-
Basic Concepts
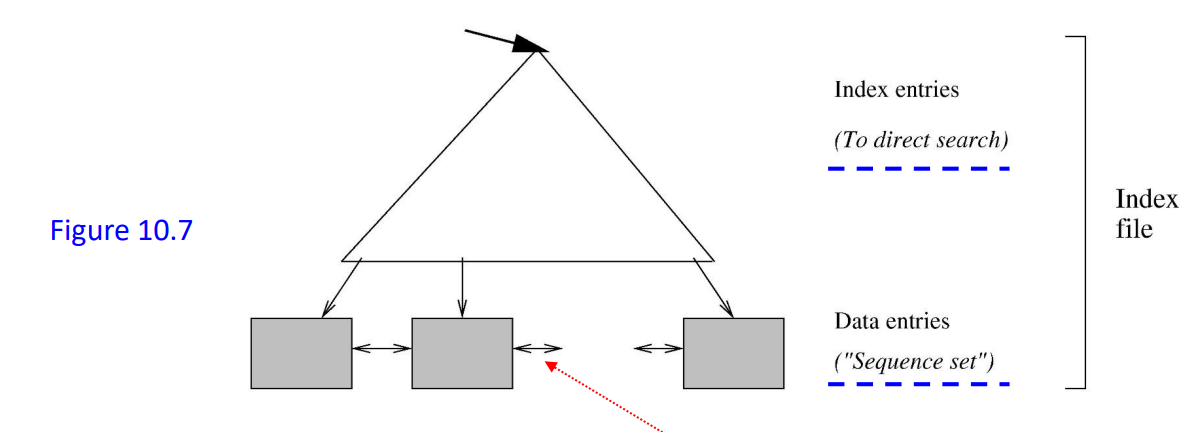
An index file consists of records (called data entry or index entry)
search-key | pointer
Index files are typically much smaller than the original file -
Index-based Access on Heap file
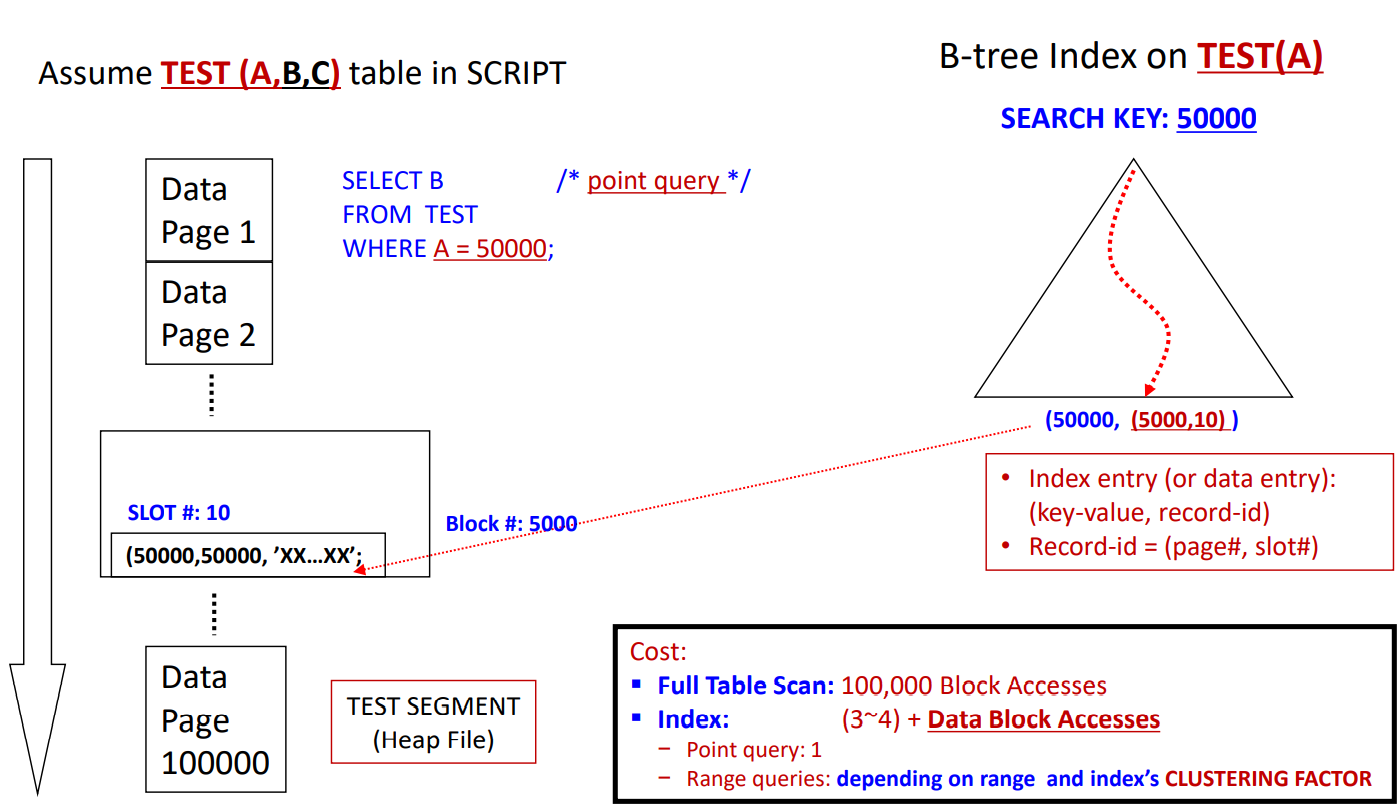
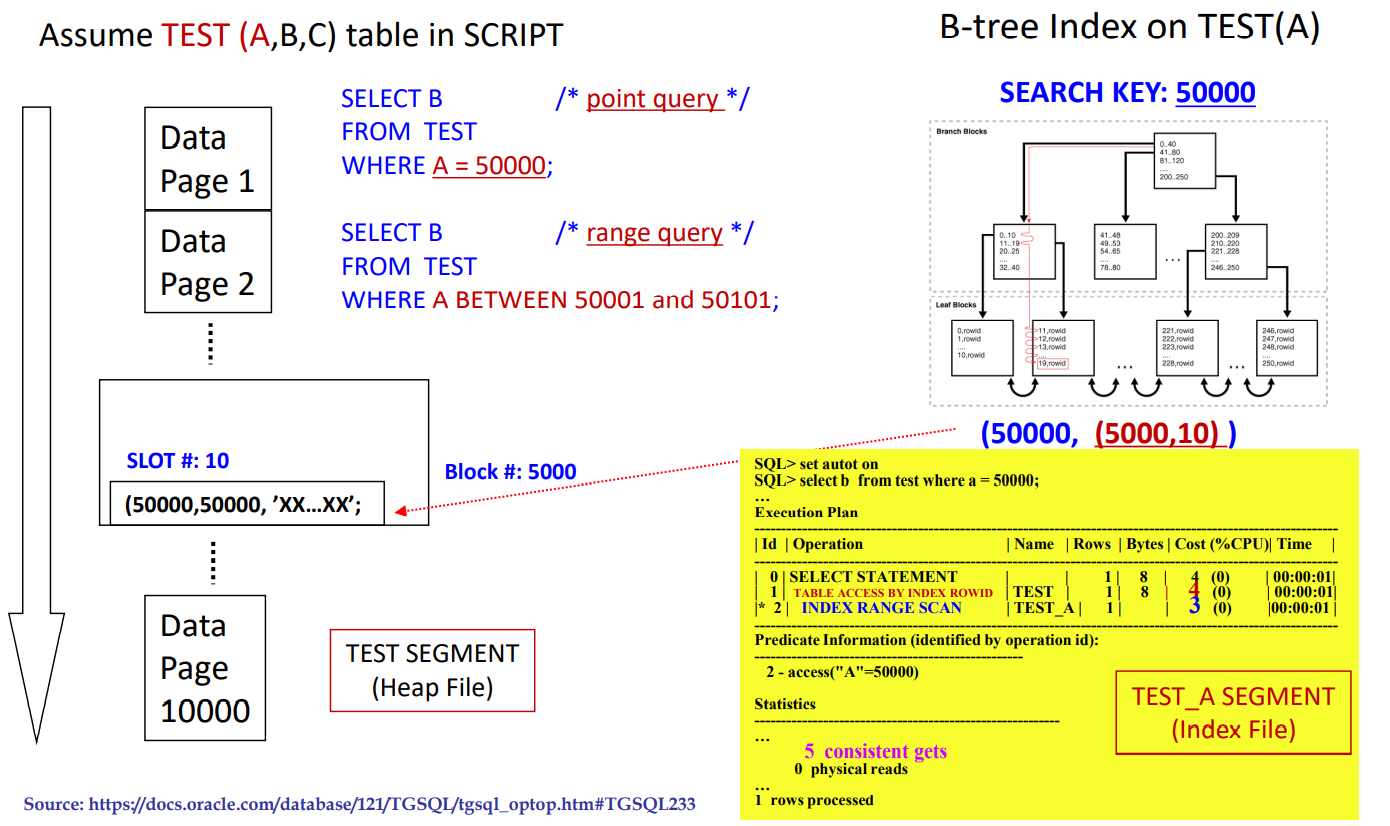
-
Trade-off: Search time vs. Space/Insertion/Deletion overhead
-
Clustered vs. Non-Clustered Index
If data records are sorted according to the index key, then clustered index. -
Structure of B+ Tree
-
Search
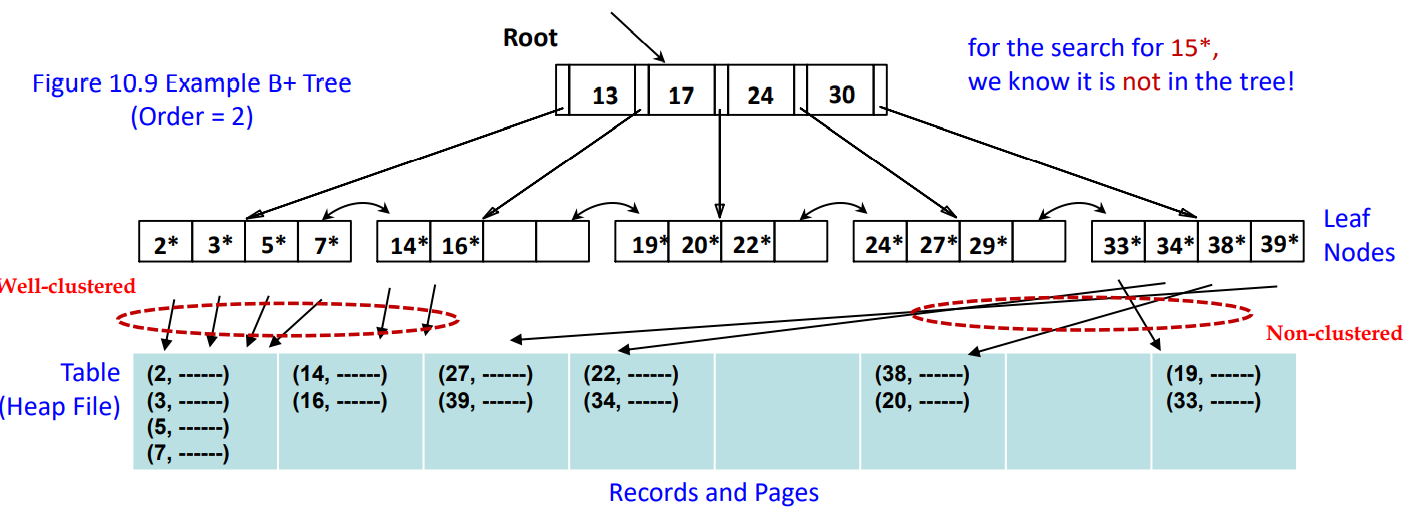
-
CLUSTERING FACTOR
접근하는 페이지가 달라지면 증가시켜줌
클러스더가 안되어있으면 매우 큼 (힙파일개수 -> 레코드개수) -
Inserting 8* into Example B+ Tree
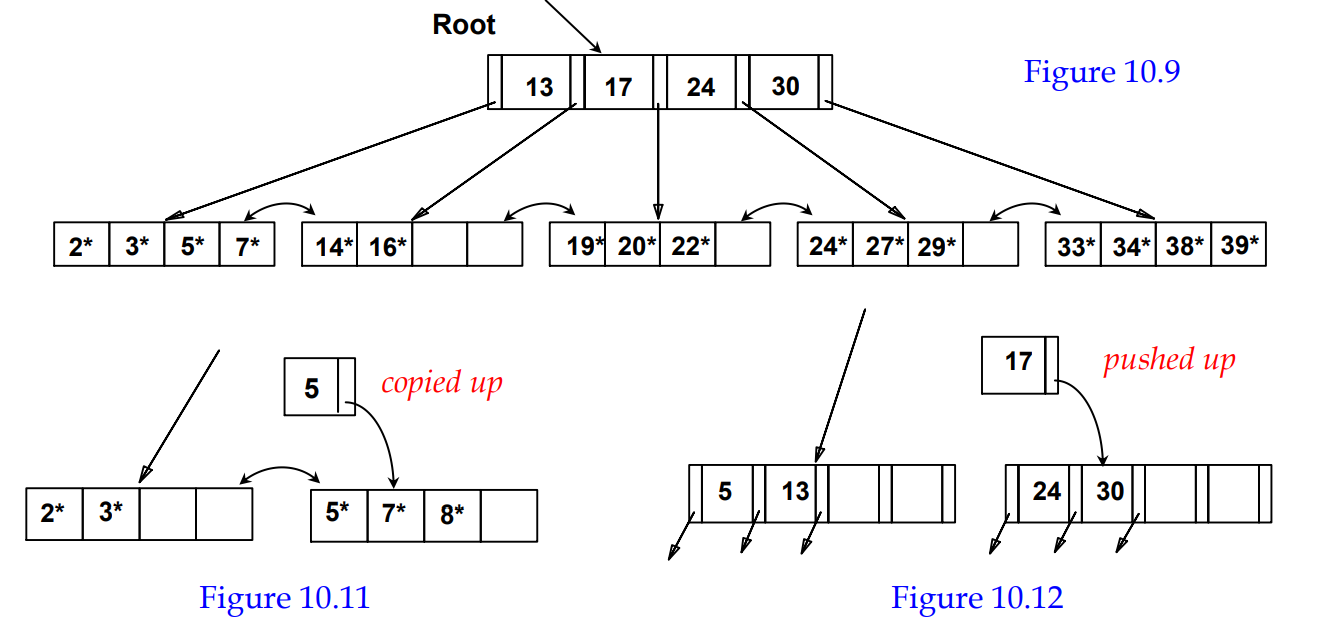
키가 바뀜, this is usually not done in practice -
Insertion/deletion at ( log N / log F) cost
F = fanout; N = # leaf pages -
Hashing
-
Bitmap indexes for data warehouse
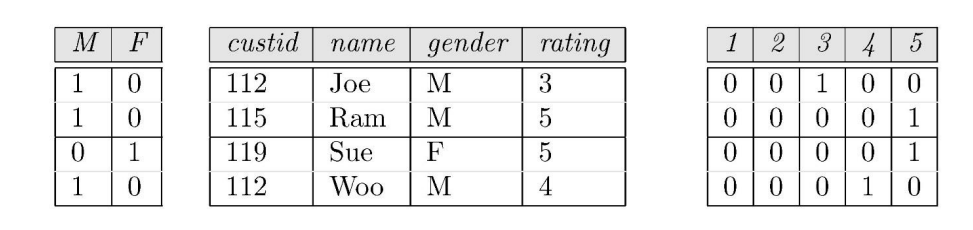
gender F & rating 5 -> bit : 1

반갑습니다.!!! :)