
학습내용
-
다양한 시각화 툴 소개
-
Superset 소개
-
제작할 대시보드 설명
-
Superset 설치 방법
-
Docker를 사용해 Superset 설치
-
Redshift 설정하고 MAU 차트 만들기
-
Cohort 차트 만들고 대시보드 구성하기
1. 다양한 시각화 툴 소개
-
시각화 툴
-
대시보드 혹은 BI(Business Intelligence) 툴이라고 부르기도 함
-
KPI, 지표 등 중요한 데이터 포인트들을 데이터를 기반으로 계산 / 분석 / 표시해주는 툴
-
결정권자의 데이터 기반 의사결정을 도움
-
데이터의 품질이 중요하기 때문에 ETL을 주로 활용
-
-
시각화 툴 종류
-
Excel, Google Spreadsheet: 일반적인 용도로 가장 많이 사용됨
-
Python: 데이터 특성 분석(EDA: Exploratory Data Analysis)에 더 적합
-
Looker(Google)
-
LookML이 자체 언어로, 데이터 모델을 만드는 것으로 시작
-
내부 고객뿐만 아니라 외부 고객을 위한 대시보드 작성 가능
-
이미 만들어진 대시보드를 활용해 대시보드 작성 가능
-
고가의 라이센스 정책을 갖고 있으나, 굉장히 다양한 기능 제공
-
-
Tableau(Salesforce)
-
다양한 제품군 보유, 일부 무료
-
제대로 배우려면 시간이 꽤 필요하지만, 강력한 대시보드 작성 기능
-
Looker가 뜨기 전까지 오랜 기간동안 마켓 리더
-
-
Power BI(Microsoft)
-
Apache Superset(오픈소스)
-
Mode Analytics
-
SQL, R, Python 등을 기반으로 데이터 분석 가능
-
조금 더 기술적인 인력을 대상으로 함
-
KPI보다는 EDA 툴에 더 가까움
-
-
-
ReDash
-
Superset과 상당히 흡사
- 쿼리 에디터는 더 강력하지만, 사용자 권한 관련 기능은 부족
- 쿼리 에디터는 더 강력하지만, 사용자 권한 관련 기능은 부족
-
-
Google Studio
-
AWS Quicksight
-
-
시각화 툴 선택 가이드
-
Looker 혹은 Tableau를 가장 많이 사용하는 추세
-
둘 모두 처음 배우는 데 시간이 필요
-
Tableau가 가격이 더 싸고, 투명하며, 무료 버전을 활용해 학습 가능
-
-
셀프 서비스 대시보드 작성이 중요 포인트
-
그렇지 않을 경우, 매번 노동력이 소모됨
-
사용하기 쉬워야 더 많은 현업 인력들이 직접 대시보드를 만들 수 있음
-
데이터 민주화, 데이터 탈중앙화
-
데이터 품질이 중요해지고, 데이터 거버넌스의 필요성 증가
-
-
이러한 측면에서는 Looker가 더 좋은 선택지지만, 가격이 상당히 비쌈
-
-
2. Superset 소개
-
Superset
-
Airflow 제작자가 시작한 오픈소스 서비스
-
다양한 형태의 시각화와 손쉬운 인터페이스 제공
-
대시보드 공유 기능
-
엔터프라이즈 수준의 보안과 권한 제어 기능 제공
-
SQLAlchemy와 연동되어 다양한 DB 연결 지원
-
Druid.io와 연동되어 실시간 데이터 시각화도 가능
-
API와 플러그인 아키텍처를 제공해 확장성이 좋음
-
-
구조와 용어
-
Flask와 React.js로 구성
-
기본적으로 sqlite를 메타데이터 DB로 사용
-
Redis를 캐싱 레이어로 사용
-
SQLAlchemy가 백엔드 DB 접근에 사용됨
-
Database, Dataset
-
Database: 관계형 데이터베이스
-
Dataset: 테이블
-
-
Dashboard, Chart
- Dashboard는 하나 이상의 Chart로 구성
-
3. 제작할 대시보드 설명
-
2개의 차트, 1개의 대시보드 제작
-
Redshift를 DB로 사용
-
채널 별 MAU(Monthly Active User) 차트
-
입력 테이블(Dataset)은 analytics.user_session_summary

-
-
Monthly Cohort 차트
-
입력 테이블(Dataset)은 analytics.cohort_summary
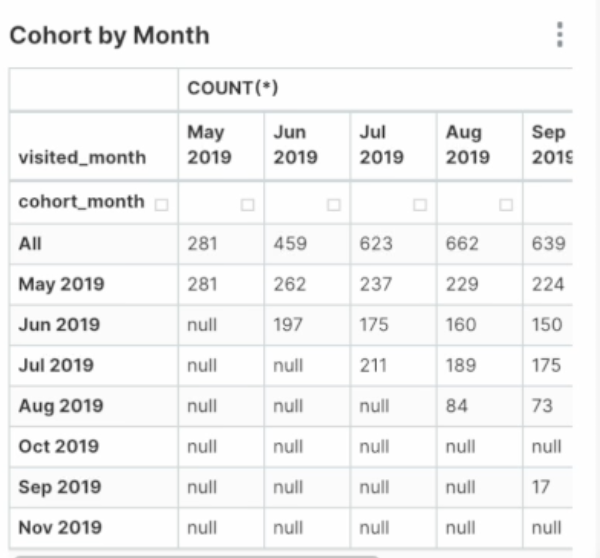
-
-
MAU 차트 입력: user_session_summary
CREATE TABLE analytics.user_session_summary AS SELECT usc.*, t.tx FROM raw_data.user_session_channel usc LEFT JOIN raw_data.session_timestamp t ON usc.sessionId = t.sessionId
-
코호트(Cohort) 분석
-
코호트: 특정 속성을 바탕으로 나누어진 사용자 그룹
- 일반적으로 사용자의 서비스 등록월 사용
- 일반적으로 사용자의 서비스 등록월 사용
-
코호트 분석: 코호트를 기반으로 사용자 이탈율, 잔존률, 총 소비금액 등 계산
-
코호트 기반 사용자 잔존율(Retention)을 월 기반으로 시각화
-
코호트 차트 입력: cohort_summary
CREATE TABLE analytics.cohort_summary AS SELECT cohort_month, visited_month, cohort.userId FROM ( SELECT userId, DATE_TRUNCATE('month', MIN(ts)) AS cohort_month FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp t ON usc.sessionId = t.sessionId GROUP BY userId ) cohort JOIN ( SELECT DISTINCT userId, DATE_TRUNCATE('month', ts) AS visited_month FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp t ON usc.sessionId = t.sessionId ) visit ON cohort.cohort_month <= visit.visited_month AND cohort.userId = visit.userId
-
-
4. Superset 설치 방법
-
Docker를 사용해 설치 vs Perset.io에서 서비스 설치
-
Docker에 익숙하고 개인 컴퓨터 사양이 충분하다면 Docker 사용
- 이 경우는 Superset 오픈소스를 그대로 사용
- 이 경우는 Superset 오픈소스를 그대로 사용
-
Preset.io는 무료 Starter 플랜이 있기는 하지만 회사 이메일이 있는 경우에만 사용 가능
- Superset 오픈소스를 기반으로 변경된 버전을 사용
- Superset 오픈소스를 기반으로 변경된 버전을 사용
-
-
Docker
-
특정 프로그램과 해당 프로그램을 실행하는 데 필요한 기타 소프트웨어를 하나의 패키지로 만듦으로써 해당 프로그램의 개발과 사용을 도와주는 오픈소스 플랫폼
-
이 패키지를 먼저 파일 형태로 만드는데, 이를 Docker Image라고 함
-
이 Image는 다른 사람들과 공유 가능
-
Docker Image 공유소를 Docker Registry(Docker Hub)라고 부름
-
-
Docker Image를 실행시킨 것을 Docker Container라고 부르며, 이 안에서 해당 프로그램이 실행됨
- Docker Engine이 먼저 실행되어야 함
- Docker Engine이 먼저 실행되어야 함
-
-
-
Redshift 테이블 정보
-
raw_data.user_session_channel
-
raw_data.session_timestamp
-
raw_data.session_transaction
-
analytics.user_session_summary
-
analytics.cohort_summary
-
5. Docker를 사용해 Superset 설치
-
운영체제에 맞는 Docker Engine 설치
-
Docker Engine 실행과 리소스 설정
- Docker 실행 -> 설정 -> Resources -> 메모리 6GB 이상 할당
- Docker 실행 -> 설정 -> Resources -> 메모리 6GB 이상 할당
-
Docker Superset 실행
a. 터미널 실행해 설치할 폴더로 이동
b. Superset Github Repo 클론
git clone https://github.com/apache/superset.git
c. superset 폴더로 이동
cd superset
d. 다음 2개의 명령 실행
-- 이미지 다운로드, 이미지 실행 docker-compose -f docker-compose-non-dev.yml pull docker-compose -f docker-compose-non-dev.yml up
e. https://localhost:8088 로 웹 UI 로그인
- USERNAME: admin / PASSWORD: admin 사용
