
[CS/자료구조] 06. 트리(Tree)
⚡ 한 줄 요약: 계층적 관계를 표현하는 트리의 기본 원리를 이해하고, 탐색(BST), 균형(AVL), 문자열(Trie), 우선순위(Heap) 등 상황에 특화된 변형 구조들의 차이점과 활용법을 익힙니다.
1. 👋 들어가며: "선형을 넘어 계층으로"
지금까지 배열, 스택, 큐와 같은 선형 자료구조를 배웠다면, 이제는 데이터 사이의 상하 관계와 계층을 표현하는 비선형 자료구조인 트리를 만날 차례입니다.
우리가 매일 다루는 HTML의 DOM 구조나 컴퓨터의 파일 시스템이 바로 트리의 대표적인 사례입니다.
-
🧐 Why:
-
단순히 데이터를 쌓아두는 것이 아니라, "어떻게 하면 수만 개의 데이터 중 원하는 것을 가장 빨리 찾을 수 있을까?"라는 질문에 최적의 해답을 주기 때문입니다.
-
특히 효율적인 검색 알고리즘과 데이터 정렬의 근간이 됩니다.
-
-
🎯 Goal:
- 트리의 기본 용어를 숙지하고, 이진 탐색 트리의 한계를 보완하는 AVL 트리의 원리를 이해하며, 자동완성의 핵심인 Trie와 우선순위 관리를 위한 Heap을 구분하여 설명할 수 있습니다.
📂 2. 트리
📌 2-1. 핵심 개념
트리는 정점(Vertex)과 간선(Edge)으로 구성된 계층적 구조를 가진 자료구조입니다.
단순히 데이터를 담는 것을 넘어, 데이터 간의 상하 관계를 표현하는 데 최적화되어 있습니다.
-
기본 구조
- 최상위 노드인 루트(Root)에서 시작하여 하위 노드인 자식(Child)으로 뻗어 나가는 구조입니다.
- 이때 각 노드는 부모-자식 관계를 형성하게 됩니다.
-
그래프와의 관계
- 트리는 그래프의 한 종류라고 할 수 있습니다.
- 하지만 일반적인 그래프와는 큰 차이점이 있습니다.
- 트리는 사이클이 없는(비순환) 연결 그래프이며, 하나의 루트를 중심으로 모든 노드가 연결되어 계층적인 구조를 이룹니다.
-
방향성
- 마치 조직도나 컴퓨터의 폴더 구조처럼, 트리는 한 방향으로만 뻗어 나가는 구조를 가집니다.
📌 2-2. 이진 트리 (Binary Tree)
실무와 알고리즘에서 가장 자주 쓰이는 형태입니다.
각 노드가 최대 두 개의 자식만을 가질 수 있는 트리로, 검색이나 정렬 알고리즘에서 매우 중요한 역할을 합니다.
-
정 이진 트리(Full Binary Tree)
- 모든 노드가 0개 또는 2개의 자식을 가집니다.
- 즉, 자식이 하나만 있는 노드가 존재하지 않습니다.
- 다만, 모든 리프 노드(자식이 없는 노드)의 깊이가 반드시 같을 필요는 없습니다.
-
포화 이진 트리(Perfect Binary Tree)
- 모든 노드가 0개 또는 2개의 자식을 가지면서, 모든 리프 노드의 깊이가 동일한 완벽한 피라미드 형태입니다.
-
완전 이진 트리(Complete Binary Tree)
- 리프 노드를 제외한 모든 레벨이 꽉 차 있고, 마지막 레벨은 왼쪽부터 차례대로 채워져 있는 구조입니다.
- 힙(Heap) 자료구조의 기본 뼈대가 됩니다.
📌 2-3. 헷갈리기 쉬운 포인트 / 오해 정리
- '포화' 이진 트리와 '완전' 이진 트리의 차이
- 모든 리프 노드의 레벨이 같아야 하는 까다로운 조건이 붙는 것은 포화 이진 트리입니다.
- 반면, 완전 이진 트리는 마지막 레벨이 다 차지 않아도 되지만, 반드시 왼쪽부터 빈틈없이 채워져야 한다는 점에서 차이가 있습니다.
📌 2-4. 한 줄 정리
트리는 루트에서 시작해 한 방향으로 뻗어 나가는 사이클 없는 계층형 그래프입니다.
📂 3. 이진 탐색 트리 (Binary Search Tree, BST)
📌 3-1. 이진 탐색 트리
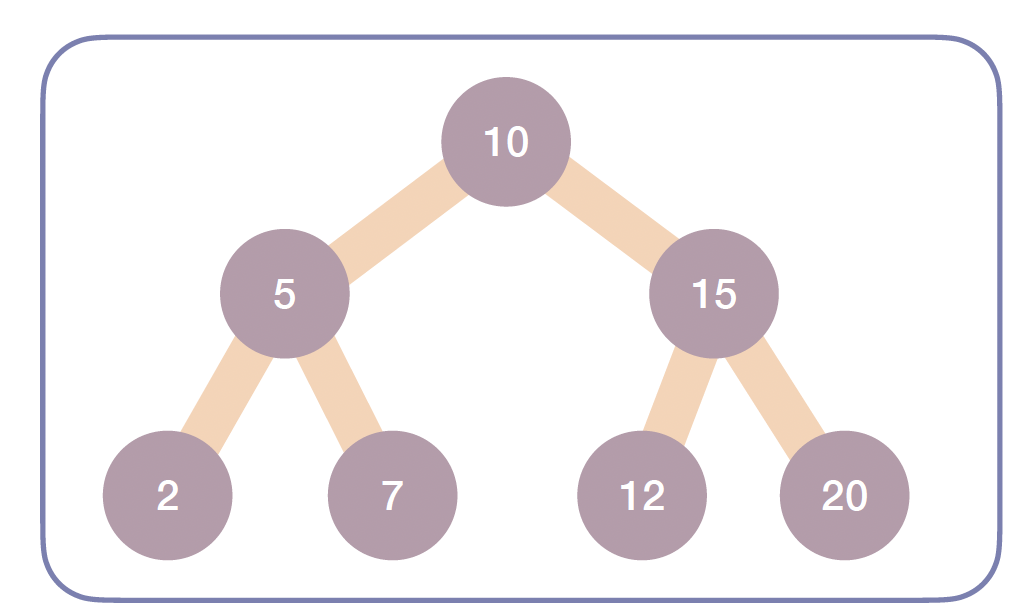
이진 탐색 트리(BST)는 정렬된 데이터를 효율적으로 검색, 삽입, 삭제할 수 있도록 설계된 이진 트리의 한 종류입니다.
-
핵심 규칙
- 각 노드를 기준으로 왼쪽 서브트리는 부모보다 작은 값, 오른쪽 서브트리는 부모보다 큰 값을 가집니다.
-
검색 원리
- 루트에서 시작하여 찾고자 하는 값과 현재 노드를 비교합니다.
- 현재 노드보다 작은 값이면 왼쪽으로, 큰 값이면 오른쪽으로 이동하며 탐색합니다.
-
성능
- 검색, 삽입, 삭제 연산의 평균 시간 복잡도는 입니다.
-
주의점 (편향 트리)
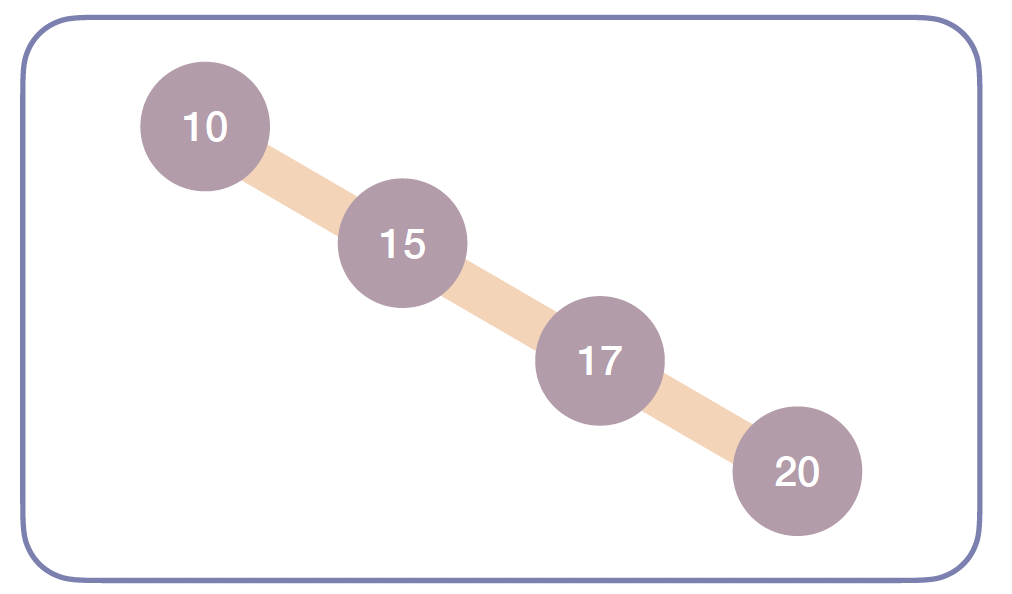
- 데이터가 이미 정렬된 상태로 들어오는 등 특정 방향으로만 삽입이 반복되면 트리가 한쪽으로 치우친 편향 트리가 됩니다.
- 이 경우 성능이 최악의 경우 까지 저하되어 연결 리스트와 다를 바 없게 됩니다.
📌 3-2. BST의 삽입과 삭제
BST는 데이터가 추가되거나 삭제될 때마다 '왼쪽은 작고 오른쪽은 크다'라는 조건을 유지해야 합니다.
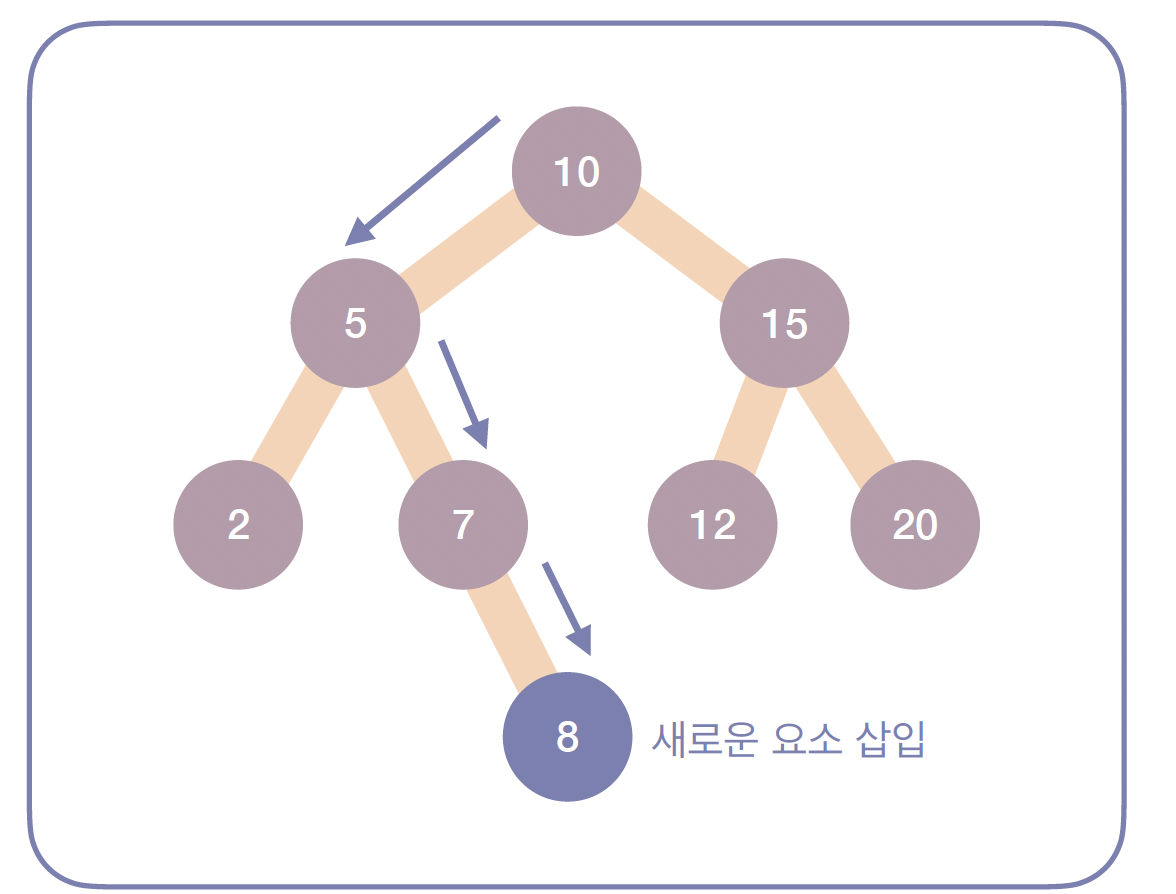
- 요소 삽입
- 새로운 값을 넣을 때, 루트부터 비교하여 적절한 위치(비어있는 리프 노드 방향)을 찾아 배치합니다.
-
요소 삭제
-
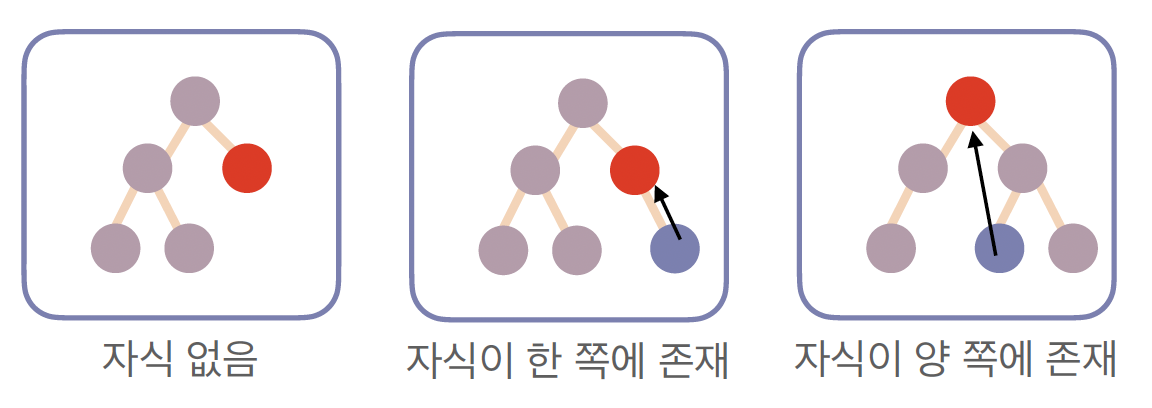
삭제는 비교적 복잡하며 세 가지 경우에 따라 처리합니다.
-
자식이 없는 리프 노드
- 단순히 제거합니다.
-
자식이 하나만 있는 경우
- 삭제한 노드의 위치로 그 자식을 올립니다.
-
자식이 둘인 경우
- 오른쪽 서브트리에서 가장 작은 값을 찾아 삭제할 노드 위치로 가져와 대체합니다.
-
-
📌 3-3. 트리의 순회 (Tree Traversal)
트리 순회는 트리 구조의 모든 노드를 한 번씩 방문하는 과정입니다.
이진 트리에서는 방문 순서에 따라 세 가지 방식이 있습니다.
-
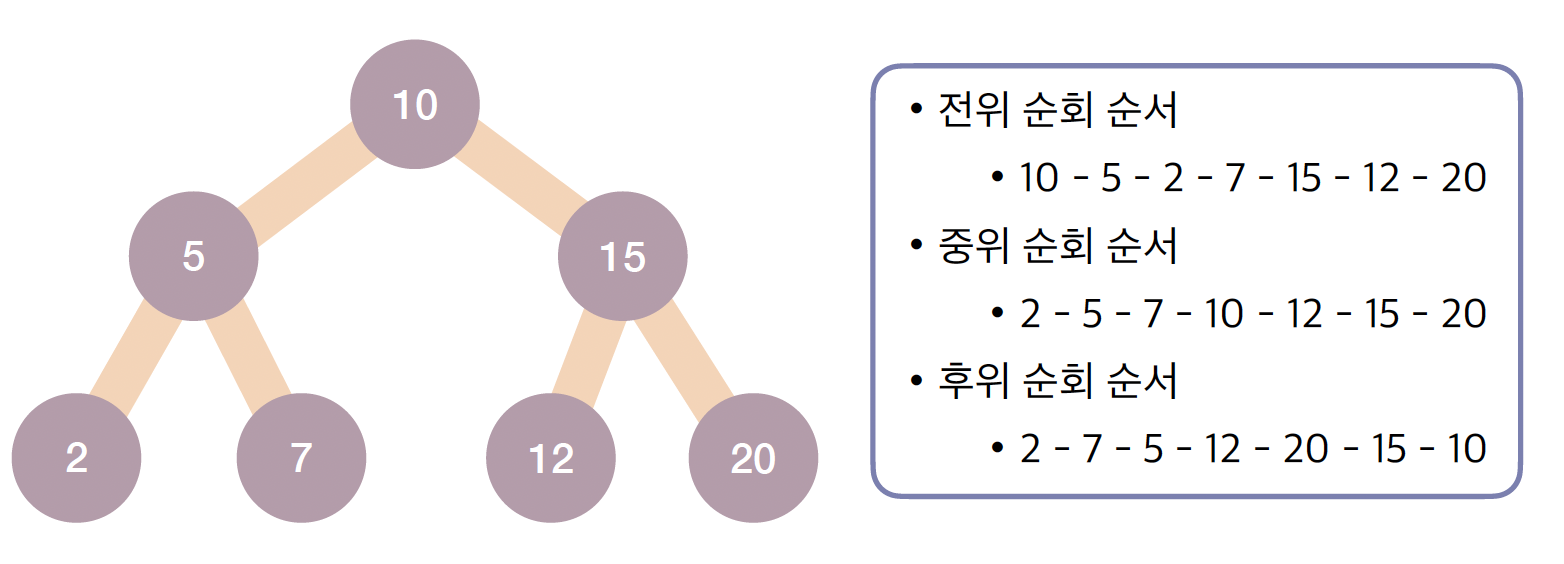
전위 순회 (Preorder)
- Root → Left → Right 순으로 방문합니다.
-
중위 순회 (Inorder)
- Left → Root → Right 순으로 방문합니다.
- 특히 BST에서 중위 순회를 하면 데이터를 오름차순으로 정렬된 결과를 얻을 수 있다는 점이 매우 중요합니다.
-
후위 순회 (Postorder)
- Left → Right → Root 순으로 방문합니다.
📌 3-4. 한 줄 정리
- 이진 탐색 트리는 평균 의 효율적인 탐색을 보장하지만 편향성이라는 약점이 있으며, 이를 중위 순회하면 정렬된 데이터를 얻을 수 있습니다.
📂 4. AVL 트리
📌 4-1. 핵심 개념
일반적인 이진 탐색 트리는 삽입이나 삭제가 특정 방향으로 반복될 경우, 트리 모양이 한쪽으로 치우치는 '편향 트리'가 될 위험이 있습니다.
이렇게 되면 탐색 성능이 까지 떨어져 효율성이 급격히 나빠집니다.
-
탄생 배경
- 이 문제를 해결하기 위해 노드 삽입/삭제 후 트리의 높이를 자동으로 조정하는 균형 이진 탐색 트리(Balanced BST) 개념이 등장했습니다.
- 참고로 AVL이라는 이름은 이 자료구조를 고안한 아델슨-벨스키(Adelson-Velsky)와 란디스(Landis)의 이름 앞글자를 따서 붙여졌습니다.
-
동작 원리
- AVL 트리는 각 노드마다 높이 정보를 저장하며, 왼쪽과 오른쪽 서브트리의 높이 차이를 1 이하로 유지하도록 강제합니다.
- 만약 이 균형이 깨지면 회전(Rotation) 연산을 통해 다시 균형을 맞춥니다.
-
불균형 케이스와 해결
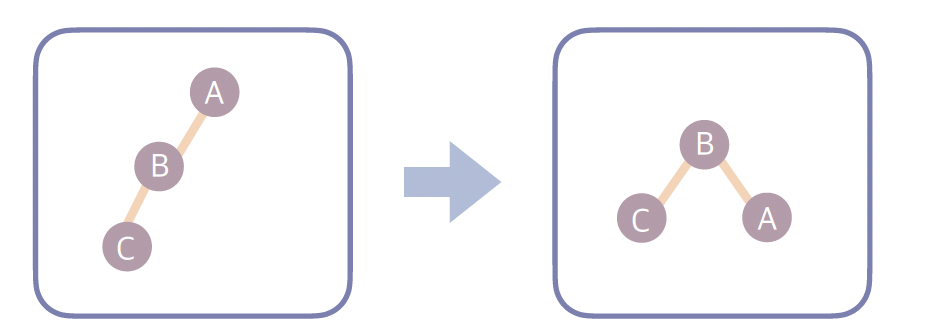
1. LL(Left-Left)
- 왼쪽 자식의 왼쪽 서브트리가 무거운 경우 → 오른쪽 회전으로 해결
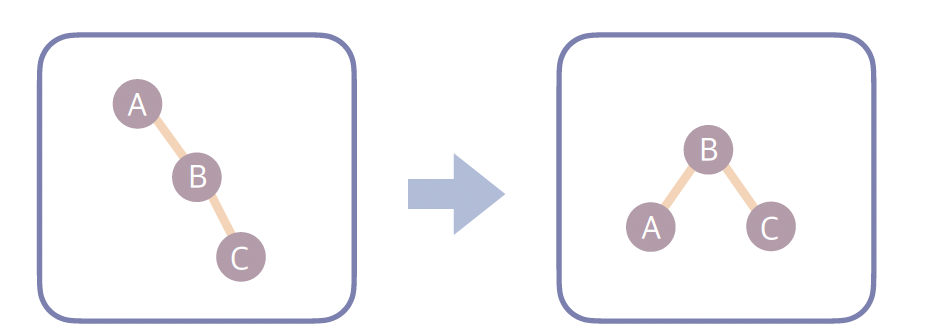
2. RR(Right-Right)
- 오른쪽 자식의 오른쪽 서브트리가 무거운 경우 → 왼쪽 회전으로 해결
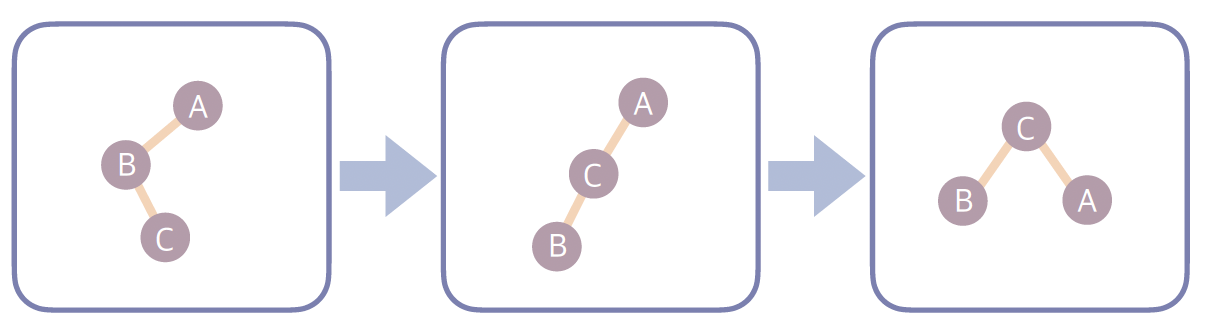
3. LR(Left-Right)
- 왼쪽 자식의 오른쪽 서브트리가 무거운 경우 → 왼쪽 회전 후 오른쪽 회전으로 해결
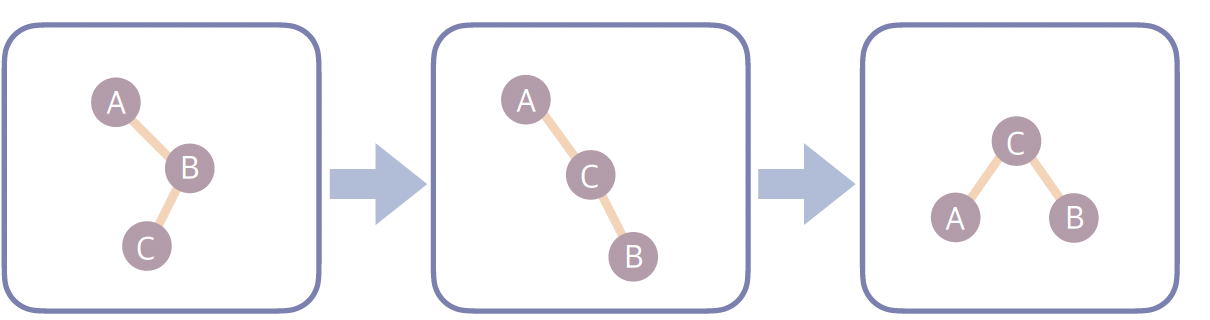
4. RL(Right-Left)
- 오른쪽 자식의 왼쪽 서브트리가 무거운 경우 → 오른쪽 회전 후 왼쪽 회전으로 해결
📌 4-2. 헷갈리기 쉬운 포인트 / 오해 정리
- 회전 연산을 하면 트리의 데이터 순서가 뒤섞이는 것 아닌가요?
- 회전 연산은 노드들의 값의 순서를 바꾸는 연산이 아니라, 그 순서를 유지한 채 구조적 위치만 재배치하는 연산입니다.
- 따라서 회전을 거치더라도 이진 탐색 트리의 대소 관계 특성(왼쪽 < 부모 < 오른쪽)은 그대로 유지됩니다.
📌 4-3. 한 줄 정리
- AVL 트리는 회전 연산을 통해 구조적 위치를 재배치함으로써, 데이터의 순서는 유지하면서도 최악의 탐색 성능을 으로 방어하는 강력한 균형 트리입니다.
💻 참고
실무에서는 AVL 트리보다 조금 더 유연한 균형을 유지하는 레드-블랙 트리(Red-Black Tree)가 더 자주 쓰이기도 합니다.
AVL은 탐색 속도가 절대적으로 중요한 경우에 유리하고, 레드-블랙 트리는 삽입/삭제가 빈번하여 회전 비용을 줄여야 하는 상황(예: Java의 TreeMap, C++의 std::map)에서 선호됩니다.
📂 5. Trie
📌 5-1. 핵심 개념
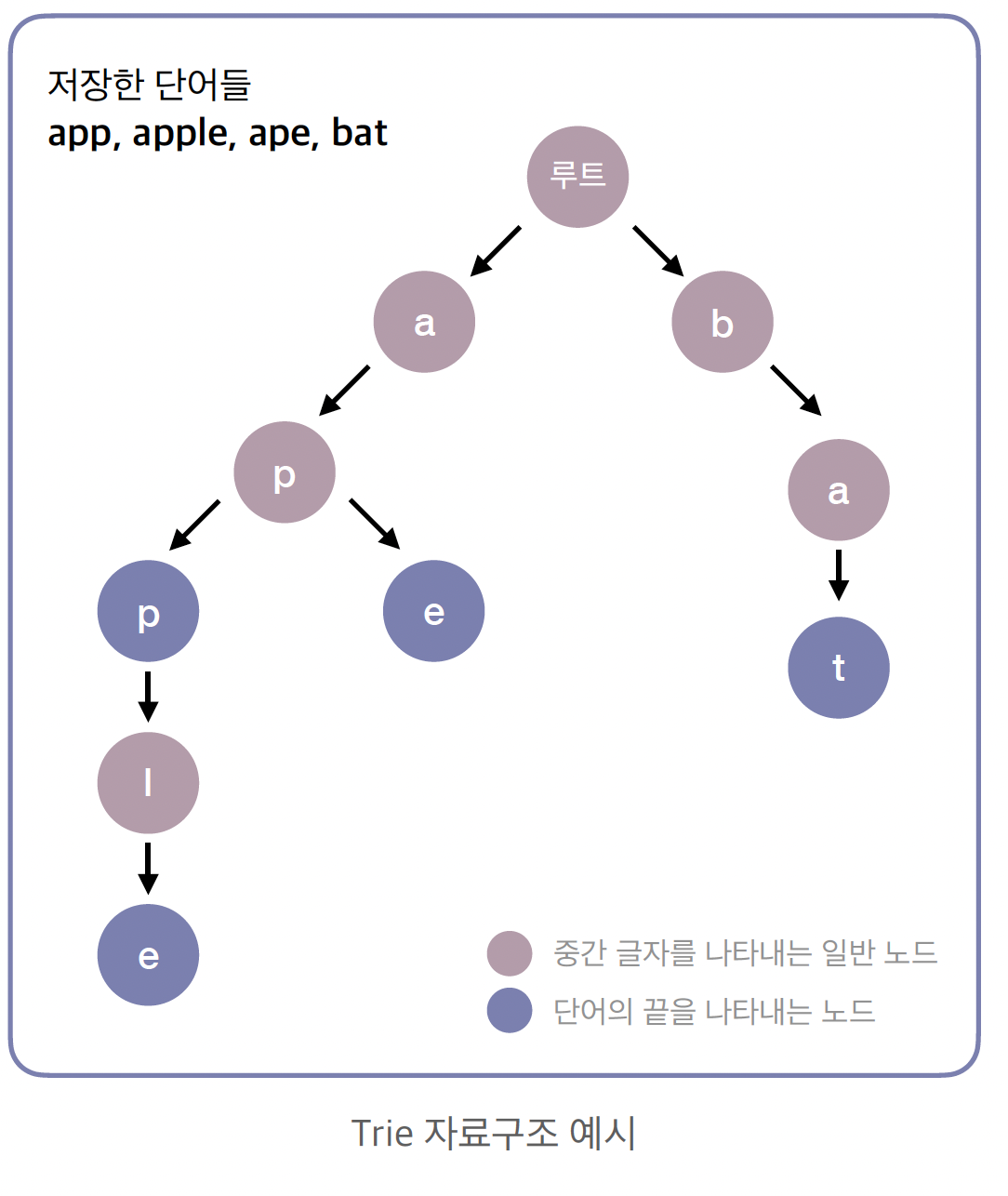
트라이는 여러 개의 문자열을 글자 단위로 나누어 트리 형태로 저장하는 자료구조입니다.
Retrieval(탐색)이라는 단어의 중간에서 이름을 따온 만큼, 특정 단어가 존재하는지 확인하거나 특정 접두사(Prefix)로 시작하는 단어를 찾는 데 최적화되어 있습니다.
우리가 매일 사용하는 검색창의 자동완성이나 휴대폰의 연락처 검색 기능이 바로 이 트라이의 원리를 이용한 대표적인 사례입니다.
💡 비유로 이해하기
사전에서 단어를 찾는 과정과 같습니다.
'apple'을 찾을 때 처음부터 끝까지 다 읽는 게 아니라, 'a' 섹션을 열고, 그 다음 'p'를 찾고, 'p'를 찾는 식으로 한 글자씩 경로를 좁혀가는 것과 똑같은 방식입니다.
트라이는 해시 테이블처럼 문자열 전체를 통째로 저장하는 것이 아니라, 문자 하나하나를 따라 내려가면서 구성하는 것이 가장 큰 특징입니다.
📌 5-2. 왜 트라이를 써야 할까?
문자열을 찾을 때 가장 먼저 떠오르는 건 '해시 테이블'일 겁니다. 하지만 트라이는 해시 테이블이 갖지 못한 강력한 무기가 있습니다.
-
압도적인 탐색 속도
- 문자열의 길이를 이라고 할 때, 삽입과 검색이 모두 에 끝납니다.
- 데이터가 아무리 많아도 단어 길이만큼만 내려가면 되니까요.
-
접두사 검색의 효율성
- "이 접두사로 시작하는 단어가 있는가?"라는 질문에 가장 완벽한 해답을 줍니다.
- 공통 접두사를 가진 단어들이 앞부분 경로를 공유하기 때문입니다.
- 예를 들어 'ap'를 입력하면 트라이는 이미 그 경로에 있는 'app', 'apple', 'application' 등을 즉시 후보로 띄울 수 있습니다.
-
트레이드오프(단점)
- 각 글자마다 노드를 생성해야 하므로 메모리 사용량이 상당히 큽니다.
- 또한 구현이 해시 테이블보다 복잡하다는 점도 기억해야 합니다.
📌 5-3. 각 노드의 구성 요소
트라이의 각 노드는 크게 두 가지 정보를 가집니다.
-
children
- 현재 문자 다음에 올 수 있는 문자들을 저장하는 딕셔너리입니다.
- 만약 현재 문자가 'a'라면 다음에 올 수 있는 'p'나 't' 같은 문자들을 키(Key)로 삼아 다음 노드를 가리킵니다.
-
is_end
- 해당 노드까지가 하나의 완성된 단어가 끝나는 지점인지를 표시하는 불리언(Boolean) 값입니다.
- 루트 노드의 역할
- 트라이는 항상 하나의 루트 노드에서 시작합니다.
- 이 루트는 실제 문자를 의미하지 않고, 모든 단어가 시작되는 출발점 역할만 수행합니다.
📌 5-4. 트라이의 구현 원리
트라이는 문자열 전체를 저장하는 대신, 한 글자씩 내려가는 경로로 표현합니다.
app, apple, ape라는 세 단어를 넣는다면, 루트에서 'a' → 'p'까지는 경로를 공유하다가 그 이후에 갈라지는 식입니다.
class TrieNode:
def __init__(self):
self.children = {} # 자식 노드들을 저장
self.is_end = False # 단어의 끝인지 표시
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word): # 단어 삽입
curr = self.root
for ch in word:
if ch not in curr.children:
curr.children[ch] = TrieNode()
curr = curr.children[ch]
curr.is_end = True
def search(self, word): # 단어 존재 여부 검색
curr = self.root
for ch in word:
if ch not in curr.children: return False
curr = curr.children[ch]
return curr.is_end
def starts_with(self, prefix): # 접두사 검색 (자동완성의 핵심!)
curr = self.root
for ch in prefix:
if ch not in curr.children: return False
curr = curr.children[ch]
return True📌 5-5. 헷갈리기 쉬운 포인트 / 오해 정리
- 해시 테이블보다 무조건 빠른가요?
- 단순 검색은 해시 테이블도 평균 이라 빠릅니다.
- 하지만 해시는 '접두사 검색' 기능이 없고, 데이터가 많아질수록 충돌(Collision) 위험이 있습니다.
- 반면 트라이는 문자열의 공통 구조를 활용하므로 자동완성 같은 특정 상황에서 훨씬 유리합니다.
📌 5-6. 한 줄 정리
트라이는 문자열의 공통 접두사를 공유하여 저장하는 트리 구조로, 문자열 탐색과 접두사 검색을 속도로 해결하는 자동완성의 핵심 자료구조입니다.
💻 참고
실무에서 대량의 태그 자동완성이나 유저 검색 기능을 구현해야할 때가 있습니다.
이때 라이브러리 없이 직접 트라이를 구축해 성능을 최적화한다면, 성능에 대한 깊은 고민을 해볼 수 있습니다.
📂 6. 힙 (Heap)
📌 6-1. 힙의 정의와 구조적 특징
힙은 완전 이진 트리 기반의 자료구조입니다.
리프 노드를 제외한 모든 레벨이 꽉 차 있어야 하며 마지막 레벨은 왼쪽부터 채워져야 하는 구조를 가집니다.
-
용도
- 주로 우선순위 큐(Priority Queue)를 구현하는 데 사용됩니다.
-
특징
- 부모 노드가 자식 노드보다 항상 크거나(최대 힙) 작아야(최소 힙) 합니다.
-
루트의 특별함
- 이 규칙 덕분에 힙의 루트 노드는 항상 전체 데이터 중 최댓값 또는 최솟값을 가지게 됩니다.
-
성능
- 삽입과 삭제 연산 모두 의 시간 복잡도를 가집니다.
📌 6-2. 힙의 종류
힙은 부모와 자식 간의 크기 관계에 따라 크게 두 가지로 나뉩니다.
-
최대 힙(Max Heap)
- 부모 노드가 자식 노드보다 큽니다.
- 루트 노드가 항상 최댓값을 가지며, 우선순위가 높은(큰 값) 데이터를 빠르게 꺼낼 때 씁니다.
-
최소 힙(Min Heap)
- 부모 노드가 자식 노드보다 작거나 같습니다.
- 루트 노드가 항상 최솟값을 가지며, 작은 값을 우선적으로 처리할 때 사용합니다.
📌 6-3. 힙의 핵심 연산: 삽입과 삭제
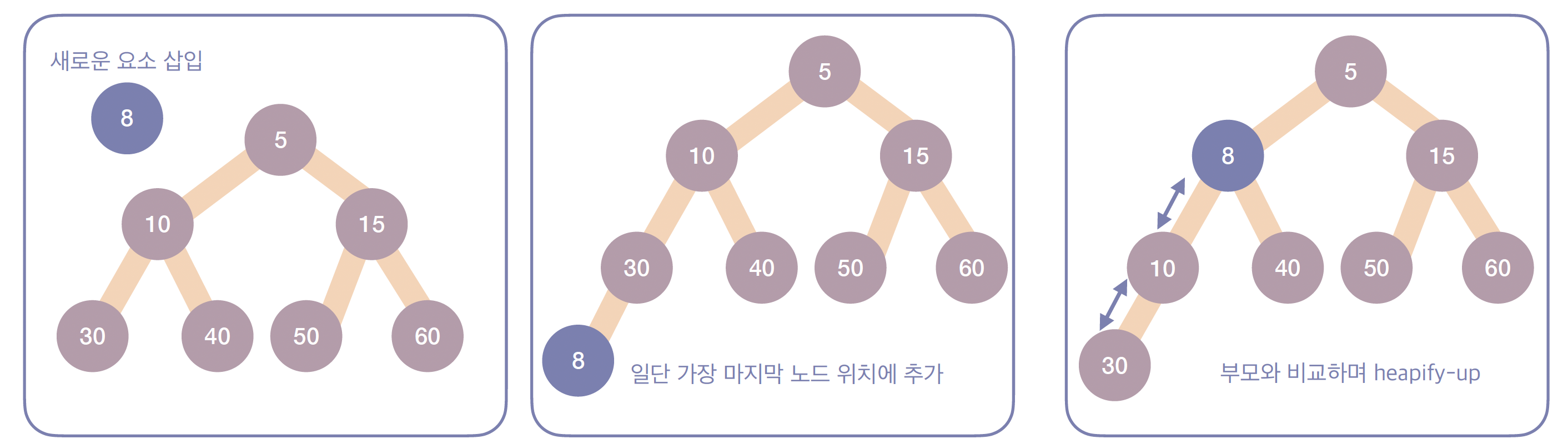
-
삽입(Insert) 연산 과정
-
단계 1
- 새로운 노드를 트리의 가장 마지막 노드 위치에 추가합니다.
-
단계 2
- 부모 노드와 비교하여 조건을 만족할 때까지 서로 위치를 바꿉니다. (Heapify-Up)
-
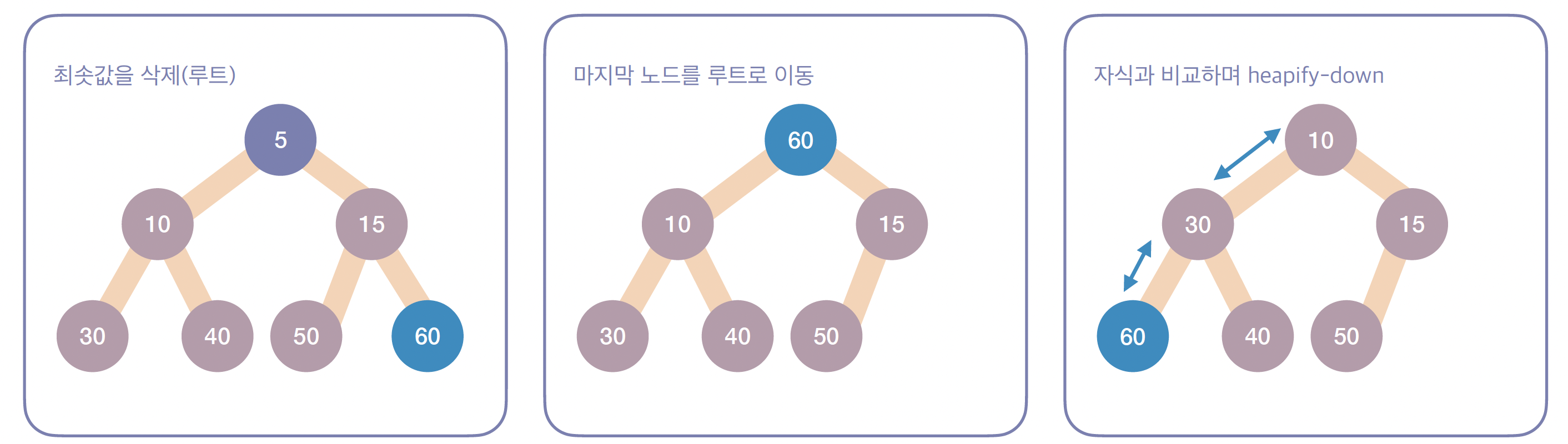
-
삭제(Delete) 연산 과정
-
단계 1
- 최댓값 또는 최솟값이 있는 루트 노드를 제거 합니다.
-
단계 2
- 트리의 마지막 노드를 루트 노드로 이동시킵니다.
-
단계 3
- 이동한 노드를 자식 노드와 비교하여 적절한 위치까지 내려보냅니다. (Heapify-Down)
-
📌 6-4. 헷갈리기 쉬운 포인트 / 오해 정리
-
정렬 상태에 대한 오해
- 힙은 '느슨한 정렬' 상태입니다. 부모가 자식보다 크다는 건 확실하지만, 왼쪽 자식과 오른쪽 자식 중 누가 더 큰지는 알 수 없습니다.
- 전체를 정렬하는 게 목적이 아니라 우선순위가 가장 높은 놈 하나만 빠르게 찾는 게 목적이기 때문입니다.
-
이진 탐색 트리(BST)와의 차이점
- BST는 '왼쪽 자식 < 부모 < 오른쪽 자식'이라는 좌우 방향의 정렬이 핵심이라면, 힙은 상하 관계(부모와 자식 간의 크기)만 따지는 느슨한 정렬 상태입니다.
-
메모리 힙과의 관계
- 이름은 같지만 전혀 다른 개념입니다.
- 자료구조의 힙은 데이터를 관리하는 '구조'를 말하고, 메모리의 힙은 동적 할당이 일어나는 '영역'을 말합니다.
📌 6-5. 한 줄 정리
- 힙은 완전 이진 트리 기반으로 우선순위가 높은 요소를 효율적으로 추출하기 위해 설계된, 우선순위 큐의 핵심 자료구조입니다.
🎁 7. 정리
🔑 요약
| 자료구조 | 핵심 특징 | 주요 장점 | 시간 복잡도(탐색) | 실무 활용 사례 |
|---|---|---|---|---|
| 이진 탐색 트리 | 좌우 대소 관계 유지 | 정렬된 상태 유지, 효율적 탐색 | 평균 | 데이터 검색 엔진 기초 |
| AVL 트리 | 스스로 균형을 잡는 BST | 편향 트리 방지, 최악의 경우 보장 | 항상 | 엄격한 탐색 성능 필요 시 |
| 트라이 (Trie) | 문자열 접두사 공유 | 문자열 탐색 및 접두사 검색 최적화 | (L=길이) | 검색어 자동완성, 사전 |
| 힙 (Heap) | 느슨한 정렬(부모-자식) | 최댓값/최솟값 즉시 추출 | 우선순위 큐, 스케줄링 |
