코호트 분석이란?
코호트 분석은 사용자 그룹(코호트)을 특정 기준에 따라 분류하고, 그 그룹의 행동 변화나 성과를 시간에 따라 추적하여 분석하는 방법입니다. 즉, 특정 기간 동안 일정한 기준으로 동일한게 묶을 수 있는 사용자들의 집단을 분석하는 기법입니다. 가장 흔하게 쓰이는 방법은 특정 날짜를 기준으로 사용자들을 하나의 집단으로 묶어 이들의 행동을 분석하는 것입니다. 이 분석 방법은 마케팅, 제품 개발, 사용자 경험 개선 등 다양한 분야에서 활용됩니다. 코호트 분석을 통해 기업이나 조직은 사용자의 행동 패턴을 더 잘 이해하고, 특정 전략이나 조치가 사용자 그룹에 어떤 영향을 미쳤는지 파악할 수 있습니다.
코호트 분석의 핵심은 시간의 흐름에 따른 변화를 관찰하는 것이며, 이를 통해 단기적 및 장기적 사용자 행동의 변화를 파악할 수 있습니다. 그래서 왜 고객들을 하나의 집단으로 묶는가를 아는 것이다. 실무적으로는 고객들의 Exit Rate와 Retention Rate(재방문율 혹은 재구매율)을 파악하여 정기적으로 문제를 진단하고, 해결 전략을 도출하기 위한 대시보드로 많이 활용됩니다.
일반적으로 코호트는 다음과 같은 기준으로 구분될 수 있습니다:
-
시간 기반 코호트: 사용자가 서비스나 제품을 처음 사용하기 시작한 시기에 따라 그룹을 분류합니다. 예를 들어, 특정 월에 가입한 사용자 그룹을 분석하여 그들의 행동 변화를 관찰할 수 있습니다.
-
행동 기반 코호트: 사용자의 특정 행동이나 이벤트를 기반으로 그룹을 분류합니다. 예를 들어, 특정 제품을 구매한 사용자나 특정 기능을 사용한 사용자 그룹의 행동을 분석할 수 있습니다.
-
인구 통계학적 코호트: 사용자의 나이, 성별, 지역과 같은 인구 통계학적 특성에 따라 그룹을 분류합니다.
코호트 분석을 수행할 때는 다음과 같은 절차를 따릅니다:
-
코호트 정의: 분석하고자 하는 코호트 그룹을 정의합니다.
-
데이터 수집: 해당 코호트에 대한 데이터를 수집합니다.
-
분석 수행: 수집된 데이터를 바탕으로 분석을 수행하여, 시간에 따른 행동 변화나 성과 지표의 변화를 관찰합니다.
-
인사이트 도출: 분석 결과를 통해 얻은 인사이트를 바탕으로 개선 방안을 도출하고 전략을 수립합니다.
코호트 분석은 사용자 행동의 이해를 깊게 하고, 전환율을 높이며, 고객 유지율을 개선하는 데 중요한 도구입니다. 이 분석을 통해 얻은 인사이트는 제품 개선, 마케팅 전략 조정, 사용자 경험 최적화 등에 활용될 수 있습니다.
예시
데이터 프레임 생성 후 데이터 정리
# 데이터프레임 생성
cohort = pd.DataFrame(cohort)
# '주문일시' 열을 datetime으로 변환
cohort['주문일시'] = pd.to_datetime(cohort['주문일시'])
# '주문일시'에서 년-월만 추출하여 새로운 열 생성
cohort['ordercycle'] = cohort['주문일시'].dt.strftime('%Y.%m')
# 각 유저고유번호별 최소 주문일시 계산
first_order = cohort.groupby('유저고유번호')['주문일시'].min().reset_index()
first_order.rename(columns={'주문일시': 'firstorder'}, inplace=True)
first_order['firstorder'] = first_order['firstorder'].dt.strftime('%Y.%m')
# 원본 데이터프레임과 병합
cohort = pd.merge(cohort, first_order, on='유저고유번호', how='left')
cohort
첫구매월 / 주문사이클 / 해당 집단 인원 수 / 총 구매금액
#월별로 구매 고객 데이터 치화
co1 = cohort.groupby(['firstorder', 'ordercycle'])['유저고유번호'].nunique().reset_index()
co1.rename(columns={'유저고유번호':'구매자수'}, inplace=True)
#주기별 구매 금액 게산
co2 = cohort.groupby(['firstorder', 'ordercycle'])['상품가격'].sum().reset_index()
co2.rename(columns={'상품가격':'구매금액'}, inplace=True)
# 데이터 병합
co = co1.merge(co2, on=['firstorder', 'ordercycle'])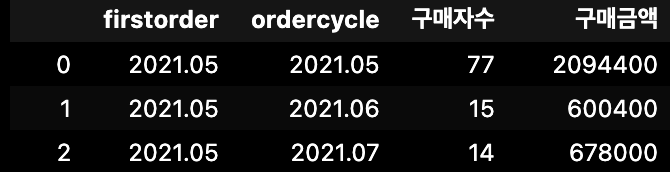
코호트 기간 기준 계산
#코호트기간 기준 계산 및 데이터 형태 최종 완성
temp = []
for i in range(co.shape[0]):
f_first_order = pd.to_datetime(co.firstorder[i]).to_period('M')
f_order_cycle = pd.to_datetime(co.ordercycle[i]).to_period('M')
month_diff = (f_order_cycle - f_first_order).n
temp.append(month_diff)
co['CohortPeriod'] = temp
co.sample(5)
co = co[co['firstorder'] > '2022.01']
co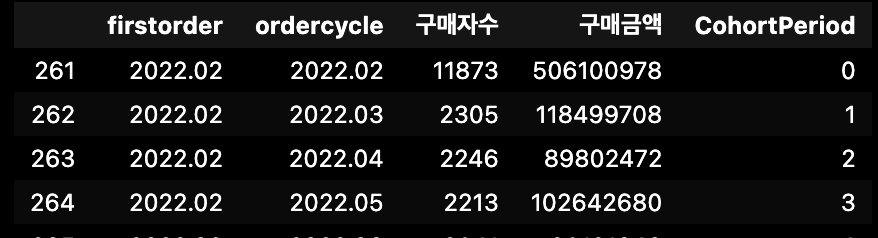
코호트 데이터 형태 최종 완성
#코호트 데이터 형태 최종 완성
## 첫 번째. 재방문율 계산을 위한 Pandas Unstack 활용
co_retention = co.set_index(['firstorder', 'CohortPeriod'])
co_retention = co_retention['구매자수'].unstack(1)
retention = co_retention.div(co_retention.iloc[:, 0],axis = 0)
## 두 번째. 구매 규모 형태 치환을 위한 Pandas Unstack 활용
co_purchase = co.set_index(['firstorder', 'CohortPeriod'])
co_purchase = co_purchase.구매금액.unstack(1)
print(co_purchase)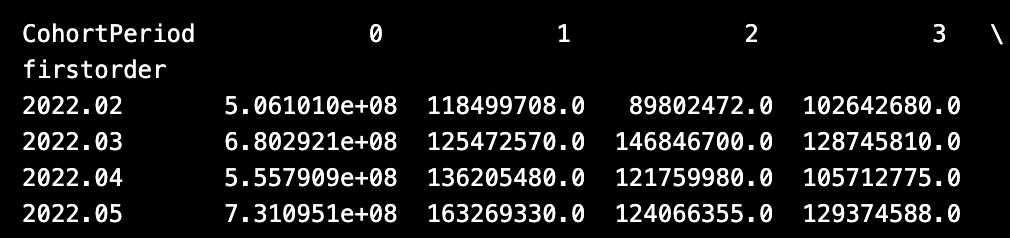
재방문율 시각화
## 재방문율 시각화 진행
plt.rcParams['figure.figsize'] = (12, 8)
sns.heatmap(retention, annot = True , fmt = '.0%', cmap = 'RdYlGn',annot_kws={'size': 8})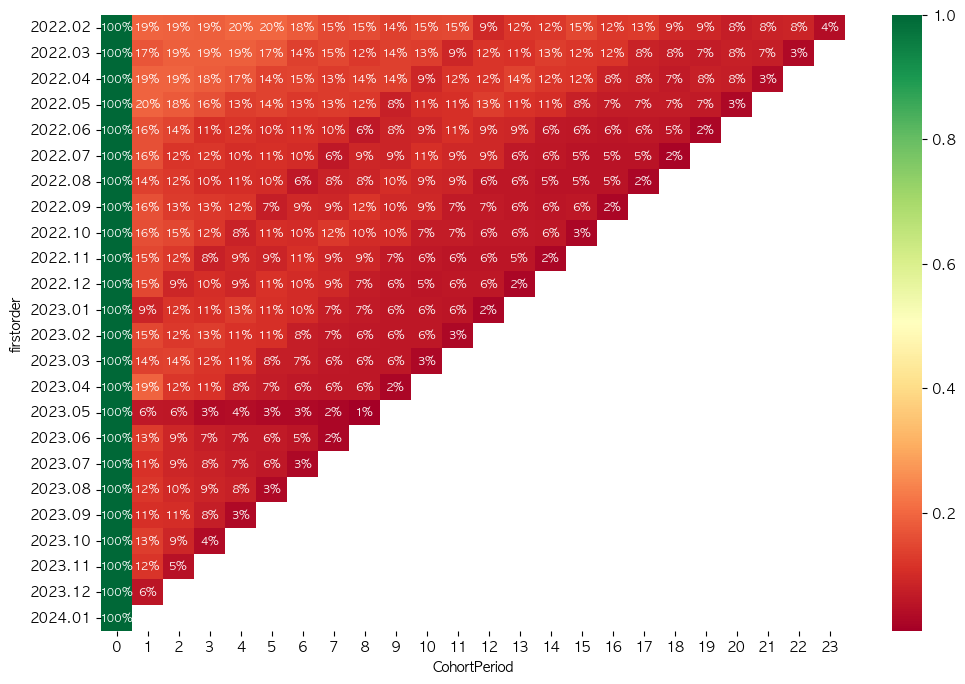 ![]
![]
구매규모 시각화
## 구매 규모 시각화
plt.rcParams['figure.figsize'] = (20, 12)
sns.heatmap(co_purchase, annot = True ,cmap = 'RdYlGn',annot_kws={'size': 8}
# , fmt = '.0%'
)
plt.yticks(rotation = 360)코호트 테이블 해석
-
가장 왼쪽열은 월별로 해당 월에 구매한 유저 수를 기록한 것
-
맨 아래서 두번째 (2023.12, 01)의 숫자는 6%이다. 이는 23.12월에도 사용하고 그 다음달에도 사용한 수 / 23.12 사용자수 = 2.23
-
이 차트를 통해서 각 코호트들의 리텐션을 CohortPeriod0 부터 23까지 분석할 수 있음.
-
리텐션 계산 방법: Month N 사용자 수 / Mon 0 사용자 수 (%)
-
코호트 차트를 보는 방향에 따라서 다양하게 해석할 수도 있음
-
세로 방향을 본다면, 같은 기간이 지난 후 cohort 간 리텐션을 비교할 수 있음
-
대각선 방향으로 본다면, 같은 시간대 cohort 간 비교를 할 수 있음
