
Transformer
"Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델입니다.
기존 seq2seq 모델의 한계
seq2seq모델은 인코더 - 디코더 구조로 구성되어 있었습니다. 여기서 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈습니다. 하지만 이러한 구조는 인코더가 입력시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 어텐션을 사용되었습니다.
트랜스포머 구조
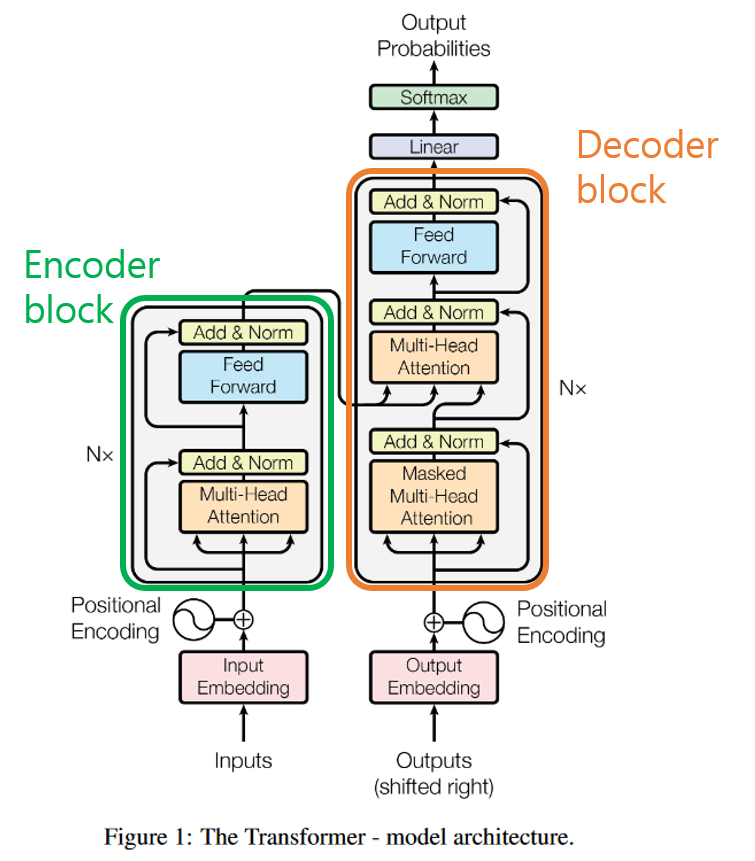
인코더 블록과 디코더 블록의 구조는 각각 입력된 문장내 단어간의 관계를 보여주는 self-attention layer와 모든 단어들에 동일하게 적용되는 fully connected feed-foward layer로 구성되어 있으며, 디코더 블록에는 이에 더해 encoder-decorder attention layer가 두 layer 사이에 들어가 있다.
1) Input - Word2Vec
각 블록별 내부 구조를 하나하나 뜯어보기 전에, 잠시 입력에 대해 짚고 넘어가겠다. 우리가 transformer에 어떤 문장을 입력할 때, 가장 먼저 거치는 과정은 그 문장을 모델이 연산할 수 있는 숫자형태로 바꿔주는 것이다. 다시말해 각 문장을 의미를 갖는 최소 단위인 단어들로 쪼갠 다음, Word2Vec이라는 알고리즘을 통해 각 단어를 vector형태로 변환한다. 우리가 image classification이나 detection 등을 할 때 이미지에서 feature를 추출하듯, 이 과정을 통해 단어는 그 의미를 보존한채 low-dimensional vector로 변한다. 이러한 일련의 과정을 word embedding이라고 하며
2) Encoder Block
트랜스포머는 하이퍼파라미터인 num_layers개수의 인코더 층을 쌓는다. 인코더를 하나의 층이라는 개념으로 생각하면 하나의 인코더 층은 크게 두개의 서브층으로 나뉘고, 이것이 셀프어텐션과 피드 포워드 신경망이다.
1. Self-Attention
문장은 word embedding을 거쳐 크기가 512인 vector들의 list{X1,X2,...Xn}로 바뀐채 먼저 첫번째 인코더 블록의 attention layer로 입력된다. 그리고 (우리가 학습시켜야할) Weight W를 만나 벡터곱을 통해 Query, Key, Value라는 3가지 종류의 새로운 벡터를 만들어낸다. 각 단어의 3가지 vector에 대해 다른 모든 단어들의 key vector와 특정한 연산을 하여 attention layer의 출력을 만들어낸다. 아래에서 그 과정을 좀더 들여다볼 예정인데, 만약 복잡한 연산과정을 알고 싶지 않다면 self-attention layer는 각 단어의 vector들끼리 서로간의 관계가 얼마나 중요한지 점수화한다 는 개념만 알고 넘어가도 좋다.

Self-Attention Layer에서 각 단어에 대한 Query, Key, Vector를 구하는 과정.
Query vector는 문장의 다른 단어들의 Key vector들과 곱한다. 이렇게 함으로써 각 단어가 서로에게 얼마나 중요한지 파악할 수 있다. 이때 주의할 점은 자기자신의 key vector와도(Self-Attention) 내적한다는 것이다. 이렇게 얻어진 각 값들은 계산의 편의를 위해 key vector 크기의 제곱근으로 나눠진 뒤, softmax를 적용해 합이 1이 되도록 한다. 거기에 각 단어의 value vector를 곱한 뒤 모두 더하면 우리가 원하는 self-attention layer의 출력이 나온다.
즉, 셀프 어텐션은 Q,K,V가 모두 동일하다.
셀프어텐션은, 앞에 문장에서 표현한 단어를 뒤에 문장에서 단순히 대명사인 This로 표현했다면, 이를 입력 문장내의 단어들끼리 유사도를 구해주기 때문에 연관성을 찾기 쉬워진다는 장점이 있다.
셀프어텐션은 각 단어 벡터들로부터 Q,K,V벡터를 얻는 작업을 거친다. 이때 Q, K, V 벡터들은 초기 입력인 d model의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가지게 되고, 이 작은 차원은 하이퍼파라미터인 num_heads로 인해 결정되는데, d model을 num_heads로 나눈 값을 각 Q,K,V의 차원으로 결정한다.
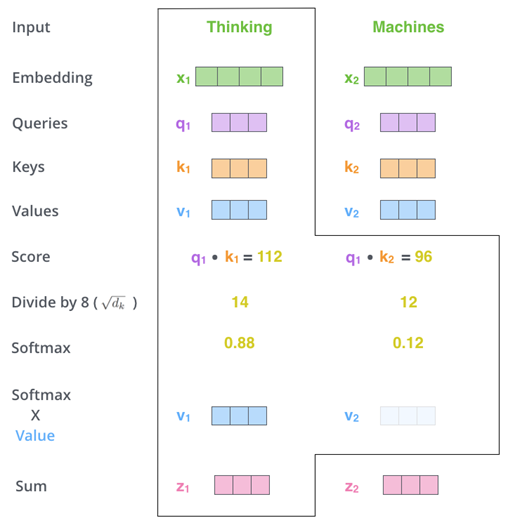
Self-Attention 연산 과정 개요.
이 출력은 입력된 단어의 의미뿐만 아니라, 문장내 다른 단어와의 관계 또한 포함하고 있다. 예를 들어 '나는 사과를 먹으려다가 그것이 썩은 부분이 있는 것을 보고 내려놓았다.' 라는 문장을 살펴보자. 우리는 직관적으로 '그것'이 '사과'임을 알 수 있지만, 여태까지의 NLP 알고리즘들은 문맥을 읽기 어렵거나 읽을 수 있다해도 단어와 단어사이의 거리가 짧을 때만 이해할 수 있었다. 그러나 attention은 각 단어들의 query와 key vector 연산을 통해 관계를 유추하기에 문장내 단어간 거리가 멀든 가깝든 문제가 되지 않는다.
논문에서는 이러한 self-attention 구조가 왜 훌륭한지에 대해서도 한 장을 활용하여 언급한다. 우선 연산 구조상 시간복잡도가 낮고 병렬화가 쉬워 컴퓨팅 자원소모에 대한 부담이 적다는 점이 있다. 또한 거리가 먼 단어간의 관계도 계산하기 쉽고 연산과정을 시각화하여 모델이 문장을 어떻게 해석하고 있는지 좀더 정확히 파악할 수 있다는 점에서도 유리하다고 한다.
2. Multi-Head Attention
모두가 알다시피 백지장도 맞들면 낫고, 회초리는 여러 개 묶을 경우 부러뜨리기 어렵다. 논문의 저자도 비슷한 생각을 하지 않았을까? Attention이 문맥의 의미를 잘 파악하는 알고리즘이긴 하지만, 단독으로 쓸 경우 자기자신의 의미에만 지나치게 집중할 수 있기에 논문의 저자는 8개의 attention layer를 두고 각각 다른 초기값으로 학습을 진행하였다. 각 layer에서 나온 출력은 그대로 합한 뒤 또다른 weight vecotr를 곱해 하나의 vector로 취합하며, 이것이 multi-head attention layer의 최종 출력이 된다.
각각의 single attention layer를 거쳐 나온 vector를 줄줄이 이어붙인 후, 또 하나의 weight에 곱해 하나의 vector로 취합한다.
이 방식의 장점은 8개의 서로 다른 representation subspace를 가짐으로써 single-head attention보다 문맥을 더 잘 이해할 수 있게 된다는 것이다. 위에서 예시를 들었던 '나는 사과를 먹으려다가 그것이 썩은 부분이 있는 것을 보고 내려놓았다.' 문장을 다시 보자. 그것과 사과는 같은 것을 가르키는 것이 맞지만, 또한 동시에 '썩은 부분'과도 관련이 있으며 '내려놓았다'와도 관련이 있다. single-head attention의 경우 이 중 하나의 단어와의 연관성만을 중시할 가능성이 높지만, multi-head attention은 layer를 여러 번 조금 다른 초기 조건으로 학습시킴으로써 '그것'에 관련된 단어에 대해 더 많은 후보군을 제공한다.
3. Position-Wise Feed-Foward Networks
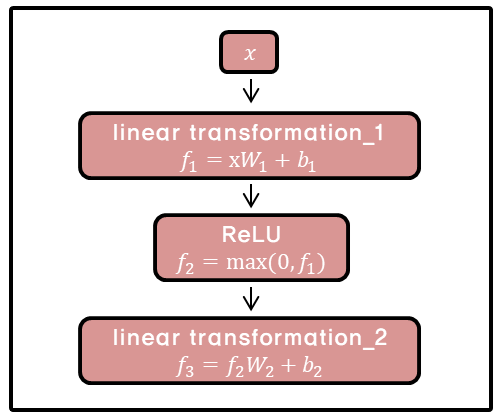
Feed-foward network 연산 과정.
attention layer를 통과한 값들은 fully connected feed-foward network를 지나가게 된다. 이때 하나의 인코더 블록 내에서는 다른 문장 혹은 다른 단어들마다 정확하게 동일하게 사용되지만, 인코더 마다는 다른 값을 가지게 된다. 이 과정의 필요성은 논문에서 특별히 언급하지는 않았지만 학습편의성을 위한 것으로 추정된다.
3) Positional Encoding
Positional vector는 단어가 embedding 된 후에 더해져서 인코더 블록의 최초 입력값을 만든다.
우리는 위에서 단어가 인코더 블록에 들어가기 전에 embedding vector로 변환됨을 보았다. 사실 여기에 한가지가 더 더해진채 인코더 블록에 입력되는데, 그것은 바로 positional encoding이다. 여태까지 과정을 잘 복기해보면 단어의 위치정보, 즉 단어들의 순서는 어떤지에 대한 정보가 연산과정 어디에도 포함되지 않았음을 알 수 있다. 문장의 뜻을 이해함에 있어 단어의 순서는 중요한 정보이므로 Transformer 모델은 이를 포함하고자 하였다.
Positional encoding vector를 하기 위한 함수는 여러 가지가 있지만 이 논문에서는 sin함수와 cos함수의 합으로 표현하였다. 그 이유는 함수의 특성상 특정 위치에 대한 positional vector는 다른 위치에 대한 positional vector의 합으로 표현할 수 있기 때문에 모델이 학습당시 보지 못한 길이의 긴 문장을 만나도 대응할 수 있게 되기 때문이다.
4) Decoder Block
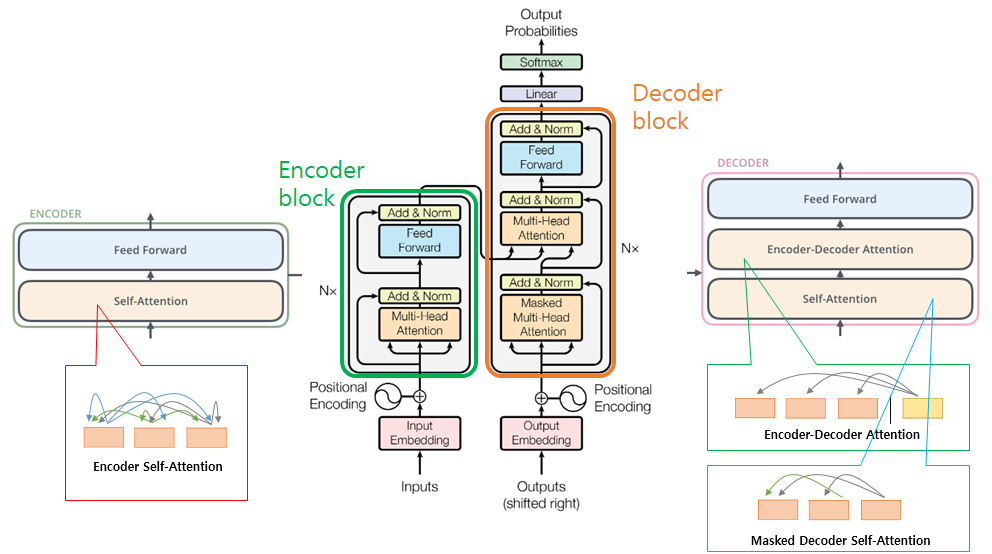
인코더 블록과 디코더 블록은 비슷하지만 약간 다른 구조를 가지고 있다.

Decoder 연산과정 개요.
먼저 self-attention시 현재 위치의 이전 위치에 대해서만 attention할 수 있도록 이후 위치에 대해서는 -∞로 마스킹을 했다. 또한 이렇게 통과된 vector중 query만 가져오고, key와 value vector는 인코더 블록의 출력을 가져온다.
인코더와 마찬가지로 6개의 블록을 통과하면 그 출력은 FCN(Fully Connected Network)과 Softmax를 거쳐 학습된 단어 데이터베이스 중 가장 관계가 깊어보이는 단어를 출력하게 된다.
Model Summary
추후에 코드를 돌려보자..
Reference
- https://arxiv.org/pdf/1706.03762v5.pdf
- https://jalammar.github.io/illustrated-transformer/
- https://wikidocs.net/31379
- https://d2l.ai/chapter_recurrent-modern/beam-search.html
- https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- https://blog.promedius.ai/transformer/
