DISK-1
-
Disks and Files
DBMS 저장소는 하드 또는 플래시 SSDs를 사용함
CPU -> CPU Cache -> DRAM -> DiskCapacity ($/GB) : Harddisk >> Flash SSD
Bandwidth (MB/sec): Harddisk < Flash SSD (몇 차선인지)
Latency (IOPS): Harddisk << Flash SSD (전송속도, 옛날에는 중요했음)
-
Disks
옛날에는 테이프가 중요한 저장장치, sequential함
디스크는 되돌리기도 가능하기에 random access로서 혁신적이었음
인접한 위치에 데이터들이 있어야 접근속도가 길어지지 않을 수 있다
e.g. elevator disk scheduling algorithms
rpm이 클수록 접근속도가 증가함
Update-in-place, No atomic write, Fsync -
Accessing a Disk Page
1) Seek time (head에서 원하는 트랙으로 arm을 움직이는 것)
2) Rotational delay (원하는 블락으로 이동하는 것, rpm에 따라 차이남)
3) Transfer time (전송속도) -
Arranging Pages on Disk
'Next' block concept : 같은 트랙, 실린더, 또는 인접한 곳에 위치 (sequentially) -
Techniques to Hid IO Bottlenecks
1) Pre-fetching (미리미리 읽어오는 것)
2) Caching
3) IO overlapping (CPU works while IO is performing)
-> Multiple threads -
Disk 개선
개선 쉬운정도 : capacity > bandwidth > latency (개선어렵기에 중요)
비용 때문에 -
메인 메모리에 모두 저장하지 않는 이유
비용측면, volatile(휘발성) : 데이터가 업데이트가 됨
Dram size와 파워관계는 exp형태 -
RAID
SLED (Single Large Expensive Disk)
상호 독립적인 싼 디스크를 묶음으로 해서 가성비 좋은 것을 만들 수 있지 않을까
목표 : Increase performance and reliability
RAID 0 : nonredundant striping (IOPS, Bandwidth)
RAID 1 : mirrored disks (안전성, 옛날에는 고장이 잘 났음)
cf) Tesla Battery and Rocket Tech (engine)
DISK-2
-
FILE (per table)
Operations
1) Insert/delete/modify record
2) Fetch a particular record (specified using record id)
3) Scan all records (possibly wiUnordered (Heap) Files (보편적임)
To support record level operations
-
Heap File: Implemented as a List
Each page contains 2 ‘pointers’ plus data. (prev, next)
비효율적 -
Heap File: Using a Page Directory
-
Oracle:
Tablespace, Segments, Extents, and Blocks -
Tablespace : 로지컬한 DBMS의 파일
-
Segment : each table, index당 세그먼트가 생김 (물리적인 개념) (파일 폴 테이블)
-
Extent : segment가 늘어날때 물리적인 할당량이 들어날 때의 단위 (연속된 디스크블락들)
-
Block (페이지라고도 불림) : 크기 설정 가능
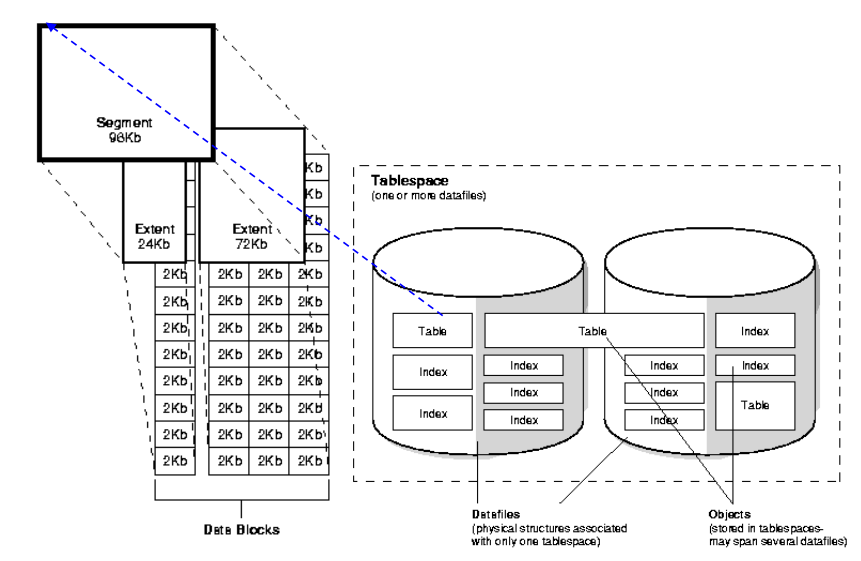
-
user_tables
COLUMN table_name FORMAT a10
COLUMN tablespace_name FORMAT a10
select table_name, tablespace_name, blocks, pct_free, avg_row_len, avg_space
from user_tables
where table_name = 'TEST'; /* TEST table in Ch9-Script.sql */
664 * 10 + 1410 ≒ 8KB (한 페이지의 크기)
- dba_segments
conn scott/tiger as sysdba
COLUMN segment_name FORMAT a10
COLUMN segment_type FORMAT a10
SELECT segment_name, segment_type, header_file, header_block,
blocks,extents, max_extents
FROM dba_segments
WHERE segment_name = 'TEST';
- dba_extents
COLUMN segment_name FORMAT a10
COLUMN tablespace_name FORMAT a10
SELECT segment_name, tablespace_name, extent_id, file_id, block_id, blocks
FROM dba_extents
WHERE segment_name = 'TEST';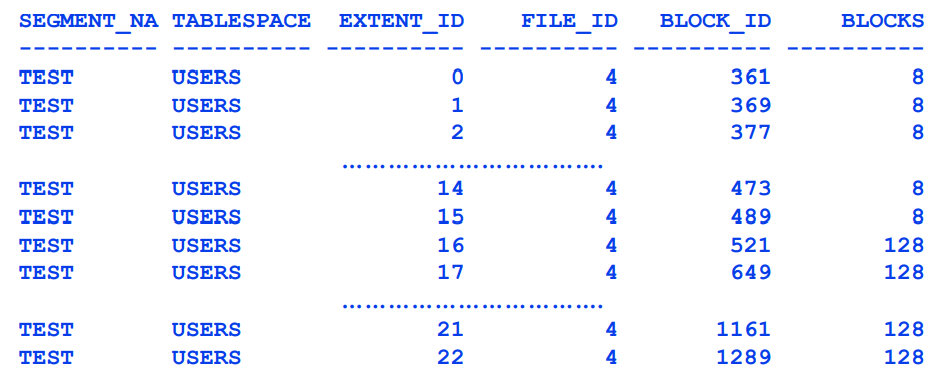
8KB * 8 = 64KB의 extent
-
Page Formats: Fixed Length Records
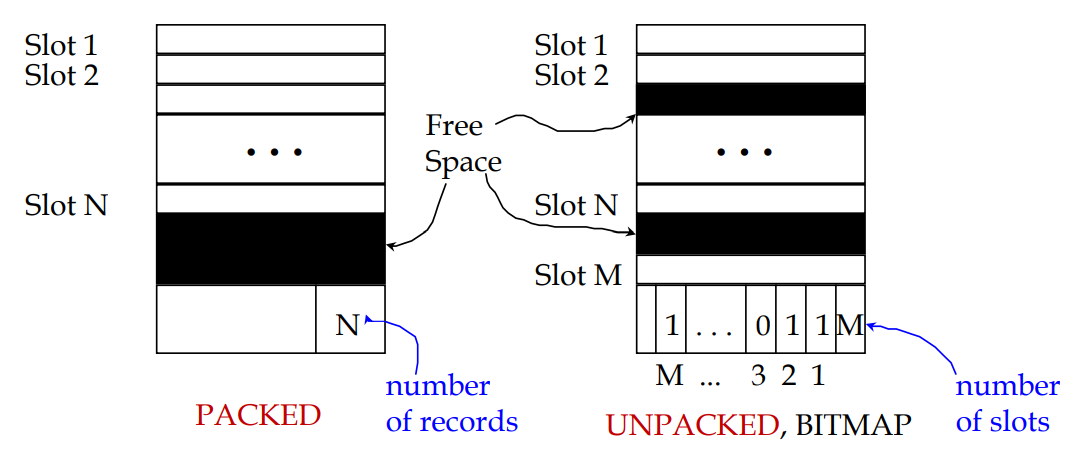
record id = <page id, slot #> // can fetch a record using its record_id
문자 타입의 크기가 다를 수 있으므로 가변되어야 함. -
Page Formats: Variable Length Records
Tuple-Oriented, Slotted Page Structure
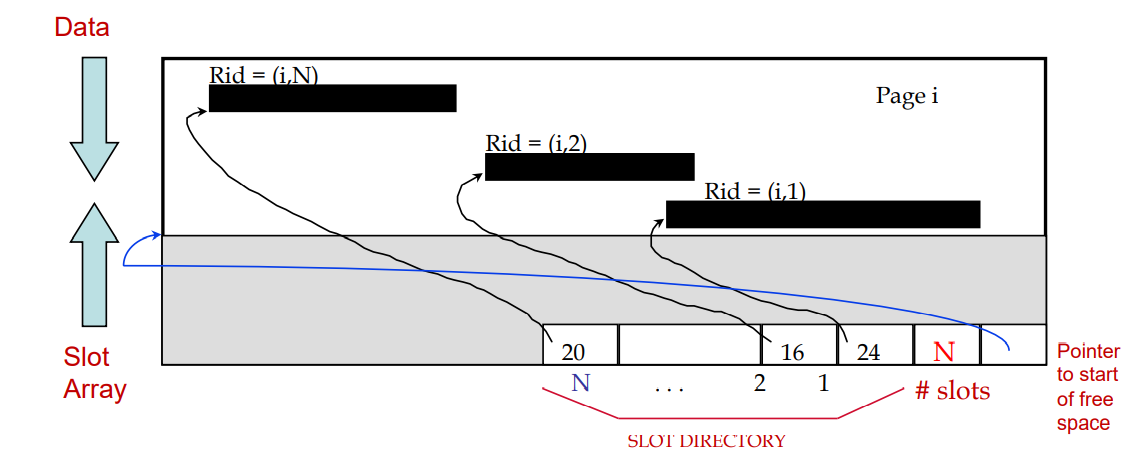
-
Block Dump in Oracle
conn scott/tiger as sysdba
select header_file, header_block, bytes, blocks
from dba_segments
where segment_name = ‘EMP';
alter system dump datafile 4 block min 27 block max 30;
--- Check the trace file in admin/udump/xxx.trc file.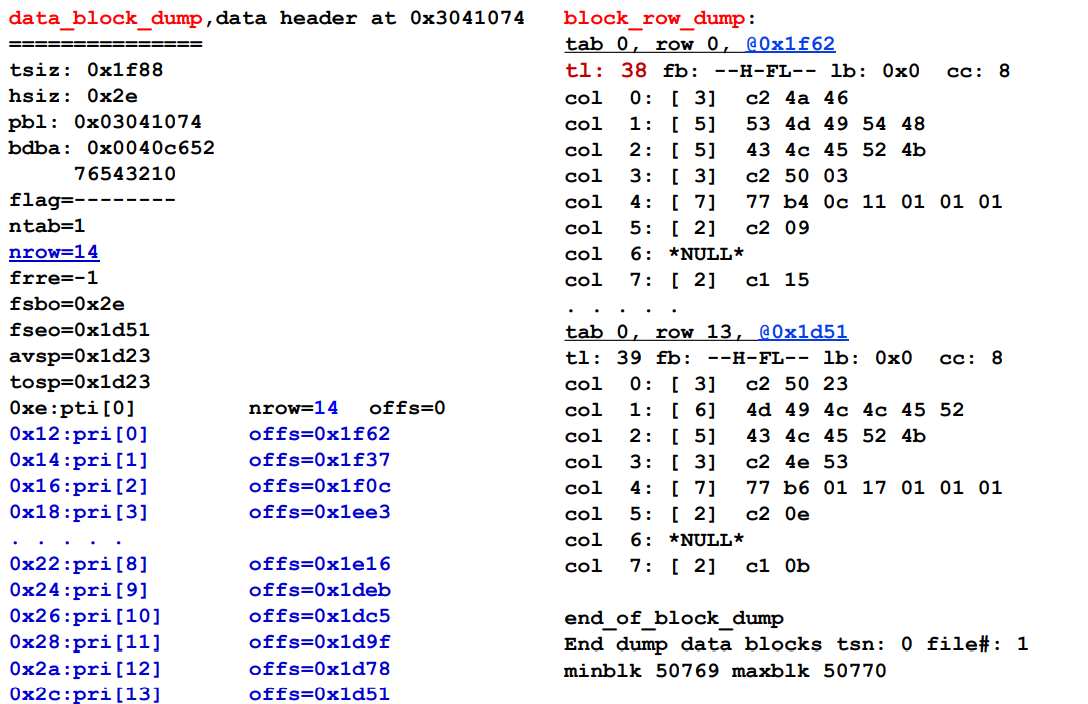
-
“Classical” Data Layout on Disk Page: Row-Store (행별로 저장)
-
Other Layouts: C-Store and Pax (열별로 저장)
-
Record Formats: Fixed Length(초기주소 + 크기x개수로 접근) / Variable Length (다 방문해서 접근해야함)
-
Row Layout in Oracle
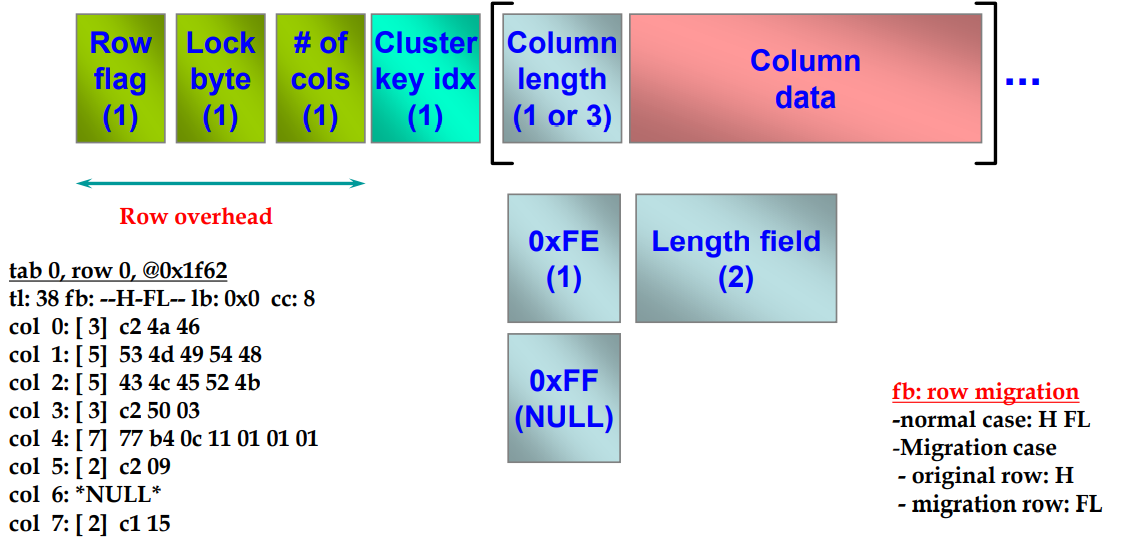
넘치면 0xFE가 들어가있음 -
Column Value in Oracle
=============== SQL DUMP function ===========
// dump() show s how a data value is stored in disk
select dump(a)
from test
where a = 1000;
DUMP(A)
-------------------------------
Typ=2 Len=2: 194,11 Integer value 1000: type 2: int, column lengh 2 byte
data value 1000 is represented as (194, 11)-
System Catalogs(or Data Dictionary)
-
Full Table Scan: An Access Method
Oracle 9.2는 1000개를 하나씩 읽는게 아니라, 16개씩 읽는다. (근데 실제는 10.398씩을 읽음)
Cost = 1000 / 10.4 + 1 = 98 -
OLAP vs. OLTP
On-Line { Analytical vs. Transactional} Processing
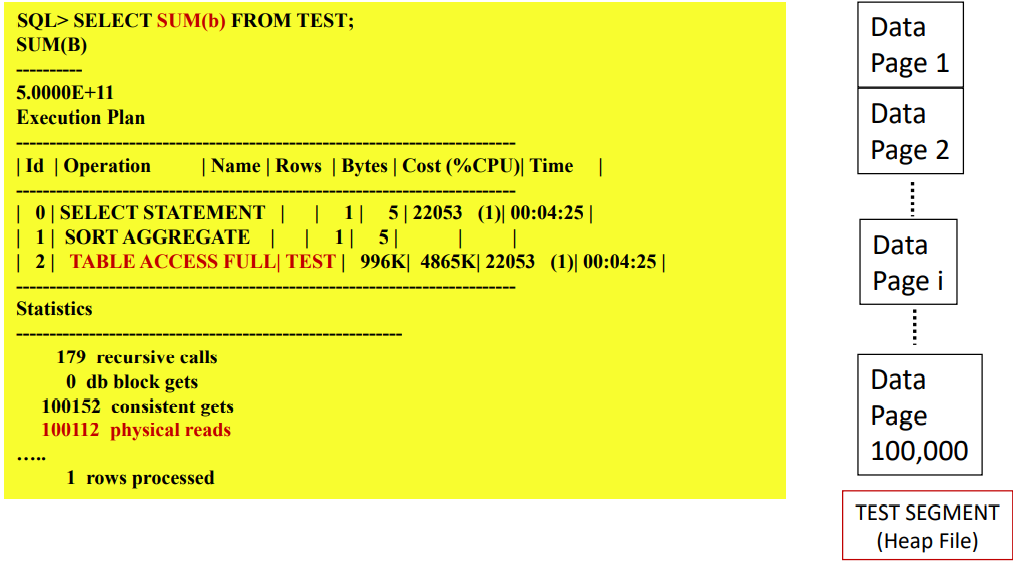
-
Point or Range Query
On-Line Transactional Processing
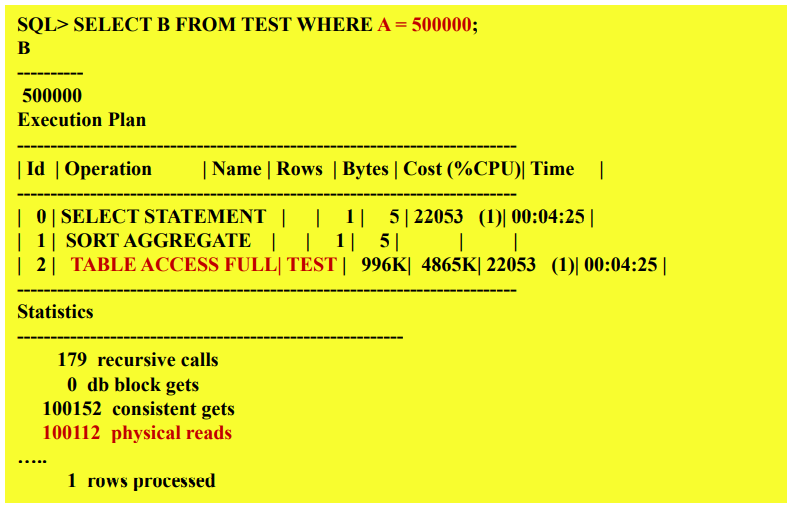
-
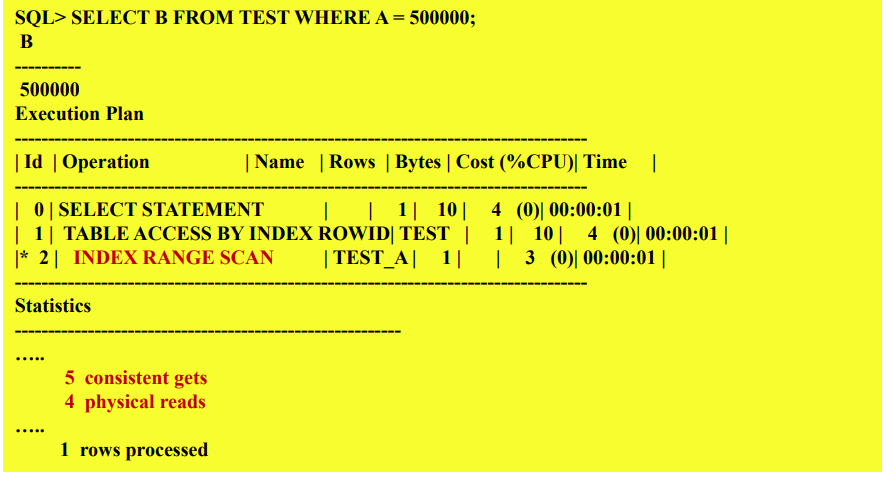
Index-based Table Access
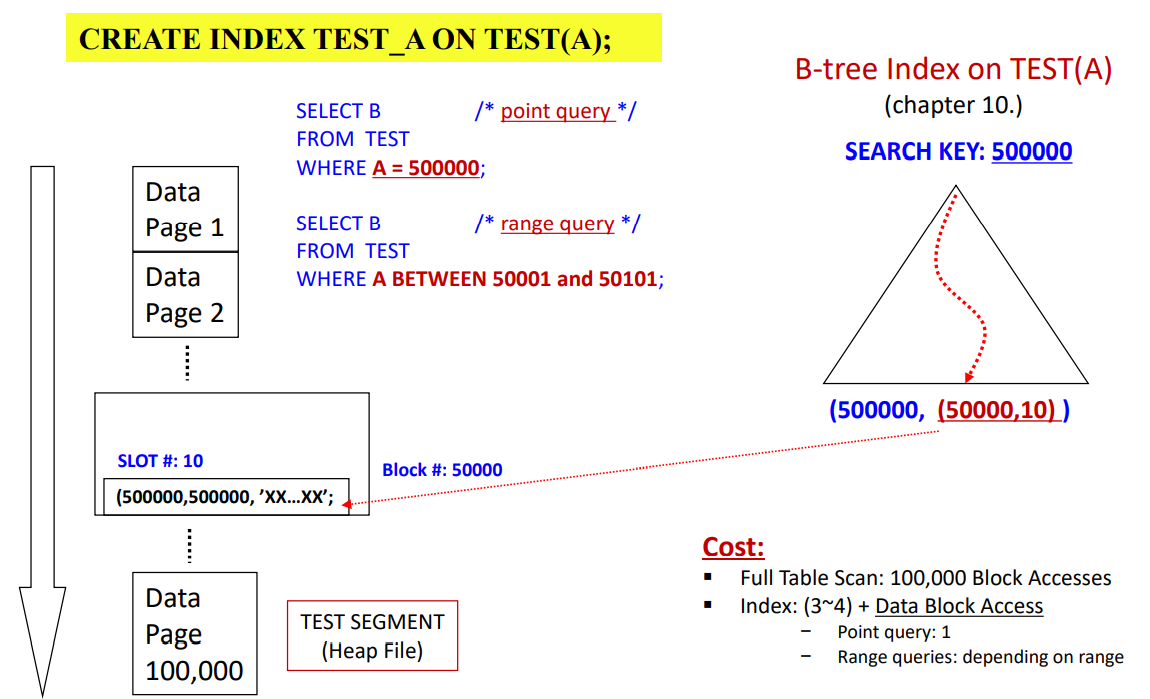
랜덤하게 페이지에 대한 접근을 하게 됨.
DISK-3
-
Disk Space Management
allocate/de-allocate a page
read/write a page -
Buffer Management in a DBMS
-
Buffer pool information table: <frame#, pageid, pin_cnt, dirty>
pin_cnt : 해당 버퍼가 사용중임을 뜻함 -
Buffer Replacement Policy
Hit vs. miss
Hit ratio = # of hits / ( # of page requests to buffer cache)
Problem: for the given (future) references, which victim should be chosen for highest hit ratio (i.e. least # of IOs)? -
Frame is chosen for replacement by a replacement policy
Random, FIFO, LRU, MRU, LFU, Clock etc. -
For a given workload, one replacement policy, A, achieves 90% hit ratio and the other, B, does 91%.
How much improvement? 1% or 10%?
Miss로 봤을때 10% / 9%, 추가 IO가 10000번, 9000번 발생됨. 그러면 10퍼 아낌으로 볼 수 있음. -
Least Recently Used (LRU)
For each page in buffer pool, keep track of time last unpinned
Replace the frame that has the oldest (earliest) time -
Problem of LRU - sequential flooding
MRU much better in this situation -
“Clock” Algorithm
An approximation of LRU
do for each page in cycle {
if (pincount == 0 && ref bit is on)
turn off ref bit;
else if (pincount == 0 && ref bit is off)
choose this page for replacement;
} until a page is chosen-
Belady’s MIN Algorithm
Theoretical optimal buffer replacement algorithm
가장 멀리있는걸 victim 으로 선정 -
CPU-IO Overlapping
3 States: CPU Bound, IO Bound, Balanced
IO가 초당 얼만큼인지가 중요함. -
서버에서 HDD와 SSD를 섞어서 가격당 capacity를 조절함
-
Five minute rule
5분 보다 더 자주 접근되면 DRAM에 투자
반대는 DISK가 더 이득
