연구목적
열람실 좌석을 클러스터링하면 어떠한 결과값이 나올지 궁금
이렇게 만들면, 열람실 좌석의 위치에 따른 선호도를 알 수 있지 않을까 예상
클러스터링 소개
클러스터링은 비슷한 특성을 가진 데이터 포인트들을 그룹화하는 기계학습의 한 분야입니다. 이 방법은 데이터의 구조를 이해하고, 숨겨진 패턴을 발견하며, 의미 있는 인사이트를 추출하는 데 유용합니다. 이 글에서는 클러스터링의 다양한 기법들을 가볍게 소개해 보겠습니다.
- K-평균 클러스터링 (K-Means Clustering)
K-평균은 가장 널리 사용되는 클러스터링 알고리즘 중 하나입니다. 이 방법은 데이터를 K개의 클러스터로 나눕니다. 알고리즘은 먼저 클러스터의 중심(centroid)을 무작위로 선택하고, 각 데이터 포인트를 가장 가까운 중심에 할당합니다. 그 후, 각 클러스터의 평균 위치를 계산하여 새로운 중심으로 설정합니다. 이 과정을 중심의 위치가 더 이상 변하지 않을 때까지 반복합니다. - 계층적 클러스터링 (Hierarchical Clustering)
계층적 클러스터링은 데이터를 트리 구조인 덴드로그램으로 표현하는 방법입니다. 이 방법은 "바텀업" 접근 방식을 사용하여 시작할 때 각 데이터 포인트를 하나의 클러스터로 간주하고, 가장 가까운 클러스터끼리 차례대로 병합해 나갑니다. 이 과정은 하나의 클러스터가 남을 때까지 계속됩니다. 사용자는 원하는 클러스터의 수를 선택하여 클러스터링을 정지할 수 있습니다. - 밀도 기반 클러스터링 (Density-Based Clustering)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)은 밀도 기반 클러스터링의 대표적인 예입니다. 이 방법은 데이터 포인트의 밀집 지역을 클러스터로 그룹화하고, 밀도가 낮은 지역을 이상치로 간주합니다. DBSCAN은 클러스터의 형태와 크기에 상관없이 클러스터를 찾을 수 있으며, 노이즈를 자동으로 구분해낼 수 있는 장점이 있습니다. - 스펙트럼 클러스터링 (Spectral Clustering)
스펙트럼 클러스터링은 그래프 이론에 기반한 방법으로, 데이터 포인트 간의 관계를 그래프로 표현합니다. 이 방법은 그래프의 라플라시안 행렬의 고유 벡터를 사용하여 데이터를 낮은 차원으로 투영한 후, 이 투영된 공간에서 클러스터링을 수행합니다. 스펙트럼 클러스터링은 복잡한 구조를 가진 데이터에 대해 우수한 성능을 보입니다.
마치며
클러스터링은 데이터를 이해하고 구조화하는 데 매우 중요한 도구입니다. 각 클러스터링 기법은 고유한 특성과 사용 케이스를 가지고 있으므로, 실제 문제에 적용하기 전에 데이터의 특성을 고려하여 가장 적합한 방법을 선택하는 것이 중요합니다.
K-means
실루엣 값이 가장큰 3으로 결정해서 진행
from sklearn.metrics import silhouette_score
# K값을 4로 설정하고 K-평균 군집 분석 수행
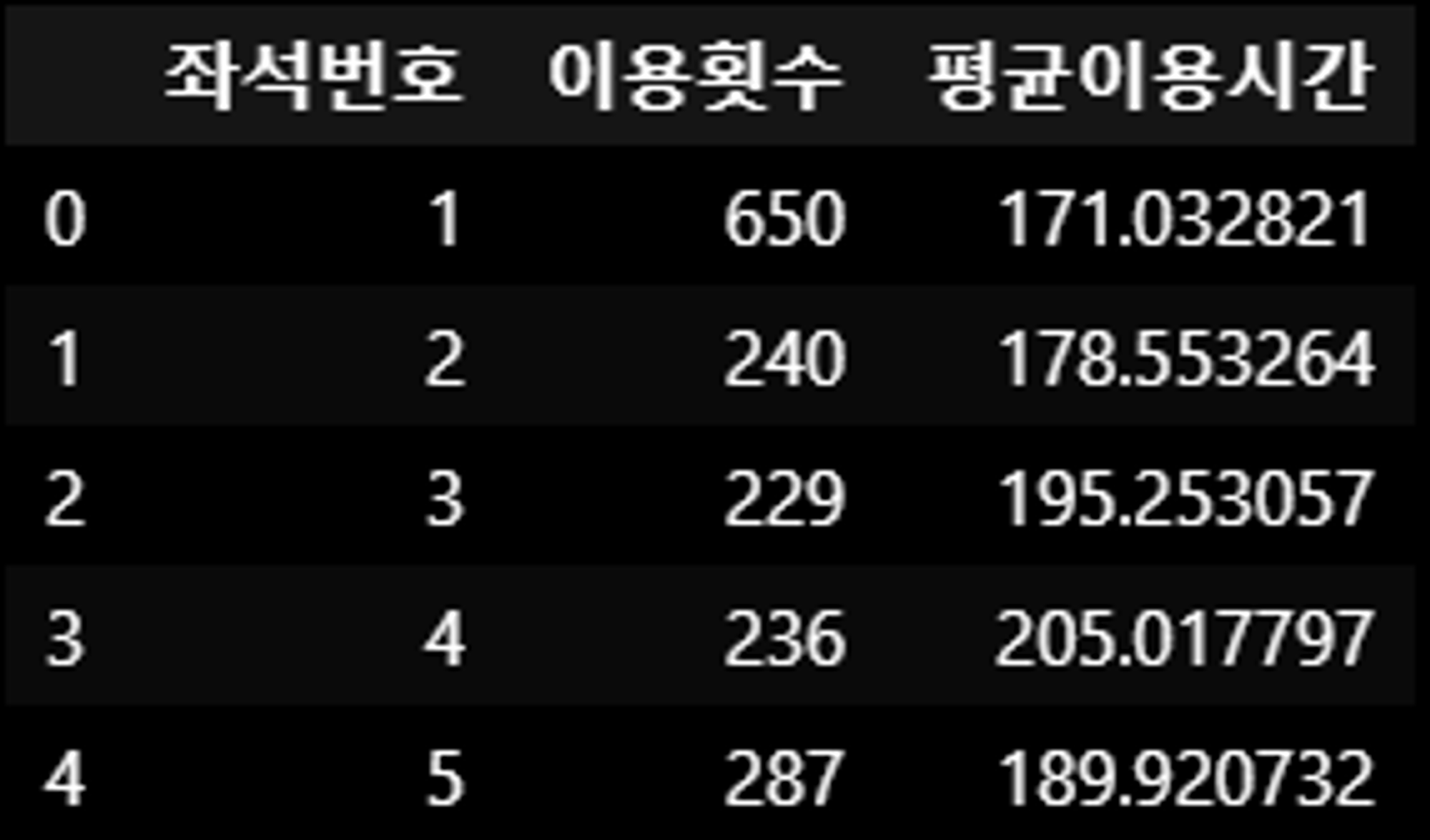
kmeans = KMeans(n_clusters=2, random_state=42)
seat_stats['군집'] = kmeans.fit_predict(seat_stats[['이용횟수', '평균이용시간']])
# 군집화 결과 시각화
plt.figure(figsize=(10, 6))
plt.scatter(seat_stats['이용횟수'], seat_stats['평균이용시간'], c=seat_stats['군집'], cmap='viridis')
plt.title('Cluster of Seats')
plt.xlabel('Usage Frequency')
plt.ylabel('Average Usage Time (minutes)')
plt.colorbar(label='Cluster')
plt.show()
# 군집별 중심점 확인
centers = kmeans.cluster_centers_
# 실루엣 점수 계산
silhouette_avg = silhouette_score(seat_stats[['이용횟수', '평균이용시간']], seat_stats['군집'])
centers, silhouette_avg
계층적 군집화
유사도 매트릭스를 만들고 진행해야합니다.
from sklearn.preprocessing import StandardScaler
from sklearn.metrics.pairwise import cosine_similarity
# 데이터 표준화
scaler = StandardScaler()
features_scaled = scaler.fit_transform(seat_stats[['이용횟수', '평균이용시간']])
# 코사인 유사도 매트릭스 계산
similarity_matrix = cosine_similarity(features_scaled)
# 유사도 매트릭스의 크기 확인
similarity_matrix.shape
from scipy.cluster.hierarchy import dendrogram, linkage
# 계층적 군집화 수행
linked = linkage(similarity_matrix, 'single')
# 덴드로그램 시각화
plt.figure(figsize=(10, 7))
dendrogram(linked,
orientation='top',
labels=seat_stats['좌석번호'].values,
distance_sort='descending',
show_leaf_counts=True)
plt.show()
from scipy.cluster.hierarchy import fcluster
# 군집 수를 기반으로 각 데이터 포인트에 대한 군집 라벨 할당
# 여기서는 덴드로그램을 기반으로 적절해 보이는 군집 수를 선택해야 합니다.
# 4개의 군집을 형성한다고 결정.
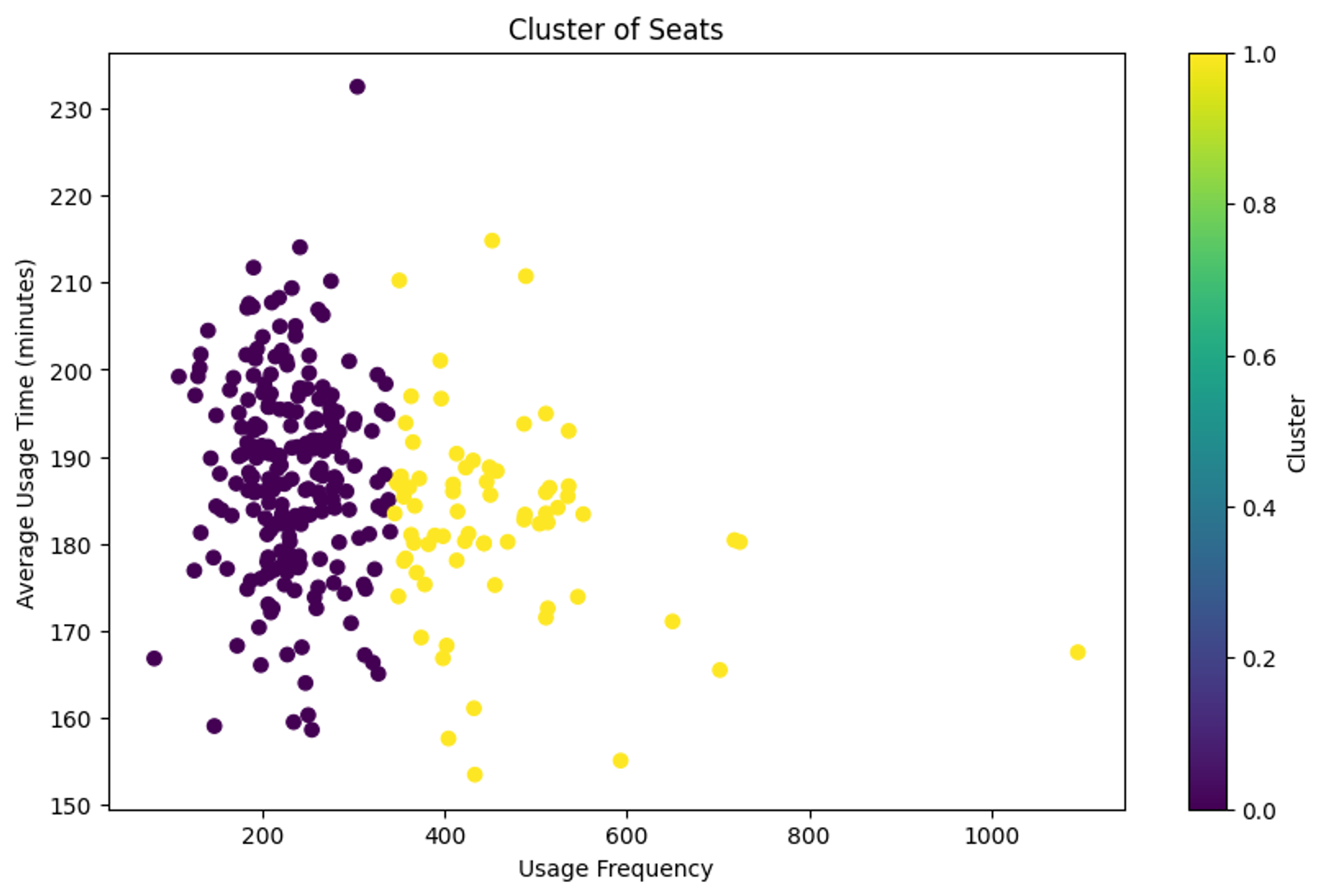
cluster_labels = fcluster(linked, t=8, criterion='maxclust')
# 군집 라벨을 좌석번호 데이터에 할당
seat_stats['군집_유사도기반'] = cluster_labels
# 군집 라벨이 할당된 데이터의 처음 몇 줄 확인
seat_stats.head()
# 군집화 결과 시각화
plt.figure(figsize=(10, 6))
plt.scatter(seat_stats['이용횟수'], seat_stats['평균이용시간'], c=seat_stats['군집_유사도기반'], cmap='viridis')
plt.title('Cluster of Seats')
plt.xlabel('Usage Frequency')
plt.ylabel('Average Usage Time (minutes)')
plt.colorbar(label='Cluster')
plt.show()
DBSCAN
from sklearn.cluster import DBSCAN
# DBSCAN 군집화 수행
# eps와 min_samples는 데이터의 특성에 따라 조정해야 할 수 있습니다.
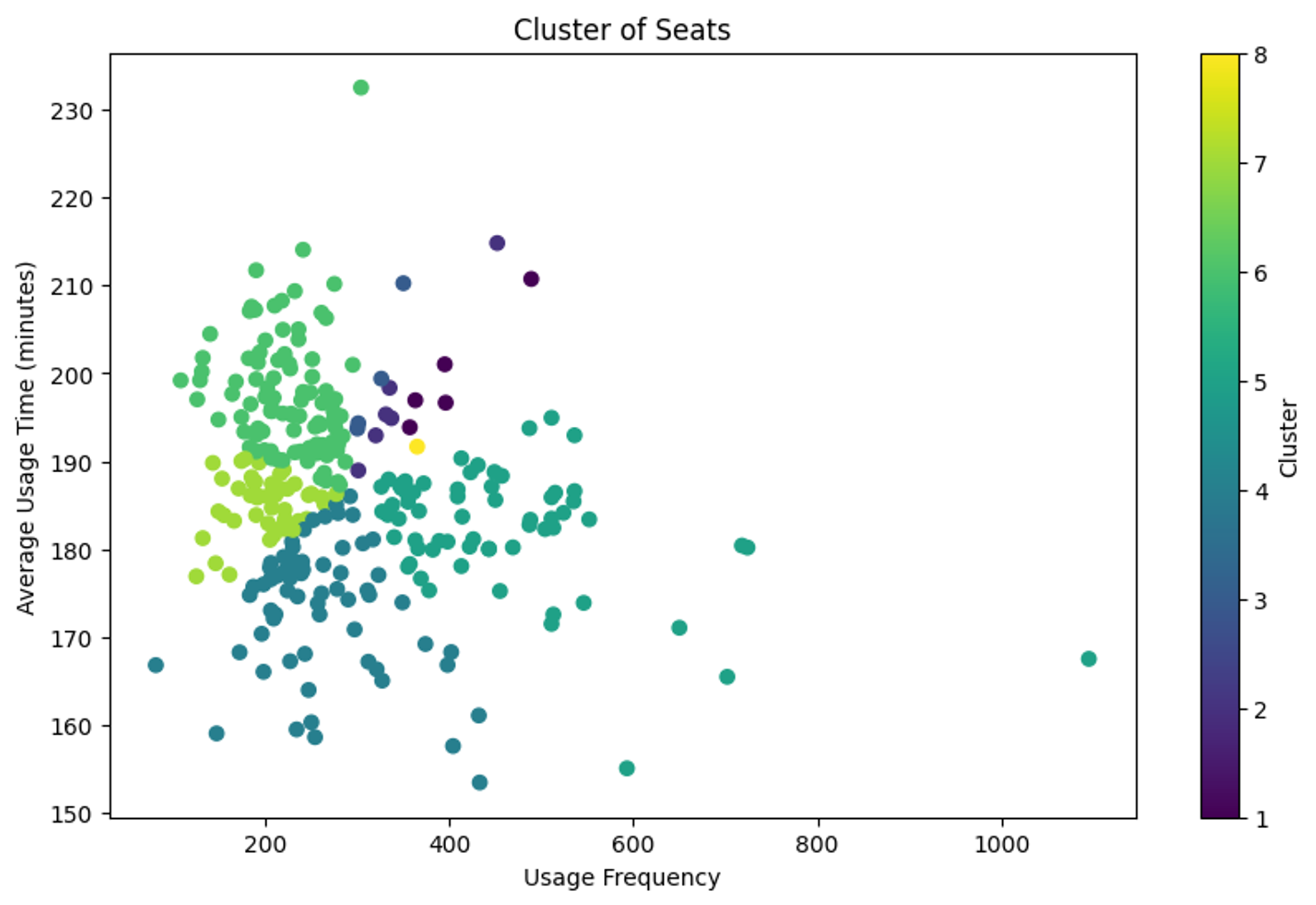
dbscan = DBSCAN(eps=0.6, min_samples=5)
seat_stats['군집_DBSCAN'] = dbscan.fit_predict(features_scaled)
# 군집화 결과 시각화
plt.figure(figsize=(10, 6))
plt.scatter(seat_stats['이용횟수'], seat_stats['평균이용시간'], c=seat_stats['군집_DBSCAN'], cmap='viridis', s=50)
plt.title('DBSCAN Clustering of Seats')
plt.xlabel('Usage Frequency')
plt.ylabel('Average Usage Time (minutes)')
plt.colorbar(label='Cluster')
plt.show()
# 군집화 결과 확인
seat_stats.groupby('군집_DBSCAN').size()
스펙트럴 군집화
from sklearn.cluster import SpectralClustering
# 스펙트럴 군집화 수행
# 군집 수는 앞서 K-평균에서 사용했던 것과 동일하게 4로 설정
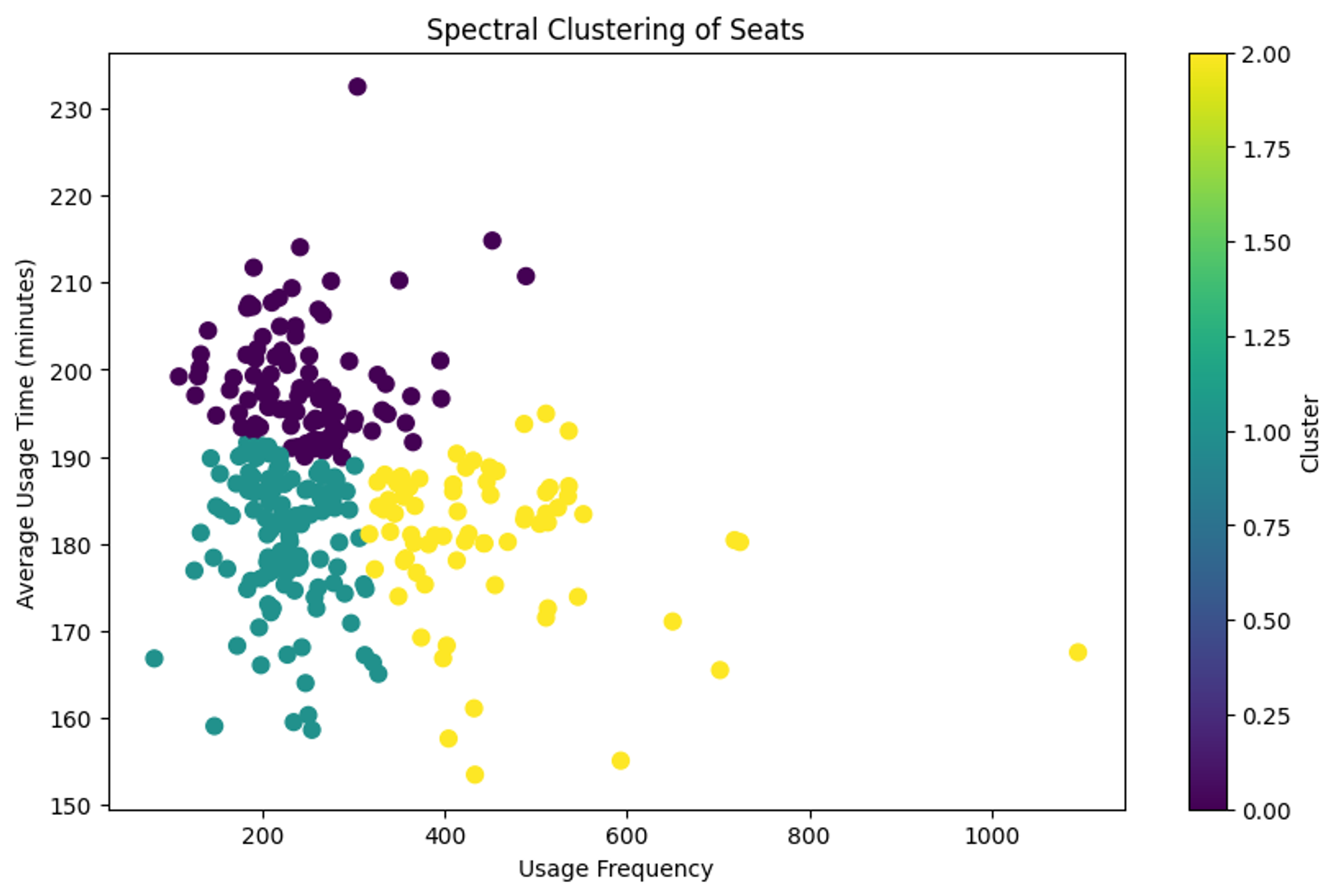
spectral_clustering = SpectralClustering(n_clusters=3, affinity='nearest_neighbors', random_state=42)
seat_stats['군집_스펙트럴'] = spectral_clustering.fit_predict(features_scaled)
# 군집화 결과 시각화
plt.figure(figsize=(10, 6))
plt.scatter(seat_stats['이용횟수'], seat_stats['평균이용시간'], c=seat_stats['군집_스펙트럴'], cmap='viridis', s=50)
plt.title('Spectral Clustering of Seats')
plt.xlabel('Usage Frequency')
plt.ylabel('Average Usage Time (minutes)')
plt.colorbar(label='Cluster')
plt.show()
# 군집화 결과 확인
seat_stats.groupby('군집_스펙트럴').size()

언제나 ‘왜?’라는 물음을 통해 불가능 대신 해법을 모색하는 AI 연구자입니다