
학습내용
-
Redshift 권한과 보안
-
Redshift 백업과 테이블 복구
-
Redshift 관련 기타 서비스 소개
-
Redshift Spectrum으로 S3 외부 테이블 조작해보기
-
Redshift ML 사용하기
-
Redshift 중지/제거하기
1. Redshift 권한과 보안
-
일반적으로 사용자 별 테이블 권한 설정은 너무 복잡하고 실수할 가능성이 높아 잘 하지 않음
-
역할 혹은 그룹 별로 스키마 별 접근 권한을 주는 것이 일반적
-
RBAC(Role Based Access Control)이 새로운 트렌드
-
여러 역할에 속한 사용자의 경우, 각 역할의 권한을 모두 가짐
-
-
개인정보와 관련된 테이블이라면 별도의 스키마 설정
- 극히 일부 사람이 속한 역할에 접근 권한 부여
- 극히 일부 사람이 속한 역할에 접근 권한 부여
-
권한 부여
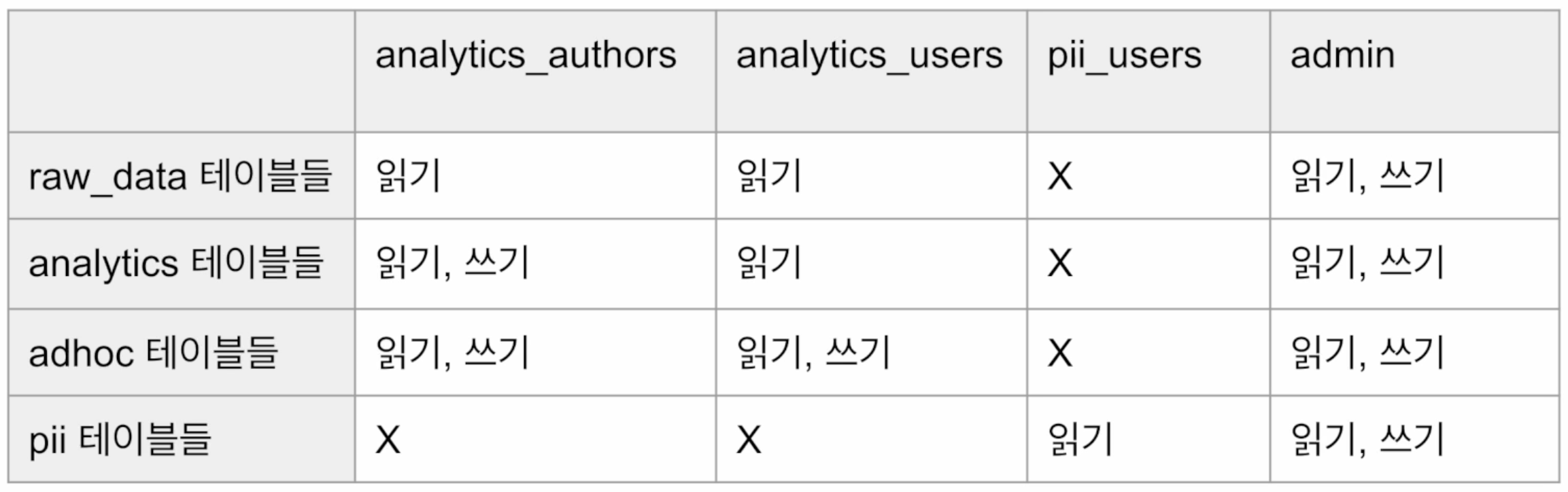
-- 스키마에 대한 권한과 테이블에 대한 권한을 같이 줘야 함 GRANT ALL ON SCHEMA analytics TO GROUP analytics_authors; GRANT ALL ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_authors; GRANT ALL ON SCHEMA adhoc TO GROUP analytics_authors; GRANT ALL ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_authors; -- 테이블에 대한 읽기 권한만 부여 GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_authors; GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_authors;GRANT USAGE ON SCHEMA analytics TO GROUP analytics_users; GRANT SELECT ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_users; GRANT ALL ON SCHEMA adhoc TO GROUP analytics_users; GRANT ALL ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_users; GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_users; GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_users;GRANT USAGE ON SCHEMA pii TO GROUP pii_users; GRANT SELECT ON ALL TABLES IN SCHEMA pii TO GROUP pii_users;- 그룹은 매번 중복되는 SQL문을 작성해야 하기 때문에, 계승이 가능한 역할을 사용하면 훨씬 간편해짐
- 그룹은 매번 중복되는 SQL문을 작성해야 하기 때문에, 계승이 가능한 역할을 사용하면 훨씬 간편해짐
-
컬럼 레벨 보안
-
테이블 내의 특정 컬럼(들)을 특정 사용자나 특정 그룹/역할에만 접근 가능하게 하는 것
-
보통 개인정보 등에 해당하는 컬럼을 권한이 없는 사용자에게 감추는 목적으로 사용
-
실수로 노출할 수도 있기 때문에 좋은 방법은 아님
-
이러한 컬럼들을 별도의 테이블로 분리해 구성하는 것이 더 좋은 방법
-
이보다도 더 좋은 방법은, 보안이 필요한 정보를 데이터 시스템에 적재하지 않는 것
-
-
-
레코드 레벨 보안
-
테이블 내의 특정 레코드(들)을 특정 사용자나 특정 그룹/역할에만 접근 가능하게 하는 것
-
특정 사용자/그룹의 특정 테이블 대상 SELECT, UPDATE, DELETE 작업에 추가 조건을 부여하는 방식으로 동작
-
이를 RLS(Record Level Security)라고 부름
-
CREATE RLS POLICY 명령어로 생성, ATTACH RLS POLICY 명령어로 특정 테이블에 추가
-
-
컬럼 레벨 보안과 마찬가지로 좋은 방법은 아님
-
2. Redshift 백업과 테이블 복구
-
기본적인 백업 방식은 마지막 백업으로부터 바뀐 내용만 저장
-
이를 스냅샷이라고 부름
-
백업을 통해 과거로 돌아가 그 시점의 내용으로 특정 테이블 복구 가능(Table Restore)
-
과거 시점의 내용으로 Redshift 클러스터 새로 생성도 가능
-
-
자동 백업
-
기본은 하루이지만 최대 35일 전까지의 변경사항 백업 가능
- Redshift 클러스터 -> Maintenance -> Edit -> Automated snapshot retention period 설정
- Redshift 클러스터 -> Maintenance -> Edit -> Automated snapshot retention period 설정
-
이 경우 백업은 같은 리전에 있는 S3에 이루어짐
-
다른 리전에 있는 S3에 백업하려면 Cross-regional snapshot copy를 설정해야 함
- 재난 시 데이터 복구에 유용
- 재난 시 데이터 복구에 유용
-
-
메뉴얼 백업
-
언제든 원할 때 생성하는 백업으로, 명시적으로 삭제할 때까지 유지
- 혹은 생성할 때 보존 기한 설정
- 혹은 생성할 때 보존 기한 설정
-
-
백업에서 테이블 복구
- Redshift 클러스터 -> Restore table -> 복구 대상의 스냅샷 선택 -> 원본 테이블(Source Table) 선택 -> 복구될 타겟 테이블 선택
- Redshift 클러스터 -> Restore table -> 복구 대상의 스냅샷 선택 -> 원본 테이블(Source Table) 선택 -> 복구될 타겟 테이블 선택
-
Redshift Serverless가 지원하는 백업 방식
-
고정비용 Redshift 클러스터에 비하면 제한적이고 조금 더 복잡함
-
스냅샷 이전에 복구 시점(Recovery Points)라는 개념이 존재
-
복구 시점을 스냅샷으로 바꾼 뒤 테이블을 복구하거나 새로운 Redshift 클러스터 등을 생성 가능
-
복구 시점은 최대 24시간 전까지의 내용만 유지
-
-
default 네임스페이스 -> 데이터 백업 -> 복구 시점으로 스냅샷 생성
- 혹은 "스냅샷 생성" 버튼을 사용해 현재 시점의 스토리지로 스냅샷 생성 가능
-
3. Redshift 관련 기타 서비스 소개
-
Redshift Spectrum
-
Redshift의 확장 기능으로, 별도의 설정은 할 필요 없이 사용량에 따라 추가 비용 발생
-
S3에 있는 파일을 마치 테이블처럼 SQL로 처리 가능
-
S3의 파일을 외부 테이블로 처리하며 Redshift의 테이블과 조인 가능
- S3 외부 테이블은 보통 Fact 테이블이 되고, Redshift의 테이블은 Dimension 테이블이 됨
- S3 외부 테이블은 보통 Fact 테이블이 되고, Redshift의 테이블은 Dimension 테이블이 됨
-
-
사용하기 위해 S3와 같은 리전의 Redshift 클러스터가 필요
-
-
Athena
-
Apache Presto를 서비스화한 것으로 Redshift Spectrum과 비슷한 기능 제공
-
S3의 데이터를 기반으로 SQL 쿼리 기능 제공
- 이 경우, S3를 데이터 레이크로 볼 수 있음
- 이 경우, S3를 데이터 레이크로 볼 수 있음
-
-
Redshift ML
-
SQL만 사용해 머신러닝 모델을 훈련하고 사용할 수 있게 해주는 Redshift 기능
-
AWS SageMaker에 의해 지원
- SageMaker는 Auto Pilot이라고 하는 최적화된 모델 자동 생성 기능 제공
- SageMaker는 Auto Pilot이라고 하는 최적화된 모델 자동 생성 기능 제공
-
이미 만들어진 모델도 사용 가능
-
4. Redshift Spectrum으로 S3 외부 테이블 조작해보기
-
Fact 테이블과 Dimension 테이블
-
Fact 테이블: 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블
-
일반적으로 매출 수익, 판매량 혹은 이익과 같은 사실 혹은 측정 항목을 포함하며 비즈니스 결정에 사용
-
일반적으로 외래키를 통해 여러 Dimension 테이블과 연결됨
-
보통 Fact 테이블의 크기가 훨씬 큼
-
-
Dimension 테이블: Fact 테이블에 대한 상세 정보를 제공하는 테이블
-
Fact 테이블의 데이터에 맥락을 제공해 사용자가 다양한 방식으로 데이터를 조각내고 분석 가능하게 해줌
-
Dimension 테이블은 일반적으로 primary key를 가지며, Fact 테이블의 외래키로 사용됨
-
-
Redshift 사용 유스 케이스
-
S3에 대용량 Fact 테이블이 파일(들)로 존재
-
Redshift에 소규모 Dimension 테이블이 존재
-
Fact 테이블은 Redshift에 적재하기 않고 Dimension 테이블과 조인하기 위해 Redshift Spectrum 사용
-
-
외부 테이블(External Table)
-
DB 엔진이 외부에 저장된 데이터를 마치 내부 테이블처럼 사용하는 방법
- S3와 같은 클라우드 스토리지의 대용량 데이터를 복사해 임시 목적, 읽기 전용으로 사용
- S3와 같은 클라우드 스토리지의 대용량 데이터를 복사해 임시 목적, 읽기 전용으로 사용
-
SQL 명령어로 DB에 외부 테이블 생성 가능
- 이 경우 데이터를 새로 생성하는 것이 아니고, 참조만 하면 됨
- 외부 테이블은 CSV, JSON, XML과 같은 파일 형식뿐만 아니라 ODBC 혹은 JDBC 드라이버를 통해 액세스하는 원격 DB와 같은 다양한 데이터 소스에 대해 사용 가능
- 이 경우 데이터를 새로 생성하는 것이 아니고, 참조만 하면 됨
-
외부 테이블을 사용해 데이터 처리 후 결과를 DB에 적재 가능
- 예를 들어, 외부 테이블을 사용해 로그 파일을 읽고 정재해 DB 테이블에 적재 가능
- 예를 들어, 외부 테이블을 사용해 로그 파일을 읽고 정재해 DB 테이블에 적재 가능
-
외부 테이블은 보안 및 성능 문제에 대해 신중한 고려 필요
-
Hive 등에서 처음 등장한 개념으로 대부분의 빅데이터 시스템에서 사용됨
-
-
-
Redshift Spectrum 사용 방식
-
S3와 같은 리전의 Redshift 클러스터 필요
-
S3 Fact 데이터를 외부 테이블로 정의
- 외부 테이블용 스키마, DB 생성
CREATE EXTERNAL SCHEMA external_schema FROM data catalog DATABASE 'myspectrum_db' iam_role 'arn:aws:iam::XXXXXX:role/redshift.read.s3' CREATE EXTERNAL DATABASE IF NOT EXISTS;
- 외부 테이블용 스키마, DB 생성
-
이전에 IAM에서 생성했던 "redshift.read.s3" Role에 AWSGlueConsoleFullAccess 권한 추가
-
AWS Glue: Airflow와 비슷한 개념으로, AWS의 Serverless ETL 서비스
-
데이터 카탈로그
-
ETL 생성 작업
-
작업 모니터링 및 로그
-
서버리스 실행
-
-
-
S3 버킷에 usc라는 폴더 생성
-
usc 폴더에 user_session_channel.csv 파일 복사
-
외부 테이블 생성
CREATE EXTERNAL TABLE external_schema.user_session_channel ( userId INTEGER, sessionId VARCHAR(32). channel VARCHAR(32) ) row format delimited fileds terminated by ',' stored as textfile location 's3://wonjin-test-bucket/usc/';
-
내부 Dimension 테이블 생성
CREATE TABLE raw_data.user_property AS SELECT userId, CASE WHEN CAST(random() * 2 AS INT) = 0 THEN 'male' ELSE 'female' END AS gender, (CAST(random() * 50 AS INT) + 18) AS age FROM ( SELECT DISTINCT userId FROM raw_data.user_session_channel );
-
Fact + Dimension 테이블 조인
SELECT gender, COUNT(*) FROM external_schema.user_session_channel usc JOIN raw_data.user_property up ON usc.userId = up.userId GROUP BY 1;
-
5. Redshift ML 사용하기
-
머신러닝
-
배움이 가능한 기계 혹은 알고리즘을 개발하는 것
-
데이터의 패턴을 보고 흉내(imitation)내는 방식으로 학습
-
학습에 사용되는 데이터를 트레이닝 셋이라고 부름
-
-
인공지능 > 머신러닝 > 딥러닝
-
-
머신러닝 모델
-
학습된 패턴에 따라 예측을 해주는 블랙박스
-
선택한 머신러닝 알고리즘에 따라 내부가 달라짐
-
동작 방식 설명과 디버깅이 어려움
-
트레이닝 셋의 품질이 머신러닝 모델의 품질을 결정
-
-
지도(Supervised) 머신러닝: 입력 데이터를 기반으로 예측
- 이외에도 비지도(Unsupervised) 머신러닝, 강화학습(Reinforcement Learning)이 존재
- 이외에도 비지도(Unsupervised) 머신러닝, 강화학습(Reinforcement Learning)이 존재
-
-
Amazon SageMaker
-
머신러닝 모델 개발을 처음부터 끝까지 해결해주는 AWS 서비스(MLOps 프레임워크)
-
기능
-
트레이닝 셋 준비
-
모델 훈련
-
모델 검증
-
모델 배포와 관리
-
-
다양한 머신러닝 프레임워크 지원
-
Tensorflow/Keras, PyTorch, MXNet, ...
-
자체 모듈로도 훈련 가능
-
-
다양한 개발 방식 지원
-
SageMaker Studio: 웹 기반 환경
-
Python Notebook
-
AutoPilot: 코딩 없이 모델 훈련 기능 제공
-
-
AutoPilot
-
SageMaker에서 제공하는 AUTOML 기능
-
훈련용 데이터 셋을 입력하면 자동으로 데이터 분석, 머신러닝 알고리즘 및 하이퍼 파라미터 조합, 테스트 수행
-
사용자가 모델 선택 후 API로 만드는 것도 가능
-
-
SQL에서 ML 모델을 빌드하고 사용하는 유스 케이스 증가
-
비개발자가 간단하게 모델을 만들고 사용 가능
-
6. Redshift 중지/제거하기
-
Redshift 서비스는 버전 업그레이드를 위해 주기적으로 중단됨
- 이를 Maintenance window라고 부르며, Serverless 서비스에는 존재하지 않음
- 이를 Maintenance window라고 부르며, Serverless 서비스에는 존재하지 않음
-
VACUUM: 테이블 청소와 최적화
-
테이블 데이터 정렬
-
디스크 공간 해제
-
삭제된 행에서 공간 회수
-
테이블 통계 업데이트
-
큰 테이블에 대한 VACUUM 명령은 리소스를 많이 잡아먹기 때문에 바쁘지 않을 때 진행
-
-
Redshift 클러스터 중지/재실행
-
당분간 필요 없을 경우
-
Redsfhit 클러스터 -> 메뉴에서 Stop 선택
-
이 경우, Redshift 클러스터의 스토리지 비용만 부담하고, SQL 실행 불가능
-
다시 필요한 경우, 메뉴에서 Resume 선택
-
-
영원히 필요 없을 경우
-
Redshift 클러스터 -> 메뉴에서 Delete 선택
-
이 때, DB 내용 백업을 S3로도 선택 가능
- 해당 S3 백업을 기반으로 Redshift 클러스터 새롭게 생성 가능
- 해당 S3 백업을 기반으로 Redshift 클러스터 새롭게 생성 가능
-
-
-
Redshift Serverless 삭제
- 모든 작업 그룹 삭제
- 모든 네임스페이스 삭제
