
[CS/자료구조] 05. 그래프 (Graph)와 탐색(BFS, DFS) 주제
⚡ 한 줄 요약: 정점과 간선으로 복잡한 관계를 정의하는 그래프 자료구조의 두 가지 구현법을 익히고, 상황에 맞는 최적의 탐색 알고리즘(BFS, DFS)을 선택하는 기준을 세웁니다.
1. 👋 들어가며: "세상은 연결로 이루어져 있다"
우리가 매일 사용하는 내비게이션의 빠른 길 찾기, SNS의 '알 수도 있는 친구' 추천, 심지어 우리가 작성하는 코드의 모듈 의존성까지, 세상의 모든 복잡한 관계는 '그래프'로 설명할 수 있습니다.
데이터를 단순히 저장하는 단계를 넘어, 데이터 사이의 관계를 어떻게 효율적으로 다루는지 알아봅니다.
-
🧐 Why:
- 단순히 데이터를 찾는 것을 넘어, "최단 경로는 무엇인가?" 혹은 "이 데이터와 저 데이터가 연결되어 있는가?"와 같은 복잡한 관계형 문제를 해결하기 위함입니다.
-
🎯 Goal:
- 그래프의 종류(방향, 가중치)를 구분하고, 상황에 따른 효율적인 구현 방식(인접 행렬 vs 인접 리스트)을 선택하며, BFS와 DFS를 직접 코드로 구현할 수 있습니다.
📂 2. 그래프 (Graph)
📌 2-1. 핵심 개념
그래프는 우리가 사는 복잡한 세상을 코드로 옮겨놓은 것과 같습니다. 데이터가 단순히 나열된 것이 아니라, 서로 어떻게 '연결'되어 있는지가 핵심입니다.
-
구성 요소
- 정점(Vertex, Node): 데이터가 실제로 저장되는 지점입니다.
- 간선(Edge): 정점과 정점 사이를 잇는 선으로, 둘 사이의 관계를 나타냅니다.
-
주요 특징 및 활용
- 객체 간의 연결 관계를 표현하는 데 매우 유용합니다.
- 우리가 매일 쓰는 네트워크, 소셜 미디어(SNS), 지도(길 찾기) 등이 모두 이 그래프 원리로 동작합니다.
-
그래프의 종류
-
방향 그래프(Directed Graph)
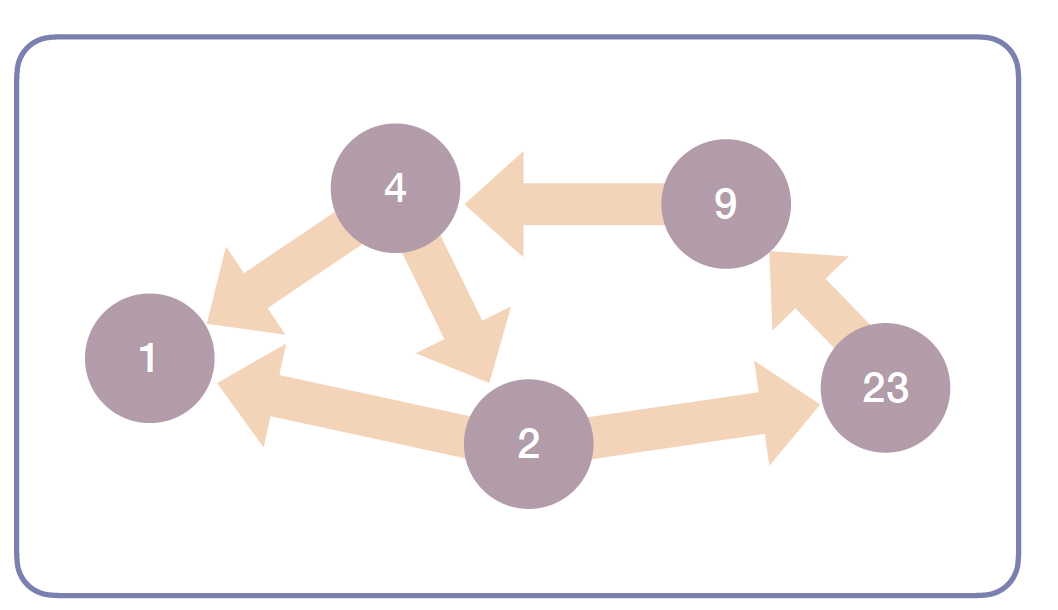
- 간선에 화살표처럼 정해진 방향이 있습니다.
- 한쪽으로만 이동이 가능합니다.
-
무방향 그래프(Undirected Graph)
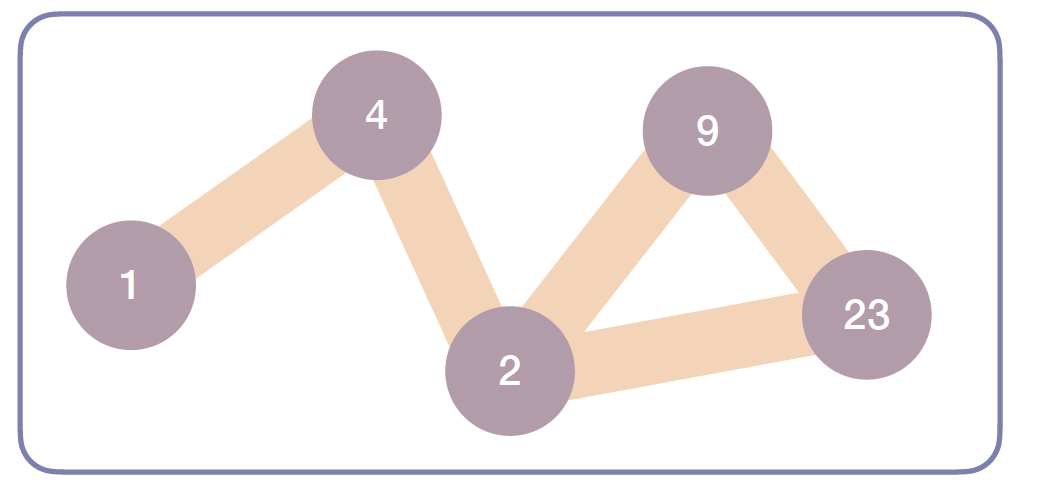
- 간선에 방향이 없어 양방향으로 자유롭게 이동할 수 있습니다.
-
가중 그래프(Weighted Graph)
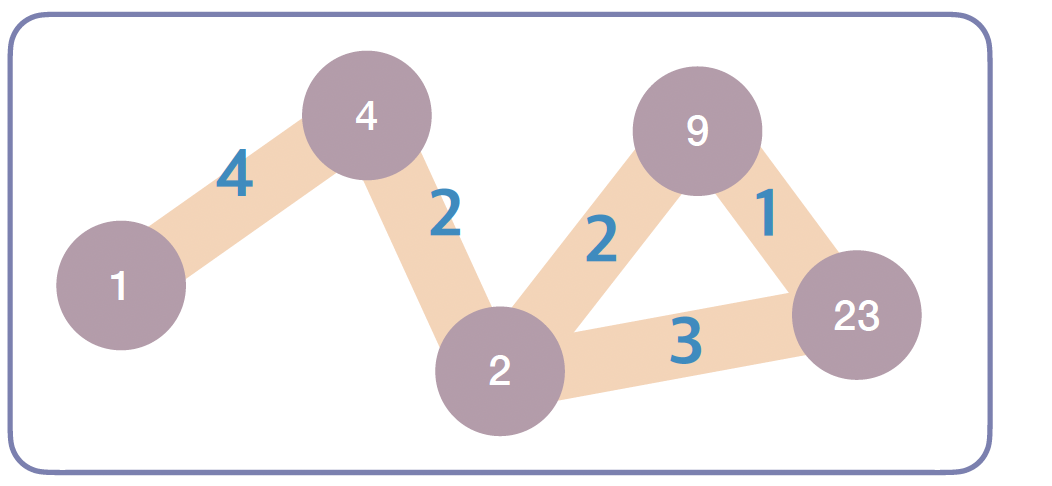
- 간선에 '비용'이나 '거리' 같은 가중치(Weight)가 부여된 형태입니다.
- 네비게이션의 길 찾기나 네트워크 연결 비용을 계산할 때 필수적입니다.
-
💡 비유로 이해하기
무방향 그래프는 서로 수락해야 맺어지는 '페이스북 친구'와 같고, 방향 그래프는 한쪽만 일방적으로 할 수 있는 '트위터 팔로워'와 같습니다.
여기에 각 도시 사이의 '실제 거리'를 숫자로 적어두면 가중 그래프가 되는 것이죠.
📌 2-2. 헷갈리기 쉬운 포인트 / 오해 정리
- 트리(Tree)와 그래프(Graph)는 완전히 별개인가요?
- 아닙니다. 트리는 그래프의 한 종류입니다. 사이클(순환)이 없고 모든 노드가 연결된 특수한 형태의 그래프가 트리입니다.
📌 2-3. 한 줄 정리
- 그래프는 관계의 본질을 정점과 간선으로 풀어낸 자료구조로, 방향성과 가중치 여부에 따라 다양한 현실 문제를 해결하는 도구입니다.
📂 3. 그래프 구현
그래프 구현은 정점 간의 연결 관계를 메모리에 저장하는 방식에 따라 인접 행렬과 인접 리스트 두 가지로 나뉩니다.
그래프를 코드로 구현할 때는 효율성(시간과 공간)의 트레이드오프를 반드시 고려해야 합니다.
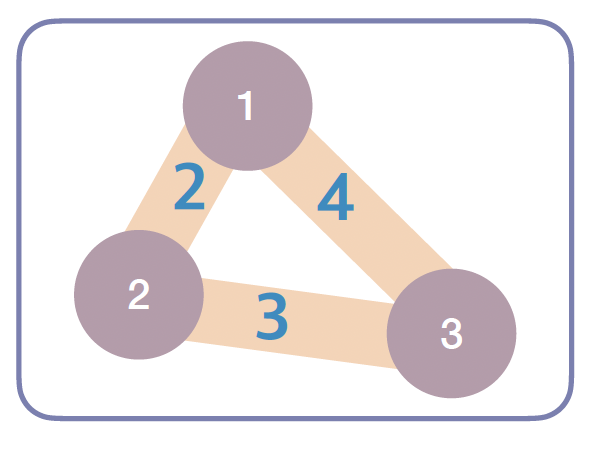
📌 3-1. 인접 행렬
-
정의
- 2차원 배열을 사용하여 정점 간의 연결 여부를 저장하는 방식입니다.
-
특징
- 빠른 조회
- 두 정점이 연결되어 있는지 확인하고 싶을 때, 배열 인덱스로 즉시 접근하여 만에 조회가 가능합니다.
- 메모리 낭비
- 정점의 개수가 일 때, 연결 여부와 상관없이 항상 크기의 공간이 필요하므로 메모리 사용량이 많습니다. ()
- 빠른 조회
-
구현 예시 (Python)
INF = float('inf') # 연결되지 않은 경우 무한대 설정 graph = [ [0, 2, 4], # 1번 정점에서의 가중치 [2, 0, 3], # 2번 정점에서의 가중치 [4, 3, 0] # 3번 정점에서의 가중치 ] print(graph[1][2]) # 2번과 3번 정점 사이의 가중치 '3' 출력
📌 3-2. 인접 리스트
-
정의
- 각 정점이 자신과 연결된 정점들의 정보를 리스트(또는 딕셔너리) 형태로 저장하는 방식입니다.
-
특징
- 메모리 효율
- 실제로 존재하는 간선()의 수만큼만 저장하므로 메모리를 적게 사용합니다. ()
- 탐색 유리
- 특정 정점과 연결된 모든 이웃 노드를 순회하며 탐색해야할 때 매우 유리합니다.
- 메모리 효율
-
구현 예시 (Python)
graph = { 1: [(2, 2), (3, 4)], # 1번과 연결된 (정점, 가중치) 2: [(1, 2), (3, 3)], # 2번과 연결된 노드들 3: [(1, 4), (2, 3)] } print(graph[2]) # 2번 정점과 연결된 모든 정보 출력
📌 3-3. 헷갈리기 쉬운 포인트 / 오해 정리
- 인접 리스트는 무조건 좋은 건가요?
- 아닙니다. 두 노드 와 가 연결되어 있는지 딱 한 번 확인하고 싶을 때, 리스트 방식은 의 리스트를 처음부터 끝까지 다 뒤져봐야 합니다. ()
- 반면, 행렬 방식은
graph[A][B]한 번이면 끝나기 때문에 조회 빈도와 데이터의 양 사이의 균형을 보는 눈이 필요합니다.
📌 3-4. 한 줄 정리
- 빠른 조회가 우선이고 간선이 많다면 인접 행렬, 메모리 절약과 이웃 노드 탐색이 중요하다면 인접 리스트를 사용합니다.
📂 4. BFS와 DFS
📌 4-1. 핵심 개념
그래프(또는 트리)에서 모든 노드를 탐색하는 알고리즘은 크게 두 갈래로 나뉩니다.
문제의 목적에 따라 어떤 '방향'으로 나아갈지가 핵심입니다.
-
너비 우선 탐색(BFS, Breadth-First Search)
- 시작 노드에서 가까운 노드부터 우선적으로 탐색하는 방식입니다.
-
깊이 우선 탐색(DFS, Depth-First Search)
- 한쪽 방향으로 끝까지 탐색한 후, 더 이상 갈 곳이 없으면 되돌아와서 다른 경로를 찾는 방식입니다.
📌 4-2. 동작 과정 상세
[BFS 동작 과정]
- 탐색을 시작할 노드를 큐(Queue)에 넣고 바로 방문 처리합니다.
- 큐에서 노드를 하나 꺼냅니다.
- 꺼낸 노드의 인접 노드들 중 방문하지 않은 노드들을 큐에 추가하면서 방문 처리합니다.
- 큐가 빌 때까지 이 과정을 반복합니다.
[DFS 동작 과정]
- 탐색을 시작할 노드를 스택(Stack) 또는 재귀로 방문 처리합니다.
- 현재 노드의 인접 노드들을 순서대로 확인합니다.
- 방문하지 않은 노드를 재귀 호출로 즉시 방문 처리합니다.
- 더 이상 방문할 노드가 없으면 이전 노드로 되돌아가 탐색을 이어갑니다.
📌 4-3. 코드 구현
-
BFS 구현
from collections import deque def bfs(graph, start): visited = set([start]) queue = deque([start]) while queue: node = queue.popleft() print(node, end=" ") # 방문한 노드 출력 for neighbor in graph[node]: if neighbor not in visited: visited.add(neighbor) queue.append(neighbor) -
DFS 구현 (재귀 방식)
def dfs(graph, node, visited=None): if visited is None: visited = set() visited.add(node) print(node, end=" ") # 방문한 노드 출력 for neighbor in graph[node]: if neighbor not in visited: dfs(graph, neighbor, visited)
[공통 그래프 정의 및 결과]
- 그래프 구조:
1: [2, 3], 2: [4], 3: [5], 4: [], 5: [] - BFS 결과:
1 2 3 4 5(층별 탐색) - DFS 결과:
1 2 4 3 5(깊이 우선)
📌 4-4. 헷갈리기 쉬운 포인트 / 오해 정리
- BFS와 DFS 둘 중 더 빠른 탐색은 무엇인가요?
- 탐색 속도 자체는 두 알고리즘 모두 모든 노드를 방문할 때 로 동일합니다.
- 중요한 건 어떤 순서로 데이터를 찾느냐 입니다.
- 최단 거리를 원한다면 BFS를, 깊은 인과 관계나 모든 조합을 보고 싶다면 DFS를 선택하는 안목이 필요합니다.
📌 4-5. 한 줄 정리
- 큐를 이용해 가까운 이웃부터 넓게 퍼져나가면 BFS, 재귀나 스택을 이용해 한 우물을 깊게 파고들면 DFS입니다.
💡 비유로 이해하기
BFS는 호수에 돌을 던졌을 때 동심원을 그리며 퍼져나가는 파동과 같고, DFS는 미로에서 한쪽 벽만 계속 짚으면서 막다른 길이 나올 때까지 가보는 탐색자와 같습니다.
🎁 5. 정리
🔑 요약
-
그래프 구현 방식
구분 인접 행렬 인접 리스트 저장 방식 2차원 배열 ( graph[i][j])연결 리스트 또는 딕셔너리 공간 복잡도 (간선 수에 비례) 조회 성능 (연결 여부 즉시 확인) (리스트를 순회해야 함) 추천 상황 간선이 매우 많은 밀집 그래프 간선이 적은 희소 그래프 -
탐색 알고리즘
구분 BFS(너비 우선 탐색) DFS(깊이 우선 탐색) 사용 자료구조 큐(Queue) 스택(Stack) 또는 재귀 탐색 특징 시작점 기준 가까운 노드부터 한 경로를 끝까지 파고든 후 복귀 주요 활용 최단 경로 찾기, 최단 거리 보장 모든 경우의 수 탐색, 사이클 확인 비유 호수의 파동 미로 찾기
