
학습내용
-
Snowflake 특징 소개
-
Snowflake 무료 시험판 시작
-
Snowflake 초기 설정
-
Snowflake 사용자 권한 설정
-
Snowflake 기타 기능과 사용 중단
1. Snowflake 특징 소개
-
Snowflake
-
클라우드 기반 데이터 웨어하우스로 시작해 데이터 클라우드라고 부를 수 있을 정도로 발전
-
글로벌 클라우드(AWS, GCP, Azure) 위에서 모두 동작 -> 멀티클라우드
-
데이터 판매를 통해 매출을 가능하게 해주는 Data Sharing, Marketplace 서비스 제공
-
ETL과 다양한 데이터 통합 기능
-
-
특징
-
스토리지와 컴퓨팅 인프라가 별도로 설정되는 가변비용 모델
- Redshift 고정비용 옵션처럼 노드 수를 조정할 필요가 없고, distkey 등의 최적화 불필요
- Redshift 고정비용 옵션처럼 노드 수를 조정할 필요가 없고, distkey 등의 최적화 불필요
-
SQL 기반으로 빅데이터 저장, 처리, 분석 가능
- 비구조화된 데이터 처리와 머신러닝 기능도 제공
- 비구조화된 데이터 처리와 머신러닝 기능도 제공
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- S3, GCP 클라우드 스토리지, Azure Blob Storage도 지원
- S3, GCP 클라우드 스토리지, Azure Blob Storage도 지원
-
배치 데이터 중심이지만 실시간 데이터 처리도 지원
-
과거 데이터 쿼리 기능인 Time Travel을 지원해 트렌드를 쉽게 분석 가능
-
웹 콘솔 외에도 Python API, ODBC/JDBC 연결 지원
-
다른 지역에 있는 데이터 공유(Cross-Region Replication) 기능 지원
-
Redshift보다 더 강력한 기본 데이터 타입 지원
-
-
구조
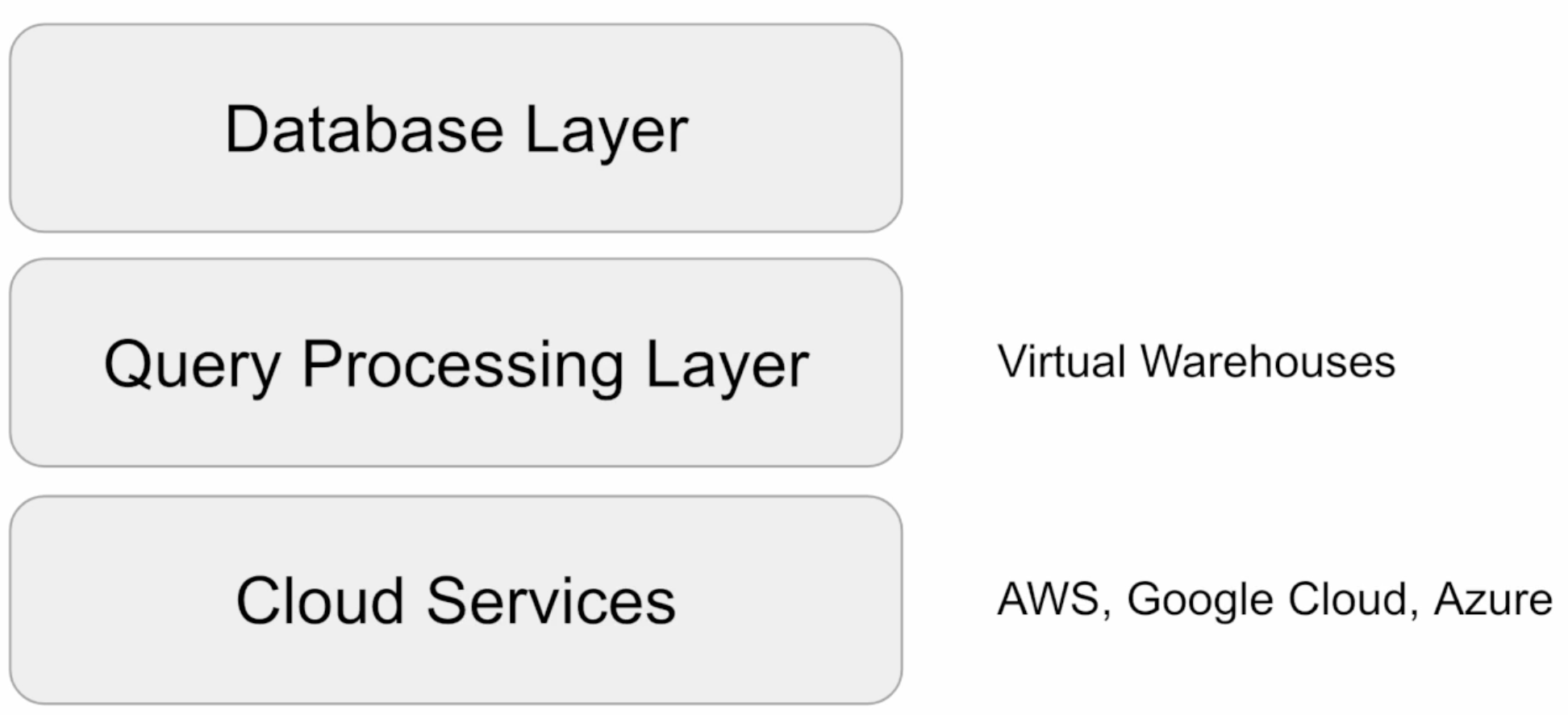
-
계정 구성
-
기업의 크기에 따라 계정을 다르게 구성
-
Organizations (대규모) -> 1 + Accounts (중규모) -> 1 + Databases (소규모)
-
Organizations: 한 고객이 사용하는 모든 Snowflake 자원들을 통합하는 최상위 레벨 컨테이너
- 하나 이상의 Account들로 구성되며, 이 모든 Account에 대한 접근 권한, 사용 트래킹, 비용을 관리하는 데 사용
- 하나 이상의 Account들로 구성되며, 이 모든 Account에 대한 접근 권한, 사용 트래킹, 비용을 관리하는 데 사용
-
Accounts: 하나의 Account는 자체 사용자, 데이터, 접근 권한을 가짐
- 하나 이상의 Database로 구성
- 하나 이상의 Database로 구성
-
Databases: Account에 속한 데이터를 다루는 논리적인 컨테이너
-
다수의 스키마와, 스키마에 속한 테이블, 뷰 등으로 구성
-
PB 단위까지 스케일 가능하고, 독립적인 컴퓨팅 리소스인 Warehouses를 가짐
-
-
2. Snowflake 무료 시험판 시작
-
최대 30일 혹은 $400까지 사용 가능
-
사용할 Cloud Provider(AWS, GCP, Azure) 선택
-
사용자 그룹은 없고 역할만 존재
-
Worksheet은 일종의 노트북에 해당하고, 다른 사용자와 공유 가능
-
로그인 전용 URL을 기억해야 함
-
기본적으로 SNOWFLAKE, SNOWFLAKE_SAMPLE_DATA라는 2개의 DB가 존재
-
Warehouse의 크레딧
-
쿼리 실행과 데이터 로드, 기타 작업 수행에 소비되는 리소스를 측정하는 단위
-
경우에 따라 다르지만, 대략 $2 ~ $4의 비용 발생
-
-
비용 구조
-
컴퓨팅 비용: 크레딧으로 계산
-
스토리지 비용: TB 단위 계산
-
네트워크 비용: 지역 간 데이터 전송 혹은 다른 클라우드 간 데이터 전송 시 TB 단위 계산
-
3. Snowflake 초기 설정
-
새로운 SQL Worksheet 생성
-
DB, 스키마 생성
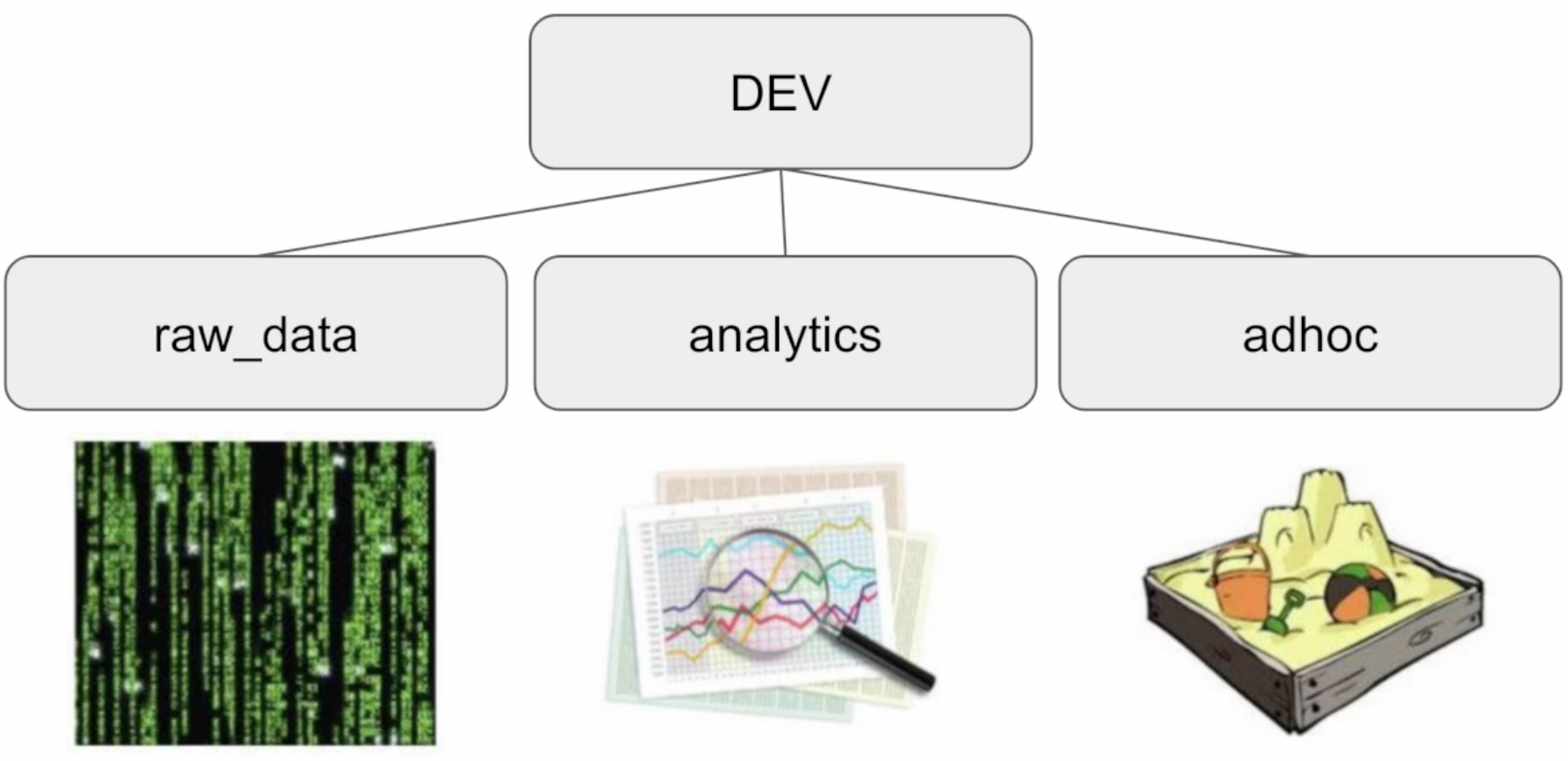
CREATE DATABASE dev; CREATE SCHEMA dev.raw_data; CREATE SCHEMA dev.analytics; CREATE SCHEMA dev.adhoc;
-
raw_data 밑에 3개의 테이블 생성
CREATE OR REPLACE TABLE dev.raw_data.session_transaction ( sessionId VARCHAR(32) PRIMARY KEY, refunded BOOLEAN, amount INT ); CREATE OR REPLACE TABLE dev.raw_data.user_session_channel ( sessionId VARCHAR(32) PRIMARY KEY, userId INTEGER, channel VARCHAR(32) ); -- s3://wonjin-test-bucker/test-data/user_session_channel.csv 파일 COPY CREATE OR REPLACE TABLE dev.raw_data.session_timestamp ( sessionId VARCHAR(32) PRIMARY KEY, ts TIMESTAMP );
-
COPY 사용해 벌크 업데이트 수행
COPY INTO dev.raw_data.session_transaction FROM 's3://wonjin-test-bucket/test-data/session_transaction.csv' credentials = (AWS_KEY_ID='...' AWS_SECRET_KEY='...') FILE_FORMAT = (type='CSV' skip_header=1 Field_OPTIONALLY_ENCLOSED_BY="") COPY INTO dev.raw_data.user_session_channel FROM 's3://wonjin-test-bucket/test-data/user_session_channel.csv' credentials = (AWS_KEY_ID='...' AWS_SECRET_KEY='...') FILE_FORMAT = (type='CSV' skip_header=1 Field_OPTIONALLY_ENCLOSED_BY="") COPY INTO dev.raw_data.session_timestamp FROM 's3://wonjin-test-bucket/test-data/session_timestamp.csv' credentials = (AWS_KEY_ID='...' AWS_SECRET_KEY='...') FILE_FORMAT = (type='CSV' skip_header=1 Field_OPTIONALLY_ENCLOSED_BY="")-
AWS 어드민 사용자의 AWS KEY ID, AWS SECRET KEY 사용 X
-
Snowflake의 S3 버킷 액세스를 위한 전용 사용자를 IAM으로 만들고 S3 읽기 권한 부여
-
해당 사용자의 AWS KEY ID, AWS SECRET KEY 사용
-
-
-
Snowflake로 S3 버킷 접근 위한 IAM 사용자 생성
-
IAM -> 사용자 -> 사용자 추가
-
"직접 정책 연결" 선택 -> AmazonS3ReadOnlyAccess 정책 추가
-
-
액세스 키 생성
- 사용자 -> 보안 자격정보 -> 액세스 키 생성
- 사용자 -> 보안 자격정보 -> 액세스 키 생성
-
analytics 스키마 밑에 테이블을 CTAS로 생성
CREATE TABLE dev.analytics.mau_summary AS SELECT TO_CHAR(A.tx, 'YYYY-MM') AS month, COUNT(DISTINCT B.userId) AS mau FROM raw_data.session_timestamp A JOIN raw_data.user_session_channel B ON A.sessionId = B.sessionId GROUP BY month ORDER BY month DESC;
4. Snowflake 사용자 권한 설정
-
ROLE, USER 생성
CREATE ROLE analytics_users; CREATE ROLE analytics_authors; CREATE ROLE pii_users; CREATE USER username PASSWORD='xxx'; GRANT ROLE analytics_users TO USER username;
-
Role 설정
GRANT USAGE ON SCHEMA dev.raw_data TO ROLE analytics_users; GRANT SELECT ON ALL TABLES IN SCHEMA dev.raw_data TO ROLE analytics_users; GRANT USAGE ON SCHEMA dev.analytics TO ROLE analytics_users; GRANT SELECT ON ALL TABLES IN SCHEMA dev.analytics TO ROLE analytics_users; GRANT ALL ON SCHEMA dev.adhoc TO ROLE analytics_users; GRANT ALL ON ALL TABLES IN SCHEMA dev.adhoc TO ROLE analytics_users; GRANT ROLE analytics_users TO ROLE analytics_authors; GRANT ALL ON SCHEMA dev.analytics TO ROLE analytics_authors; GRANT ALL ON ALL TABLES IN SCHEMA dev.analytics TO ROLE analytics_authors; -
Redshift와 마찬가지로 컬럼 레벨 보안, 레코드 레벨 보안이 있음
- 민감한 정보를 별도의 테이블로 관리하거나, 데이터 시스템에 적재하지 않는 것을 권장
- 민감한 정보를 별도의 테이블로 관리하거나, 데이터 시스템에 적재하지 않는 것을 권장
-
Data Governance
-
필요한 데이터가 적재적소에 올바르게 사용되는 것을 보장하기 위한 데이터 관리 프로세스
-
기본 목적
-
데이터 기반 결정의 일관성
-
데이터를 이용한 가치 창출
-
데이터 관련 법규 준수
-
-
관련 기능(Enterprise Level)
-
Object Tagging
-
CREATE TAG 명령어로 생성
-
Tag는 구조적으로 계승
-
개인 정보 관리가 중요 용도 중 하나
-
-
Data Classification
-
Analyze, Review, Apply 3가지 단계로 구성
-
Analyze: 테이블에 적용 시 민감한 정보 분류
-
Review: 데이터 엔지니어가 확인 후 최종 리뷰
-
Apply: 결과를 System Tag로 적용
-
-
-
Tag Based Masking Policies
- Tag에 액세스 권한 지정
- Tag에 액세스 권한 지정
-
Access History
- 데이터 액세스에 대한 감사 추적을 제공해 보안과 규정 준수
- 데이터 액세스에 대한 감사 추적을 제공해 보안과 규정 준수
-
Object Dependencies
-
Data Governance와 시스템 무결성 유지가 목적
-
테이블이나 뷰를 수정하는 경우, 이로 인한 영향을 자동으로 식별
-
계승 관계를 분석해 더 세밀한 보안 및 액세스 제어
-
-
-
5. Snowflake 기타 기능과 사용 중단
-
기타 기능
- Marketplace, Data Sharing, Query / Copy / Task History
- Marketplace, Data Sharing, Query / Copy / Task History
-
무료 시험 기간이 끝나면 계정이 자동으로 "Suspended" 모드로 변경
- 신용 카드 정보를 입력하지 않으면 과금 발생 X
메모
- 드롭박스에서 DB를 선택하면
dev.처럼 이름을 명시하지 않아도 됨
