
학습 주제
-
인터넷 사용자 간의 약속, HTTP
-
웹페이지와 HTML
-
나의 첫 HTTP 통신 코드
-
윤리적으로 웹 스크래핑, 크롤링 진행하기
-
웹 브라우저가 HTML을 다루는 방법
1. 인터넷 사용자 간의 약속, HTTP
-
인터넷과 웹
-
인터넷: 범지구적으로 연결된 네트워크
-
웹: 인터넷 상에서 정보를 교환할 수 있는 시스템
-
-
웹에서 정보 주고받기
- 정보를 요청(Request)하는 컴퓨터를 클라이언트, 정보를 처리 후 응답(Response)하는 컴퓨터를 서버라고 부름
- 정보를 요청(Request)하는 컴퓨터를 클라이언트, 정보를 처리 후 응답(Response)하는 컴퓨터를 서버라고 부름
-
HTTP(HyperText Transfer Protocol)
-
웹 상에서 정보를 주고받기 위한 약속
-
HTTP 요청/응답은 정보를 담는 Head와 내용물인 Body로 구분
-
2. 웹페이지와 HTML
-
웹사이트와 웹페이지
-
웹페이지: 웹 속에 있는 문서 한 개
-
웹사이트: 웹페이지의 모음
-
-
웹페이지는 어떻게 만들까요?
- 웹 브라우저: HTML에 대한 HTTP 요청을 보내고, HTTP 응답에 담긴 HTML 문서를 우리가 보기 쉬운 형태로 화면을 그려주는(Rendering) 역할
- 웹 브라우저: HTML에 대한 HTTP 요청을 보내고, HTTP 응답에 담긴 HTML 문서를 우리가 보기 쉬운 형태로 화면을 그려주는(Rendering) 역할
-
HTML의 구조
-
Hypertext: 다른 웹페이지로 연결하는 링크
-
여러 태그로 감싼 요소(Element)들의 집합
-
웹 브라우저마다 지원하는 태그와 속성이 다름
-
3. 나의 첫 HTTP 통신 코드
-
requests 라이브러리
- Python에서 간단히 HTTP 통신을 진행할 수 있는 라이브러리
- Python에서 간단히 HTTP 통신을 진행할 수 있는 라이브러리
-
GET: 정보 요청하기
# requests 라이브러리를 사용해 NAVER의 홈페이지를 요청한 뒤 응답 받아보기 import requests res = requests.get("https://www.naver.com") # Header 확인 print(res.headers) # Body 확인 print(res.text[:1000])
-
POST: 정보 갱신을 요청하기
import requests # JSON 형식의 payload를 사용해 POST 요청 전송 payload = {"name": "Lee", "age": 25} res = requests.post("https://webhook.site/XXX", payload) # 상태 코드 확인 print(res.status_code)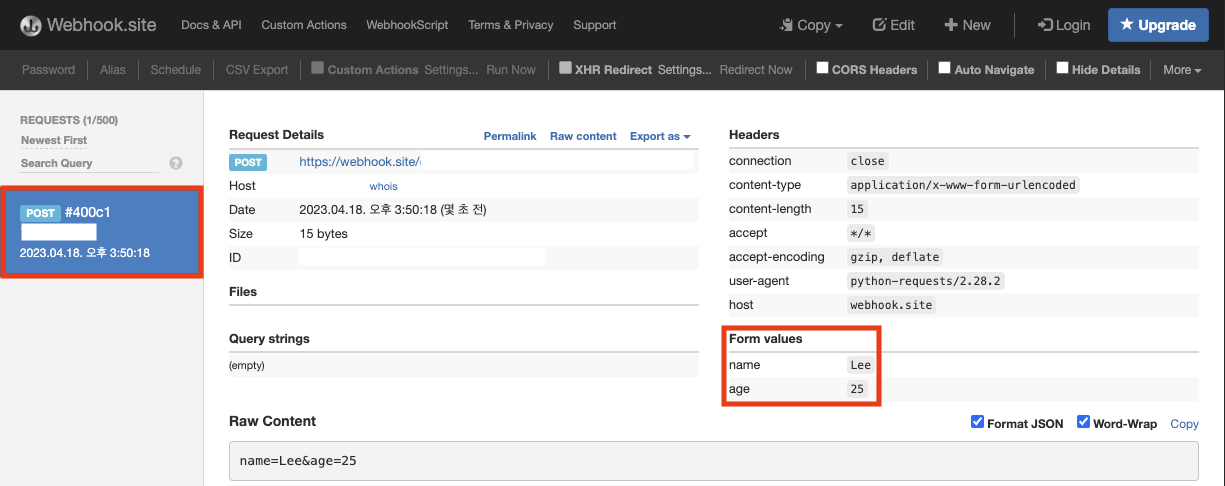
4. 윤리적으로 웹 스크래핑, 크롤링 진행하기
-
웹 크롤링과 웹 스크래핑
-
웹 스크래핑: 웹페이지들로부터 원하는 정보를 추출
-
웹 크롤링: 크롤러(Crawler)를 사용해 반복적으로 웹페이지의 정보를 인덱싱(색인)
-
-
올바르게 HTTP 요청하기
-
고려할 점
-
웹 스크래핑/크롤링을 통해 달성하고자 하는 목적
-
나의 웹 스크래핑/크롤링이 서버에 미치는 영향
-
-
로봇 배제 프로토콜(REP: Robot Exclusion Protocol, robots.txt)
-
로봇이 무단으로 웹사이트의 정보를 긁어가거나 서버에 부하를 주는 것을 방지하기 위한 규칙
-
웹 크롤러들은 해당 규칙을 준수하며 크롤링 진행
1. 서버에 과도한 부하 금지
2. 가져온 정보 사용 시 저작권과 데이터베이스권에 위배되지 않는지 주의
-
웹 브라우저에게 우리가 스팸 봇이 아닌 사람이라는 것을 알리기 위해 전달하는 것이 사용자 에이전트(User Agent) 정보
- 나의 사용자 에이전트 확인: https://www.whatismybrowser.com/detect/what-is-my-user-agent/
- 나의 사용자 에이전트 확인: https://www.whatismybrowser.com/detect/what-is-my-user-agent/
-
robots.txt 가져오기
-
접근하고자 하는 웹페이지의 메인 주소에 '/robots.txt'를 붙이면 확인 가능
import requests res = requests.get("https://www.naver.com/robots.txt") print(res.text)
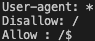
-
User-agent: 규칙이 적용되는 대상 사용자 에이전트
-
Disallow: 크롤링을 금지할 웹페이지
-
Allow: 크롤링을 허용할 웹페이지
-
-
-
5. 웹 브라우저가 HTML을 다루는 방법
-
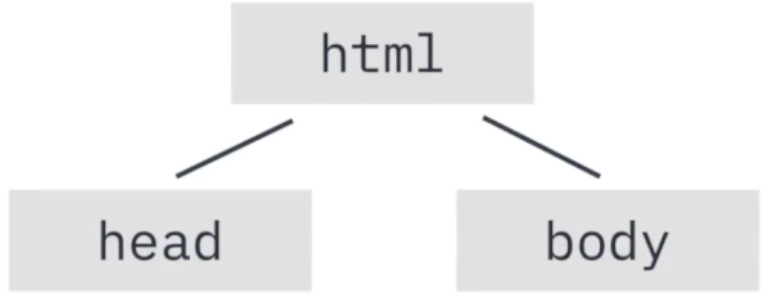
브라우저의 렌더링 엔진은 웹 문서를 로드한 후, 파싱을 진행
-
파싱 결과 만들어진 위와 같은 계층적인 모델이 DOM(Document Object Model)
-
각 노드(
<html>,<head>,<body>)를 객체로 생각하면 문서 관리 용이 -
DOM Tree를 순회해서 특정 원소를 쉽게 추가/탐색 가능
-
-
파이썬으로 HTML을 분석하는 HTML Parser를 제작해야 함
메모
-
pip install말고pip3 install사용하기 -
AttributeError: partially initialized module 'requests' has no attribute 'get’
- 파일명과 모듈명이 같아서 발생한 에러
-> 파일명 변경해서 해결
- 파일명과 모듈명이 같아서 발생한 에러
