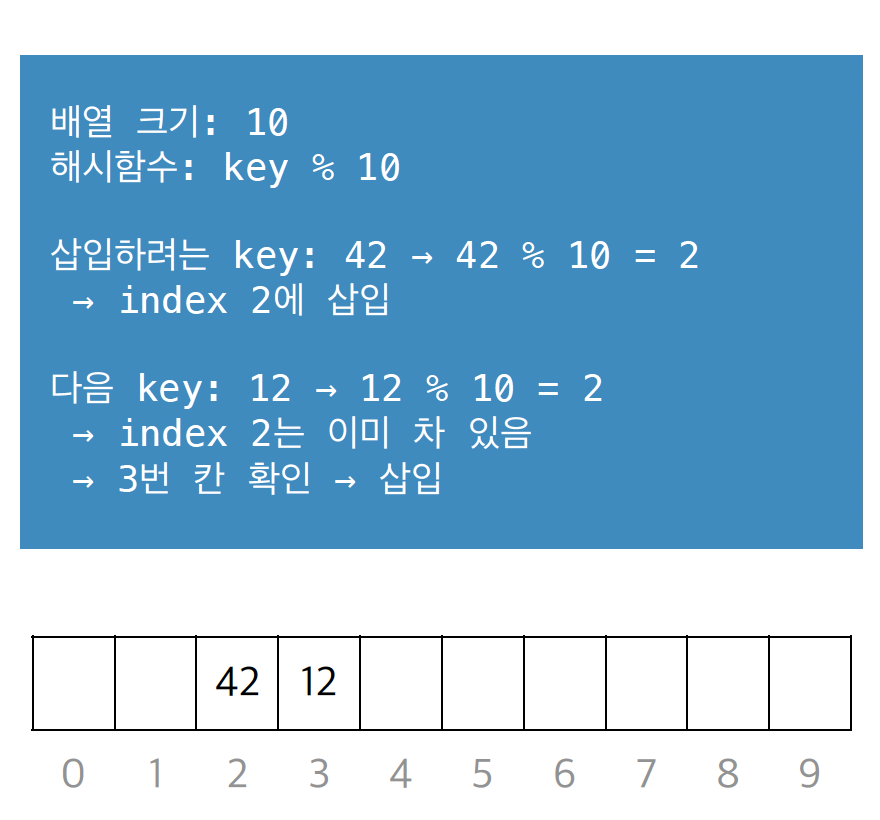
선형 탐색(Linear Probing)
-
충돌 시 바로 옆자리(인덱스 +1, +2, ...)를 순차적으로 확인합니다.
-
예시
-
배열 크기 10에서 키 42는 2번 칸에 저장됩니다.
-
이때 키 12가 들어오면 2번 칸에서 충돌이 나므로 바로 다음인 3번 칸이 비어있는지 확인하고 삽입합니다.
-
덩어리가 형성되는 클러스터링 현상이 생길 수 있다는 단점이 있습니다.
-
-
-
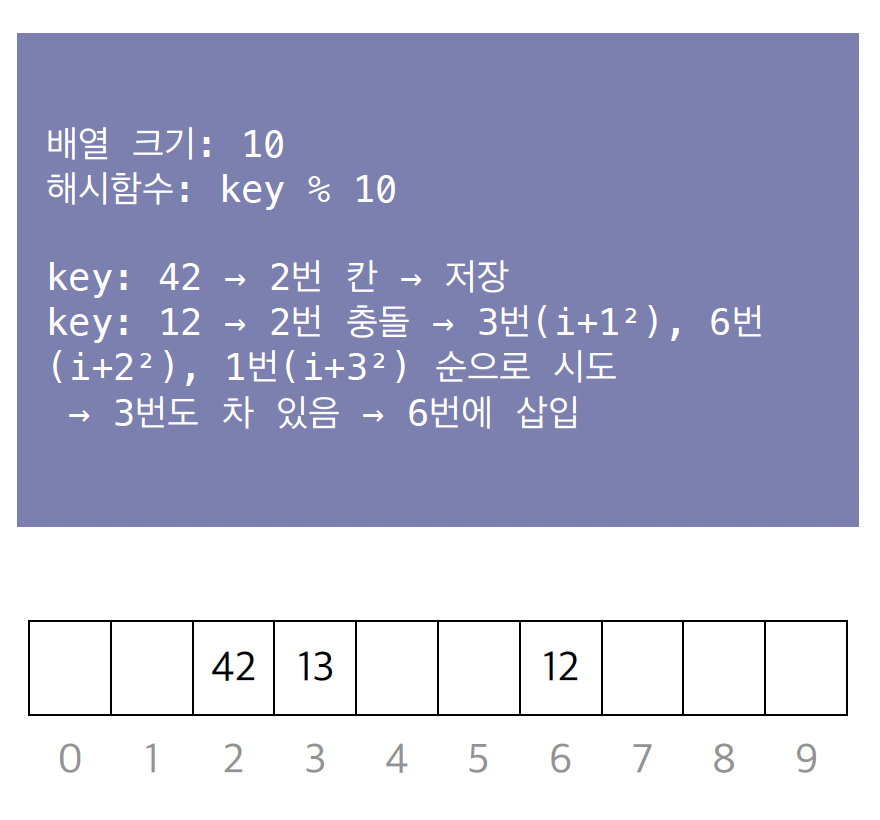
이차 탐색(Quadratic Probing)
-
옆자리 대신 보폭을 제곱(, ...)으로 늘려가며 탐색합니다.
-
특정 지역에 데이터가 물리는 문제를 완화합니다.
-
-
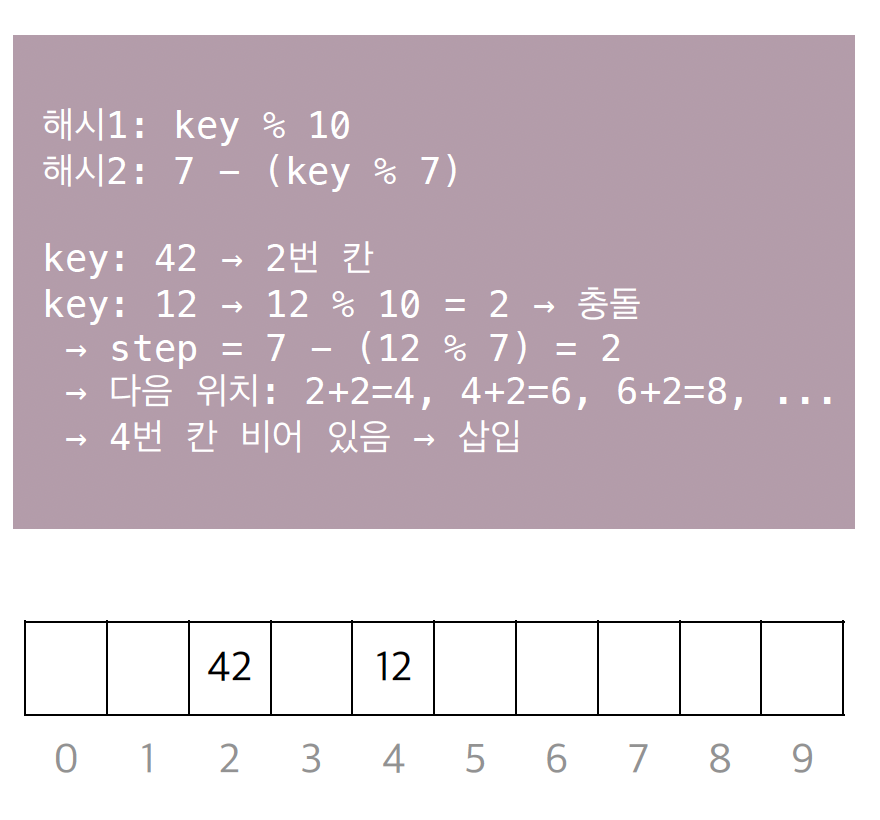
이중 해싱(Double Hashing)
-
두 개의 해시 함수를 사용합니다.
-
두 번째 해시값을 이동 간격(Step)으로 활용하여 탐색 위치를 불규칙하게 만듭니다.
-
충돌 분산 효과가 가장 좋습니다.
-
예시
-
해시1이
key % 10, 해시2가7 - (key % 7)일 때, 12는 2번 칸에서 충돌이 발생합니다. -
이때
step = 7 - (12 % 7) = 2이므로 4번 칸()을 확인하여 삽입합니다.
-
-
📌 3-5. 한 줄 정리
- 해시 충돌은 비둘기집 원리에 의해 피할 수 없는 현상이므로, 체이닝이나 개방 주소법 같은 전략을 통해 성능 저하를 방어하는 설계가 핵심입니다.
🎁 4. 정리
🔑 요약
| 구분 | 체이닝(Chaining) | 개방 주소법(Open Addressing) |
|---|---|---|
| 방식 | 버킷 뒤에 연결 리스트로 매달기 | 배열 내 다른 빈 칸 찾아가기 |
| 장점 | 구현이 비교적 단순하며 유연함 | 추가 메모리 공간(포인터) 소모가 없음 |
| 단점 | 동일 해시 값에 데이터가 쏠리면 성능 저하 | 데이터가 밀집되는 클러스터링 현상 발생 가능 |
| 성능 영향 | 메모리 외부에 추가 가능 | 배열이 꽉 차면 Resizing 비용이 크게 발생 |
